






count是在数据库查询中常用的函数,经常用于统计记录数和做分页查询,那么count(1),count(*),count(列名)有什么区别,哪种效率更高呢,我们首先看一下网上关于这几种count的解释和结论:
-
count(主键id):使用这个方式,InnoDB 会遍历整个表,把所有的 id 值都传给 sever 层。sever 层拿到 id 后,可以直接按行累加(id 不能为空)。
-
count(1):InnoDB 会遍历整个表,但是不取值。sever 对返回的每一行,都放一个数字 “1”,这个判断不可能为空,可以直接累加。
-
count(字段):
1.如果这个字段为 not null,则读出字段,按行累加。
2.如果这个字段为允许 null,在执行的时候,需要将值取出判断,如果不是 null 才累加。
-
count(*):不会取出全部字段,而是专门做了优化,按行累加。
综上,按照效率排序,count(字段) < count(主键 id) < count(1) ≈ count(*)。所以,建议尽量使用count(*)。
接下来我们通过实验来验证。
在实验之前,我们先了解下影响mysql查询效率的三个指标:响应时间、处理的数据行数量、返回的数据行数量。处理和返回的数据行数量好理解,需要读取和处理的数据越多,耗时越长。重点是响应时间,响应时间是由服务时间和队列时间组成。服务时间是服务端实际处理查询的时间,队列时间是资源等待时间,如I/O操作、行锁释放等,也跟服务器硬件和操作系统当时的负载情况有关,我们没办法控制所有环境因素始终是一致的,因此,响应时间并不是一成不变的,只能从大概率的数据统计来证明我们的结论。下面的实验数据也只是选取了其中的一份样本数据。
以表tbl_coupons2为例,该表有140多万条数据,id列为主键,coupons_name列建有普通索引,数据库版本为mysql5.6.11。分别执行下面语句:
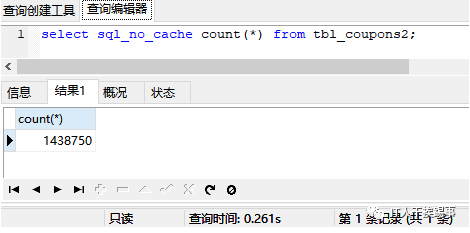
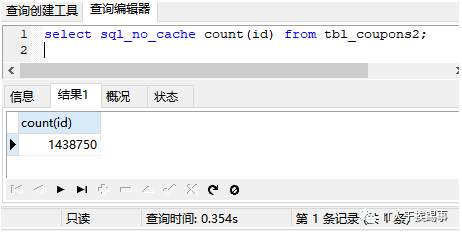

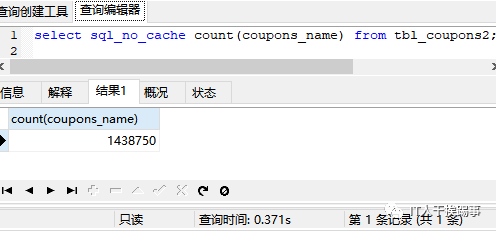

一切看起来都很完美,我们几乎可以得出结论:
count(字段)<count(索引字段) ≈ count(主键 id) < count(1) ≈ count(*)。
接下来我们再做些骚操作,看看索引和主键对count的影响。先删除tbl_coupons2表的主键和索引(每次删除或创建索引后都执行下表分析analyze table tbl_coupons2,以确保查询优化器能正确执行,提高实验数据的准确性),然后再执行一遍下面语句:
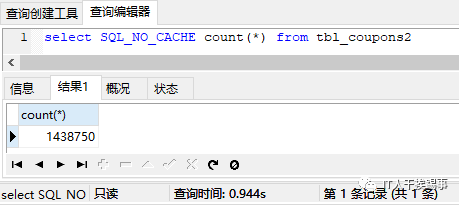

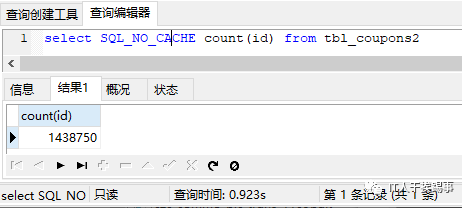
我们可以看到,没有索引和主键后,效率立马降低了数倍,而且无论怎么count,效率都差不多。
接下来我们再加回主键alter table tbl_coupons2 add primary key(id),看看执行情况:
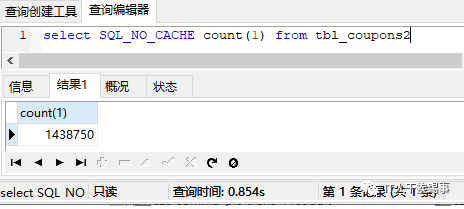
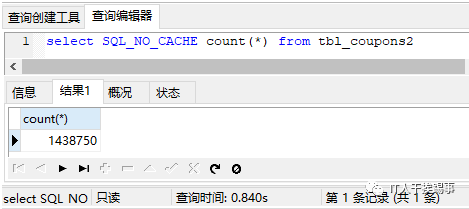
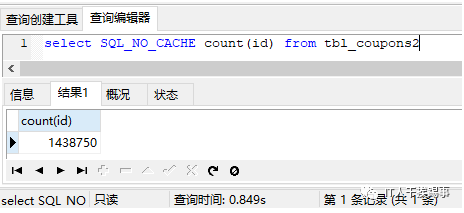
执行效率并没有明显提升,我们再建一个索引create unique index idx_id on tbl_coupons2(id),再次执行:
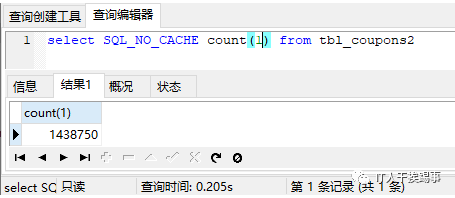
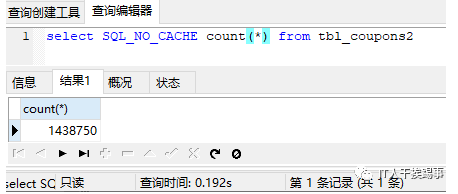
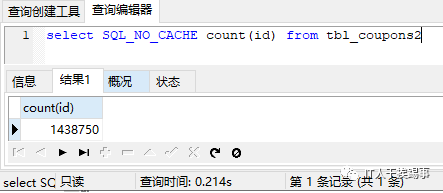
可以看到,效率明显提升了。为了进一步证明主键对count(*)的影响,我又尝试了在coupons_no字段建主键,在id字段建普通索引等情况,实验结果证明,主键并不能提升count查询效率,要建索引才可以。
总结:
1、要提升count查询效率,一定要建索引(唯一索引和普通索引区别不大),主键不能替代索引,在尽量短的字段建索引,效果更好。
2、在有索引前提下,按照效率排序,count(字段)<count(索引字段) ≈ count(主键 id) < count(1) ≈ count(*),理论上count(*)优于count(1),实际效果差不多。
其它优化方法:
1、使用EXPLAIN,如explain select count(*) from tbl_coupons2,但这样返回记录数并不准确,没有太大应用价值。
2、通过程序逻辑优化,对于数据量比较大的表,可以新建另一个记录表来专门记录大表的记录数,每次插入和删除时同时更新记录表的记录数(程序不方便改动的情况下可以通过触发器实现),需要统计数据行数时直接从记录表取。
PS:主键和唯一索引的区别
1、主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。
2、主键创建后一定包含一个特殊的唯一性索引,唯一性索引不一定就是主键。
3、唯一性索引列允许空值, 而主键列不允许为空值。
4、主键可以被其他表引用为外键,而唯一索引不能。
5、 一个表最多只能创建一个主键,但是可以创建多个唯一索引。
6、主键更适合那些不容易改变的唯一标识,如自动递增列,身份证号等。
















 2641
2641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









