







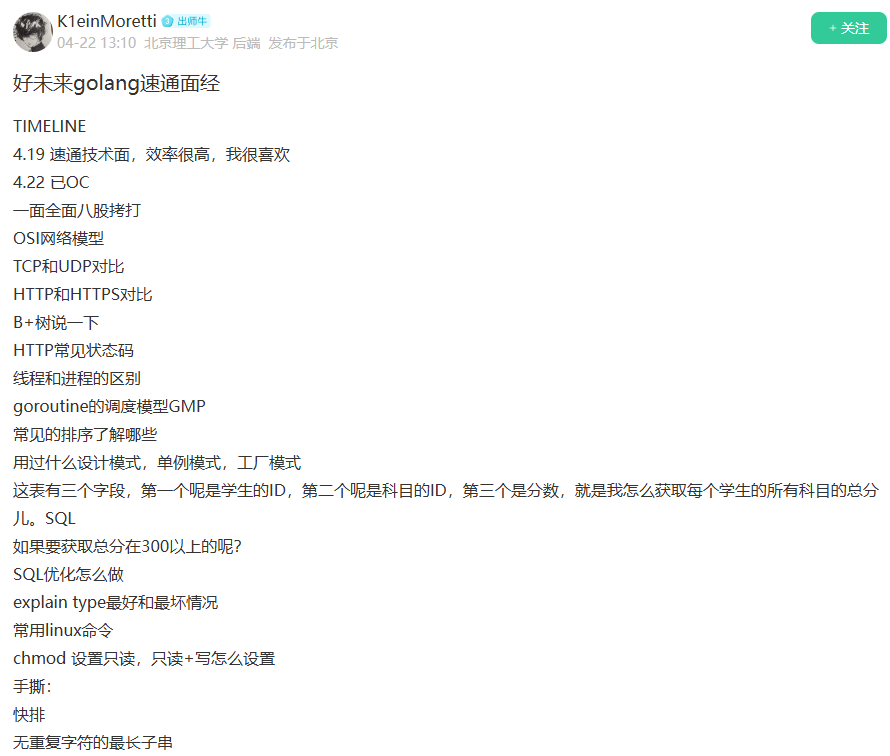
OSI网络模型
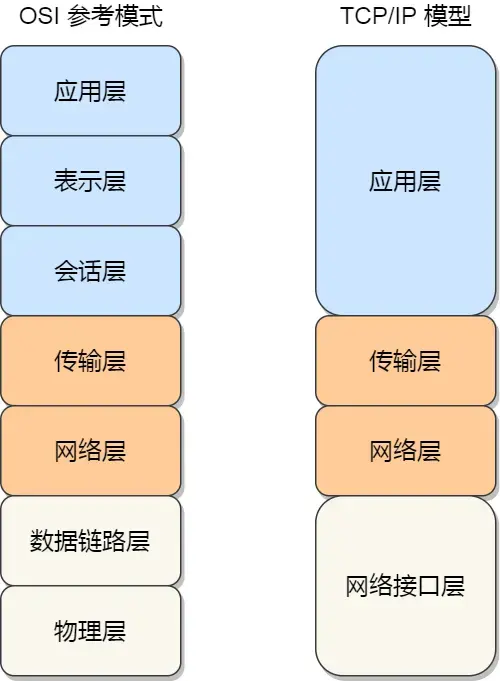

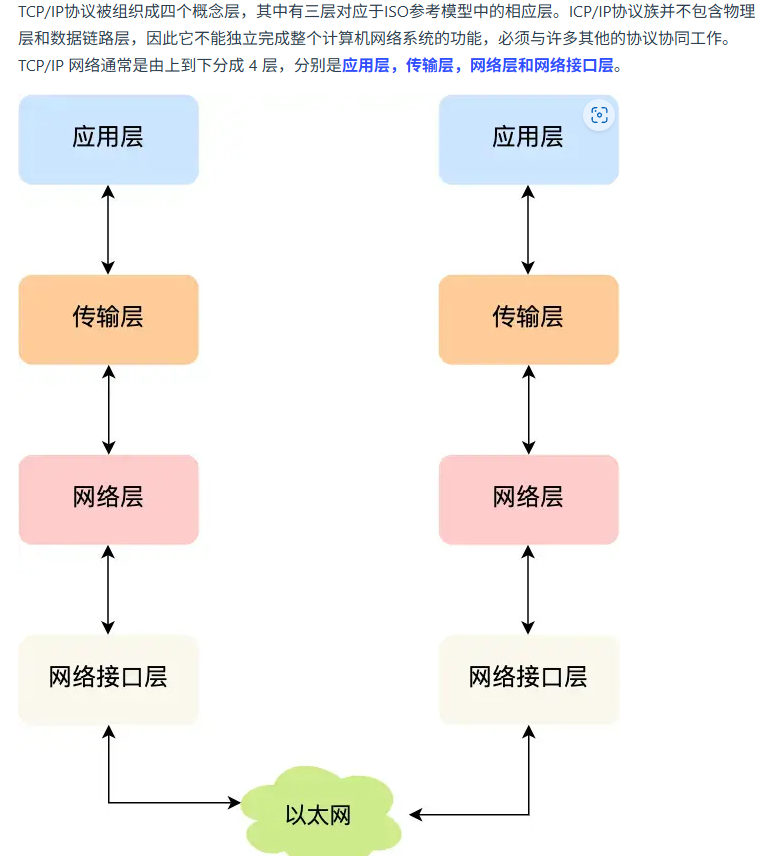

TCP和UDP对比

HTTP和HTTPS对比

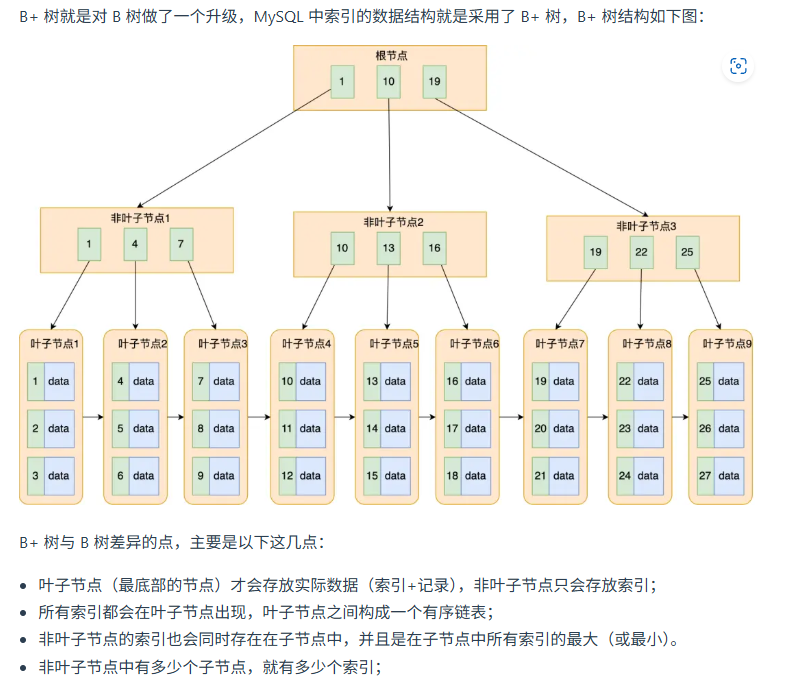
B+树
HTTP常见状态码

线程和进程的区别

goroutine的调度模型GMP

常见的排序了解哪些
快速排序
func quickSort(data []int) {
if len(data) <= 1 {
return
}
base := data[0]
l, r := 0, len(data)-1
for i := 1; i <= r; {
if data[i] > base {
data[i], data[r] = data[r], data[i]
r--
} else {
data[i], data[l] = data[l], data[i]
l++
i++
}
}
quickSort(data[:l])
quickSort(data[l+1:])
}
func main() {
s := make([]int, 0, 16)
for i := 0; i < 16; i++ {
s = append(s, rand.Intn(100))
}
fmt.Println(s)
quickSort(s)
fmt.Println(s)
}
归并排序
func mergeSort(data []int) []int {
length := len(data)
if length <= 1 {
return data
}
num := length / 2
left := mergeSort(data[:num])
right := mergeSort(data[num:])
return merge(left, right)
}
func merge(left, right []int) (result []int) {
l, r := 0, 0
for l < len(left) && r < len(right) {
if left[l] < right[r] {
result = append(result, left[l])
l++
} else {
result = append(result, right[r])
r++
}
}
result = append(result, left[l:]...)
result = append(result, right[r:]...)
return
}
func main() {
s := make([]int, 0, 16)
for i := 0; i < 16; i++ {
s = append(s, rand.Intn(100))
}
fmt.Println(s)
s = mergeSort(s)
fmt.Println(s)
}
堆排序
func heapSort(array []int) {
m := len(array)
s := m / 2
for i := s; i > -1; i-- {
heap(array, i, m-1)
}
for i := m - 1; i > 0; i-- {
array[i], array[0] = array[0], array[i]
heap(array, 0, i-1)
}
}
func heap(array []int, i, end int) {
l := 2*i + 1
if l > end {
return
}
n := l
r := 2*i + 2
if r <= end && array[r] > array[l] {
n = r
}
if array[i] > array[n] {
return
}
array[n], array[i] = array[i], array[n]
heap(array, n, end)
}
func main() {
s := make([]int, 0, 16)
for i := 0; i < 16; i++ {
s = append(s, rand.Intn(100))
}
fmt.Println(s)
heapSort(s)
fmt.Println(s)
}
用过什么设计模式,单例模式,工厂模式
设计模式是解决软件设计中常见问题的可复用方案。单例模式和工厂模式是两种最常用的设计模式,以下是它们的核心原理、实现方式及实际应用场景:
一、单例模式 (Singleton Pattern)
核心思想
确保一个类只有一个实例,并提供全局访问点。
应用场景
- 日志记录器(全局唯一日志对象)
- 数据库连接池(避免重复创建连接)
- 配置管理(统一读取配置文件)
- 缓存管理器(如 Redis 客户端实例)
关键实现方式
-
饿汉式(线程安全,但可能浪费资源)
public class Singleton { private static final Singleton instance = new Singleton(); private Singleton() {} // 私有构造方法 public static Singleton getInstance() { return instance; } } -
懒汉式(延迟加载,需处理线程安全)
public class Singleton { private static volatile Singleton instance; private Singleton() {} public static Singleton getInstance() { if (instance == null) { synchronized (Singleton.class) { if (instance == null) { instance = new Singleton(); } } } return instance; } }- 双重检查锁定(Double-Checked Locking):解决同步性能问题。
volatile关键字:禁止指令重排序,避免未初始化完成的对象被访问。
-
静态内部类(推荐方式,线程安全且延迟加载)
public class Singleton { private Singleton() {} private static class Holder { private static final Singleton instance = new Singleton(); } public static Singleton getInstance() { return Holder.instance; } }
注意事项
- 反射攻击:通过反射调用私有构造方法可破坏单例,需在构造方法中增加防御逻辑。
- 序列化问题:反序列化可能生成新对象,需实现
readResolve()方法返回单例实例。
二、工厂模式 (Factory Pattern)
核心思想
将对象的创建与使用分离,通过工厂类统一管理对象的实例化过程。
三种变体及区别
| 类型 | 特点 | 适用场景 |
|---|---|---|
| 简单工厂 | 一个工厂类生产多种产品,通过参数区分 | 产品类型少且逻辑简单 |
| 工厂方法 | 每个产品对应一个工厂类,通过子类实现扩展 | 需要扩展新类型,避免修改已有代码 |
| 抽象工厂 | 生产一组相关或依赖的产品(产品族) | 需要创建多个关联对象(如UI主题) |
1. 简单工厂(Simple Factory)
public class ShapeFactory {
public Shape createShape(String type) {
if ("circle".equals(type)) {
return new Circle();
} else if ("square".equals(type)) {
return new Square();
}
throw new IllegalArgumentException("Unknown shape type");
}
}
- 缺点:新增类型需修改工厂类,违反开闭原则。
2. 工厂方法(Factory Method)
// 抽象工厂接口
public interface ShapeFactory {
Shape createShape();
}
// 具体工厂类
public class CircleFactory implements ShapeFactory {
@Override
public Shape createShape() {
return new Circle();
}
}
public class SquareFactory implements ShapeFactory {
@Override
public Shape createShape() {
return new Square();
}
}
- 优点:新增产品时只需添加新工厂类,无需修改已有代码。
3. 抽象工厂(Abstract Factory)
// 抽象工厂接口(生产一组关联产品)
public interface GUIFactory {
Button createButton();
Checkbox createCheckbox();
}
// 具体工厂:Windows风格组件
public class WindowsFactory implements GUIFactory {
@Override
public Button createButton() {
return new WindowsButton();
}
@Override
public Checkbox createCheckbox() {
return new WindowsCheckbox();
}
}
// 具体工厂:MacOS风格组件
public class MacOSFactory implements GUIFactory {
@Override
public Button createButton() {
return new MacOSButton();
}
@Override
public Checkbox createCheckbox() {
return new MacOSCheckbox();
}
}
- 应用场景:跨平台UI组件、数据库驱动(如MySQL/Oracle连接器)。
三、实际项目中的应用示例
单例模式案例
- 日志工具类:
public class Logger { private static Logger instance; private Logger() {} // 禁止外部实例化 public static synchronized Logger getInstance() { if (instance == null) { instance = new Logger(); } return instance; } public void log(String message) { // 写入日志文件 } }
工厂模式案例
- 数据库连接池:
public interface ConnectionFactory { Connection createConnection(); } public class MySQLConnectionFactory implements ConnectionFactory { @Override public Connection createConnection() { return DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb"); } } public class PostgreSQLConnectionFactory implements ConnectionFactory { @Override public Connection createConnection() { return DriverManager.getConnection("jdbc:postgresql://localhost:5432/mydb"); } }
四、设计模式的选择原则
-
单例模式:
- 需严格控制全局唯一实例时使用。
- 避免滥用,可能导致资源无法释放或单元测试困难(如Mock对象替换问题)。
-
工厂模式:
- 对象创建逻辑复杂或需要解耦时优先使用。
- 简单场景可直接用
new,复杂场景(如依赖注入)可结合Spring等框架。
五、常见误区
- 单例模式的线程安全问题:未正确使用双重检查锁定或静态内部类可能导致多实例。
- 工厂模式的过度设计:若对象创建逻辑简单,直接实例化更清晰。
- 忽略开闭原则:通过工厂方法或抽象工厂扩展,而非修改已有代码。
六、其他常用设计模式
- 观察者模式:事件驱动系统(如消息订阅)。
- 策略模式:算法族封装,动态切换(如支付方式选择)。
- 装饰器模式:动态扩展对象功能(如Java I/O流)。
根据具体需求选择合适的设计模式,避免为了模式而模式。
这表有三个字段,第一个呢是学生的ID,第二个呢是科目的ID,第三个是分数,怎么获取每个学生的所有科目的总分
select SID, SUM(score) AS total_score FROM student_score GROUP BY SID
如果要获取总分在300以上的呢?
select SID, SUM(score) AS total_score FROM student_score GROUP BY SID HAVING total_score > 300
having与where的区别:
having是在分组后对数据进行过滤
where是在分组前对数据进行过滤
having后面可以使用聚合函数
where后面不可以使用聚合
SQL优化怎么做
们需要明确SQL查询的性能瓶颈在哪里。这通常可以通过查看查询的执行计划来实现。数据库管理系统(如MySQL、PostgreSQL等)提供了EXPLAIN命令,可以帮助我们了解查询是如何被执行的,包括使用的索引、扫描的行数等信息。
- 索引优化:确保在查询条件中使用的列上有适当的索引。例如,如果经常按某个字段进行过滤或排序,可以考虑为该字段创建索引。
- 查询重写:简化复杂的子查询,尽量避免使用SELECT *,只选择需要的列以减少数据传输量。
- 减少计算:避免在WHERE子句中对列进行函数操作或类型转换,因为这可能会导致索引失效。
要优化 SQL 查询以获取每个学生的所有科目的总分,可以考虑以下几点:
1. 使用索引
确保在 student_id 和 score 字段上创建索引,这样可以加快查询速度。创建索引的 SQL 语句如下:
CREATE INDEX idx_student_id ON scores(student_id);
2. 合理选择字段
如果只需要学生 ID 和总分,确保只选择这两个字段,可以减少数据传输量。
3. 查询优化
使用如下查询来获取每个学生的总分:
SELECT student_id, SUM(score) AS total_score
FROM scores
GROUP BY student_id;
4. 数据分区
如果表非常大,可以考虑对数据进行分区(例如按学期或年份分区),这样在查询时可以更快地定位相关数据。
5. 确保表的设计合理
确保表的设计规范,避免冗余数据。例如,确保没有重复的记录。
6. 使用物化视图
如果这个查询非常频繁并且数据更新不太频繁,可以考虑创建一个物化视图,定期更新:
CREATE MATERIALIZED VIEW student_total_scores AS
SELECT student_id, SUM(score) AS total_score
FROM scores
GROUP BY student_id;
7. 监测和调试
使用数据库的执行计划功能来分析查询的性能,识别瓶颈并进行针对性的优化。
总结
通过创建索引、合理选择字段、数据分区、物化视图等方法,可以显著提升 SQL 查询的性能。
explain type最好和最坏情况
参考:https://blog.csdn.net/why15732625998/article/details/80388236
- EXPLAIN简介
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。
➤ 通过EXPLAIN,我们可以分析出以下结果:
表的读取顺序
数据读取操作的操作类型
哪些索引可以使用
哪些索引被实际使用
表之间的引用
每张表有多少行被优化器查询
➤ 使用方式如下:
EXPLAIN +SQL语句
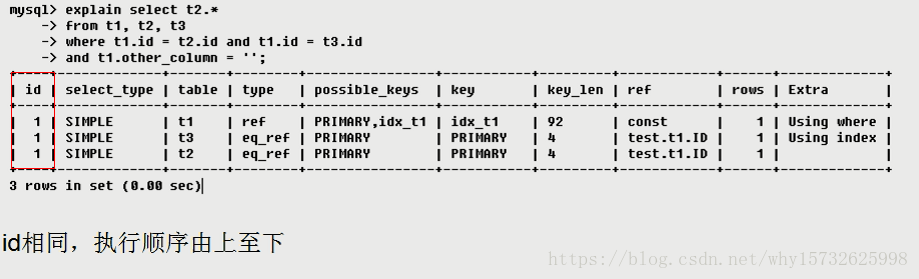
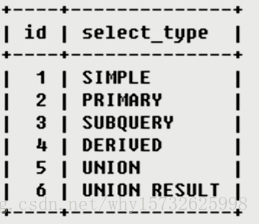
分别用来表示查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
SIMPLE 简单的select查询,查询中不包含子查询或者UNION
PRIMARY 查询中若包含任何复杂的子部分,最外层查询则被标记为PRIMARY
SUBQUERY 在SELECT或WHERE列表中包含了子查询
DERIVED 在FROM列表中包含的子查询被标记为DERIVED(衍生),MySQL会递归执行这些子查询,把结果放在临时表中
UNION 若第二个SELECT出现在UNION之后,则被标记为UNION:若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED
UNION RESULT 从UNION表获取结果的SELECT
type所显示的是查询使用了哪种类型,type包含的类型包括如下图所示的几种:
从最好到最差依次是:
system > const > eq_ref > ref > range > index > all
一般来说,得保证查询至少达到range级别,最好能达到ref。
- system 表只有一行记录(等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计
- const 表示通过索引一次就找到了,const用于比较primary key 或者unique索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL就能将该查询转换为一个常量。
- eq_ref 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
- ref 非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体。
- range 只检索给定范围的行,使用一个索引来选择行,key列显示使用了哪个索引,一般就是在你的where语句中出现between、< 、>、in等的查询,这种范围扫描索引比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
- index Full Index Scan,Index与All区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和Index都是读全表,但index是从索引中读取的,而all是从硬盘读取的)
- all Full Table Scan 将遍历全表以找到匹配的行
常用linux命令

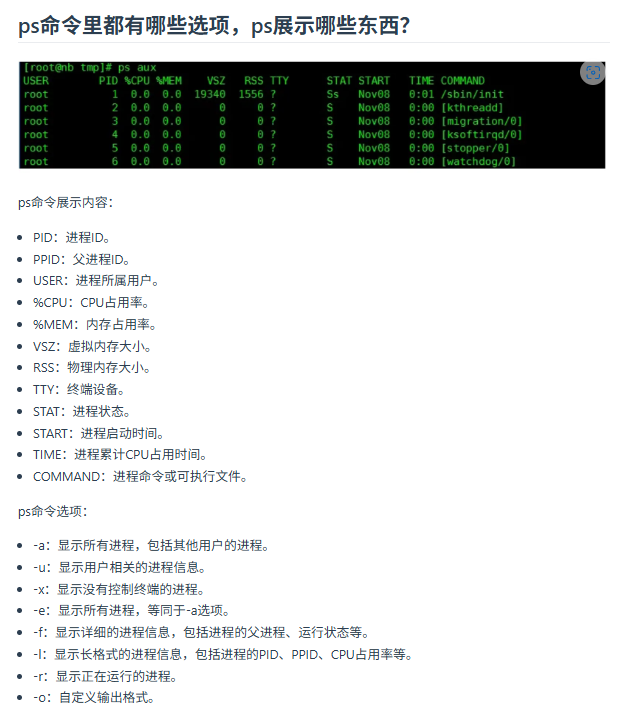
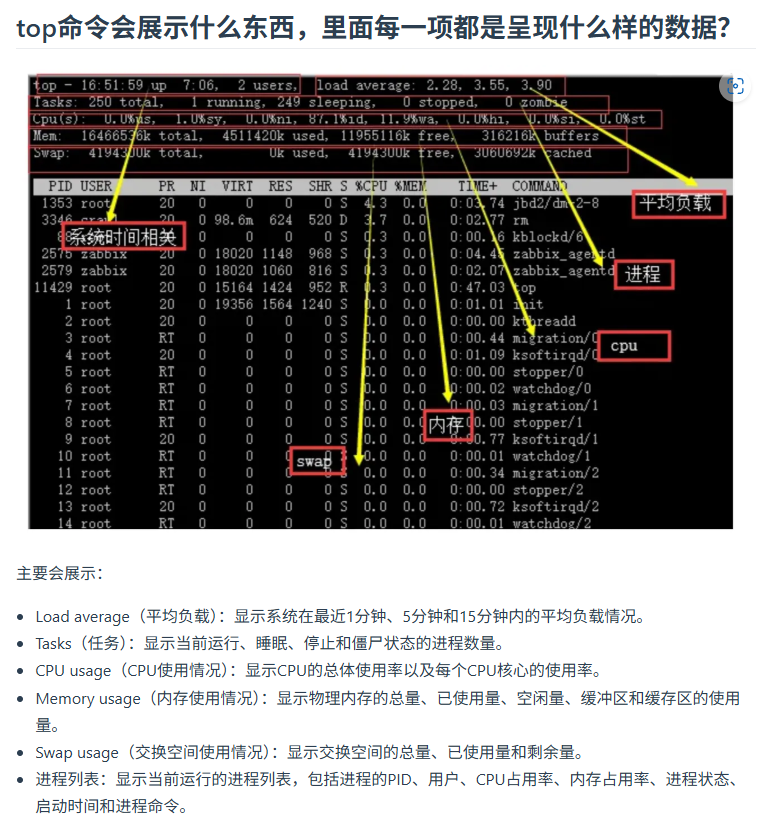
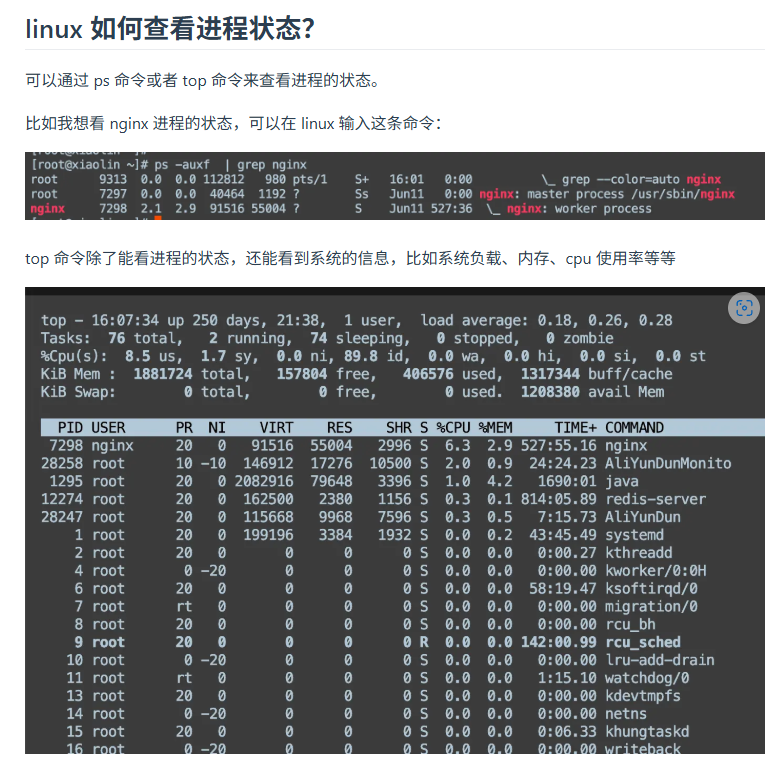
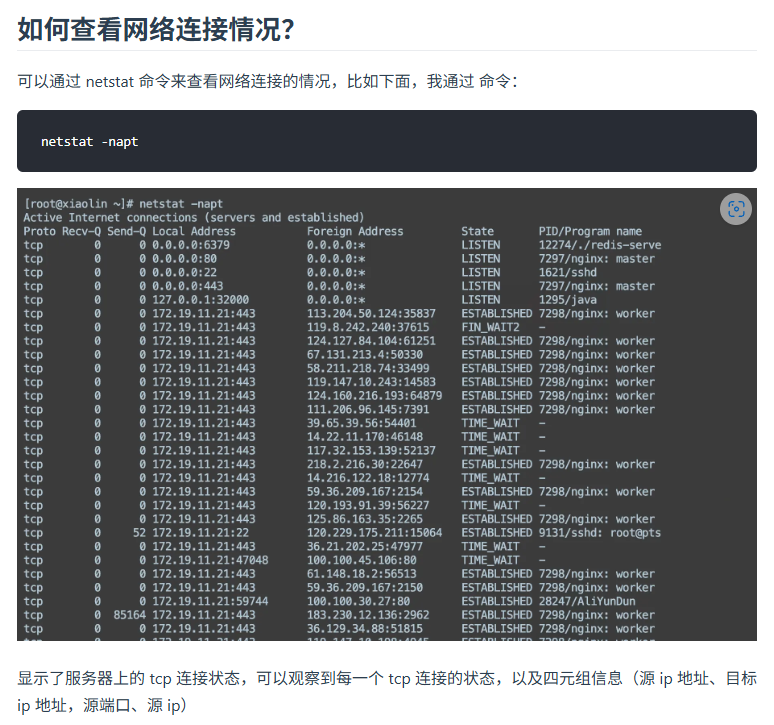
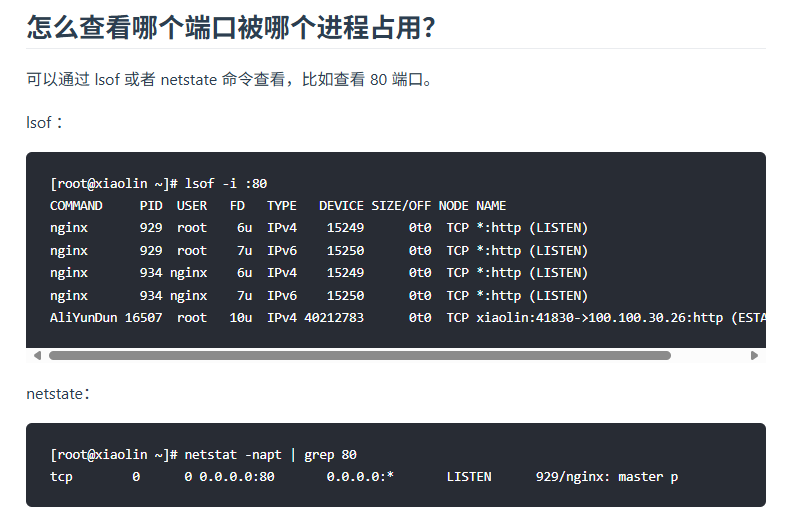

chmod 设置只读,只读+写怎么设置
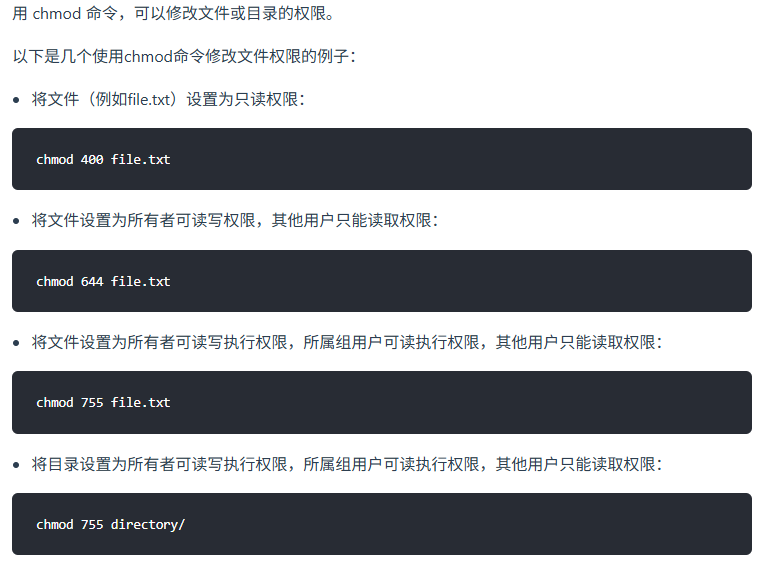

chmod 是一个用于改变文件和目录权限的命令。它允许用户设置谁可以读取、写入或执行文件。以下是 chmod 的基本用法和示例。
基本语法
chmod [options] mode file
权限模式
mode 可以用符号或数字表示:
-
符号表示法:
r:读权限 (read)w:写权限 (write)x:执行权限 (execute)u:文件所有者 (user)g:文件所在组 (group)o:其他用户 (others)a:所有用户 (all)
示例:
chmod u+x file.txt:给文件所有者添加执行权限。chmod go-w file.txt:去掉组和其他用户的写权限。chmod a+r file.txt:给所有用户添加读权限。
-
数字表示法:
- 权限用三位数字表示,每位数字的值为:
- 4:读权限
- 2:写权限
- 1:执行权限
- 这三位数字的组合表示不同的权限。
示例:
chmod 755 file.txt:设置所有者有读、写、执行权限(7),组和其他用户有读和执行权限(5)。chmod 644 file.txt:设置所有者有读和写权限(6),组和其他用户只有读权限(4)。
- 权限用三位数字表示,每位数字的值为:
常用选项
-
-R:递归改变目录及其子目录下的文件权限。示例:
chmod -R 755 /path/to/directory
示例
-
给文件添加执行权限:
chmod +x script.sh -
撤销写权限:
chmod -w document.txt -
设置多个权限:
chmod u+x,g-w,o+r file.txt
通过这些基本用法,您可以有效管理文件和目录的权限。
快排
package main
import (
"fmt"
"math/rand"
)
func fast_sort(num []int) {
if len(num)<=1{
return
}
base := num[0]
l, r := 0, len(num)-1
for l < r {
for l < r && num[r] > base {
r--
}
if num[r] <= base {
num[l] = num[r]
}
for l < r && num[l] <= base {
l++
}
if num[l] > base {
num[r] = num[l]
}
}
num[l] = base
fast_sort(num[:l])
fast_sort(num[l+1:])
}
func main() {
s := make([]int, 16)
for i := 0; i < 16; i++ {
s[i] = rand.Intn(100)
}
fmt.Println(s)
fast_sort(s)
fmt.Println(s)
}
无重复字符的最长子串
https://leetcode.cn/problems/longest-substring-without-repeating-characters/description/
func lengthOfLongestSubstring(s string) int {
ans := 0
book := map[byte]int{}
for l,r := 0,0;r<len(s);r++{
book[s[r]]++
for book[s[r]]>1{
book[s[l]]--
l++
}
if r-l+1>ans{
ans = r-l+1
}
}
return ans
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









