







4.SpringBoot集成Kafka
文章目录
来源参考的deepseek,如有侵权联系立删
1.入门示例
1.pom依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2.KafkaProducer消息生产者配置
@Component
@Slf4j
public class KafkaProducer {
private HashMap map=new HashMap<>();
@Autowired
private KafkaTemplate<Integer,String> kafkaTemplate;
public void send(String topic,String msg){
log.info("开始发送消息,topic:{};message:{}",topic,msg);
ListenableFuture<SendResult<Integer,String>> send=kafkaTemplate.send(topic, msg);
//消息确认机制
send.addCallback(new ListenableFutureCallback<SendResult<Integer,String>>(){
@Override
public void onSuccess(SendResult<Integer, String> result) {
log.info("消息发送成功,topic:{};message:{}",topic,msg);
}
@Override
public void onFailure(Throwable ex) {
//落库操作
map.put(topic,msg);
}
});
}
}
springboot3.x写法
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import lombok.RequiredArgsConstructor;
@Service
@RequiredArgsConstructor
public class KafkaProducerService {
private final KafkaTemplate<String, String> kafkaTemplate;
// 同步发送(阻塞等待确认)
public void sendMessageSync(String topic, String key, String value) {
kafkaTemplate.send(topic, key, value).whenComplete((result, ex) -> {
if (ex == null) {
System.out.printf("发送成功:topic=%s, partition=%d, offset=%d%n",
result.getRecordMetadata().topic(),
result.getRecordMetadata().partition(),
result.getRecordMetadata().offset());
} else {
System.err.println("发送失败:" + ex.getMessage());
}
});
}
// 异步发送(默认方式)
public void sendMessageAsync(String topic, String message) {
kafkaTemplate.send(topic, message);
}
}
- Spring Boot 2.x:
send()返回ListenableFuture<SendResult>,支持addCallback()回调。 - Spring Boot 3.x:
send()返回CompletableFuture<SendResult>,弃用ListenableFuture,因此需要使用CompletableFuture的 API(如whenComplete)。
3.KafkaConsumer消息消费
@Component
@Slf4j
public class KafkaConsumer {
private List<String> exist=new ArrayList<>();
@KafkaListener(topics = {"lx"},groupId = "lx")
public void consumer(ConsumerRecord<Integer,String> record){
if (exist.contains(record.value())){
log.error("不满足幂等校验!!!");
}
log.info("消息消费成功,topic:{},message:{}", record.topic(), record.value());
exist.add(record.value());
}
}
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
@Component
public class KafkaConsumerService {
// 单个消息消费(手动提交偏移量)
@KafkaListener(topics = "test-topic", groupId = "spring-group")
public void listenMessage(String message, Acknowledgment ack) {
System.out.println("收到消息:" + message);
ack.acknowledge(); // 手动提交
}
// 批量消费(需配置 listener.type=batch)
@KafkaListener(topics = "batch-topic", groupId = "spring-group")
public void listenBatch(List<String> messages, Acknowledgment ack) {
messages.forEach(msg -> System.out.println("批量消息:" + msg));
ack.acknowledge();
}
}
4.yml配置文件
生产者配置
#kafka配置
spring:
kafka:
#kafka集群地址
# bootstraps-server: 192.168.25.100:9092
bootstrap-servers: 192.168.25.100:9092
producer:
#批量发送的数据量大小
batch-size: 1
#可用发送数量的最大缓存
buffer-memory: 33554432
#key序列化器
key-serializer: org.apache.kafka.common.serialization.StringSerializer
#value序列化器
value-serializer: org.apache.kafka.common.serialization.StringSerializer
#达到多少时间后,会发送
properties:
linger.ms: 1
# 禁止生产者触发 Topic 创建请求
allow.auto.create.topics: false
#代表集群中从节点都持久化后才认为发送成功
acks: -1
消费者配置
spring:
kafka:
#kafka集群地址
bootstraps-server: 192.168.25.100:9092
consumer:
enable-auto-commit: false
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
properties:
session.timeout.ms: 15000
# 禁用生产者触发 Topic 元数据请求时自动创建
allow.auto.create.topics: false
group-id: test
auto-offset-reset: earliest
listener:
ack-mode: manual_immediate # 精准控制offset提交
concurrency: 3 # 并发消费者数
type: batch
5.实体类
@Data
public class KafkaRequest {
/**
* 主题
*/
private String topic;
/**
* 消息
*/
private String message;
}
6.消息发送
@RestController
@Slf4j
public class KafkaController {
private final String topic="lx";
private int temp=1;
@Autowired
private KafkaProducer producer;
/**
* 下单
*
* @param kafkaRequest
* @return null
*/
@RequestMapping("/test01")
public void test01(KafkaRequest kafkaRequest){
log.info("test01测试成功!topic:{};message:{}",kafkaRequest.getTopic(), kafkaRequest.getMessage());
producer.send(kafkaRequest.getTopic(), kafkaRequest.getMessage());
}
@RequestMapping("/test02")
public void test02(KafkaRequest kafkaRequest){
log.info("test02测试成功!topic:{};message:{}",topic, temp);
producer.send(topic, String.valueOf(temp));
temp++;
}
}
kafka启动方式
./kafka-server-start.sh ../config/server.properties
2.yml完整配置
spring:
kafka:
# 基础配置(必填项)
bootstrap-servers: localhost:9092 # Kafka集群地址,多节点用逗号分隔
client-id: spring-boot-app # 客户端标识(日志追踪用)
# 生产者配置
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 键序列化器
value-serializer: org.apache.kafka.common.serialization.StringSerializer # 值序列化器
acks: all # 消息确认机制:all表示所有副本确认(最高可靠性)
retries: 5 # 发送失败重试次数(需配合幂等性使用)
batch-size: 16384 # 批量发送缓冲区大小(单位:字节)
linger-ms: 50 # 发送延迟等待时间(毫秒,提高吞吐量)
buffer-memory: 33554432 # 生产者内存缓冲区大小(默认32MB)
compression-type: snappy # 消息压缩算法(可选gzip/lz4/zstd)
transaction-id-prefix: tx- # 开启事务时需配置前缀(需配合@Transactional)
# 消费者配置
consumer:
group-id: app-consumer-group # 消费者组ID(同一组共享分区)
auto-offset-reset: earliest # 无Offset时策略:earliest(从头)/latest(最新)
enable-auto-commit: false # 关闭自动提交Offset(推荐手动提交)
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
max-poll-records: 500 # 单次poll最大消息数(避免OOM)
fetch-max-wait-ms: 500 # 消费者等待broker返回数据的最长时间
isolation-level: read_committed # 事务消息隔离级别(read_committed/read_uncommitted)
# 监听器配置(高级优化)
listener:
type: single # 监听器类型:single(单条)/batch(批量)
ack-mode: manual # Offset提交模式:manual(手动)/batch(批量提交)
concurrency: 3 # 消费者线程数(建议等于分区数)
poll-timeout: 3000 # poll方法超时时间(毫秒)
# 消息重试与死信队列(容错机制)
retry:
topic:
attempts: 3 # 最大重试次数
initial-interval: 1000 # 初始重试间隔(毫秒)
multiplier: 2.0 # 重试间隔倍数(指数退避)
dead-letter-topic: dlq-${topic} # 死信队列命名规则(自动创建)
# 安全协议(企业级场景)
properties:
security.protocol: SASL_PLAINTEXT # 安全协议(如PLAINTEXT/SASL_SSL)
sasl.mechanism: PLAIN # SASL认证机制
ssl.truststore.location: /path/to/truststore.jks
# 自定义业务配置(非Kafka标准参数)
app:
kafka:
topics:
input-topic: user-events # 业务输入Topic
output-topic: processed-events # 业务输出Topic
3.关键配置注释说明
1. 生产者优化参数
| 参数 | 说明 | 推荐值 |
|---|---|---|
acks=all | 确保所有ISR副本写入成功,防止数据丢失 | 高可靠性场景必选 |
compression-type=snappy | 减少网络带宽占用,提升吞吐量 | 消息体>1KB时启用 |
transaction-id-prefix | 支持跨分区原子性写入(需配合@Transactional注解) | 金融交易类业务必配 |
2. 消费者可靠性配置
| 参数 | 说明 | 注意事项 |
|---|---|---|
enable-auto-commit=false | 避免消息处理失败但Offset已提交导致数据丢失 | 需手动调用ack.acknowledge() |
isolation-level=read_committed | 只消费已提交的事务消息 | 需与生产者事务配置联动 |
3. 监听器高级特性
| 参数 | 使用场景 | 示例 |
|---|---|---|
type=batch | 批量消费(提升吞吐量) | 适用于日志处理等实时性要求低的场景 |
concurrency=3 | 并发消费者数 | 需与Topic分区数一致,避免资源浪费 |
4. 安全认证配置
spring:
kafka:
properties:
security.protocol: SASL_PLAINTEXT
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="secret";
4.配置验证方法
- 启动检查:添加
@ConfigurationProperties(prefix = "spring.kafka")绑定配置到Bean,通过单元测试验证注入值 - 日志监控:开启DEBUG日志观察生产者/消费者连接状态
logging:
level:
org.springframework.kafka: DEBUG
- AdminClient 工具:通过编程方式检查Topic元数据
@Autowired
private KafkaAdminClient adminClient;
public void checkTopic() {
Map<String, TopicDescription> topics = adminClient.describeTopics("user-events");
topics.values().forEach(topic -> System.out.println(topic));
}
5.高级配置
1.事务支持
// 配置事务管理器
@Bean
public KafkaTransactionManager<String, String> transactionManager(
ProducerFactory<String, String> producerFactory) {
return new KafkaTransactionManager<>(producerFactory);
}
// 使用事务发送
@Transactional
public void sendWithTransaction() {
kafkaTemplate.send("topic1", "msg1");
kafkaTemplate.send("topic2", "msg2");
}
2.消息重试与死信队列
1. 手动发送到自己创建的普通队列DLQ
@KafkaListener(topics = "payments")
public void handlePayment(PaymentEvent event, Acknowledgment ack) {
try {
paymentService.process(event);
ack.acknowledge();
} catch (InvalidPaymentException ex) {
// 手动发送到DLQ
kafkaTemplate.send("dlq-payments", event);
ack.acknowledge(); // 避免重复消费
}
}
2.通过@RetryableTopic重试注解实现
1.创建自定义容器工厂
由于@RetryableTopic注解不支持批量消费,所以手动创建一个工厂
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> batchAckContainerFactory(
ConsumerFactory<String, String> consumerFactory) {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
factory.setBatchListener(false); // 禁用批处理模式
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL); // 手动提交偏移量
return factory;
}
2.消息失败重试及死信消费者
/**
* kafka消费者重试(死信队列)
*/
@Slf4j
@Component
public class KafkaMQListener {
/**
* RetryableTopic注解不支持batch消费
* 可以不用配置DeadLetterPublishingRecoverer通过该注解配置死信队列
* attempts:重试次数
* @Backoff delay:消费延迟时间,单位为毫秒。
* @Backoff multiplier:延迟时间系数,此例中 attempts = 3, delay = 5000, multiplier = 2 ,
* 则间隔时间依次为5s、10s、20s、40s,最大延迟时间受 maxDelay 限制。
* fixedDelayTopicStrategy:可选策略包括:SINGLE_TOPIC 、MULTIPLE_TOPICS
* SINGLE_TOPIC:所有重试使用同一主题。但不能配置 multiplier,否则不会生成单一主题
* MULTIPLE_TOPICS:每次重试使用独立主题(默认)
*/
@KafkaListener(topics = {"dlxTopic"}, groupId = "dlxConsumer",containerFactory = "batchAckContainerFactory")
@RetryableTopic(
attempts = "3",
backoff = @Backoff(delay = 1000),
fixedDelayTopicStrategy = FixedDelayStrategy.SINGLE_TOPIC
)
public void listener(ConsumerRecord<String, String> record, Acknowledgment acknowledgment) {
// 获取消息体
String message = record.value();
log.info("收到测试消息,message = {}, record={},topic={}", message, JSONObject.toJSONString(record),record.topic());
throw new BusinessException();
}
/**
* 死信消费者,超过重试次数的消息,会进入死信队列,死信队列统一由一个消费者进行消费。
*/
@DltHandler
public void dltHandler(ConsumerRecord<String, String> record, Acknowledgment acknowledgment) {
String topic = record.topic();
log.info("进入死信队列 topic={}, value={}", record.topic(),record.value());
acknowledgment.acknowledge();
}
/**
* 死信队列消费者。写法二
*
* @param value 消息主体
* @param topic 主题
* @param offset 偏移量
*/
//@DltHandler
public void dltHandler2(String value,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(KafkaHeaders.OFFSET) long offset) {
log.error("死信队列:{},from {} offset {}", value, topic, offset);
}
}
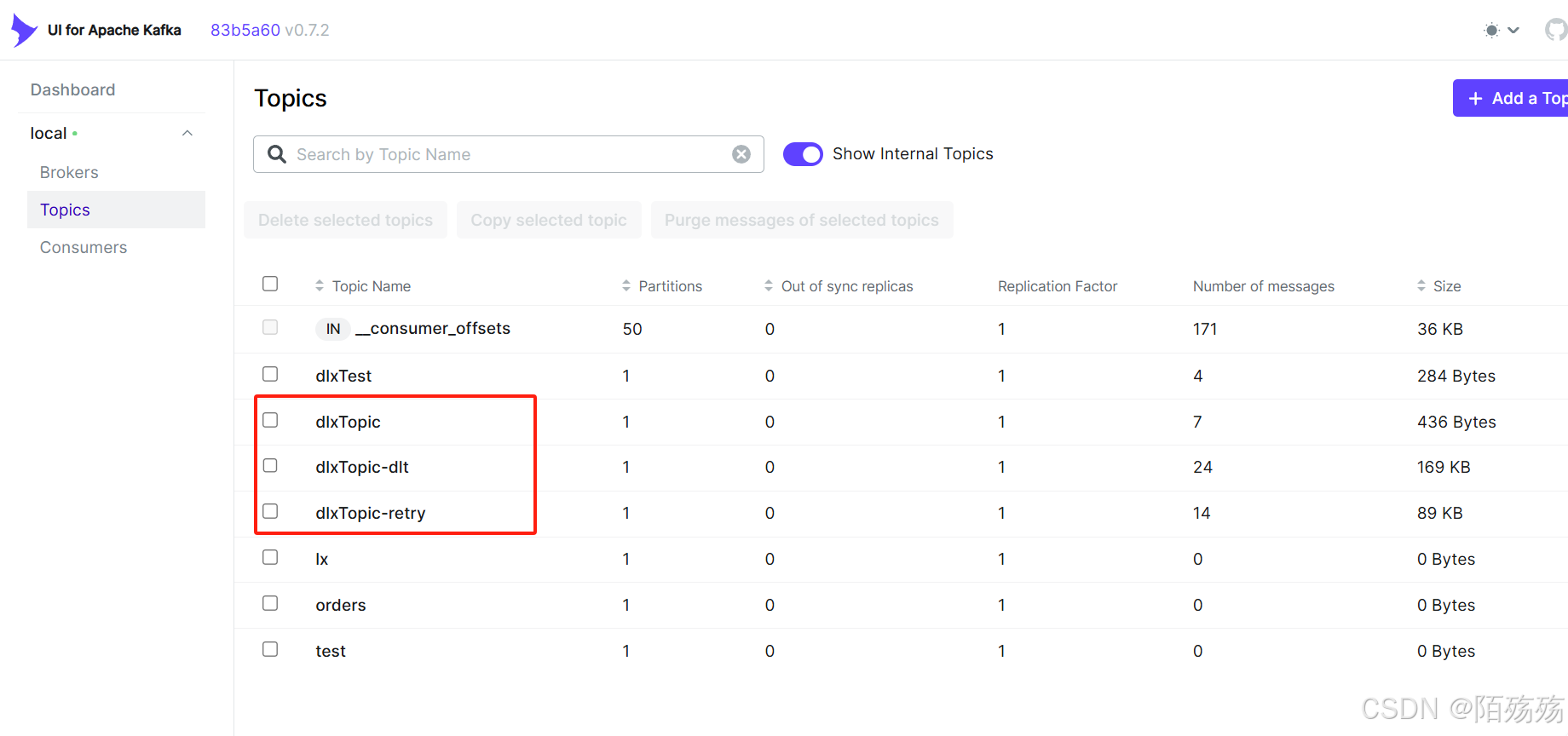

3.全局异常消费重试及死信队列配置
@Configuration
public class KafkaGlobalErrorConfig {
/**
* 死信队列配置方式1
* 定义全局错误处理器(支持批量/单消息模式),重试三次进死信
*/
@Bean
public CommonErrorHandler globalErrorHandler(KafkaTemplate<String, Object> template) {
// 创建 DeadLetterPublishingRecoverer 并定义死信主题命名策略
DeadLetterPublishingRecoverer recover = new DeadLetterPublishingRecoverer(
template,
(consumerRecord, exception) -> {
// 自定义死信主题名称,例如在原主题名后追加 "-dlq",默认后缀.DLT
return new TopicPartition(consumerRecord.topic() + "-dlq", consumerRecord.partition());
}
);
// 配置错误处理器
// 最大重试3次后进入死信队列
DefaultErrorHandler handler = new DefaultErrorHandler(
recover, // 死信队列恢复器
new FixedBackOff(1000L, 3)
);
// 指定可重试异常类型
handler.addRetryableExceptions(NetworkException.class);
handler.addNotRetryableExceptions(SerializationException.class);
// 偏移量提交策略
handler.setCommitRecovered(true);
return handler;
}
/**
* 死信队列配置方式2
*/
//@Bean
//@Primary
public DefaultErrorHandler kafkaErrorHandler(KafkaTemplate<?, ?> template) {
return new DefaultErrorHandler(
new DeadLetterPublishingRecoverer(template), // 死信队列恢复器
new FixedBackOff(1000L, 3)
);
}
}


















 9470
9470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









