







tar -zxvf hadoop-2.7.2.tar.gz
mv hadoop-2.7.2.tar.gz hadoop
mv hadoop-2.7.2 /usr/local/src
我的虚拟机中将压缩包放到了chinaskills文件夹下,解压后将压缩包改名,移动路径,为后期配置环境变量提供方便。
- 配置
vi /usr/local/src/usr/hadoop/etc/hadoop/hadoop-ebv.sh
进入上述文件中找到“export JAVA_HOME",配置jdk的路径

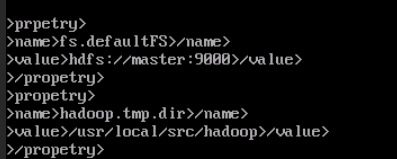
配置core-site.xml文件
<propetry>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</propetry>
<propetry>
<name>hadoop.tmp.dir</name>
</value>/usr/local/src/hdaoop</value>
</propetry>
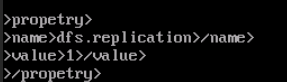
配置hdfs-site.xml文件
<propetry>
<name>dfs.replication</name>
<value>1</value>
</propetry>
配置yarn-site.xml文件
<propetry>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</propetry>
<peopetry>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</propetry>
<propetry>
<name>yarn.resourcemanger.scheduler.address</name>
<value>master:18030</value>
</propetry>
<propetry>
<me>yarn.resourcemanger.resource-tracker.address</name>
<value>master:18025</value>
</propetry>
<propetry>
<name>yarn.resourcemanger.admin.address</name>
<value>master:18141</value>
</propetry>
<propetry>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</propetry>

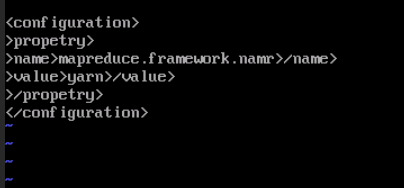
配置mapreduc文件
在当前目录下有一个mapred-site.xml.template文件,将其复制改名到当前文件夹下
cp mapred-site.xml.template mapred-site.xml
<propetry>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</propetry>
配置master中的slave文件(文件位置也在当前目录下)
将文件中的内容删除,并根据自己的搭建集群进行修改,我的子节点主机名分别为:slave1;slave2,在该文件下添加自己的子节点的主机名。
将master中的hadoop复制的子节点中
scp -r /usr/local/src/hadoop root@slave1:/usr/local/src
根据自己所配置的节点数进行复制,我在这子节点有两个,所以需要复制两次。
配置环境变量(主子节点都需要做)
vi /root/.bash_profile
#hadoop
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
退出保存后执行以下命令
source /root/.bash_profile
使上述配置生效

- 初始化Hadoop集群
进入到/hadoop/bin目录下
hadoop namenode -format
后遇到y or n直接选择y
如图所示

- 启动
在/hadoop/bin目录下启动
start-all.sh
- 查看节点
输入jps查看节点
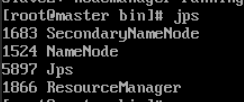
如上图所示,节点启动完成为成功















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









