






Hadoop的安装没有头绪吧,我来手把手教会你安装和使用Hadoop
这里我首先把安装所需要的资料放在这里,这里有你所需的java,Hadoop,spark等众多资源,后续还在更新,密码: 6uw6 --来自百度网盘超级会员V4的分享
开始进入正题
Hadoop的安装
在安装之前我们必须要先安装虚拟机,这个如果不会,私聊小编,发教程。
安装jdk
由于小编用的是MacBook笔记本,所以没有可用的xshell,我用的是电脑自带的终端,win本的童鞋,可以安装shell来进行操作,xshell我会放在文章的末尾。
win本
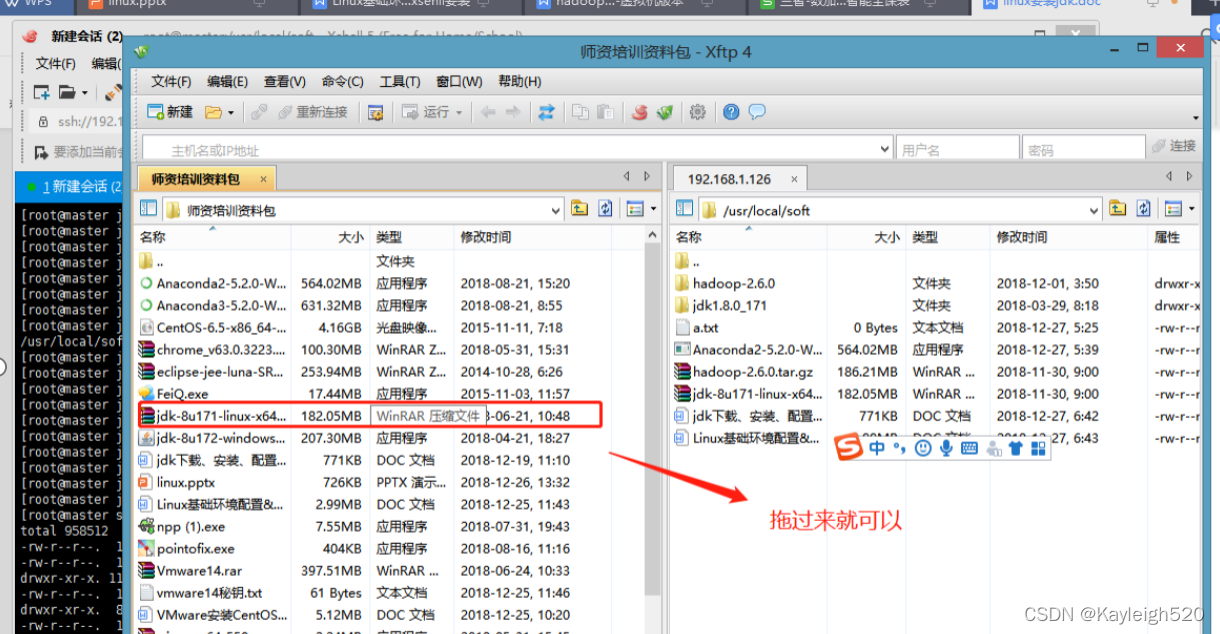
使用Xftp 将java的压缩包拖到linux下面。
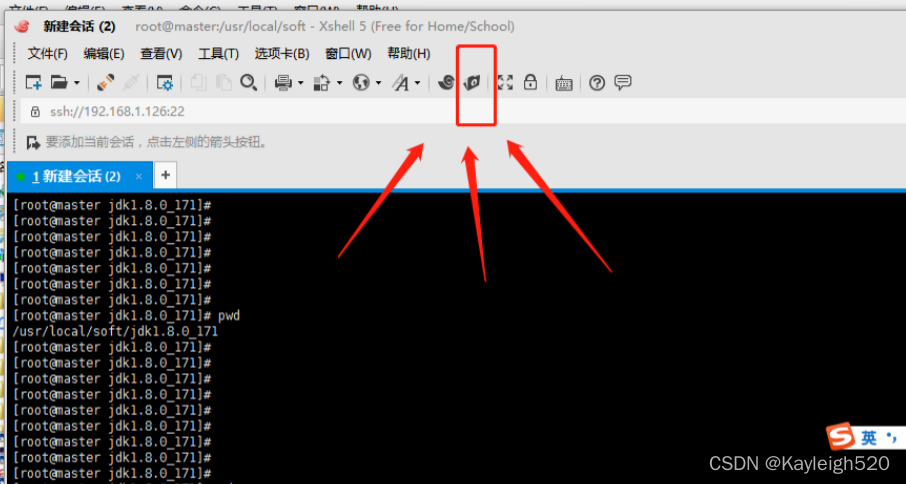
1. 安装xftp(安装完成以后不用管)
2. 打开xshell的文件传输窗口,根据提示输入地址和命令。
3. 将java压缩包拖到linux下面
第四步以后,MacBook和win本的安装步骤都是一样的了,因为都是在虚拟机中安装java和Hadoop。
如果使用的是MacBook,在终端连接虚拟机以后,直接用指令
scp -r /文件目录/ root@IP /你所要保存的目录/
举个例子:

应该是很详细了吧,如果传输指令不会用的话,建议多练练虚拟机,多熟练一下,不用刻意去背。
4. linux下面解压:
使用命令:
tar -zxvf jdk-8u171-linux-x64.tar.gz
解压过后,开始修改环境变量。
在profile文件下修改
vim /etc/profile

注意:
千万不要修改profile中的文件,要不然会造成你的指令都用不了,那有没有办法解决呢,既然小编决定教你们安装Hadoop,当然一些小编初学的时候犯的错误都会给大家安排上,直接输入这句话
export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
然后你就可以使用指令啦,还不赶紧去试试
在profile文件中添加这句话:
然后按下 i 键 进入编辑模式。
插入下面两两行路径:注意jdk的路径不要写错
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
export PATH=.:$JAVA_HOME/bin:$PATH
注意,可能小白就直接复制粘贴进去了,这个时候你需要找到你的java放在哪个文件夹下面,长点心哦。
最后:
保存:按住 shfit+冒号(:)输入wq是保存:
然后执行命令:source /etc/profile
检验jdk是否安装成功:
java -version
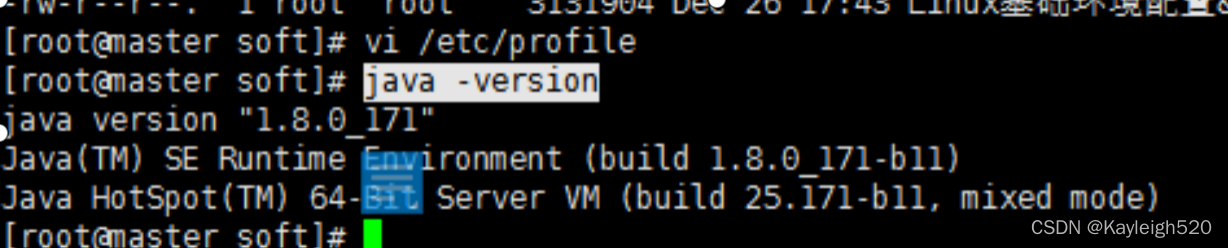
出现这个就代表你的jdk安装完成了,如果没有这句话就说明你的java安装失败了,有任何问题直接联系小编哦。
下面开始安装Hadoop
Hadoop安装
防火墙
1. 首先你需要关闭防火墙,这里给出centos6和centos7的指令:
centos6的关闭防火墙:service iptables stop
centos6的关闭防火墙开机自启动:chkconfig iptables off
centos7的关闭防火墙:systemctl stop firewalld
centos7的关闭防火墙开机自启动:systemctl disable firewalld
centos7的查看防火墙的状态:systemctl status firewalld
这里说一下为什么要关闭开机自启,因为你关闭防火墙的时候,每次启动都会自动打开防火墙
然后关机,克隆三台虚拟机,克隆的时候选择完整克隆,不要使用链接克隆,克隆的过程就不说了,直接关机然后右键虚拟机,就能找到虚拟机克隆
免密登陆
1.设置主机名与IP映射
首先设置主机名与IP映射,如果不修改ip映射,后面网页可视化界面可能会导致看不到节点,就会发生错误
修改配置文件命令:vi /etc/hosts

这里的IP是我自己的,(我新建了三台虚拟机来做的安装步骤教程)
2. 安装密钥
主节点执行命令ssh-keygen -t rsa 产生密钥 一直回车
执行命令
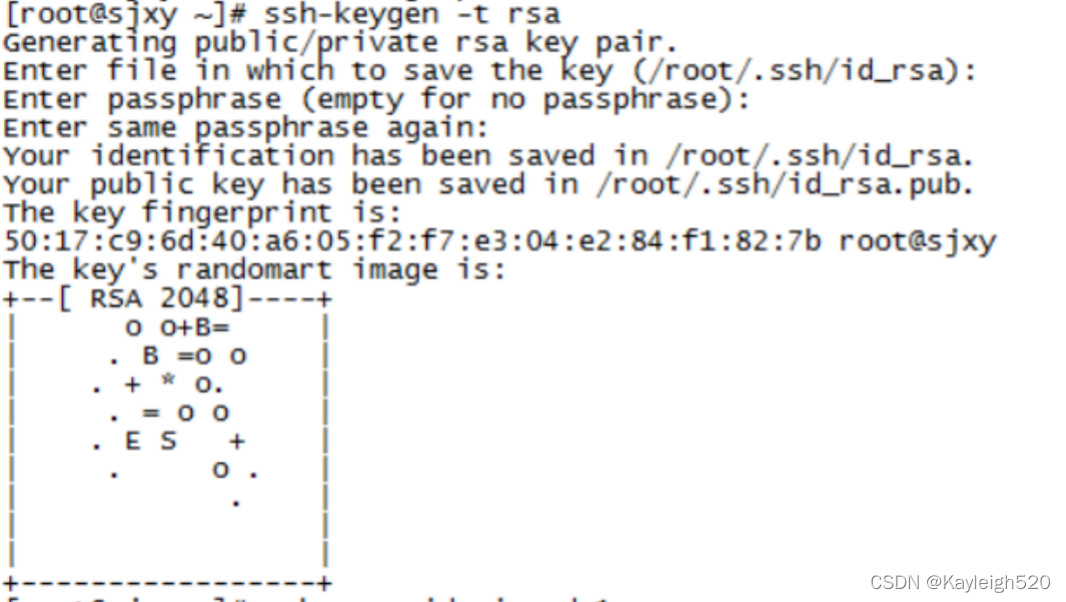
将密钥拷贝到其他两个子节点,命令如下:
ssh-copy-id -i node1
ssh-copy-id -i node2
实现免密码登录到子节点。
实现主节点master本地免密码登录
首先进入到/root 命令:cd /root
再进入进入到 ./.ssh目录下
命令:cd ./.ssh/
然后将公钥写入本地执行命令:
cat ./id_rsa.pub >> ./authorized_keys
出现以下界面就说明添加成功了。

3. 将hosts文件拷贝到node1和node2节点
scp /etc/hosts node1:/etc/hosts
scp /etc/hosts node2:/etc/hosts
- 新建soft目录
mkdir /usr/local/soft
将hadoop的jar包先上传到虚拟机/usr/local/soft目录下,主节点。

5. 解压
tar -zxvf hadoop-2.7.6.tar.gz
解压完后会出现 hadoop-2.7.6的目录
- 修改配置文件
修改master中hadoop的一个配置文件/usr/local/soft/hadoop-2.7.6/etc/hadoop/slaves
删除原来的所有内容,修改为如下
node1
node2
请一定要注意配置文件内容的格式,可以直接复制过去黏贴。不要随意改
修改hadoop-env.sh文件
打开hadoop-env.sh文件
插入:
加上一句:
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
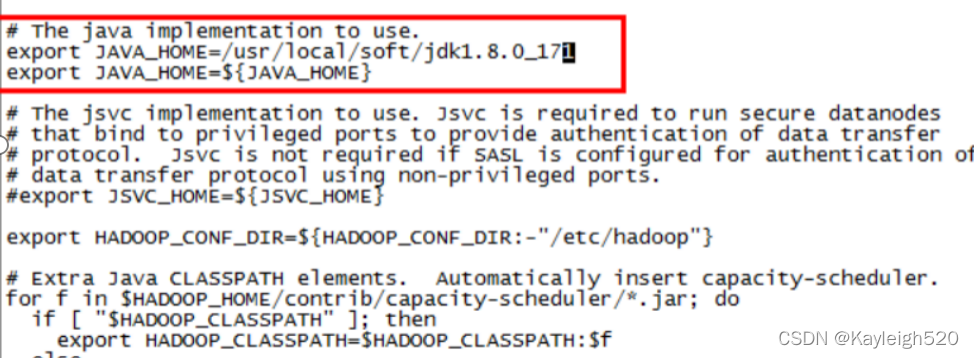
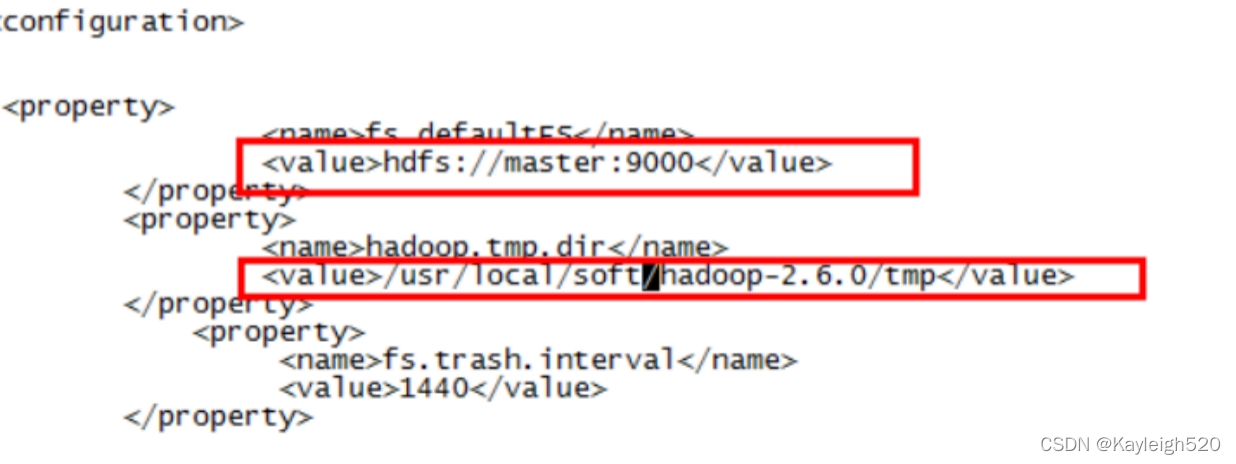
修改core-site.xml文件
注意这里面需要修改你的Hadoop的文件目录地址,切记一定要修改
将下面的配置参数加入进去修改成对应自己的
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.6.0/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
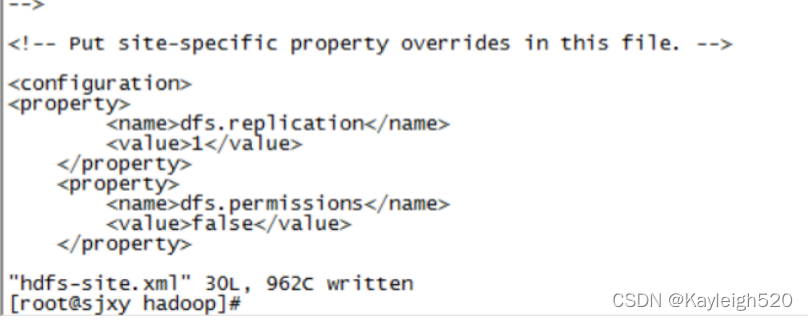
修改 hdfs-site.xml
修改 hdfs-site.xml 将dfs.replication设置为1
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
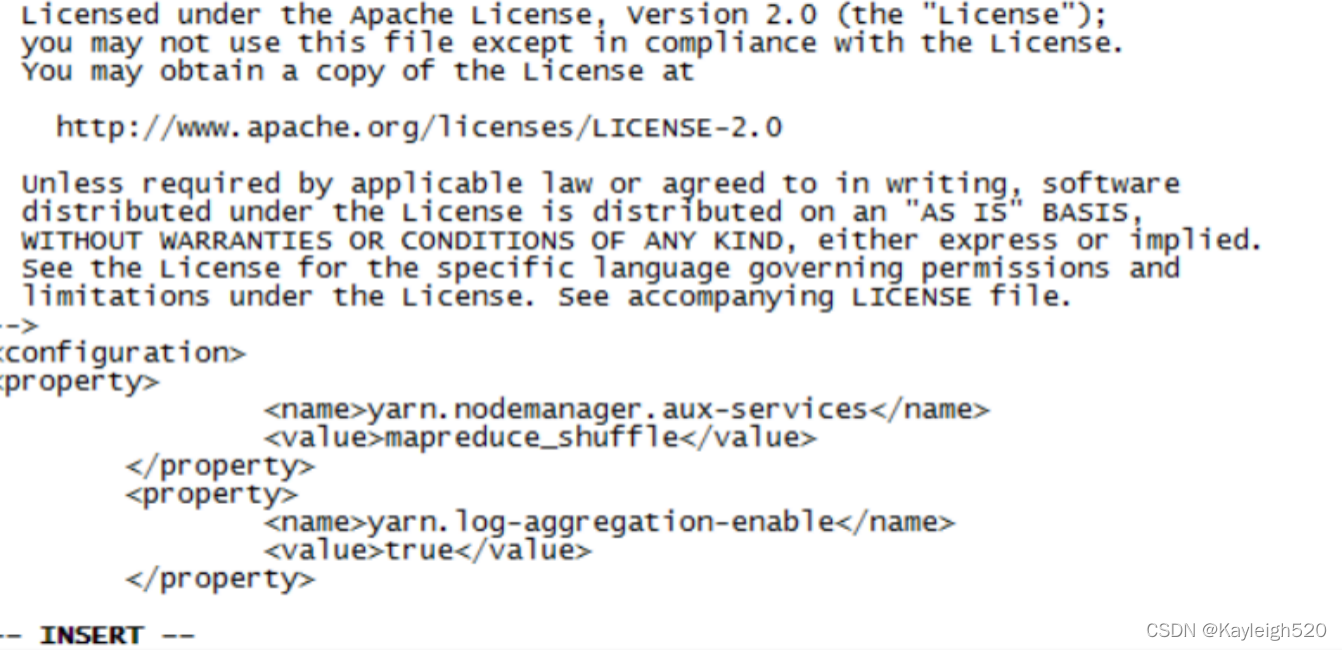
修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
修改 mapred-site.xml
修改 mapred-site.xml(将mapred-site.xml.template 复制一份为 mapred-site.xml
命令:cp mapred-site.xml.template mapred-site.xml)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
到这里配置文件就已经更改好了,配置文件有我这个就够了,不需要参考其他文件,保证不会出错系列
- 传文件
将hadoop的安装目录分别拷贝到其他子节点
scp -r /usr/local/soft/hadoop-2.6.0 node1:/usr/local/soft/
scp -r /usr/local/soft/hadoop-2.6.0 node2:/usr/local/soft/
然后进行写一步,格式化命令:
首先看下hadoop-2.6.0目录下有没有tmp文件夹。
如果没有 执行一次格式化命令:
cd /usr/local/soft/hadoop-2.6.0目录下
执行命令:
./bin/hdfs namenode -format
会生成tmp文件。
然后
/usr/local/soft/hadoop-2.6.0目录下
启动执行:./sbin/start-all.sh
这里通过jps查看主节点进程是不是缺少
主节点进程为下面几个(下面是进程名称,不是命令):
Namenode
secondarnamenode
resourcemanager
子节点进程 (在node1和node2上分别输入命令:jps)
datanode
nodenodemanager
验证hdfs:
可以windows电脑登录浏览器(强烈建议chrome浏览器)
地址:192.168.73.134:50070 (ip地址是master的地址)
看到下面页面证明 hdfs装好了
下图是我已经创建了一个hdfs上的目录,刚装好的hadoop应该是空的什么都没有
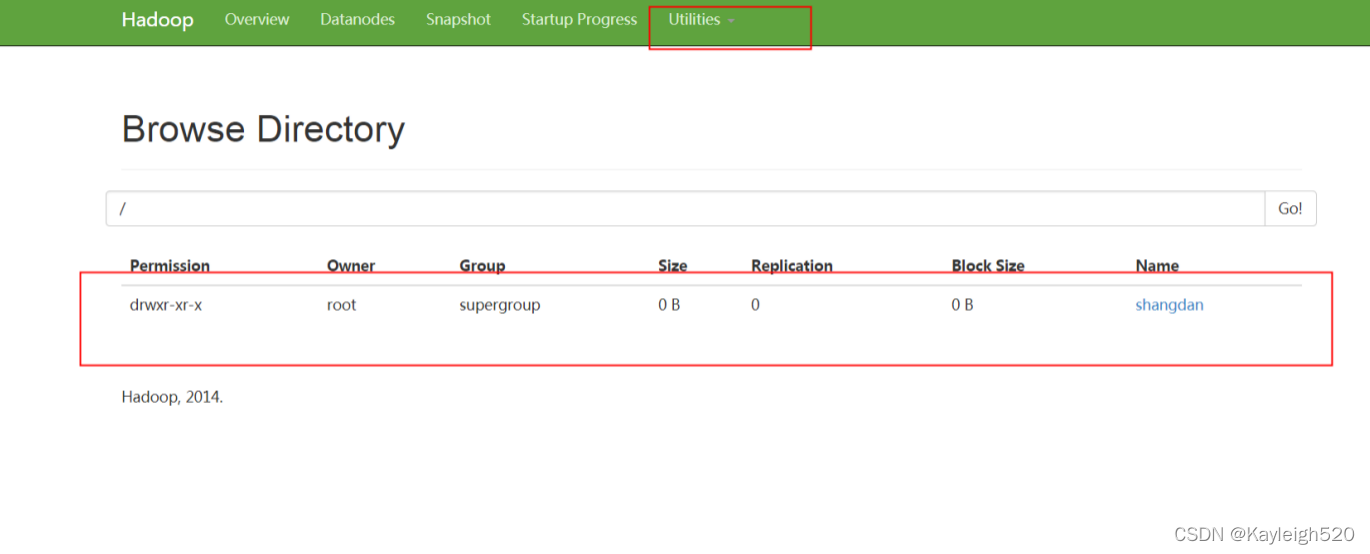
******* 如果第一次启动失败了,请重新检查配置文件或者哪里步骤少了。
再次重启的时候
1需要手动将每个节点的tmp目录删除:
rm -rf /usr/local/soft/hadoop-2.6.0/tmp
然后执行将namenode格式化
2在主节点执行命令:
./bin/hdfs namenode -format
建议:
大家在完成hadoop集群搭建以后,建议搭建把虚拟机的三个节点在vmware中挂起,,不要关机(关机相当于把集群直接断电,再次启动会异常,下次电脑直接继续运行虚拟机就可以)
到此,Hadoop就已经安装完成了,很简单,细心一点就没什么问题,下一章节我们说hdfs是我使用,以及hdfs的Java操作
















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









