






 本文介绍了Linux的基础知识,包括系统目录结构、常用命令、XShell的使用。接着深入讲解了磁盘分区的概念,如何查看和管理磁盘,如创建分区、格式化和挂载。然后讨论了网络管理,包括网络命令、网络测试和进程调度。此外,还提到了Cmake在构建和管理项目中的作用。
本文介绍了Linux的基础知识,包括系统目录结构、常用命令、XShell的使用。接着深入讲解了磁盘分区的概念,如何查看和管理磁盘,如创建分区、格式化和挂载。然后讨论了网络管理,包括网络命令、网络测试和进程调度。此外,还提到了Cmake在构建和管理项目中的作用。
1. Linux 基础
1.1 系统目录结构
1.1.1 /
根目录Unix和Linux中没有ABCD盘符,仅有一个硬盘,一个根
1.1.2 /bin
系统的常用命令目录,包括控制台命令,系统可执行文件,系统的核心二进制文件等
1.1.3 /etc
发布目录,相当于windows的windows目录,保存系统所有核心内容,不建议随意读写
1.1.4 /usr
用户目录,相当于windows的program files目录,常用于安装所有用户共有的软件资源。
1.1.5 /root或~
root根用户的用户目录,相当于winsows的C:/users/admainistrator
1.1.6 /home
保存其他用户的目录。如Linux系统中有user1用户,那么一定有/home/user1目录存在
1.1.7 /var
系统运行过程中的数据目录
1.2 常用命令
linux系统命令严格区分大小写
1.经常使用
cd,ls,psw,touch,mkdir
cp,mv,rm
more,less,head,tail
cat:打印文件内容
ln:建立软链接(快捷方式) 硬链接(半独立)
wc:统计文件行数
whatis:命令简单说明
2.压缩与解压
.tar结尾的文件
解压:tar xvf 压缩包名
压缩:tar cvf 文件夹名(多个文件压缩在一个包里)
.gz和.z和.tgz结尾的文件
解压:gzip -d 压缩包名
压缩:gzip 文件夹名(每个文件分别压缩成为一个包)
3.系统相关
time,date,uanme,lsb_release
du:统计文件和目录所占磁盘空间
dmesg:显示内核状态信息
uptime:显示系统时间、用户连接、负载
top:查看CPU使用率
free:查看内存和交换空间
4.网络相关
ping:查看网络连通性
ifconfig:配置网络
netstat:显示各种网络相关信息,如网络连接,路由表,接口状态 (Interface Statistics),masquerade 连接,多播成员 (Multicast Memberships) 等等。
5.查找命令(*代表省略文字)
find -name 文件名 :查找文件
grep "test" :查找文件中符合条件的字符串,-c:统计符合字符串条件的行数
6.管道(输出进程|输入进程)
|管道符,将一个命令的输出作为另外一个命令的输入
ps 打印进程信息
cat 打印文件内容
7.重定向(输出进程>文件)
> 输出重定向到一个文件
>> 输出重定向到一个文件,附加在源文件后面
>! 输出重定向到一个文件,覆盖源文件
< 文件内容输入重定向到一个进程
8.文本编辑
vi:通用文本编辑器,类比win记事本
vim:vi的增强版本,多了高亮显示
1.2.1 pwd
print working directory:输出当前工作目录
1.2.2 cd
change directory:切换目录
返回上级:cd ..
切换具体位置:cd 绝对/相对路径
1.2.3 ls
查看当前同级目录下的文件夹
1.2.4 more
分屏显示文件内容,more 文件名,打开文件后,空格显示下一屏,回车显示下一行,q退出分屏,ctrl+c退出命令
1.2.5 head
显示文件前n行内容,head -n 文件名
1.2.6 tail
显示文件后n行内容,tail -n 文件名
1.2.7 mkdir
创建子目录,mkdir 目录名
1.2.8 touch
创建文件,touch 文件名
1.2.9 vi/vim
打开/新建文件:vi 文件名(在命令行)
进入编辑模式:(在非编辑模式下,编辑模式就是记事本)
a:append追加
i:insert插入
o:under line 在光标下一位新增一行,进入编辑
O:per line 在光标上一位新增一行,进入编辑
退出编辑模式:ESC(在编辑模式下)
保存::w(在非编辑模式下)
退出vi/vim编辑器::q(在非编辑模式下)
保存+退出::wq(在非编辑模式下)
显示行号::set nu(在非编辑模式下)
搜索:/搜索内容(在非编辑模式下)
光标跳转:跳转末尾G 跳转开头gg
1.2.10reboot
重启Linux系统,需要root权限
1.2.11 halt
关闭正在运行的Linux系统
1.2.12 ifconfig
查看ip等网络信息,如我的私有ipv4为192.168.0.13
1.2.13 网络配置
Linux默认使用NTA地址转换(将一组私有ip映射为1个公有ip与外网连接),可以节省ip资源,缺点是局域网中不同网段不能相互访问。解决方法:虚拟机设置为桥连。
1.3 XShell
1.3.1 Shell
shell不是具体哪一款程序,是一类程序的统称,这些程序只要是能够按照用户的要求去调用操作系统的接口,就可以称之为shell程序.
linux有许多shell程序,其中一款软件叫做bash.
当我们用命令行开启或远程连接一台linux主机之后,就开启了bash.
bash定义变量:变量名=变量值 (赋值符号两边不可以有空格.)
在bash中查看变量的值: echo $变量名
变量在其他程序中使用需要用 export 变量名 将变量声明成环境变量.
取消变量的方式是 unset 变量名.
查看当前所有环境变量 env 指令
set则是查看所有变量, 包括环境变量,用户自定义的变量.
解释文件:bash 文件名
1.3.2 XShell
在Windows中远程操控开机状态的Linux的工具
step1:创建win与linux链接(协议 SSH,主机Linux IPv4,默认端口)
step2:选择操作Linux的用户名(root),输入该用户的密码,进行连接
step3:在XShell中使用linux命令远程操作Linux
2. Linux磁盘分区
2.1 磁盘类型
HDD,SSD, SATA,PCIe之间的关系和区别:
-
SATA,PCIe是接口类型:
SATA(Serial Advanced Technology Attachment)是一种串行接口标准,用于连接HDD和SSD等存储设备。PCIe(Peripheral Component Interconnect Express)是一种高速并行接口标准,用于连接各种设备,包括显卡、网卡和存储设备等。
-
HDD,SSD 是硬盘类型:
HDD(Hard Disk Drive)机械硬盘SSD(Solid State Drive)固态硬盘:普通的SSD配的是SATA接口(AHCI协议),NVMe SSD配的是PCIe接口(Non-Volatile Memory Express , NVMe 传输协议)
2.2 分区概念
这个太重要了,比如在下载huggingface权重的时候,突然报错 No space left on device ,原因是磁盘空间满了,你如果了解linux的磁盘分区,就可以对服务器磁盘占用进行查看,找到可用的磁盘,指定下载路径解决这个问题。
在Linux操作系统中,任何外部物理存储设备接入系统后都是以文件的形式存在,且不同类别的设备接入系统后被识别的文件类型不同(在linux下,/dev目录是很重要的,各种设备都在下面),这里我们用下表来详细说明:
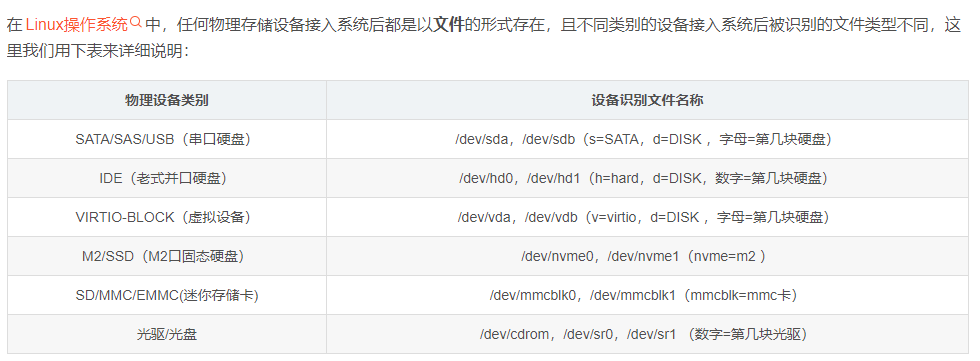
-
/dev/hd一般是指 IDE接口的硬盘,/dev/hda指第一块硬盘,/dev/hdb指第二块硬盘,等等; -
/dev/sd一般是指 SATA接口的硬盘,/dev/sda指第一块硬盘,/dev/sdb指第二块硬盘,等等。 -
/dev/nvme一般是指 PCIe接口的固态硬盘,/dev/nvmen0指第一块硬盘,/dev/nvmen1指第二块硬盘,等等。 -
/dev/loop是指虚拟设备/伪设备,用于挂载文件系统镜像或其他虚拟设备。
2.3 查看磁盘分区 fdisk
查看系统磁盘的区域划分:
fdisk -l
我的分区结果显示如下:
Disk /dev/loop0: 4 KiB, 4096 bytes, 8 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop1: 63.48 MiB, 66547712 bytes, 129976 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop2: 55.68 MiB, 58363904 bytes, 113992 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop3: 218.4 MiB, 228999168 bytes, 447264 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop4: 45.95 MiB, 48160768 bytes, 94064 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop5: 73.9 MiB, 77463552 bytes, 151296 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop6: 63.46 MiB, 66535424 bytes, 129952 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop7: 496.9 MiB, 521015296 bytes, 1017608 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/nvme0n1: 3.65 TiB, 4000787030016 bytes, 7814037168 sectors
Disk model: INTEL SSDPE2KX040T8
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 20B59105-C06F-4522-AFCD-9F0677491D28
Device Start End Sectors Size Type
/dev/nvme0n1p1 2048 7814035455 7814033408 3.7T Linux filesystem
Disk /dev/sda: 447.13 GiB, 480103981056 bytes, 937703088 sectors
Disk model: INTEL SSDSC2KB48
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: dos
Disk identifier: 0xd10b40f8
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 2048 976895 974848 476M 83 Linux
/dev/sda2 978942 937701375 936722434 446.7G 5 Extended
/dev/sda5 978944 16977919 15998976 7.6G 82 Linux swap / Solaris
/dev/sda6 16979968 416978943 399998976 190.8G 83 Linux
/dev/sda7 416980992 937701375 520720384 248.3G 83 Linux
Partition 2 does not start on physical sector boundary.
Disk /dev/sdb: 12.75 TiB, 14000519643136 bytes, 27344764928 sectors
Disk model: ST14000NM001G-2K
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: F8EDECEE-8C12-448A-9A40-5D4D70A32AE4
Device Start End Sectors Size Type
/dev/sdb1 2048 27344762879 27344760832 12.8T Linux filesystem
Disk /dev/loop8: 496.10 MiB, 521121792 bytes, 1017816 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop9: 81.27 MiB, 85209088 bytes, 166424 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop10: 40.88 MiB, 42840064 bytes, 83672 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop11: 349.71 MiB, 366678016 bytes, 716168 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop12: 55.68 MiB, 58363904 bytes, 113992 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop13: 218.4 MiB, 228999168 bytes, 447264 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop14: 12.33 MiB, 12922880 bytes, 25240 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop15: 73.92 MiB, 77492224 bytes, 151352 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop16: 349.71 MiB, 366682112 bytes, 716176 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop17: 91.7 MiB, 96141312 bytes, 187776 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/loop18: 40.86 MiB, 42827776 bytes, 83648 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
分析可知:
/dev/nvme0n1: 这是一个3.65 TiB的NVMe固态硬盘,它使用GPT分区表。唯一的分区是/dev/nvme0n1p1,类型为Linux filesystem,大小为3.7T。
/dev/sda: 这是一个447.13 GiB的SSD硬盘,它使用MBR分区表。该硬盘有多个分区:
/dev/sda1是引导分区,大小为476M,文件系统类型为Linux。
/dev/sda2是扩展分区,包含逻辑分区/dev/sda5、/dev/sda6和/dev/sda7。
/dev/sda5是Linux swap / Solaris分区,大小为7.6G。
/dev/sda6和/dev/sda7都是Linux分区,分别大小为190.8G和248.3G。
/dev/sdb: 这是一个12.75 TiB的机械硬盘,它使用GPT分区表。唯一的分区是/dev/sdb1,类型为Linux filesystem,大小为12.8T。
/dev/loop0到/dev/loop18的设备。这些是虚拟设备或回环设备,用于挂载文件系统镜像或其他虚拟设备。
2.4 磁盘挂载、分区、格式化
磁盘空间不足时,我们常常要买新的硬盘扩充磁盘空间,首先将新买的硬盘插入机器,只是插入机器,这个磁盘并不能用。假如我们新买了12.75 TiB的机械硬盘,直接插入机器,然后进行分区、格式化、挂载,使得磁盘空间可用在目录中访问。
1. 分区
刚刚插入的磁盘,通过fdisk -l查看发现多了一个未分区的空间/dev/sdb:
Disk /dev/sdb: 12.75 TiB, 14000519643136 bytes, 27344764928 sectors
Disk model: ST14000NM001G-2K
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
接下来进行交互式分区:
- 运行命令
fdisk /dev/sdb来打开/dev/sdb设备的分区工具。请注意,这个命令将会直接操作磁盘设备,请谨慎操作,确保选择正确的设备。 - 在fdisk命令提示符下,您可以使用以下命令进行分区:
n:创建新分区
p:选择主分区
e:选择扩展分区
l:显示分区列表
d:删除分区
w:保存并退出 - 根据需求,选择适当的分区类型和大小,并按照提示进行操作。可以创建多个分区或者将整个磁盘作为一个分区。
- 当完成分区后,使用命令
w保存并退出分区工具。
系统会自动重新加载分区表,然后您可以使用新创建的分区。
分区结束后,再用fdisk -l查看,就会发现多了一个分区/dev/sdb1:
Device Start End Sectors Size Type
/dev/sdb1 2048 27344762879 27344760832 12.8T Linux filesystem
还可以用lsblk查看分区:可以看到刚刚把/dev/sdb设备的12.8T空间,全部划分给/dev/sdb1逻辑分区了
lsblk /dev/sdb
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 12.8T 0 disk
└─sdb1 8:17 0 12.8T 0 part
2. 格式化
新磁盘分区完成后,可以对sdb1分区进行格式化,可以使用相应的文件系统工具,将sdb1分区格式化为ext4文件系统(请注意,这将会清除分区中的所有数据,请谨慎操作)
mkfs.ext4 /dev/sdb1
3. 挂载
挂载就是将磁盘关联到目录下的操作。
如果磁盘的某个分区是外部设备的空间,在使用时我们常常将外设的空间,挂载到当前机器的目录下,使得访问外设空间和访问机器本地空间一样方便。
- 每个分区都有对应的UUID(Universally Unique Identifier,通用唯一标识符),
ls -l /dev/disk/by-uuid查看要挂载的分区的UUID:如sdb1的就是0d9bb044-26d9-4ea0-aab3-ffb8f4a828de:
lrwxrwxrwx 1 root root 10 11月 21 16:20 0d9bb044-26d9-4ea0-aab3-ffb8f4a828de -> ../../sdb1
lrwxrwxrwx 1 root root 10 11月 21 16:20 3398eb07-6123-4275-81e9-0d5c4964b564 -> ../../sda6
lrwxrwxrwx 1 root root 10 11月 21 16:20 5480f23c-0d43-4247-a52d-7f7d7d0629c1 -> ../../sda5
lrwxrwxrwx 1 root root 15 11月 21 16:20 6cdd0fe5-8138-4666-8464-be161bc89fbb -> ../../nvme0n1p1
lrwxrwxrwx 1 root root 10 11月 21 16:20 70fc075d-6ad7-47a8-a6bb-705dd204b414 -> ../../sda1
lrwxrwxrwx 1 root root 10 11月 21 16:20 aba773e8-c911-4b99-b36c-17b6dcc86807 -> ../../sda7
- vim 打开
vim /etc/fstab文件,写入挂载项:
UUID=0d9bb044-26d9-4ea0-aab3-ffb8f4a828de /data ext4 defaults 0 2
模板解析:
UUID=<partition-UUID> <mount-point> <filesystem-type> <mount-options> <dump> <pass>
<partition-UUID>:替换为要挂载分区的UUID,例如 UUID=abcd-efgh。
<mount-point>:替换为分区的挂载点,即分区要挂载到的目录路径。
<filesystem-type>:替换为文件系统类型,例如 ext4、ntfs等。
<mount-options>:替换为挂载选项,比如 defaults、noatime等。可以根据需求添加多个选项,用逗号分隔。
<dump>:指定是否备份此文件系统,通常设置为 0。
<pass>:指定文件系统检查顺序,通常设置为 2。
-
重启机器
reboot -
使用
mount命令将/dev/sdb1挂载到/data目录上,这样就可以访问该/dev/sdb1分区中的文件和目录了。
sudo mount /dev/sdb1 /data
- 同时,也可以使用
umount命令卸载该分区,使得该分区不再对应该目录。
如下,是将名为/dev/sda1的设备(通常是一个磁盘分区)挂载到名为/boot的目录上。也就是说,/dev/sda1设备中的文件和目录可以通过/boot目录来访问。
/dev/sda1 446M 349M 63M 85% /boot
2.5 查看磁盘占用与挂载 df
划分挂载完成的分区,可以使用df -h查看不同分区的占用率和挂载情况:
df -h
Filesystem是文件系统(磁盘分区),Mounted on是挂载点(挂载目录)
Filesystem Size Used Avail Use% Mounted on
udev 378G 0 378G 0% /dev
tmpfs 76G 3.7M 76G 1% /run
/dev/sda6 187G 61G 117G 35% /
tmpfs 378G 4.0K 378G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 378G 0 378G 0% /sys/fs/cgroup
/dev/loop1 64M 64M 0 100% /snap/core20/2015
/dev/loop2 56M 56M 0 100% /snap/core18/2790
/dev/loop0 128K 128K 0 100% /snap/bare/5
/dev/loop3 219M 219M 0 100% /snap/gnome-3-34-1804/93
/dev/loop4 46M 46M 0 100% /snap/snap-store/638
/dev/loop6 64M 64M 0 100% /snap/core20/1891
/dev/loop5 74M 74M 0 100% /snap/core22/858
/dev/loop7 497M 497M 0 100% /snap/gnome-42-2204/132
/dev/sda1 446M 349M 63M 85% /boot
/dev/nvme0n1p1 3.6T 991G 2.5T 29% /data0
/dev/sda7 244G 186G 46G 81% /home
/dev/loop8 497M 497M 0 100% /snap/gnome-42-2204/141
/dev/loop9 82M 82M 0 100% /snap/gtk-common-themes/1534
/dev/loop10 41M 41M 0 100% /snap/snapd/20290
/dev/loop11 350M 350M 0 100% /snap/gnome-3-38-2004/140
/dev/loop12 56M 56M 0 100% /snap/core18/2796
/dev/loop13 219M 219M 0 100% /snap/gnome-3-34-1804/90
/dev/loop14 13M 13M 0 100% /snap/snap-store/959
/dev/loop15 74M 74M 0 100% /snap/core22/864
/dev/loop16 350M 350M 0 100% /snap/gnome-3-38-2004/143
/dev/loop17 92M 92M 0 100% /snap/gtk-common-themes/1535
/dev/loop18 41M 41M 0 100% /snap/snapd/20092
tmpfs 60M 0 60M 0% /var/log/rtlog
/dev/sdb1 13T 6.3T 5.7T 53% /data1
tmpfs 76G 8.0K 76G 1% /run/user/1001
磁盘分区 与 挂载目录 分析:
/dev/sda6是根文件系统,总大小为187G,已使用61G,可用空间117G,使用率为35%。
/dev/sda1是引导分区,总大小为446M,已使用349M,可用空间63M,使用率为85%。
/dev/nvme0n1p1是一个数据分区,总大小为3.6T,已使用991G,可用空间2.5T,使用率为29%。
/dev/sda7是/home分区,总大小为244G,已使用186G,可用空间46G,使用率为81%。
/dev/sdb1是/data1分区,总大小为13T,已使用6.3T,可用空间5.7T,使用率为53%。
临时文件系统(tmpfs)和循环设备(/dev/loopX),通常是由操作系统使用的内存中的虚拟文件系统。这些文件系统通常是只读的,并且使用率为100%。
/tmp、/run、/sys/fs/cgroup等是临时文件系统,用于临时存储和运行时数据。
/mnt/log/rtlog是一个日志文件系统,总大小为60M,目前未使用。
查看path路径下的磁盘占用与挂载情况:
df -h path
Filesystem Size Used Avail Use% Mounted on
/dev/sda7 244G 186G 46G 81% /home
2.6 查看文件大小 du
查看path目录下所有文件的大小,及汇总:
du -ac /home/pgao/yue
如下显示:file_size,file_path
64K /home/pgao/yue/1.png
372K /home/pgao/yue/astronaut_rides_horse.png
4.0K /home/pgao/yue/Stable-Diffusion-Video/requirements/pt2.txt
......
153624 /home/pgao/yue
153624 total
3. Linux 网络管理
3.1 网络环境操作
网络查看工具:net-tools(ipconfig、route、netstat)
ifconfig
ifconfig:查看网络状态(能查看IP地址和子网掩码,但是不能查看网关和DNS地址),还可以临时设置某一网卡的IP地址和子网掩码。
- 查看网络状态:
ifconfig,(lo表示本地回环网卡的信息)
eth0 Link encap:Ethernet HWaddr 00:0C:29:11:30:39
inet addr:192.168.134.129 Bcast:192.168.134.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe11:3039/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:19731 errors:0 dropped:0 overruns:0 frame:0
TX packets:502 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1248492 (1.1 MiB) TX bytes:58905 (57.5 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
- 临时设置IP和子网掩码:使用ifconfig命令还可以临时设置某一网卡的IP地址和子网掩码。
ifconfig eth0 192.168.0.200 netmask 255.255.255.0
route
- 查看路由列表(可以看到当前计算机的网关):
route -n - 临时设定网关:
route add default gw 192.168.1.1 - 删除设定的网关:
route del default gw 192.168.1.1
netstat
netstat可以用于查看当前计算机开放的端口,从而判断当前计算机启动了哪些服务
netstat 选项
选项:
-t:列出TCP协议端口
-u:列出UPD协议端口
-n:不使用域名和服务名,而使用IP地址和端口号
-l:仅列出在监听状态网络服务
-a:列出所有的网络连接
-r:列出路由列表,功能和route命令一只
常用组合:-tuln、-an、-rn
查看某一状态下的网络连接情况,如:netstat -an | grep ESTABLISHED
查看某一网络状态下的行数(查看有多少台计算机连接到当前服务器),如:netstat -an | grep ESTABLISHED | wc -l
netstat -rn 和 route -n 命令功能一样,结果一致。通过这样的命令查看当前计算机的网关地址。
3.2 网络测试
ping命令
探测指定IP或域名的网络状况
ping [选项] ip或域名
wget命令
下载命令
wget 下载地址
git lfs命令
tcpdump命令
tcpdump命令 用于监听某一网卡下某一服务的数据包接收情况(截获数据包-抓包)。
tcpdump -i eth0 -nnX port 21
选项:
-i 指定监听的网卡
-nn 将数据包中的域名与服务转为IP和端口显示
-X 以十六进制和ASCII码显示数据包内容
port 指定监听的端口
4. Linux进程、线程和调度
推荐阅读:两个程序悲催的进化旅程
进程:资源分配的基本单位
进程数据结构:进程控制块PCB描述进程资源(task_struct),如pid、mm内存资源、fs文件系统资源(路径)、file文件资源、signal信号等
pid数量有上限:cat /proc/sys/kernel/pid_max,可知pid_max=32768
fork炸弹::(){:|:&};:,函数:使用管道|创建新的进程递归的后台调用&自己;将pid耗尽。解决:ulimit -Hu 30 这个指令可以限制每一个用户最多只能创建30个进程
PID管理:pstree查看进程树,将所有task_struct串在一个树上,表示父子进程关系。[pid : task_struct]使用哈希映射。
Linux进程生命周期(就绪、运行、睡眠、停止、僵死)
就绪:(时间片用完)等CPU
睡眠:(缺少除CPU以外的资源)等其他资源
运行:有CPU+资源
僵尸:进程结束,资源释放,但PID的task_struct数据结构还没清除,一旦父进程调用wait4时,task_struct消失
停止:运行结束(ctrl-z),释放CPU,可以继续运行(fg或bg)
僵尸是个什么鬼?
进程资源已经释放,但PID的task_struct还在,父进程可以查子进程的死因status。
停止状态与作业控制,cpulimit
为了保证CPU利用率在某个范围(<20%),将程序间断的停止和运行
初见fork
分叉fork():将执行当前程序的进程克隆一份,从fork()开始独立并行执行,父进程fork()返回值=子进程pid,子进程fork()返回值=0。
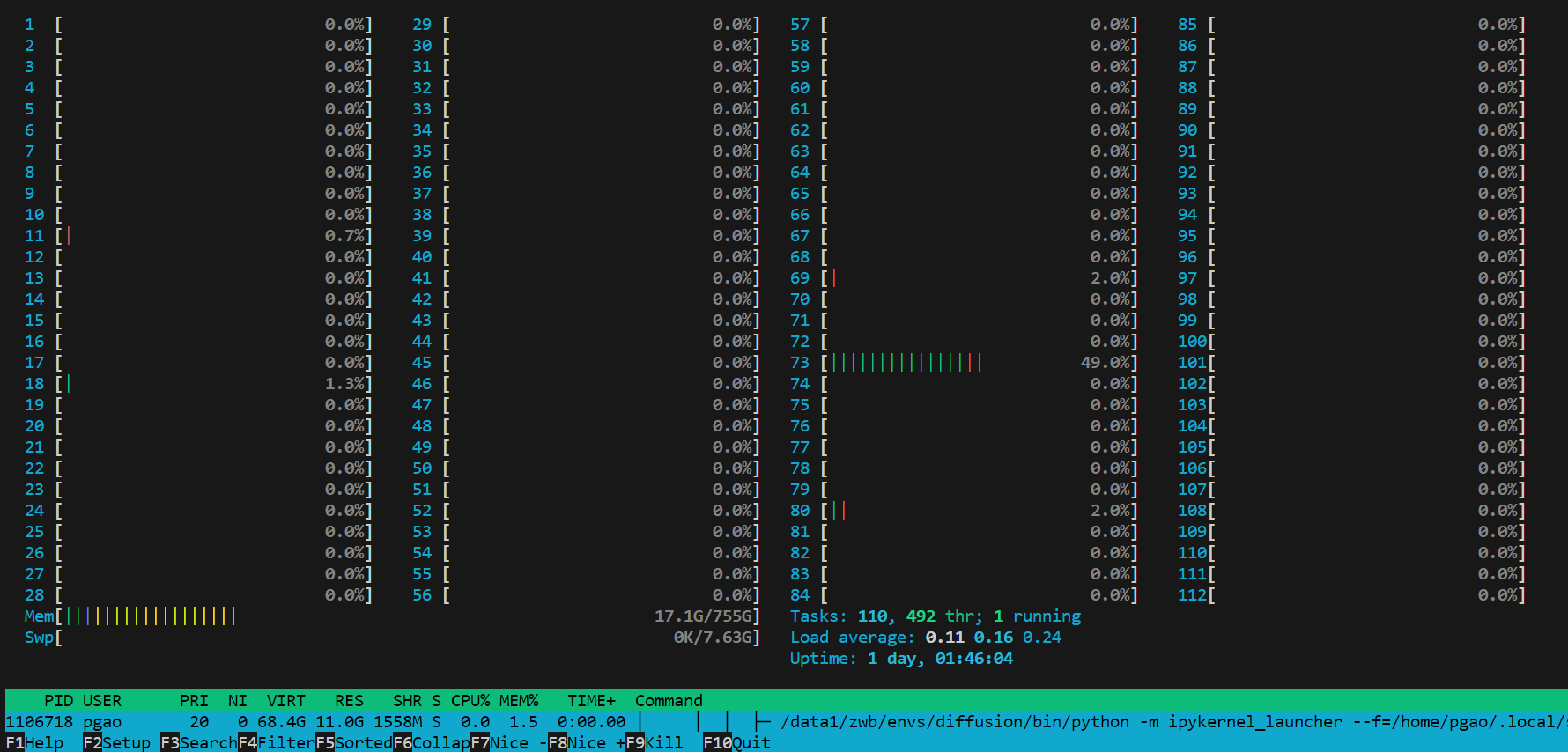
4.1 系统资源查看
htop实时查看CPU占用
安装htop工具
sudo apt-get install htop
使用htop查看cpu使用情况
htop
可以看到我的服务器的CPU逻辑核数=112
gpustat实时查看GPU占用
pip install gpustat
watch -n 1 gpustat # 每隔1s刷新一次

其实系统自带的nvidia-smi也可以实时查看:
watch -n 5 nvidia-smi
nvitop 实时查看GPU占用
想要拥有nvtop那样详细的展示,又想拥有gpustat那样彩色的界面,并且希望能够像gpustat一样通过pip快速安装,那就不得不提nvitop工具了。
安装方式
pip install nvitop
nvitop展示的模式有三种:
- auto (默认)
- compact
- full
如果希望展示超完整的显卡信息,则用如下命令:
nvitop -m full
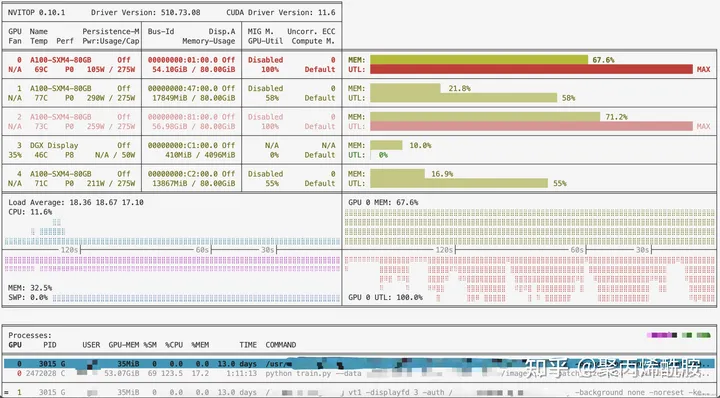
我认为这个工具最好用的地方不在于彩色文字和进度条,而在于它能够完整地显示出每个进程的执行用户、运行时长、执行指令以及每个进程所使用的GPU编号。可谓是集其他工具的优势于一身的实用主义工具了!
4.2 后台执行
nohup 是一个在 Unix 和类 Unix 系统上用来忽略挂断(SIGHUP)信号的命令。nohup执行bash命令行:(不要少了 &)
nohup ./train.sh > output.log &
上述命令将会以后台方式运行名为 train.sh 的程序,并将标准输出重定向到 output.log 文件中。当用户退出登录或终端关闭时,该程序将继续在后台运行。
通过 nohup 后台运行的程序会生成一个名为 train.sh 的文件,用于保存标准输出和标准错误流。如果不希望生成这个文件,可以将标准输出和标准错误流重定向到其他文件或 /dev/null。
在使用 nohup 命令时,该命令后面跟随的程序将会忽略挂断信号,因此可以在用户退出登录或终端关闭后继续在后台运行。因此对于ssh远程连接服务器的同学来说nohup是跑实验的常用工具。
4.3 杀死进程
使用 kill 命令时,还可以指定不同的选项:
kill -opt PID
-opt :
-9:强制终止进程(使用SIGKILL信号)。
-15:默认选项,发送终止信号(SIGTERM)给进程。
5. Cmake
文件编译的进化过程:
-
gcc:它是GNU Compiler Collection(就是GNU编译器套件),也可以简单认为是编译器,它可以编译很多种编程语言(括C、C++、Objective-C、Fortran、Java等等)。我们的程序只有一个源文件时,直接就可以用gcc命令编译它。可是,如果我们的程序包含很多个源文件时,怎么办,用gcc命令逐个去编译时,就发现很容易混乱而且工作量大,所以出现了下面make工具。
编译单个文件:
gcc -o 编译后文件名(xxx.o) 源文件名(xxx.c) -
make:make工具可以看成是一个智能的批处理工具,它本身并没有编译和链接的功能,而是用类似于批处理的方式—通过调用makefile文件中用户指定的命令来进行编译和链接的。
在工程目录下执行Makefile的文件编译:make
在工程目录下执行Makefile的clean: make clean -
makefile:makefile是make命令执行的规则文件。make工具就根据makefile中的命令进行编译和链接的。makefile命令中就包含了调用gcc(也可以是别的编译器)去编译某个源文件的命令。makefile在一些简单的工程完全可以人工拿下,但是当工程非常大的时候,手写makefile也是非常麻烦的,如果换了个平台makefile又要重新修改,这时候就出现了下面的Cmake这个工具。
编译一个工程:
在工程下:touch Makefile
编写Makefile:
目标文件 … : 依赖文件 …
cc -c xxx.c (只编译不链接)
目标文件 … : 依赖文件 …
cc -o xxx xxx.o (链接)
指令代号:
命令行命令 -
cmake:cmake就可以更加简单的生成makefile文件给上面那个make用。当然cmake还有其他更牛X功能,就是可以跨平台生成对应平台能用的makefile,我们就不用再自己去修改了。可是cmake根据什么生成makefile呢?它又要根据一个叫CMakeLists.txt文件(学名:组态档)去生成makefile。
-
CMakeList.txt:到最后CMakeLists.txt文件谁写啊?亲,是你自己手写的。
-
cmake和makefile的关系:cmake是makefile更高一级的抽象。
学习的话:手写Makefile和Makelist.txt
6. Linux集群调度(slurm)
集群的架构一般是:集群节点 + 集群存储
Linux集群中有2种节点:管理节点/登录节点(user挂vpn之后可以使用ssh远程链接的linux电脑,当然有的集群只能通过跳板机连接节点,不能直接ssh练节点)、计算节点(使用过程中在管理节点通过Slurm向计算节点提交CPU或GPU任务)
存储Quota
- 文件存储:在存储中,我们将代码,conda环境、checkpoint和数据存放在文件存储,如Lustre、Petrel FS
- 对象存储:在存储中,我们将大型数据集和ckpt存储使用对象存储,如Ceph SSD、Ceph HDD
集群使用 Lustre 分布式文件系统,所有节点都将 Lustre 挂载在自己的 /mnt/lustre 目录下,Lustre 主要包含一个 share 目录 /mnt/lustre/share_data 和用户目录 /mnt/lustre/yourname。
1、查看quota:用户可以使用命令“id”查看自己的UID和GID,UID即为自己账号在集群上对应的id,GID则为申请加入集群群组的id(如未加入群组,则GID为自身uid)。
Lustre中使用命令:lfs quota -u $UID /mnt/lustre
Petrel FS中使用命令:petrelfs-ctl --getquota --uid $UID
2、查看文件系统整体可用空间Lustre中使用命令:df–h|greplustrePetrelFS中使用命令:df -h | grep petrelfs
3、使用常用conda环境
Lustre中使用命令:source /mnt/lustre/share/platform/env/pt1.7.1
PetrelFS中使用命令:source /mnt/petrelfs/share/platform/env/pt1.7.1(需要提前申请在petrelfs公共目录中安装对应的环境)
Slurm任务操作
Slurm 会将所有计算节点划分成若干分区,每个分区需要单独申请权限,任务不能跨分区提交。
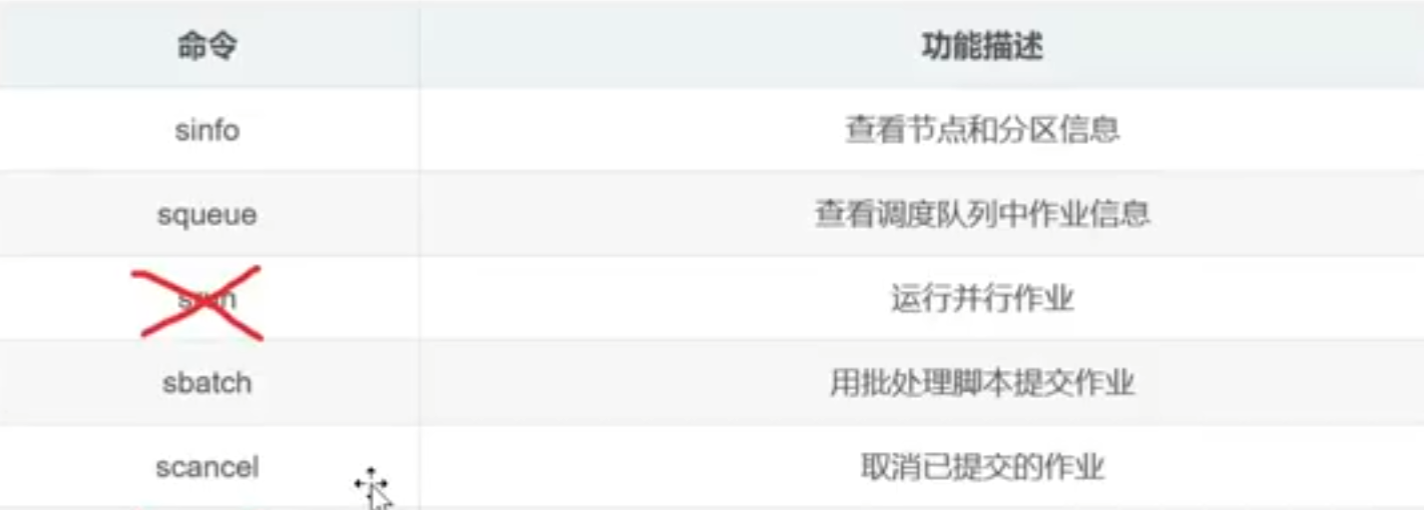
srun 任务提交
相比于直接在物理机上直接python main.py, 在slurm集群上提交任务需要额外使用srun来提交任务。直接学sbatch吧,一样的。
sbatch 提交任务
sbatch用于提交作业到作业调度系统中。先编写作业脚本(1个是python脚本,1个是包含srun的sh脚本),然后使用sbatch命令提交。提交后脚本将在分配的计算节点中运行。其优势是提交任务的方式为异步方式,退出tmux或终端连接不会对任务执行造成影响,同时支持在抢占后进行重排队。使用体验和srun --async差不多。
需要编写一个sbatch的sh脚本,并将需要申请的资源放在脚本的最上方,以#SBATCH开头:
N为节点数(每个节点上有gres=gpu个显卡,如果作业不能跨节点(MPI)运行, 申请的节点数应不超过1)ntasks-per-node是每个节点上多线程运行py的任务个数(每个节点上运行一个任务,默认一情况下也可理解为每个节点使用一个核心,如果程序不支持多线程(如openmp),这个数不应该超过1)n为所有节点运行py的总任务数(n = N * tasks-per-node),
#!/usr/bin/env sh
#SBATCH --partition=分区name
#SBATCH --gres=gpu:8
#SBATCH --ntasks-per-node=8
#SBATCH -n8
#SBATCH --job-name=job_name
#SBATCH -o logs/job_name
GLOG_vmodule=MemcachedClient=-1 srun --mpi=pmi2 \
python -u main.py \
--config cfgs/train.yaml
然后直接在命令行中输入sbatch $脚本名,提交任务。( --quotatype=spot --async用来蹭卡,使用异步提交方式提交的任务支持被抢占(原本quota为spot,然后别人的任务排进来后kill了你的任务)后自动重新排队。)
JOB_NAME='fuck'
OUTPUT_DIR="$(dirname $0)/$JOB_NAME"
LOG_DIR="./logs/${JOB_NAME}"
PARTITION='分区名'
NNODE=1
NUM_GPUS=1
NUM_CPU=16
srun -p ${PARTITION} \
-n${NNODE} \
--quotatype=spot \
--async \
-o ${LOG_DIR} \
-n${NNODE} \
--gres=gpu:${NUM_GPUS} \
--ntasks-per-node=1 \
--cpus-per-task=${NUM_CPU} \
swatch监控/取消任务
查看运行的任务:squeue -u your_user_name
JOBID:任务号
VIRTUAL_PAETITION:分区名字
NAME: 任务名称
QUOTA_TYPE:任务类型,reserved占用本分区资源,spot为白嫖其他分区模式,可以通过srun --quotatype指定,auto方式为有资源时分配reserved,没资源时spot
USER: 用户名
ST: R正在跑,PD 正在排队, CG正在退出
TIME: 已经运行的时常,最大运行时间为14days
NODES:使用的节点数量
NODELIST:使用的节点ip列表
取消我的任务:
# 取消单个任务
scancel $jobid
# 取消我的所有任务
scancel -u $yourname
查看分区中的任务:squeue -p 分区name
通过squeue -u your_user_name 可以看到当前你正在运行的任务(你正在运行的节点$host), 其中最后一列为你的任务NODELIST(REASON)所使用的节点(下面都用$host表示),如SH-IDC1-10-140-1-[145,152]
执行这句会在目标节点上执行top以便于查看CPU、负载、内存等 状态:
# 短时间查看
swatch -n $host top
# 长时间查看(10分钟)
swatch -n $host top always
执行这句会在目标节点上执行’nvidia-smi’以便于检测GPU status:
# 短时间查看
swatch -n $host nv
# 长时间查看(10分钟)
swatch -n $host nv always
卡顿释放内存:swatch -n $host memory_release
任务异常结束:请查找你的任务最后的输出,找到任务的jobid,然后输入swatch examine $jobid 查看任务结束情况,关注下列两列:如果出现PREEMPT说明是spot被杀。
查看闲置显卡:svp list
>VIRTUAL_PARTITION DEPARTMENT RESERVED_TOTAL RESERVED_USED RESERVED_IDLE SPOT_USED RESERVED_BLOCKED
video <none> 272 136 136 0 0
意思为总quota272张卡,使用136张,剩余136张,白嫖0张
7. Git代码版本管理
一个很nb的课:https://www.bilibili.com/video/BV1B8411a74a?p=9&vd_source=b2549fdee562c700f2b1f3f49065201b
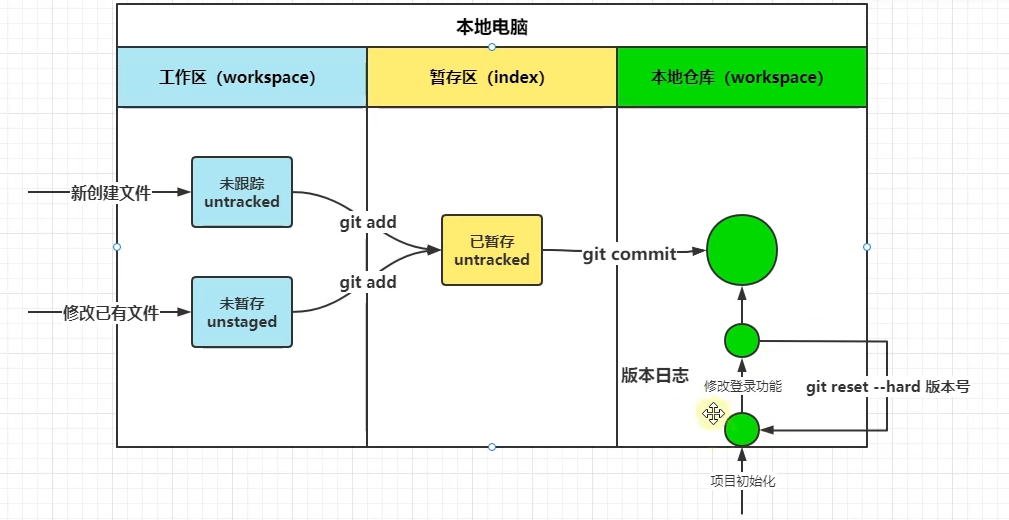
7.1 工作区到本地仓库
新建的本地文件(untracked) / commit后又修改过的已有文件(unstaged),存在于工作区中,如果想要提交到远程GitHub仓库:首先需要先提交到暂存区,然后提交到本地仓库,最后再提交到远程仓库。
设置用户标签(安装完git设置一下),用于团队开发时标识修改者:
git config --global user.name 用户名
git config --global user.email 邮箱
初始化本地仓库:(先cd到项目文件夹内)
git init
查看本地仓库状态:
git status
添加/移除暂存区(.表示当前目录下所有文件):
git add 文件名 / git add .
git rm --cached 文件名
提交本地仓库(将暂存区的文件提交到本地仓库):
git commit -m "日志信息"
查看日志:(多次commit后,用于查看commit版本号,用于版本切换)
git reflog
版本切换:(将本地仓库中的指定版本的代码覆盖工作区的代码)
git reset --hard 版本号
7.2 本地仓库的分支操作
团队开发中,除了master主分支的codebase代码,还需要其他人员进行不同模块的代码编写,为例不影响master分支的代码功能,就需要创建其他的子分支(拷贝master某个版本的代码),在其基础上添加新模块,最后再合并回master分支。
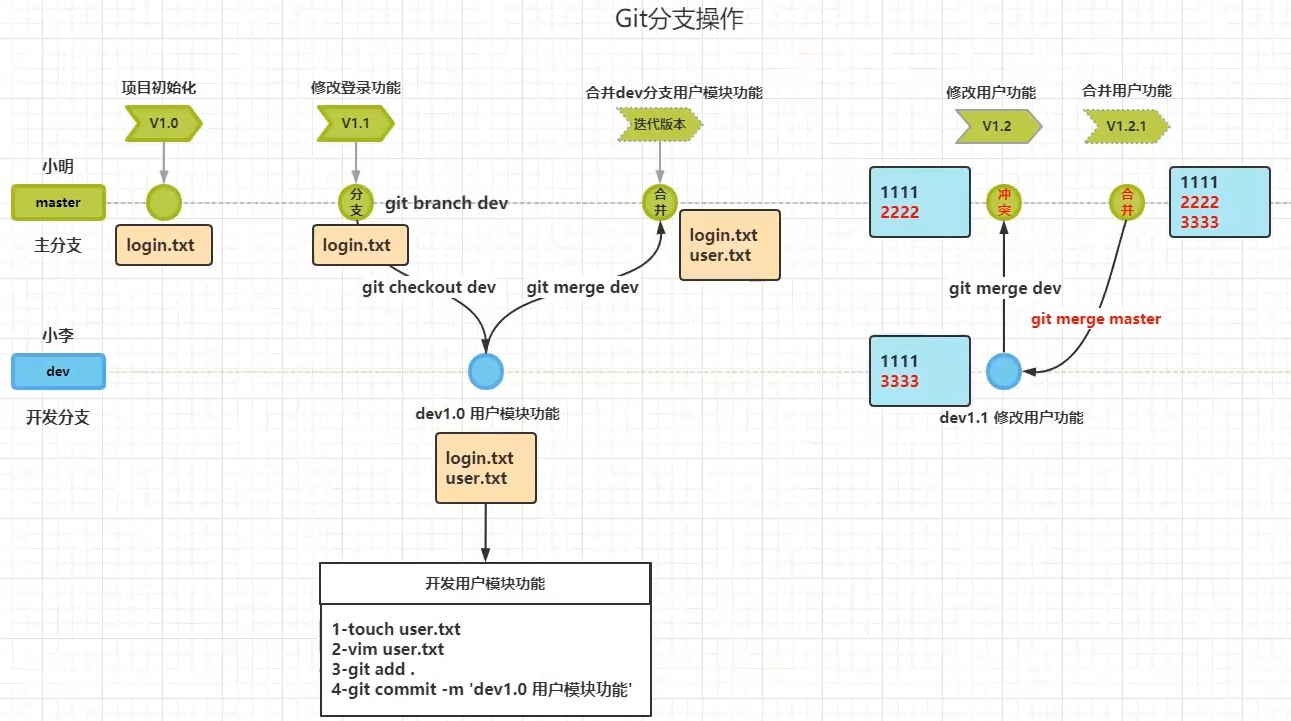
查看所有分支:
git branch -v
创建子分支:
git branch 分支名
切换分支:(-b是如果没有该分支,就创建一个)
git checkout 分支名
git checkout -b 分支名
删除子分支:
git branch -d 分支名
在新分支中我们就可以修改和添加新的代码,然后add和commit,把子分支提交到本地仓库。
合并分支(例如我们有master分支和dev分支,我们希望将dev的子模块代码合并进入master):
git checkout master
git merge 子分支名
合并冲突:(如果不止是添加了新文件,还修改了master中的已有文件代码,当master分支和子分支修改了相同文件且都commit后,合并时就会冲突merge conflict,需要指定使用master的还是子分支的)
手动修改冲突的文件
git add 冲突的文件
git commit -m 'fix file.py merge conflict'
之后在子分支中,再用merge合并来自master的代码就可以,也不会发生冲突。
分支的命名规范:

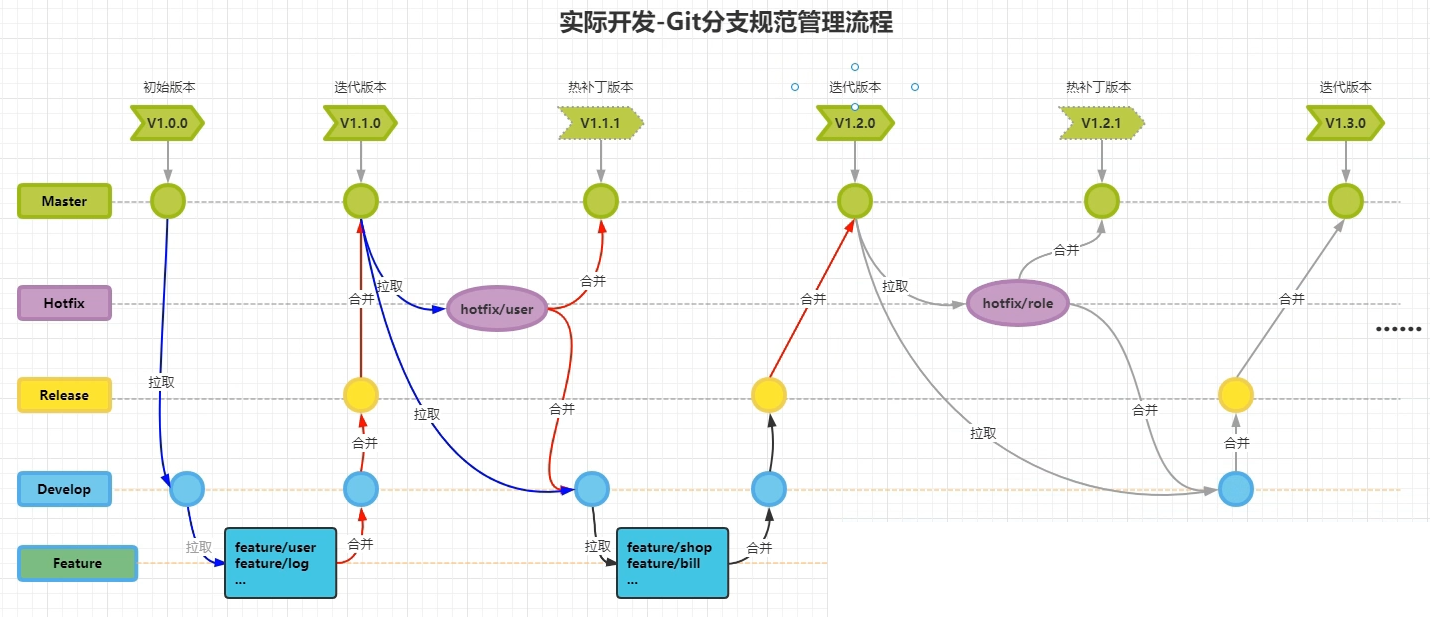
7.3 本地仓库到远程仓库
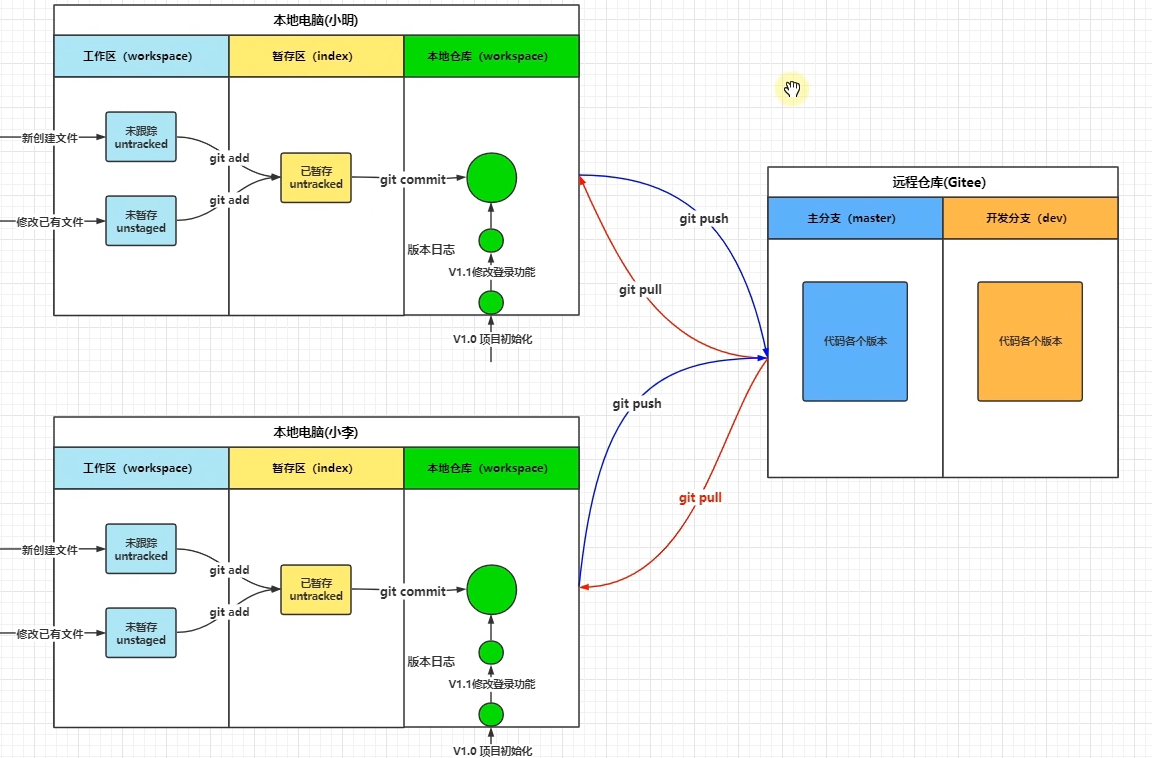
前面讲的操作都是单个开发者在一台电脑上进行项目不同版本的开发。当涉及多个不同的远程开发者时,就需要GitHub、GitLab、Gitee等远程开发仓库了。不同的开发者可以pull和push项目的不同分支的不同版本。
配置ssh:(在本地生成ssh公钥,复制到远程仓库的web账号setting里)
ssh-keygen -t rsa # 本地生成公钥
cat ~/.ssh/id_rsa.pub # 打印公钥
复制到web账号的setting里
git -T git@github.com # 验证公钥
添加远程仓库:(origin是仓库的别名,默认就用这个,仓库地址从web端粘贴)
git remote add origin 仓库地址
推送远程仓库:(把本地master分支推送到名为origin的远程仓库的master分支)
git push origin master
注意【先pull再push】:当团队多人开发时,当他人对远程仓库某个分支修改后,我们也进行了修改,打算push时,就会失败,需要先进行pull把别人修改的部分拉取到本地,合并后再push。
但是每次push时都需要指定远程仓库名和分支名,太过繁琐,一种更加方便的方式是,将当前本地分支与远程仓库的分支建立关联,后面只用git push就能推送到远程仓库。
建立关联:
git push --set-upstream orgin master # 建立关联
git branch -vv # 查看关联
git push # 建立好关联后,直接可以推送
克隆:默认克隆master分支
git clone 仓库路径 本地目录
7.4 远程仓库的分支操作
远程仓库创建新的分支:github无法web端手动操作,因此需要先在本地仓库创建子分支,然后推送到远程仓库。
git checkout -b 子分支名 # 直接新建一个分支然后切换至新创建的分支
git push origin 子分支名 # 将新分支推动到远程仓库,等效创建远程仓库分支
推送到远程仓库子分支:(远程仓库名为origin)
git push origin 子分支名
抓取(很少用):将远程仓库内的更新都抓取到本地仓库,不会进行合并(如果不指定远程仓库名和分支名,就抓取所有分支)
git fetch origin master
拉取(多用):将远程仓库的修改拉到本地,自动进行合并(等于fetch+merge)
git pull origin master
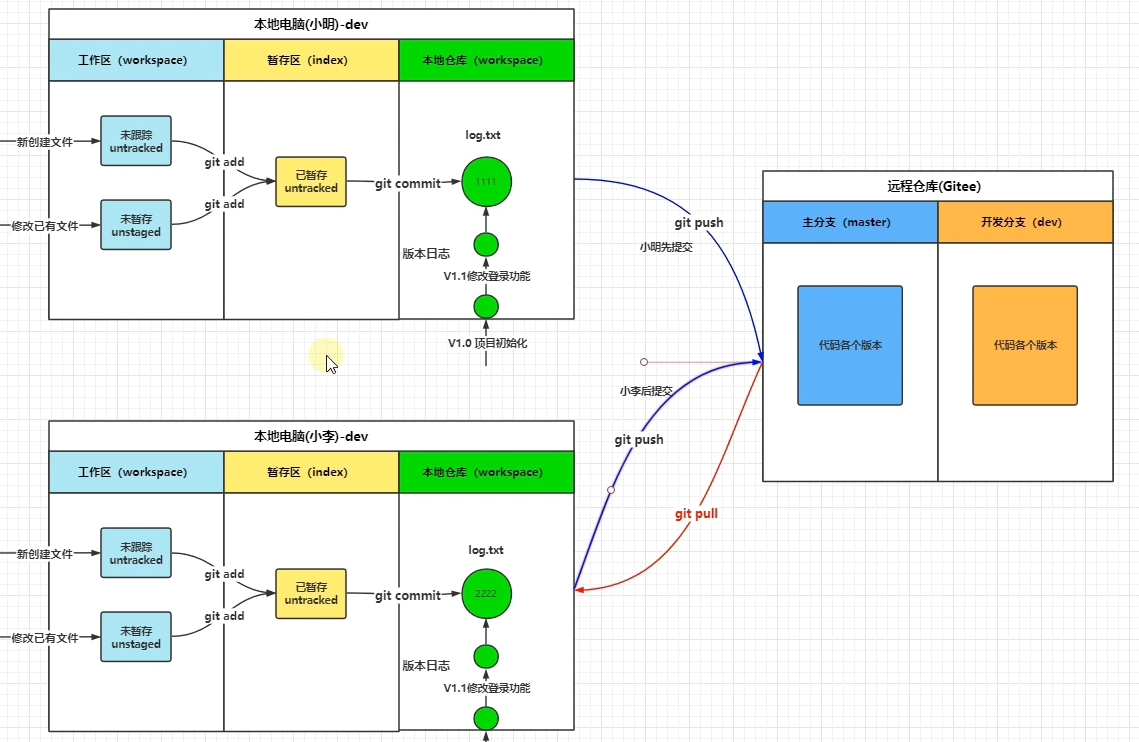
合并冲突:不同的人对远程仓库的同一个地方编写了不同的代码,先后进行push时,后push的开发者,就会报合并冲突错误,我们可以使用类似本地分支冲突的解决方案:先在【先pull后push】,在pull的合并冲突报错后,本地人工修改冲突的地方,然后add和commit,最后再push。
8. 文件云存储
8.1 Amazon S3
Amazon Web Services Simple Storage Service (AWS S3)是亚马逊公司提供的,一种存储和检索任意数量的数据的服务,使用 高度 可扩展、可靠、快速且廉价的数据存储。当我们下载和配置awscli后就可以使用了。
SSD存储池:加速小文件读写
HDD存储池:提供超大容量的数据存储
AWS S3使用存储桶和对象来操作存储数据。存储桶是存放对象的容器(类似电脑的分区/盘)。对象指的是一个文件和描述该文件的任何元数据(存在电脑分区。盘中的文件)。要在 Amazon S3 中存储对象,您需要创建存储桶,然后将该对象上传到存储桶。当对象位于存储桶时,您可以将其打开、下载并移动它。当您不再需要对象或存储桶时,可以清理您的资源。
创建桶(make bucket):输入以下指令,创建一个名为”myBucket”的桶,注意:每个bucket_name集群唯一,如果已有该bucket_name,会报错bucketalreadyexis。
aws s3 mb s3://myBucket
查看所有已创建的桶:
aws s3 ls
上传对象:可将位于本地myFolder目录中的myFile.txt,上传至创建的myBucket桶中
s3 cp myFolder/myFile.txt s3://myBucket/
查看桶中文件:
aws s3 ls s3://myBucket
下载对象:通过复制的方式将位于myBucket桶中的myFile.txt文件,下载至本地myFolder目录,并重命名为myFile2.txt
aws s3 cp s3://myBucket/myFile.txt myFolder/myFile2.txt
删除对象:删除位于myBucket桶中的myFile.txt对象
aws s3 rm s3://myBucket/myFile.txt
删除桶(remove bucket):删除myBucket桶
aws s3 rb s3://myBucket




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











