







import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.atomic.LongAdder;
public class T {
static long count=0L;
final static Object lock = new Object();
static AtomicLong aLong= new AtomicLong(0);
static LongAdder longAdder= new LongAdder();
public static void main(String[] args) {
List<Thread>list= new ArrayList<>();
for (int i = 0; i < 1000; i++) {//1000个线程
list.add(new Thread(()->{
for (int j = 0; j < 100000; j++) {
synchronized (lock) {
count++;
}
}
}));
}
long LongStart = System.currentTimeMillis();
list.forEach((o)->{o.start();});
list.forEach((o)-> {
try {
o.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long LongEND = System.currentTimeMillis();
Thread []threads= new Thread[1000];
for (int i = 0; i < 1000; i++) {
threads[i]=new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 100000; j++) {
aLong.incrementAndGet();//i++
}
}
});
}
long AutoStart = System.currentTimeMillis();
for (Thread t :
threads) {
t.start();
}
for (Thread t :
threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long AutoEnd = System.currentTimeMillis();
long addStart = System.currentTimeMillis();
LinkedList<Thread>threadLinkedList= new LinkedList<>();
for (int i = 0; i < 1000; i++) {
threadLinkedList.add(new Thread(()->{
for (int j = 0; j < 100000; j++) {
longAdder.increment();
}
}));
}
threadLinkedList.forEach((o)->{o.start();});
threadLinkedList.forEach((o)->{
try {
o.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long addEnd = System.currentTimeMillis();
System.out.println("最后结果--"+count+"longCount用时"+(LongEND-LongStart));
System.out.println("最后结果--"+aLong.get()+"longAuto用时"+(AutoEnd-AutoStart));
System.out.println("最后结果--"+longAdder.longValue()+"longAdder用时"+(addEnd-addStart));
}
}
加入主线程中然后…,又学一招
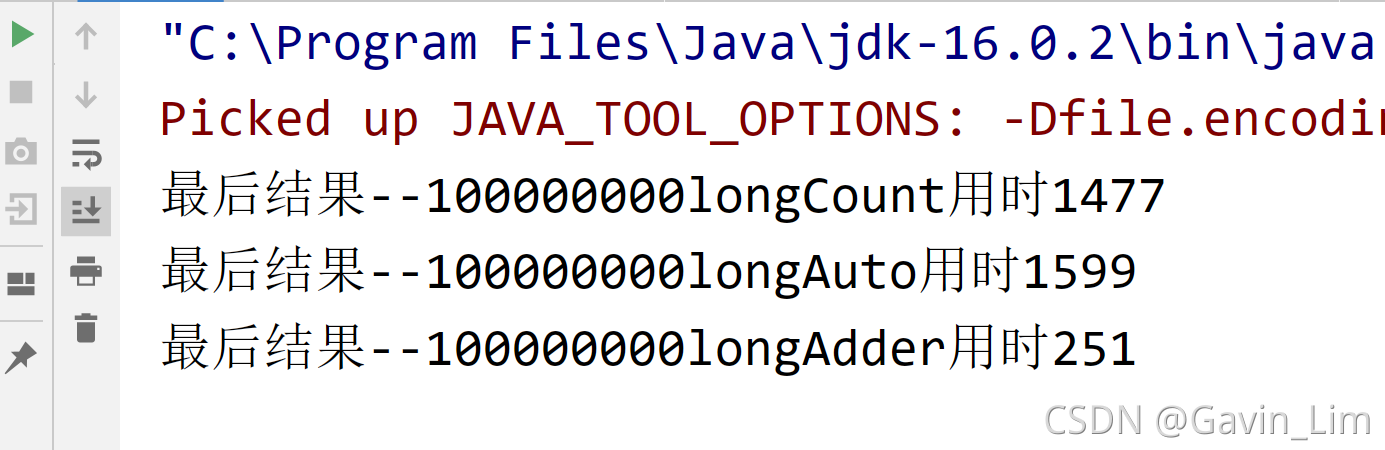 首先分析一下第一种,syc,应用了锁,所以当线程越累越多的时候,更多的线程在等待,又偏向锁到自旋锁再到重量级锁,会有一个锁升级的状态,用时会比较多
首先分析一下第一种,syc,应用了锁,所以当线程越累越多的时候,更多的线程在等待,又偏向锁到自旋锁再到重量级锁,会有一个锁升级的状态,用时会比较多
结局方法是加volatile,
结果看图----
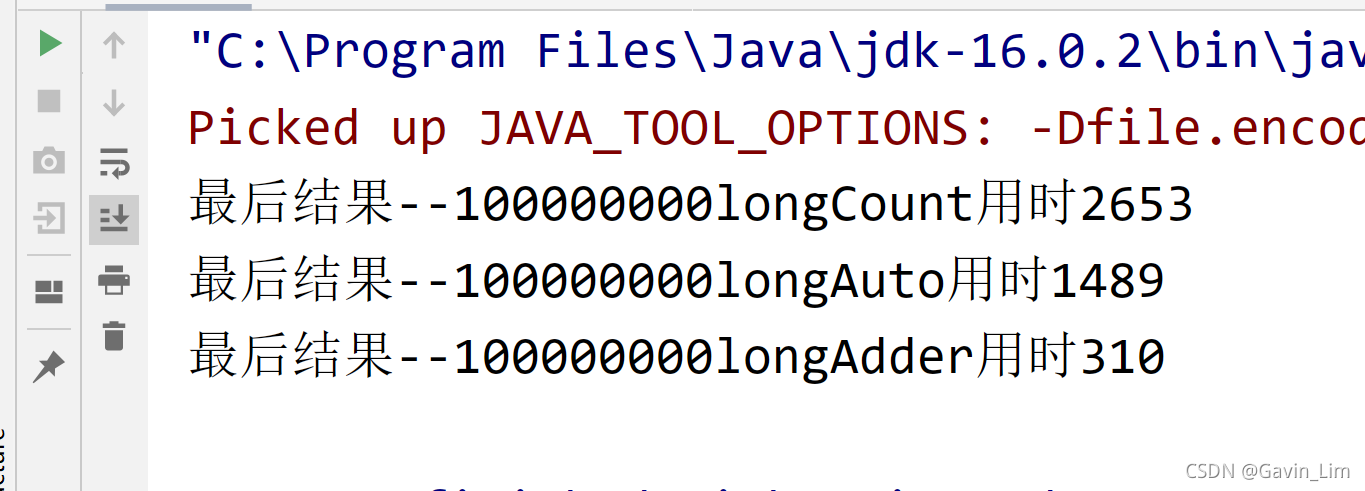
第二种CAS操作,相当于无锁,但为什么运行时间却比第一种多呢? 问题在于那个static long count 上,因为虽然是静态的,但是当一个线程修改完数据之后对其他线程是不可见的,等该线程将count写入到内存之后下一个线程才开始,这会耗费一定时间(当线程过多的时候,耗费的时间累计页不容小觑)
第三种为什么这么快?因为
LongAdder的内部做了一个分段锁,在它内部做运算的时候会将值放到一个数组里,比如说数组长度为4,最开始是0,1000个线程,250个线程被锁在第一个数组元素里,每一个都往上递增,算出来的结果加到一起
类似于这么一个效果
250个线程同时加1,在将结果加到一起,累加了250而不是一个线程自己累加250次;当然按照现在的处理器4核8线程,一次最多加8,但是也比只有一个线程拿到锁,一次加1累加8次快;
当线程数量级小或者循环的次数减少,三者的差距不会太大,如果都很多的话,LongAdder的效率是三者中高的;
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











