







1.在Pandas中读入2020年中国大学排名.xlsx,并显示前五行。
import pandas as pd
df = pd.read_excel("2020年中国大学排名.xlsx")
df.head(5)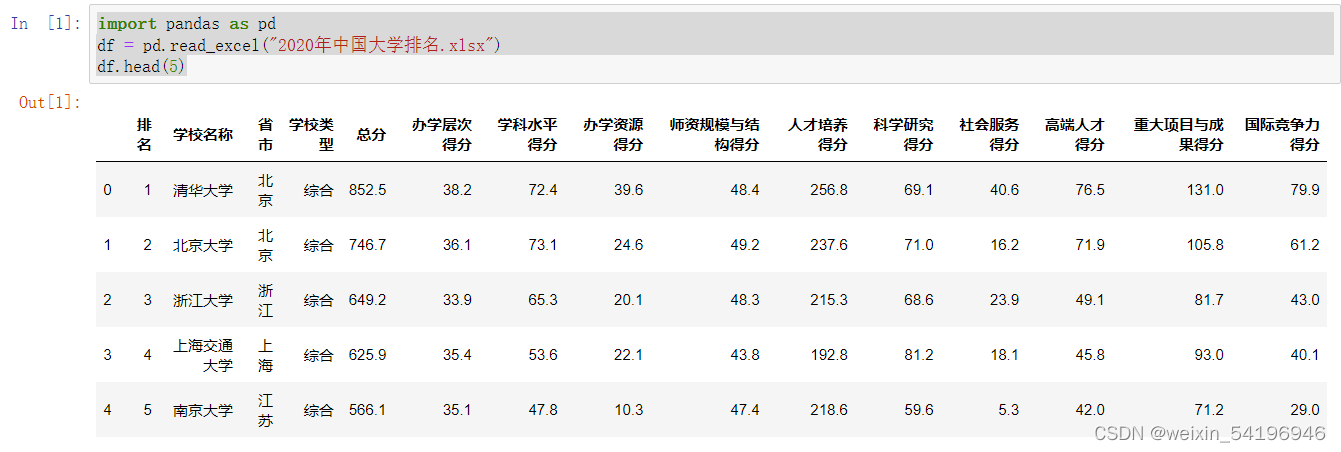
2.修改索引为 “学校名称”列,数据已经按照降序排列,让“学校”当索引会更好一点。
df = df.set_index("学校名称")
print(df.head(10)) 3.查看数据量,也就是数据框的 行 * 列,总共单元格的数量。
3.查看数据量,也就是数据框的 行 * 列,总共单元格的数量。
df.size
4.将数据按照总分升序排列,并展示前20个学校,备注:也就是看倒数20名啦
df = df.sort_values(by='总分')
df.head(20) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









