







缓存三兄弟(穿透、击穿、雪崩)
本文主要讲解缓存穿透、缓存击穿、缓存雪崩的概念及相关实例,如布隆过滤器的使用、互斥锁的实现等。同时是自我的成果,希望能帮助到各位。有不对的地方,欢迎指出。
缓存
“缓存的原始意义,是指访问速度比一般随机存取存储器快的一种高速存储器。 简单来说,缓存就是数据交换的缓冲区。当我们的硬件需要读取数据的时候,一般会先在缓存中查找想要的数据,这样速度比较快。如果找不到的话,就会在内存中查找,但这样会降低电脑的运行速度。所以缓存的作用,就是帮助我们的电脑更快的运行。可以说缓存的设置,是所有计算机系统可以发挥高性能的重要因素之一。”
缓存穿透
定义:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查到数据库。
通常情况下,我们使用redis的流程为:
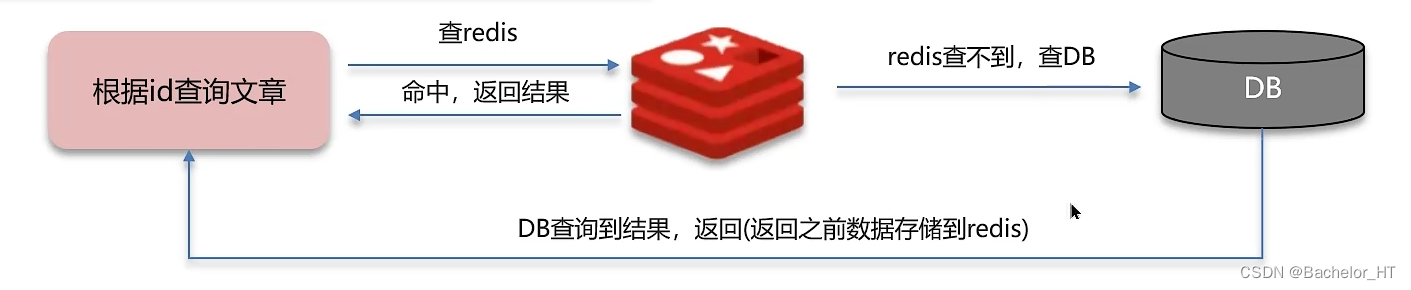
但这种情况考虑不周,所有为了应对缓存穿透的情况我们有两种解决方式:
-
缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存
- 优点:简单
- 缺点:消耗内存,而且可能会导致不一致的问题
-
使用布隆过滤器
- 优点:内存占用少,没有多余的key
- 缺点:实现复杂,存在误判
其流程图如下:
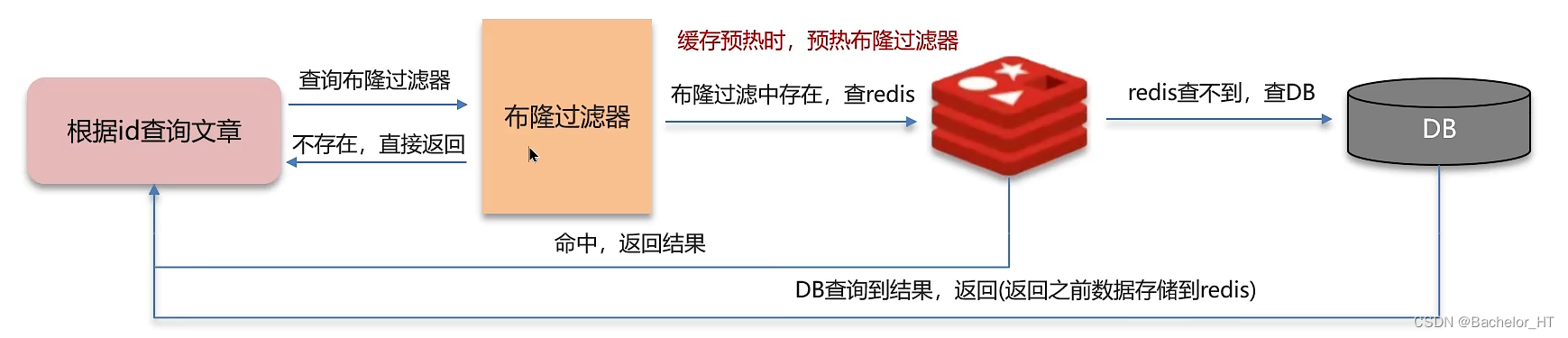
布隆过滤器
首先,我们需要引入一个知识点:
位图(bitmap):相当于一个以(bit)位为单位的数组,数组中每个单元智能存储二进制数0或1;
布隆过滤器存储数据时,会通过多个hash函数获取hash值,根据hash计算数组对应位置改为1。查询数据时,使用相同的hash函数获取hash值,判断对应位置是否都为1,如果是,则该数据存在redis中;反之,不在,需要访问DB。这种情况会存在误判的情况,如下:
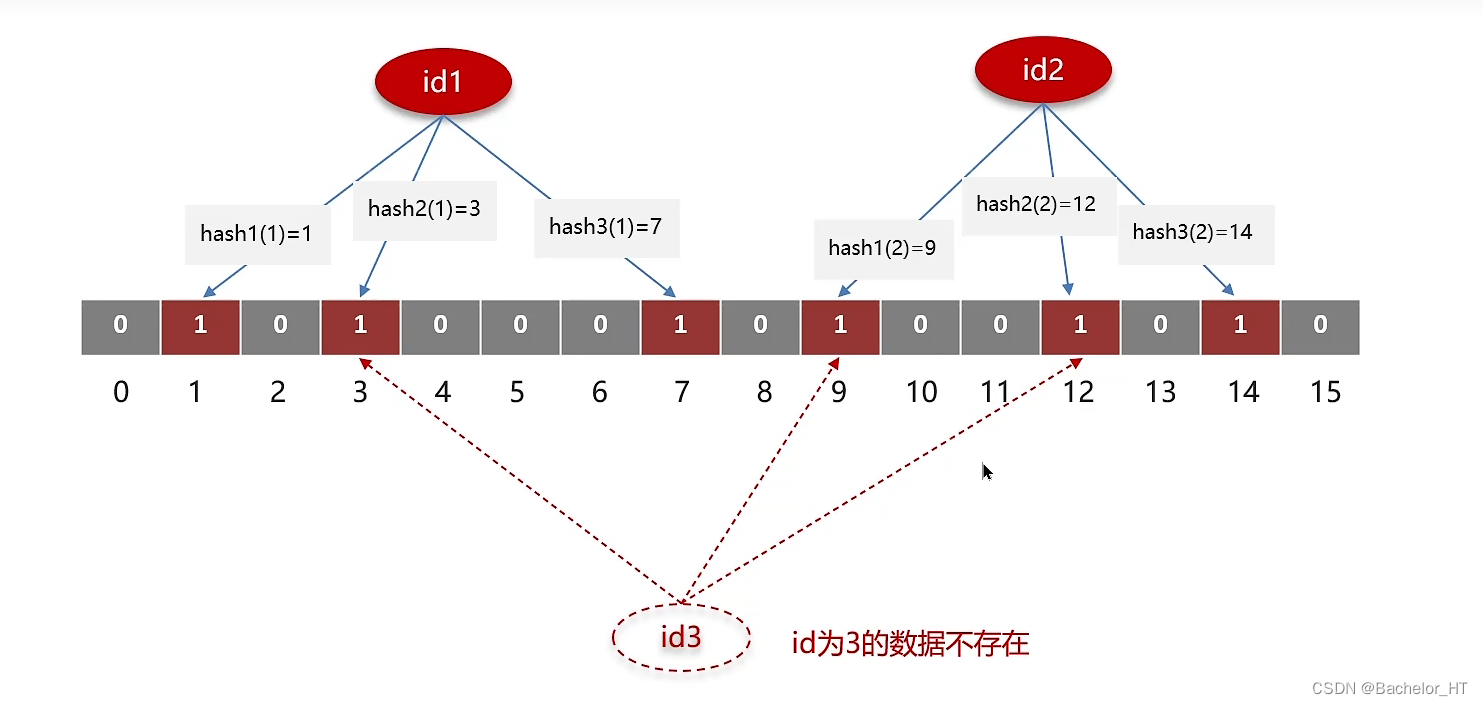
若查询一个不存在的数据:id=3。经过hash函数3次计算后得出的hash值恰好均为1,这时布隆过滤器失败,redis就会访问DB。为了解决这种情况我们可以增大数组长度(会带来更多内存消耗)。
布隆过滤器的使用
布隆过滤器目前有3种实现方式
- google的 guava
- redisson
- redis的 reBloom.so插件
这里我们使用Redisson来实现
依赖引入
在pom.xml文件中引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.10.6</version>
</dependency>
代码实现
@Service
public class BloomFilterService{
@Autowired
private RedissonClient redissonClient;
private static long size = 10000000L;//预计要插入多少数据
private static double fpp = 0.05;//期望的误判率
// 自定义布隆过滤器的 key
private String BLOOM_FILTER_KEY = "BachelorHT";
/**
*
* 向布隆过滤器中添加数据, 模拟向布隆过滤器中添加10亿个数据
*/
public void addToBloomFilter() {
// 获取布隆过滤器
RBloomFilter<Integer> bloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_KEY);
// 初始化,容量为10亿, 误判率为0.05
bloomFilter.tryInit(size,fpp);
// 模拟向布隆过滤器中添加10亿个数据
for (int i = 1; i <= size; i++) {
bloomFilter.add(i);
}
}
/**
*
* 判断数据是否存在
*/
public boolean contains(int value) {
// 获取布隆过滤器
RBloomFilter<Integer> bloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_KEY);
// 判断是否存在
return bloomFilter.contains(value);
}
}
缓存击穿
定义:给某一个key设置了过期时间,当key过期时,恰好这个时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间压垮DB。其流程如下:
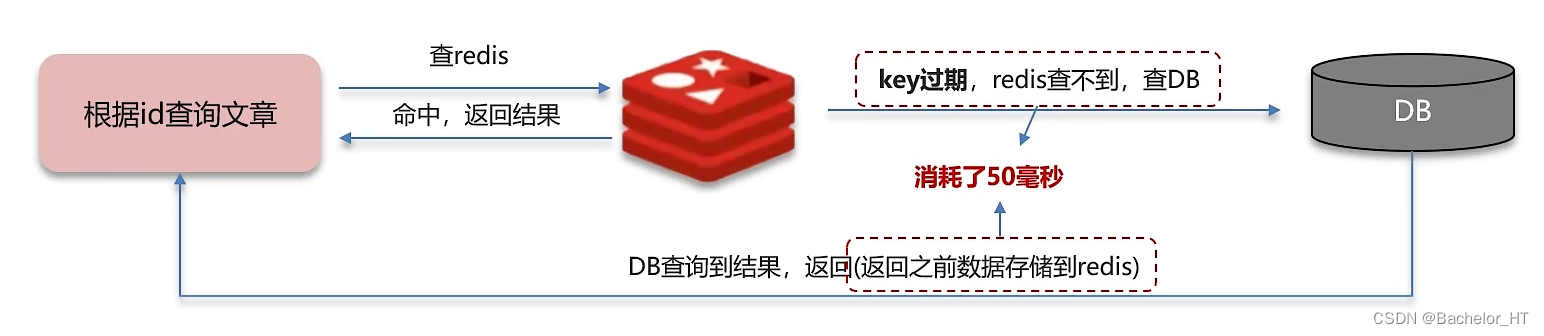
解决方案
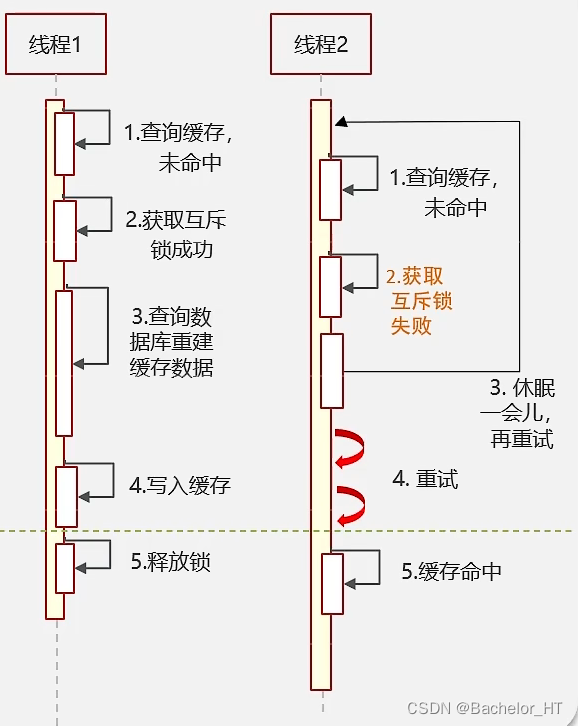
互斥锁
锁具有 互斥性,加锁之后线程从原来的 并行 变成了 串行。 第一个线程过来访问,获得锁,只有第一个线程能够去直接访问数据库,然后把数据写入缓存。第二个线程过来,没得到锁,只能不断重试去获得锁,直至第一个线程释放锁,然后第二个线程就能够直接从缓存中获得数据。
注:金融业务(涉及钱),需要保证数据强一致性,使用互斥锁。
互斥锁 流程图如下:
实现代码如下:
Controller:
public Result queryById(Long id) {
//缓存穿透
//互斥锁解决缓存击穿
Shop shop = serviceImpl.queryWithMutex(id);
if (shop == null) {
return Result.fail("数据不存在!");
}
//返回
return Result.ok(shop);
}
ServiceImpl:
@Autowired
private StringRedisTemplate stringRedisTemplate;
public Shop queryWithMutex(Long id) {
String key = CACHE_BOOK_KEY + id;
//1.从redis查询缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
//3.存在,直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return shop;
}
if (shopJson != null) {
return null;
}
//4.实现缓存重建
//4.1获取互斥锁
String lockKey = "lock:book:" + id;
Shop shop = null;
try {
boolean isLock = tryLock(lockKey);
//4.2判断是否获取成功
if (!isLock) {
//4.3失败,则休眠并重试
Thread.sleep(50);
//递归
return queryWithMutex(id);
}
//4.4成功,根据id查询数据库
shop = getById(id);
//5.不存在,返回错误
if (shop == null) {
//缓存击穿问题
//将空值写入redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
//6.存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_BOOK_TTL, TimeUnit.MINUTES);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
//7.释放互斥锁
unlock(lockKey);
}
//8.返回
return shop;
}
//获得锁
public boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
//释放锁
public void unlock(String key) {
stringRedisTemplate.delete(key);
}
逻辑过期
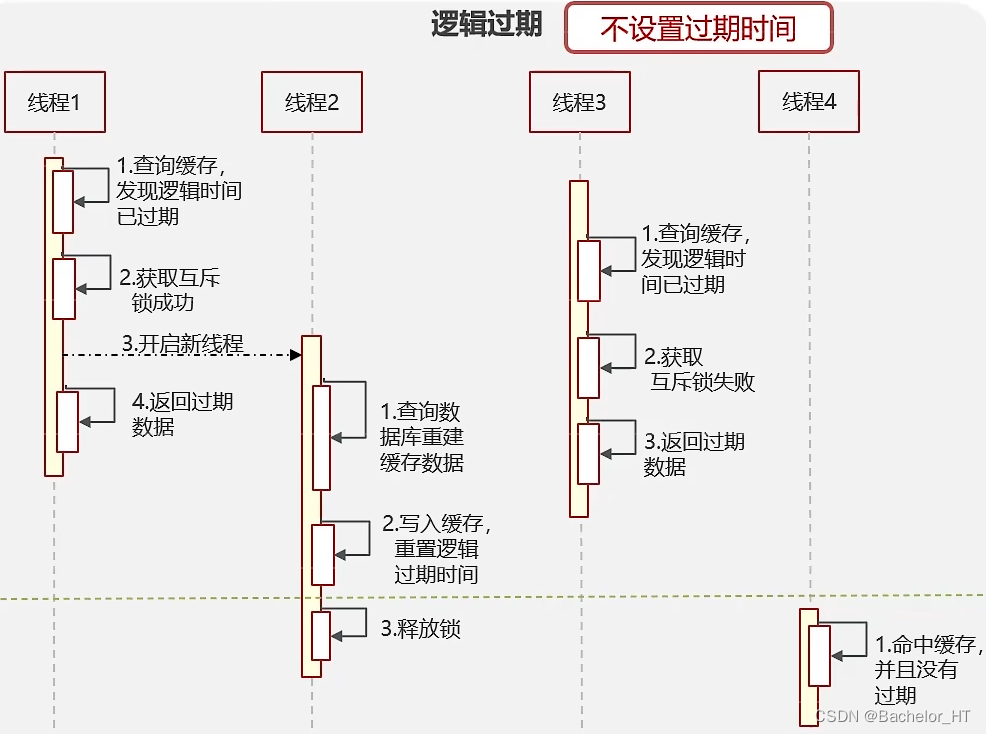
不设置失效时间,而是在value中添加一个时间值,每次访问时,获取当前时间,与过期时间比较,如果当前时间小于过期时间,没过期。反之,逻辑过期,此时获取互斥锁,并开启新线程,返回过期数据。在新线程中,查询DB重建缓存数据,将其写入缓存并重置过期时间,释放锁。若在线程3没有释放互斥锁时,线程3获取锁失败后,直接返回过期时间。
该方法保证了高可用,提高了性能。
如图所示:
缓存雪崩
定义:同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大的压力。流程如图:

解决方式:
- 给不同的key的TTL(Time To Live 生存时间)添加随机值
- 利用Redis集群提高服务的可用性(哨兵模式、集群模式)
- 给缓存业务添加降级限流策略,保底策略(ngnix、spring cloud gateway、sentinel)
以下是学习Sentinel的链接 - 给业务添加多级缓存(Guava,Caffeine)
有意思的打油诗:
穿透无中生有key,布隆过滤null隔离。
缓存击穿过期key,锁与非期解难题。
雪崩大量过期key,过期时间要随机。
面试必考三兄弟,可用限流来保底。














 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









