






前面学习了MongoDB,也只是一些入门的操作,后续还会继续深入学习
深入学习Hadoop,那么就需要了解Hadoop发展的历史沿革,就像学习历史一样;
当然一件事物被创作出来需要不断地发展才能完善;
Hadoop1.0
在Hadoop刚刚出来时,由于相关能力还不完善,所以会有一些缺陷,比如下面的几个方面:
- 抽象层次低
为什么这么说呢,你看现在我们使用Hadoop的时候只需要编写一个JAR文件就可以了,在hadoop1.0时候需要开发者自己管理各个作业之间的依赖关系所以Hadoop1.0时不像现在那样只需要关心jar怎么写(当然也可以使用其他语言编写处理逻辑,这里只是举个例子);
- 表达能力有限
表达能力有限是说什么呢?即使Hadoop的适用场景有限,像什么遗传算法~迭代计算等他是不适用的,因为他是通过Map处理完之后再通过reduce来处理,所以对于迭代计算,hadoop是不适用的;
- 实时性差
前面说了Map处理完之后,Reduce再来处理,所以他的实时性是较差的;
- 单点故障
由于那时候设计的只有一个主namenode节点(secondarynamenode并不是热备节点),所以当namenode节点出现故障时,整个系统就崩了;
- 隔离性
由于是单节点机制,所以对于命名空间上的隔离性就很差,
- 资源管理效率低下
对于资源的管理,1.0并没有提供很好的一套解决方案,往往需要开发人员去写代码实现,但这是不通用的;
所以hadoop2.0对以上的缺陷进行了改进;
Hadoop2.0
都改了些什么呢?
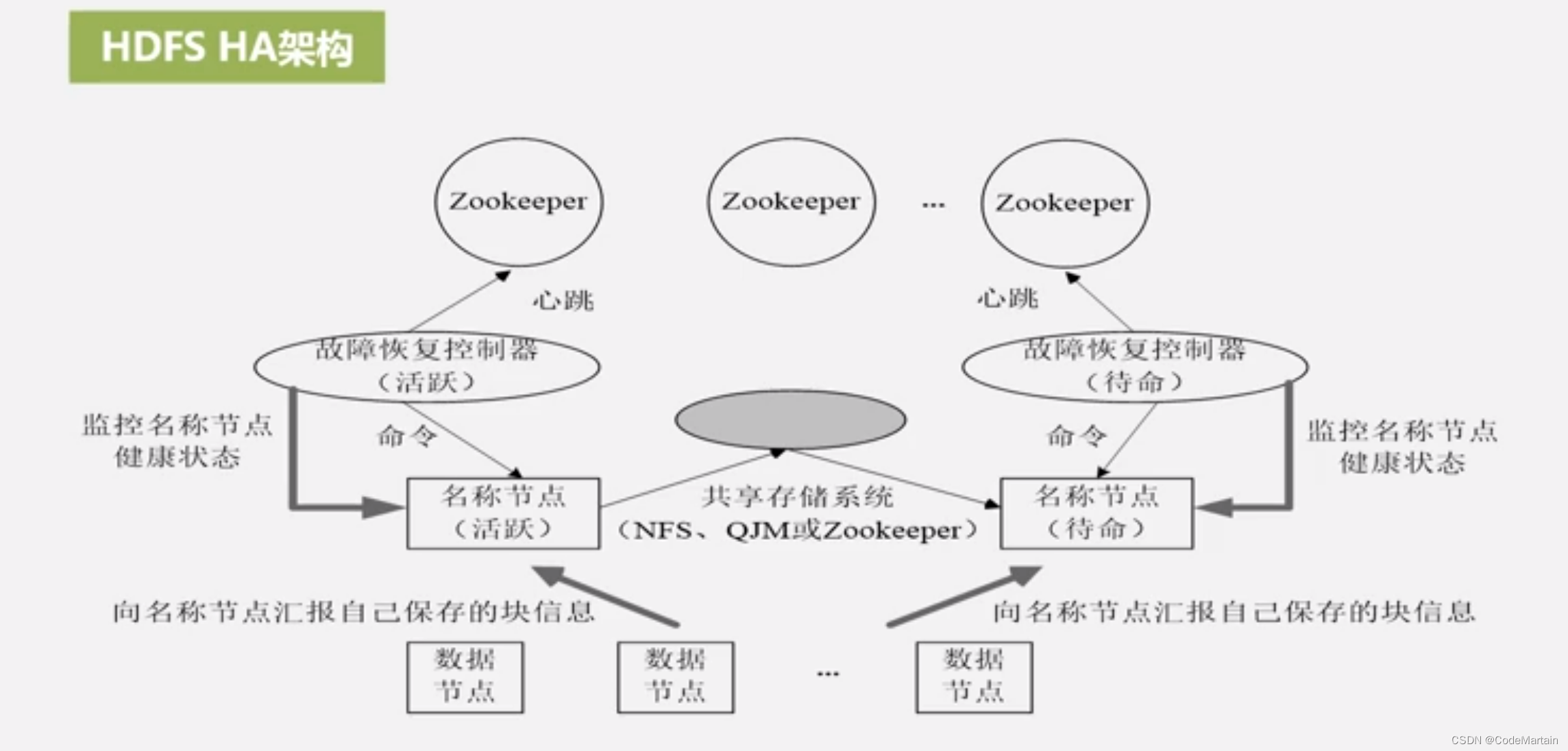
- 解决了单节点故障问题
对于namenode新增了一个热备份节点,通过zookeeper来监控节点状态以此来实现始终有一个节点处于活跃状态,另一个节点随时待命;
这两个节点之间是如何做到数据同步的?
通过共享内存空间实现了blockid的同步
然后是通过datanode实时向namenode汇报自己存储的块的信息
- 新增组件,丰富生态
对于hadoop1.0的缺陷,hadoop2.0又推出了相应的组件来解决1.0版本时候的一些缺陷;
| 新增组件 | 解决的问题 |
|---|---|
| pig | 处理大规模数据的脚本语言,解决了1.0版本需要自己编写代码去处理数据的问题 |
| spark | 基于内存的分布式并行编程框架,支持迭代计算,实时性计算能力得到了提升 |
| Oozie | 工作流和协调服务引擎,用于协调hadoop上不同的任务 |
| Tez | DAG计算框架,用于对作业实现分解,重新组合以减少重复作业的任务 |
| Kafka | 用于解决各个组件之间的数据交换 |
还有一个问题~那就是命名空间之间的隔离性;
- 命名空间隔离
Hadoop Fedoration机制解决了该问题:
该机制通过拆分原来一个命名空间为N个,这样保证了每个命名空间之间的隔离性,每个命名空间中的元数据被称为一个块池(即保存了指向每个块的所有数据,就像一个水池),但是底部存储空间大家是公用的;
简单的来说就是将原来一个命名空间切分成N份,每份都可用于寻址;
画个图看一下啊:
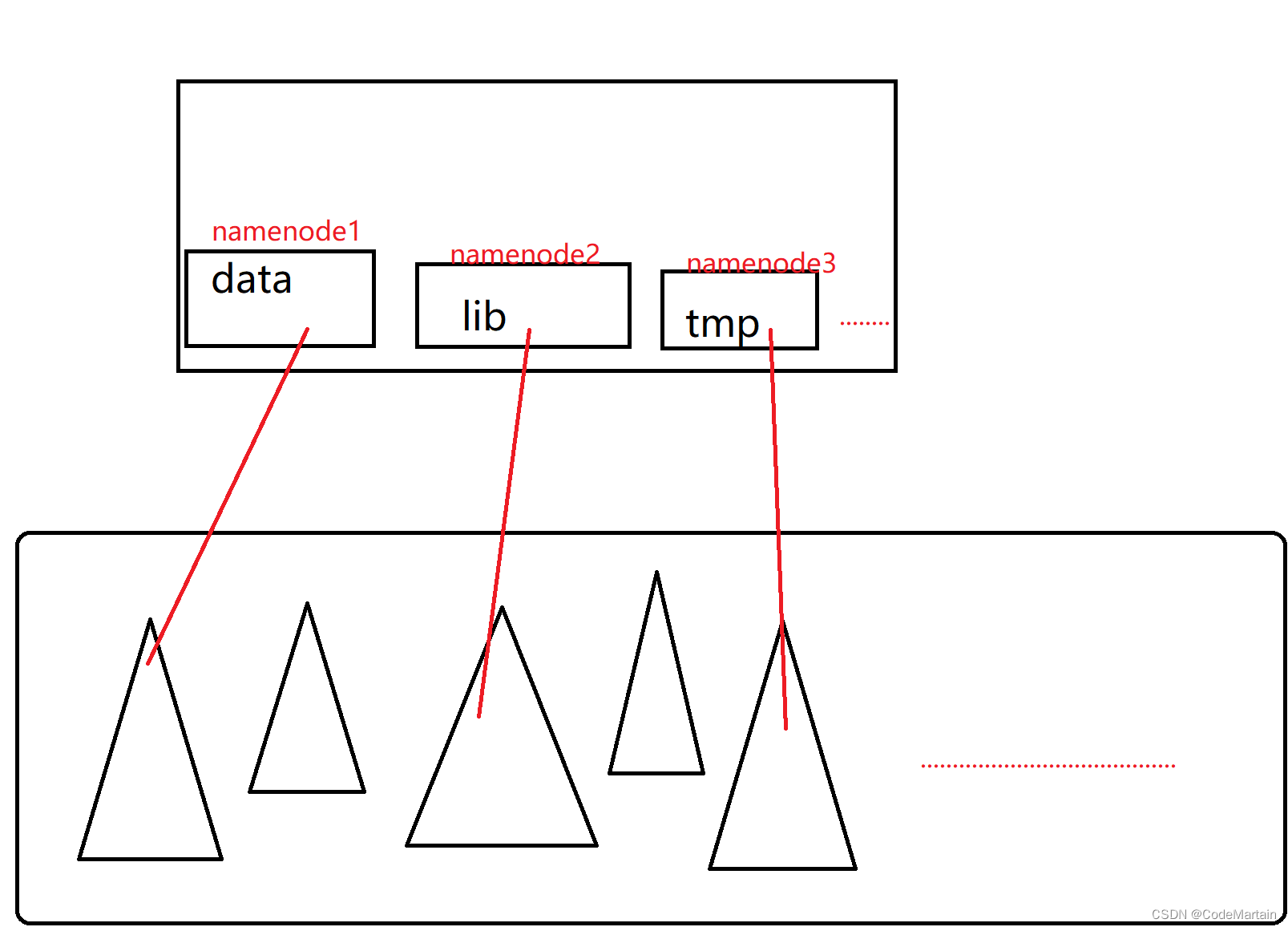
这一点就像是我们的文件系统,每一个文件夹下可以有不同的数据,只有通过这一个文件夹才能访问该数据,这就实现了命名空间之间的隔离性;
- 资源管理效率
hadoop1.0的时候通过jobtracker实现资源的分配,但是他跟namenode一样也是只有一个节点,这同样会出现单点故障的问题:

当任务过多的时候,jobtracker对任务的分配处理压力就很大了,根本处理不过来呀,(可能会出现内存溢出哦),如果任务出现故障还要负责任务的恢复…
有数据显示hadoop1.0版本中节点数量超过4000就很容易出现故障;
hadoop1.0中jobtracker对资源的划分单位为一个个slot(对内存和cpu的分配单位),map有map的slot,reduce有reduce的slot,同样是slot两者却不同通用,不能互用;
为了解决这个问题,推出了Yarn来管理资源
将原来hadoop1.0时候的jobtracker的能力进行拆分,拆分方案如下:
master端:将JobTRacker功能拆分成以下
- 资源管理~ResourceManager
- 任务调度 ~ApplicationMaster
- 任务监控~ApplicationMaster
slave端,将tasktracker替换为nodemanager
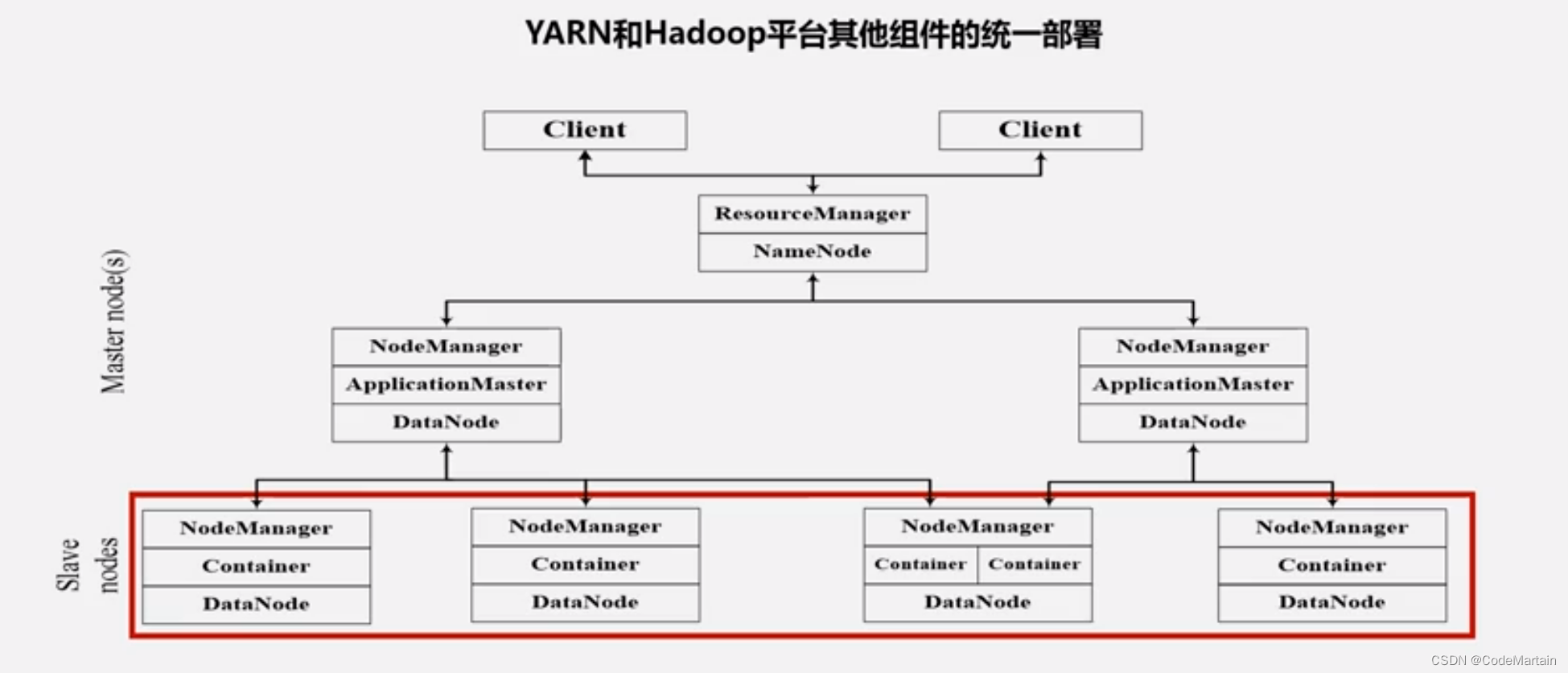
这样原来hadoop1.0的体系架构就被拆分成了下面这个样子:
hadoop(负责计算)+yarn(负责资源管理)
Yarn组件功能
ResourceManager
全局的资源管理器,负责整个系统的资源管理和分配,主要包括两个组件~调度器和应用程序管理器
- 处理客户端请求
- 启动/监控ApplicationMaster
- 监控NodeManager
- 资源分配与调度
调度器
调度器接受来自applicationmaster的应用程序资源请求,把集群中的资源以容器1的形式(1.0是一个个slot)分配给提出申请的应用程序,容器的选择会考虑应用程序所要处理的数据的位置,进行就近选择从而实现计算向数据靠拢
调度器被设计成一个可插拔的组件,允许用户自定义调度器;
应用程序管理器
管理所有应用程序的管理工作,主要包括应用程序提交,与调度器协调资源以
启动ApplicationMaster,
监控ApplicationMaster运行状态
在状态失败时重新启动;
ApplicationMaster作用
- 为程序申请资源,并分配给内部任务
- 任务调度,监控与容错,(请求发送们给ApplicationMaster,由ApplicationMaster向ResourceManager申请内存等资源,ResourceManager会以容器的形式向申请对象分配资源;
NodeManager作用
- 单个节点的资源管理器
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster命令
yarn集群中每个节点都有nodemanager,负责监控容器的生命周期;
Yarn体系结构
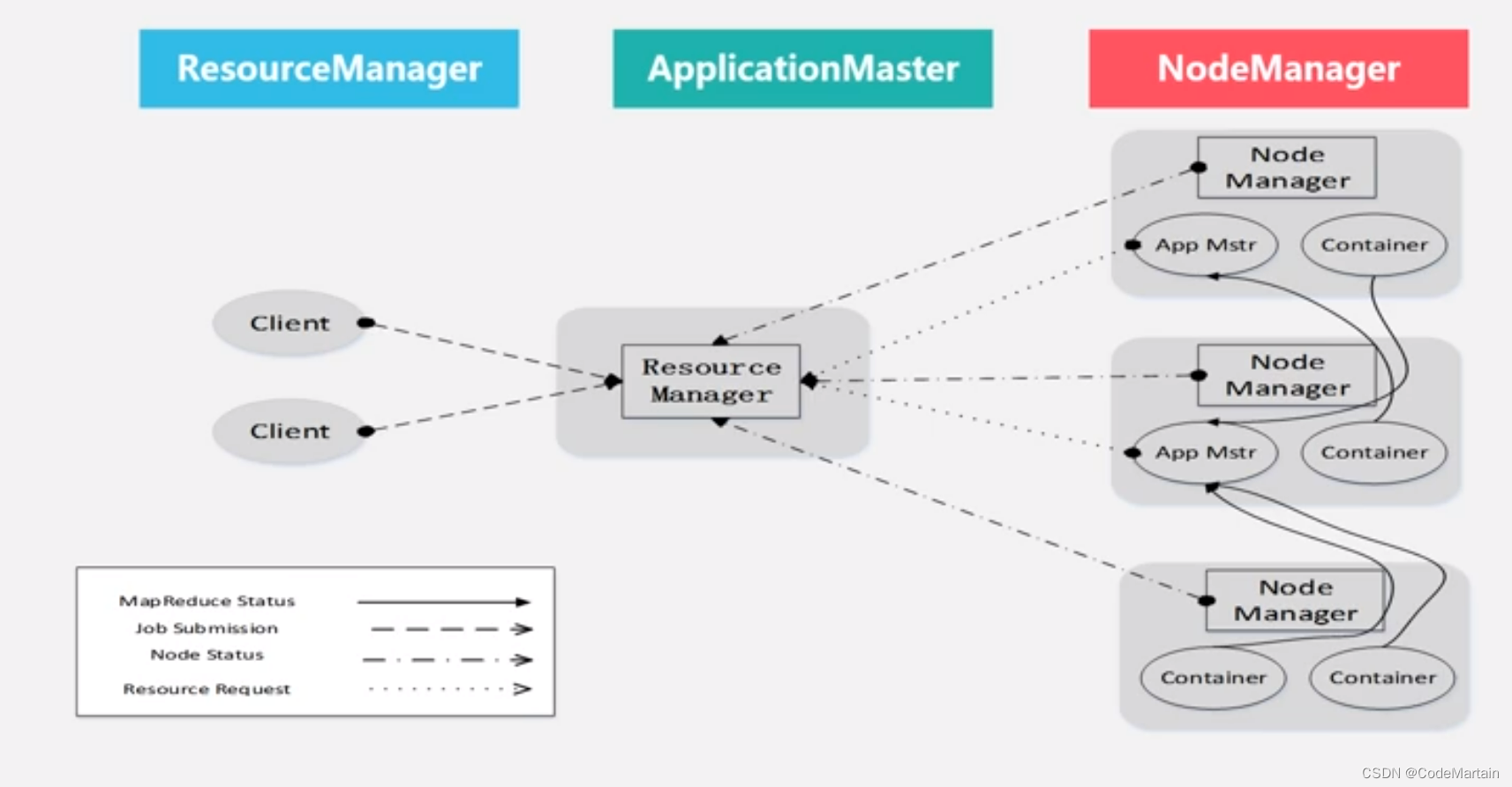
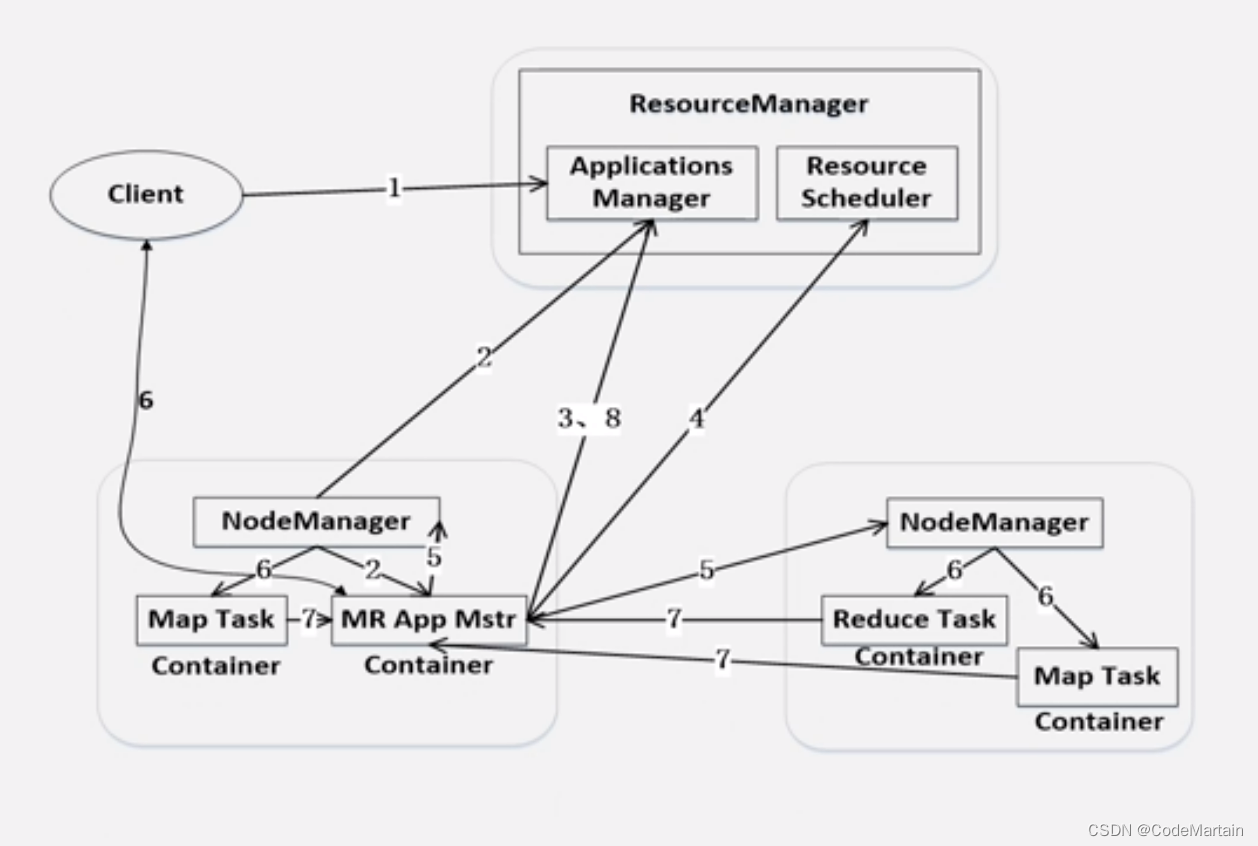
Yarn的工作流程
- 客户端向Yarn提交请求
- 应用程序
- applicationmaster程序
- 启动applicationmaster命令
- 分配容器
ResourceManager接受请求后为应用程序分配一个容器,然后在容器中启动一个ApplicationMaster
-
注册
Applicationmaster向ResourceManager注册,以使得RM能够获得容器的运行情况; -
申请资源
ApplicationMaster采用轮询的方式向RM申请资源 -
分配资源
容器资源分配给每一个任务(map/reduce) -
注销资源
任务运行完毕后,ApplicationMaster向ResourceManager管理器注销并关闭容器;
如下图所示:
Yarn的到来给Hadoop1.0版本带来了性能的提升:
- 减少了原来Jobtracker的功能挤压,减少了资源消耗
- 每个作业单独分配一个applicationmaster,由applicationmaster去管理容器的运行,不像jobtracker那样每个作业都管)根本管不过来)
- yarn框架是纯粹的资源调度管理框架,可以单独定制资源调度管理的方式(实现Applicationmaster即可)
Yarn资源管理框架,它不仅仅可以自定义资源管理调度方式,也可基于这个框架2运行各种其他的框架:
- 运行MR的批处理
- 运行流计算Storm
- 运行基于内存计算的Spark


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











