






机器学习
计算机对一部分数据进行学习,得出某一模型,然后另外一些数据进行预测与判断
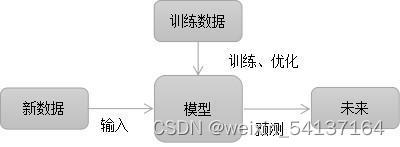
机器学习实际应用:垃圾邮件过滤,文本语音识别,网络引擎搜索,自动驾驶等
机器学习方法:监督学习,无监督学习,强化学习等
监督学习&无监督学习
基本流程
- 需求分析 构建问题 判断选择影响模型的具体因素
- 数据采集 收集所需数据
- 数据预处理 清洗数据 分为训练集,验证集,测试集
- 特征工程(?)
- 模型训练:训练模型
- 模型评估 评估模型 模型优化参数调整 预测新样本数据
监督学习
给学习算法一个标记了正确答案的数据集进行学习
算法可以由标记好的训练集中学到或建立一个模式(函数 / learning model),并依此模式推测新的实例
训练集是由一系列的训练范例组成,每个训练范例则由输入对象(通常是向量)和预期输出所组成
函数的输出可以是一个连续的值(称为回归分析),或是预测一个分类标签(称作分类)
分类与回归
定量输出称为回归,或者说是连续变量预测;
定性输出称为分类,或者说是离散变量预测。
例子:
预测明天的气温是多少度,这是一个回归任务;
预测明天是阴、晴还是雨,就是一个分类任务。
连续数据:能无限细分的叫做连续型,比如长度,重量,温度
离散数据:不能无限细分的就叫离散型,比如序号1~20
对连续型数据可以求算术平均,离散型就不可以
主流的监督学习算法
分类:K邻近,决策树,朴素贝叶斯,逻辑回归,SVM,,Adaboosting,神经网络
回归:K邻近,线性回归,回归树,Adaboosting,神经网络
无监督学习
不对已知数据集进行处理,算法可以在在没有标签的数据里可以发现潜在的一些结构
- 无监督学习没有明确的目的
- 无监督学习不需要给数据打标签
- 无监督学习无法量化效果
聚类与降维
聚类:无监督学习能把数据集分为n个簇,即相似数据分为一组,分类结果需要人为判断和定义
降维:无监督降维是特征预处理中一种常用方法,用在数据预处理中,保留大部分相关信息的同时将数据压缩到较小维数的子空间上,可以降低对计算机性能的压力
分类模型评估指标
准确率 :预测正确的结果占总样本的百分比,样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效
Accuracy =(TP+TN)/(TP+TN+FP+FN)
精准率:所有被预测为正的样本中实际为正的样本的概率,精准率代表对正样本结果中的预测准确程度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
Precision=TP/(TP+FP)
召回率:实际为正的样本中被预测为正样本的概率
Recall=TP/(TP+FN)
TP:实际为正判断为正
FN:实际为正判断为负 (漏报)
FP:实际为负判断为正 (误报)
TN:实际为预负测为负
例子:有5个正样本,5个负样本,系统查找出4个正样本,6个负样本,其中只有3个是真正的正样本,计算上述各指标
TP:3 FN:2 FP:1 TN:3
F1分数:在精确率(Precision)和召回率(Recall)之间找到一个平衡点
F1=(2×Precision×Recall)/(Precision+Recall)
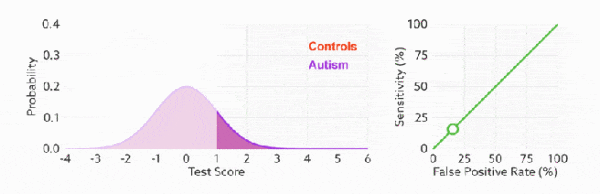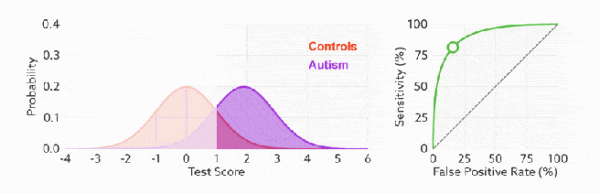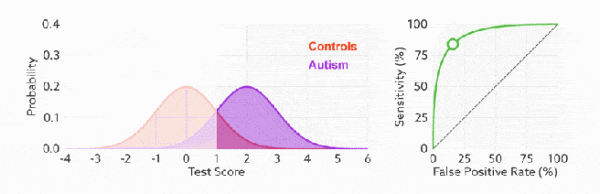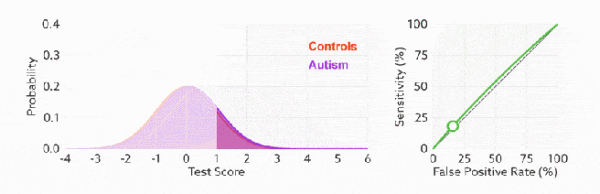
ROC曲线
真正率(TPR)=灵敏度(Sensitivity) = TP/(TP+FN)
假正率(FPR)=1-特异度(Specificity) = TN/(FP+TN)
- 灵敏度=召回率
- 由于我们比较关心正样本,所以需要查看有多少负样本被错误地预测为正样本,所以使用(1- 特异度),而不是特异度
ROC曲线主要指标TPR和FPR可以无视样本不平很的问题
判断ROC曲线的好坏
通过不断改变预测的正样本负样本数,遍历所有阈值来绘制整条曲线,TPR越高同时FPR越低那么模型性能就越好(ROC曲线越陡性能越好)
AUC ROC曲线下的面积
ROC 曲线越陡越好,所以理想值就是 1,一个正方形,而最差的随机判断都有 0.5,所以一般 AUC 的值是介于 0.5 到 1 之间的
AUC 的一般判断标准
0.5 – 0.7: 效果较低
0.7 – 0.85: 效果一般
0.85 – 0.95: 效果很好
0.95 – 1: 效果非常好
强化学习
通过一系列与环境的交互来得到最大的正面奖励,每种状态都有对应的正负奖励
举例:Alpha go
计算机从0开始,通过不断尝试从错误中学习,最后找到规律,学会了达到目的的方法
强化学习的反馈并非标定过的正确标签或数值,而是奖励函数对行动的度量
数据集
-训练集-验证集-测试集
训练集:训练集(Training Dataset)训练模型时使用
验证集:当我们的模型训练好之后,就可以使用验证集(Validation Dataset)来看看模型在新数据(验证集和测试集是不同的数据)上的表现如何。同时通过调整超参数,让模型处于最好的状态。
验证集有2个主要的作用:
- 评估模型效果,为了调整超参数而服务
- 调整超参数,使得模型在验证集上的效果最好
说明:
- 验证集不像训练集和测试集,它是非必需的。如果不需要调整超参数,就可以不使用验证集,直接用测试集来评估效果。
- 验证集评估出来的效果并非模型的最终效果,主要是用来调整超参数的,模型最终效果以测试集的评估结果为准。
测试集:当我们调好超参数后,通过测试集(Test Dataset)来做最终的评估,通过测试集的评估,我们会得到一些最终的评估指标,例如:准确率、精确率、召回率、F1等
交叉验证法
留出法(Holdout cross validation)
按照固定比例将数据集静态的划分为训练集、验证集、测试集。的方式就是留出法
划分可以参考以下三个原则:
- 对于小规模样本集(几万量级),常用的分配比例是 60% 训练集、20% 验证集、20% 测试集。
- 对于大规模样本集(百万级以上),只要验证集和测试集的数量足够即可,例如有 100w 条数据,那么留 1w 验证集,1w 测试集即可。1000w 的数据,同样留 1w 验证集和 1w 测试集。
- 超参数越少,或者超参数很容易调整,那么可以减少验证集的比例,更多的分配给训练集
留一法(Leave one out cross validation)
每次的测试集都只有一个样本,要进行 m 次训练和预测。 这个方法用于训练的数据只比整体数据集少了一个样本,因此最接近原始样本的分布。但是训练复杂度增加了,因为模型的数量与原始数据样本数量相同。 一般在数据缺乏时使用。
k 折交叉验证(k-fold cross validation)
静态的「留出法」对数据的划分方式比较敏感,有可能不同的划分方式得到了不同的模型。「k 折交叉验证」是一种动态验证的方式,这种方式可以降低数据划分带来的影响。具体步骤如下:
- 将数据集分为训练集和测试集,将测试集放在一边
- 将训练集分为 k 份
- 每次使用 k 份中的 1 份作为验证集,其他全部作为训练集。
- 通过 k 次训练后,我们得到了 k 个不同的模型。
- 评估 k 个模型的效果,从中挑选效果最好的超参数
- 使用最优的超参数,然后将 k 份数据全部作为训练集重新训练模型,得到最终模型。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









