







RAG所依赖的库
pip install pymupdf pypdf docx2txt unstructured moviepy openai-whisper Chroma chromadb
conda install -c conda-forge ffmpeg
chroma run
一、RAG简介
1、什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合了信息检索技术与语言生成模型的人工智能技术。该技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等。RAG模型由Facebook AI Research(FAIR)团队于2020年首次提出,并迅速成为大模型应用中的热门方案。
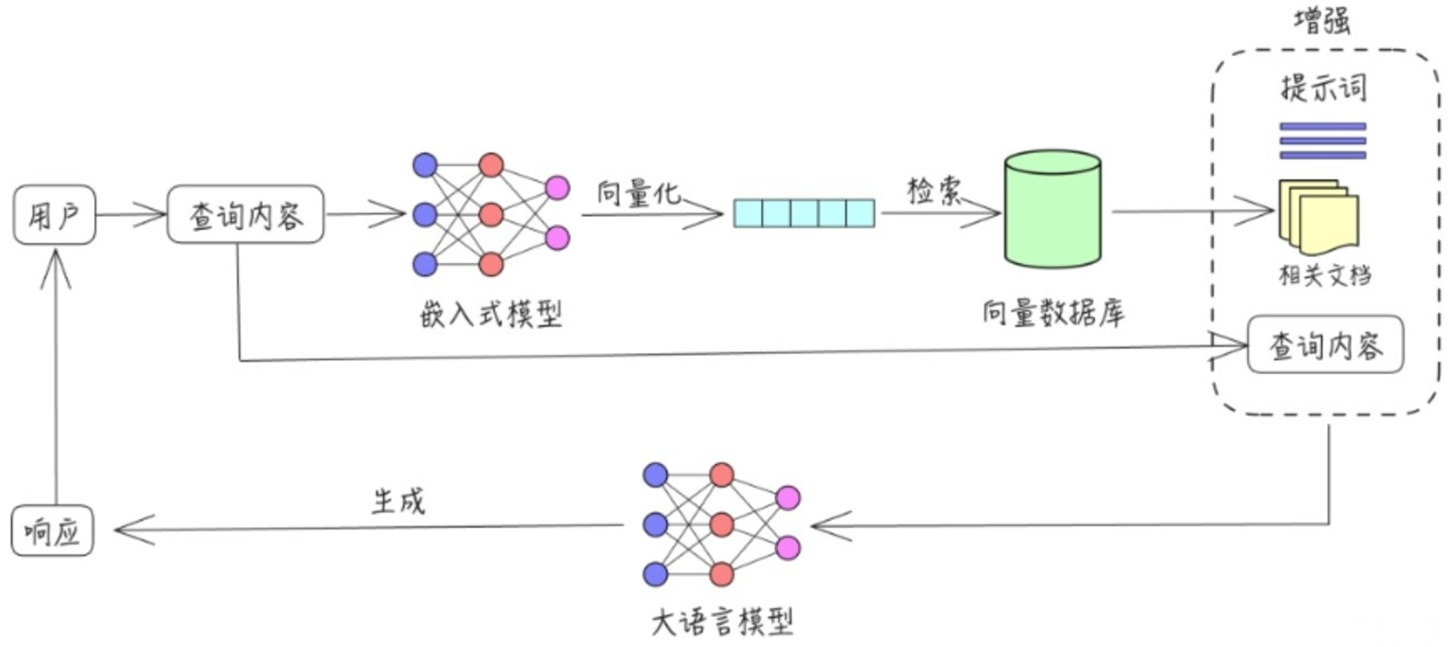
大型语言模型(LLM)面临两个问题:
1、知识截止:当 LLM 返回的信息与模型的训练数据相比过时时。每个基础模型都有知识截止,这意味着其知识仅限于训练时可用的数据。
2、幻觉:当模型自信地做出错误反应时,就会发生幻觉。
RAG解决了上述问题。
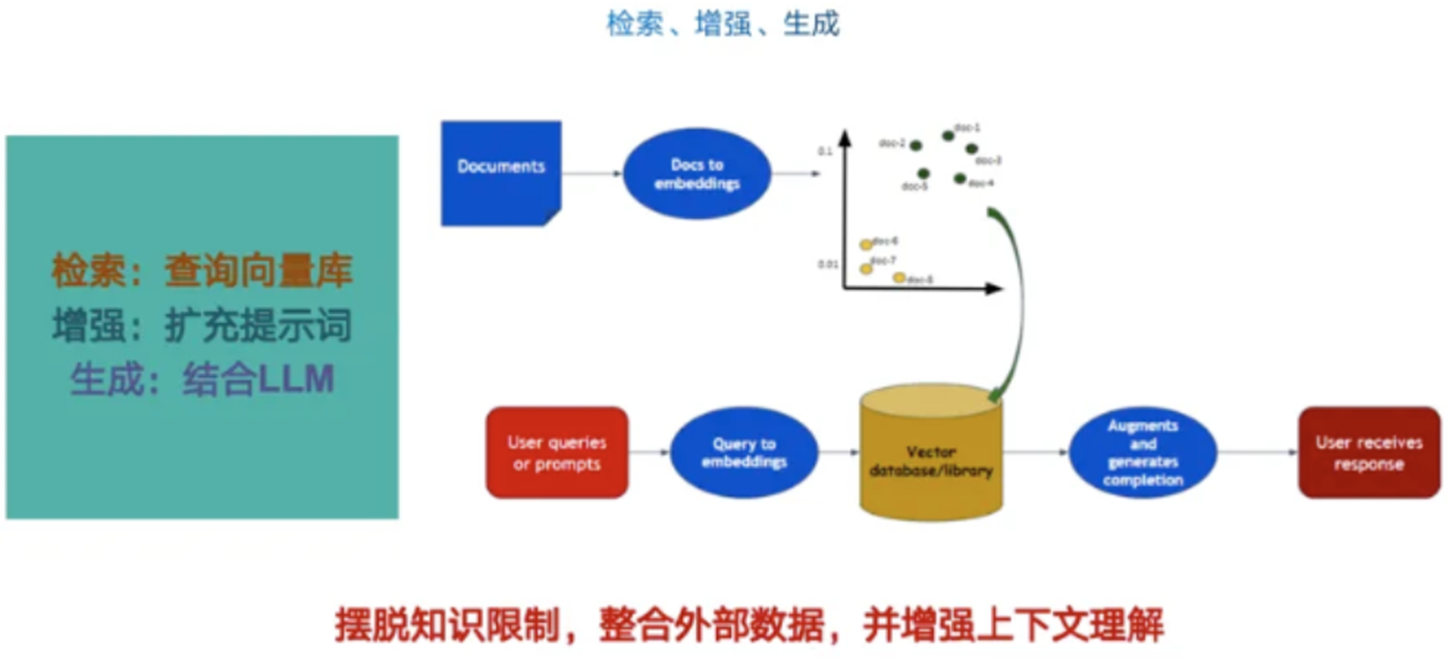
2、RAG的检索、增强、生成
检索:RAG流程的第一步,从预先建立的知识库中检索与问题相关的信息,目的是为后续的生成过程提供有用的上下文信息和知识支撑。
增强:RAG中增强是将检索到的信息用作LLM的上下文输入,以增强模型对特定问题的理解和回答能力。这一步的目的是将外部知识融入生成过程中,使生成的文本内容更加丰富、准确和符合用户需求。
生成:RAG流程的最后一步,结合LLM生成符合用户需求的回答。生成器会利用检索到的信息作为上下文输入,并结合大语言模型来生成文本内容。
“检索、增强、生成”,谁增强了谁?谁生成了答案?
主语很重要,是从知识库中检索到的问答对,增强了LLM的提示词(prompt),LLM拿着增强后的Prompt生成了问题答案。
二、RAG的实现
pip install pymupdf pypdf docx2txt unstructured moviepy openai-whisper Chroma chromadb
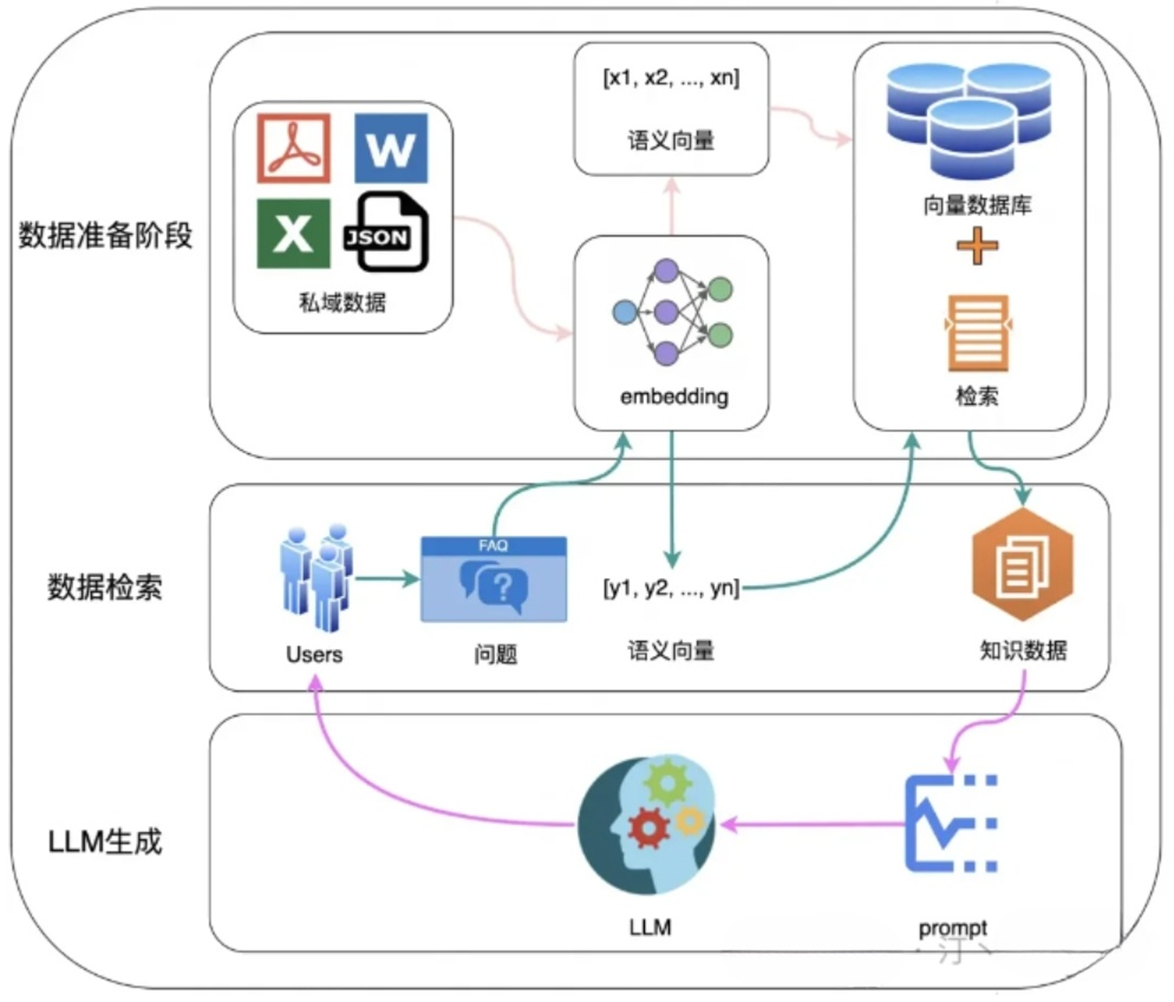
1、数据准备与知识库构建
(1)收集数据:首先,需要收集与问答系统相关的各种数据,这些数据可以来自文档、网页、数据库等多种来源。
(2)数据清洗:对收集到的数据进行清洗,去除噪声、重复项和无关信息,确保数据的质量和准确性。
(3)知识库构建:将清洗后的数据构建成知识库。这通常包括将文本分割成较小的片段(chunks),使用文本嵌入模型(如GLM)将这些片段转换成向量,并将这些向量存储在向量数据库(如FAISS、Milvus等)中。
2、检索模块设计
(1)问题向量化:当用户输入查询问题时,使用相同的文本嵌入模型将问题转换成向量。
(2)相似度检索:在向量数据库中检索与问题向量最相似的知识库片段(chunks),通过计算向量之间的相似度(如余弦相似度)来实现。
(3)结果排序:根据相似度得分对检索到的结果进行排序,选择最相关的k个片段作为后续生成的输入。
3、生成模块设计
(1)上下文融合:将检索到的相关片段与原始问题合并,形成更丰富的上下文信息。
(2)大语言模型生成:使用大语言模型(如QWEN2)基于上述上下文信息生成回答。大语言模型会学习如何根据检索到的信息来生成准确、有用的回答。
4、RAG特点总结
(1)通过检索增强技术,将用户查询与索引知识融合,利用大语言模型生成准确回答。
(2)把这个过程想象成开卷考试,让 LLM 先翻书,再回答问题。
RAG技术结合了大型语言模型的强大生成能力和检索系统的精确性。允许模型在生成文本时,从外部知识库中检索相关信息,从而提高生成内容的准确性、相关性和时效性。这种方法不仅增强了模型的回答能力,还减少了生成错误信息的风险。
三、基于langchain搭建RAG系统(⭐)
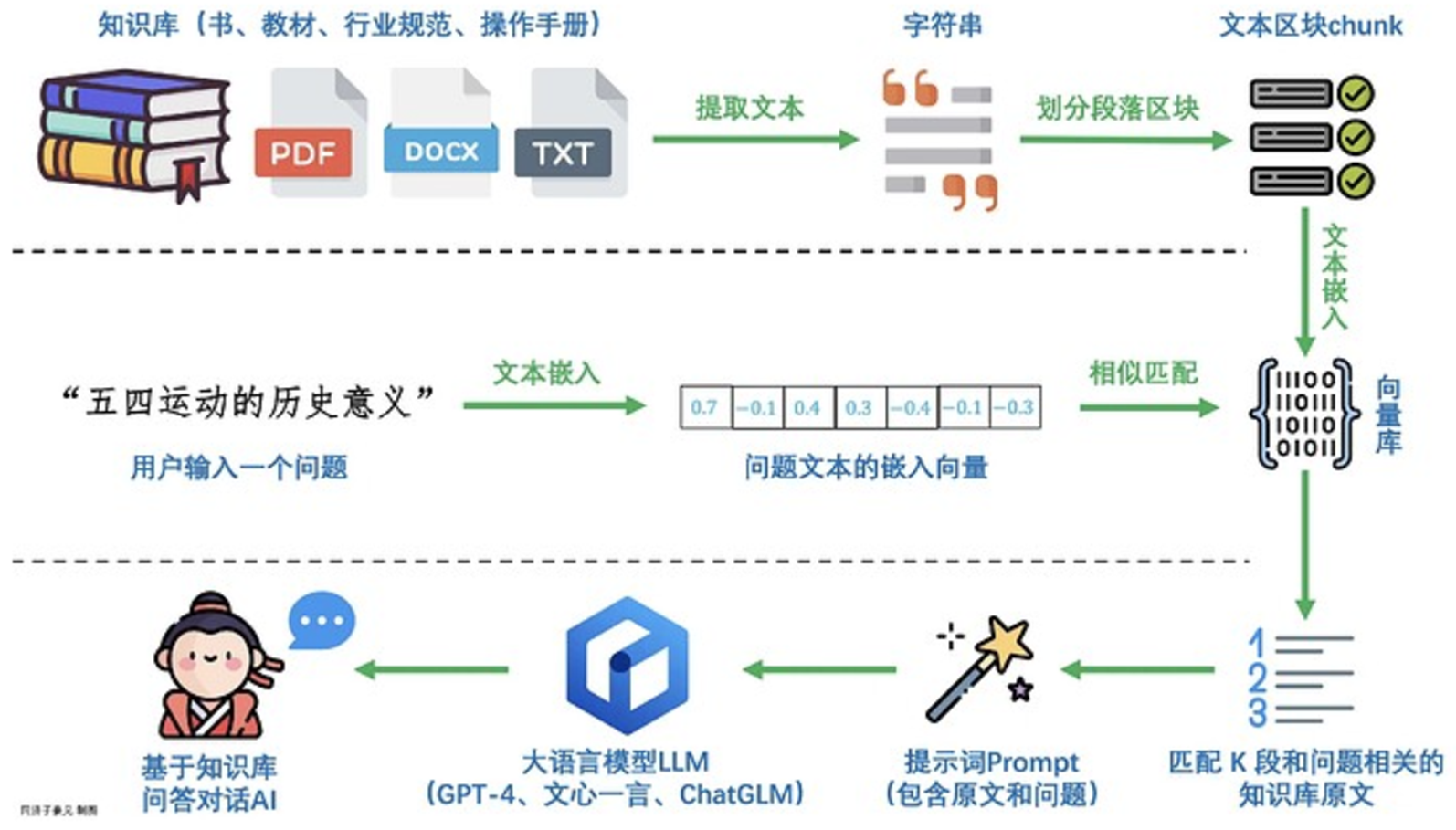
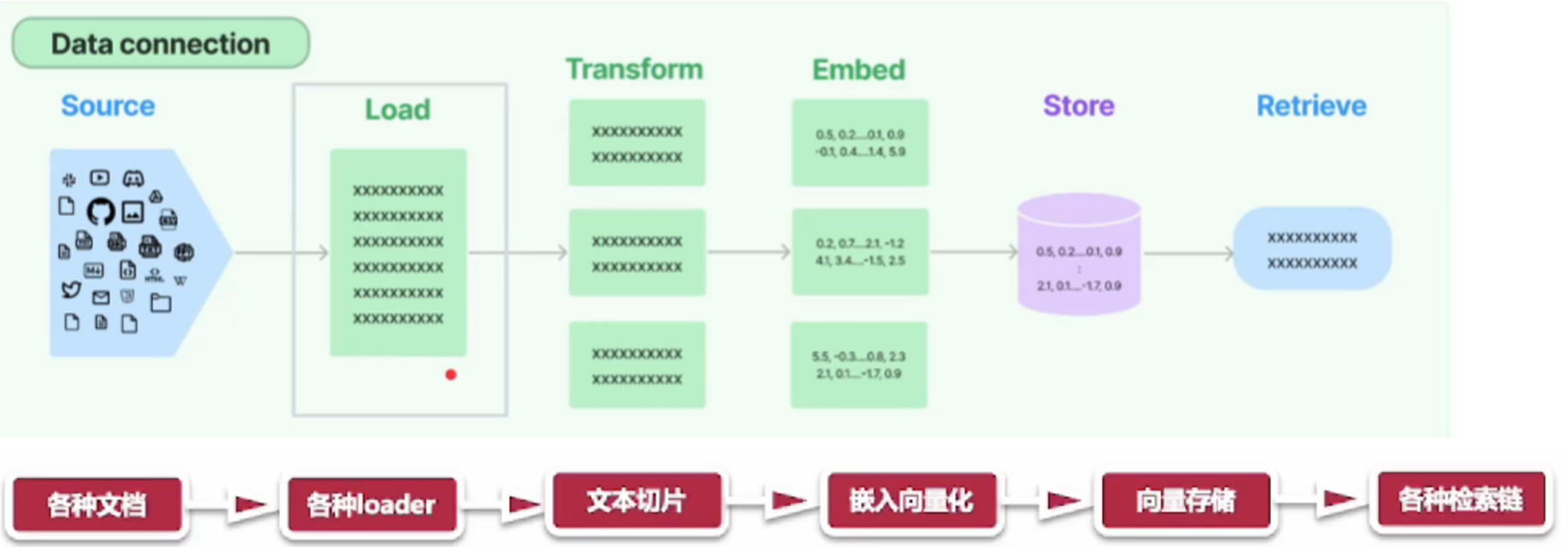
0、总体步骤
- 文档加载器:从许多不同的来源加载文档
- 文档转换器:分割文档,删除多余的文档等
- 文本词嵌入模型:采取非结构化文本,并把它变成一个浮点数的列表 矢量存储:存储和搜索嵌入式数据
- 向量存储:存储和搜索embedding数据
- 检索器:查询你的数据
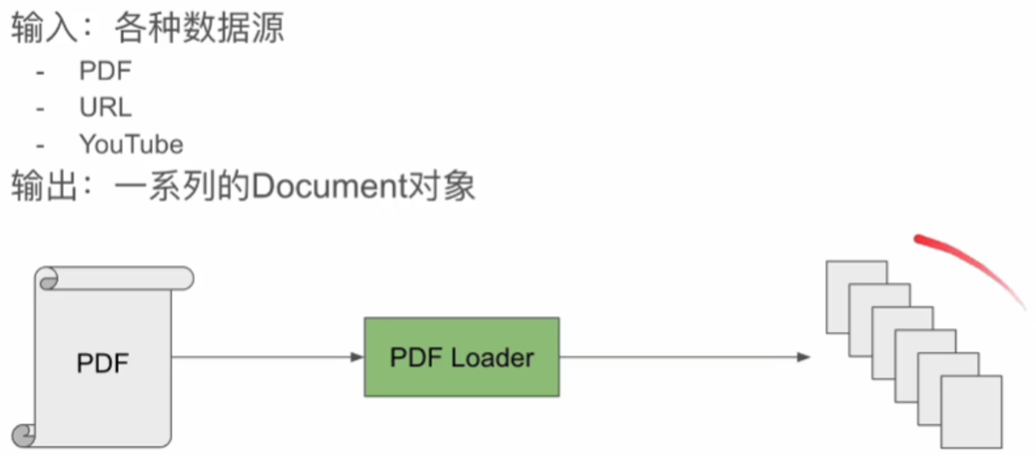
1、文档加载器
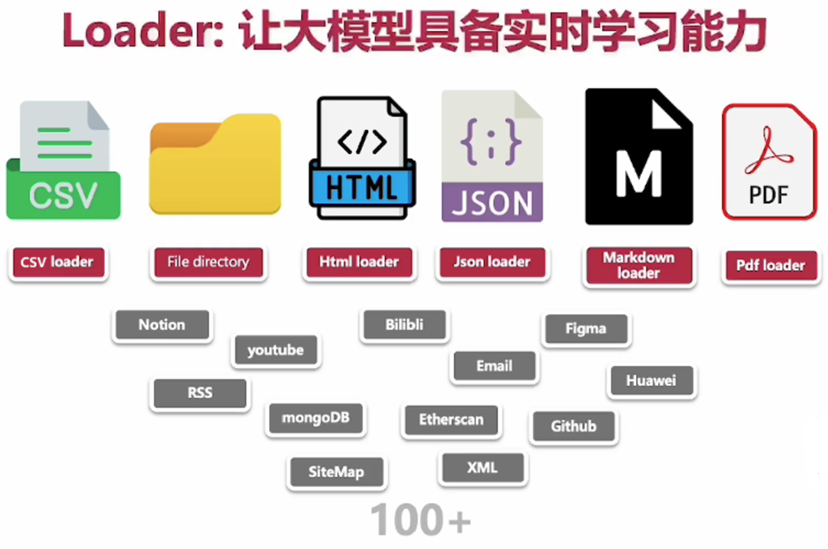
langchain 提供了大约100多种文档加载器,比如:
TXT 文件:TextLoader
PDF 文件:PyPDFLoader、PyMuPDFLoader
Word 文件:Docx2txtLoader
Excel 文件:PandasExcelLoader、OpenPyXLLoader
CSVLoader、JSONLoader、HTMLLoader、MarkdownLoader、UnstructuredFileLoader(非结构化文件,如 .doc, .ppt 等)。
视频加载器:先将视频里的语音部分转换为文本,然后再使用文本加载器处理。
from langchain_community.document_loaders import PyPDFLoader # pdf
from langchain_community.document_loaders import PyMuPDFLoader # pdf
from langchain_community.document_loaders import TextLoader # txt
from langchain_community.document_loaders import Docx2txtLoader # docx
from langchain_community.document_loaders import UnstructuredExcelLoader # excel
pdf_loader = PyMuPDFLoader("car_info.pdf")
pdf_pages = pdf_loader.load()
print(type(pdf_pages)) # <class 'list'>
print(len(pdf_pages)) # 354 (页码)
print(type(pdf_pages[0])) # <class 'langchain_core.documents.base.Document'>
# print(pdf_pages[0]) # 包含 page_content(文本内容)、metadata(配置信息)
print(pdf_pages[0].page_content) # 获取文本内容
print(pdf_pages[0].metadata) # 获取配置信息import moviepy as mp # 视频编辑库
import whisper # OpenAI 开发的一个语音识别模型,能够将音频转换为文本
# whisper依赖ffmpeg处理音频文件 conda install -c conda-forge ffmpeg
from langchain_community.document_loaders import TextLoader
import os
# 读取视频,转为音频
video = mp.VideoFileClip("m.mp4")
audio = video.audio
audio_file = "m.wav"
audio.write_audiofile(audio_file)
# 使用 Whisper 将音频转换为文本
# 不同大小的模型(tiny, base, small, medium, large),适合不同的硬件条件。
model = whisper.load_model("tiny") # 加载模型
result = model.transcribe(audio_file) # 转录音频文件
transcribed_text = result["text"] # 获取文本信息
# 将转录的文本保存到文件中
temp_text_file = "m.txt"
with open(temp_text_file, "w",encoding="utf-8") as f:
f.write(transcribed_text)
# 使用 Langchain 的 TextLoader 读取文本文件
loader = TextLoader(temp_text_file,encoding="utf-8")
documents = loader.load()
print(documents) # [Document(metadata={'source': 'm.txt'}, page_content='...']
# 打印读取的文本内容
for doc in documents:
print(doc.page_content)
# 删除多余临时文件
os.remove(audio_file)
os.remove(temp_text_file)2、数据清洗
我们期望知识库的数据尽量是有序的、优质的、精简的,因此我们要删除低质量的、甚至影响理解的文本数据。
正则表达式:
去除非中文字符之间的换行符
re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)
import re
from langchain_community.document_loaders import PyMuPDFLoader
pdf_loader = PyMuPDFLoader("car_info.pdf")
pdf_pages = pdf_loader.load()
pdf_page = pdf_pages[100]
# 正则匹配
# 匹配两个非中文字符之间的换行符(\n),并将其替换为空字符串(即删除换行符)
new_line = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)
pdf_page.page_content = re.sub(new_line, lambda match: match.group(0).replace("\n", ""), pdf_page.page_content)
# 将 ■ 改为 -
# new_line = re.compile(r'■', re.DOTALL)
# pdf_page.page_content = re.sub(new_line, "-", pdf_page.page_content)
# 移除 ■
pdf_page.page_content = pdf_page.page_content.replace("■", "")
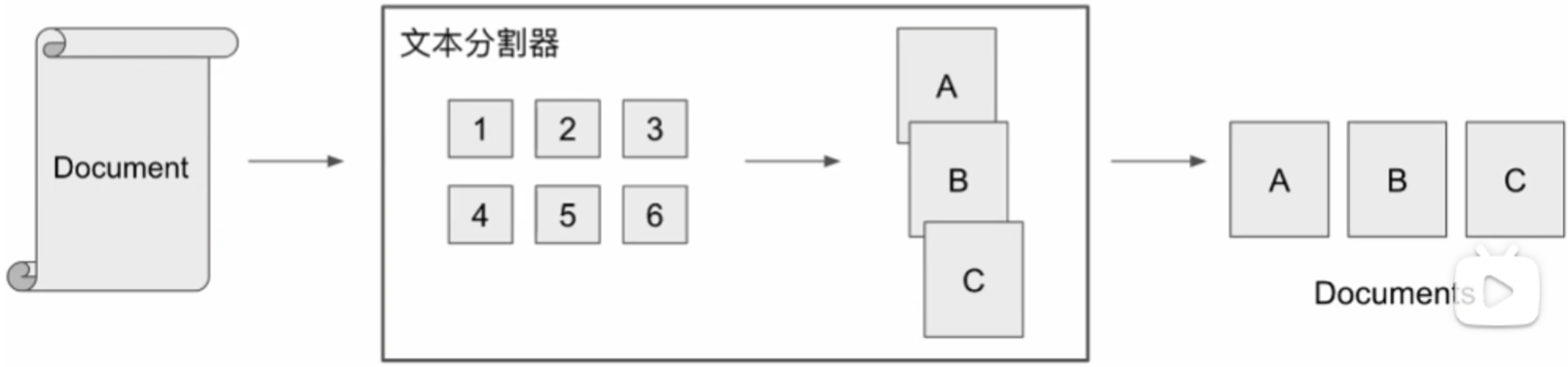
print(pdf_page.page_content)3、文档转换器-文本分割器
(1)单个文档的长度往往会超过模型支持的长度,我们往往需要对文档进行分割成若干个 chunk,然后将每个 chunk 转化为词向量,存储到向量数据库中。
(2)在检索时,我们会以 chunk 作为检索的元单位,每次检索到 n 个 chunk 作为模型可以参考来回答用户问题的知识。
(3)Langchain 中文本分割器都根据:
chunk_size (块大小):每个块包含的字符或 Token(如单词、句子等)的数量
chunk_overlap (块与块之间的重叠大小):两个块之间共享的字符数量
进行分割。
缺陷:
(1)分割粒度太大可能导致检索不精准,粒度太小可能导致信息不全面
(2)问题的答案可能跨越两个片段
Langchain 提供多种文档分割方式:
RecursiveCharacterTextSplitter(): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
CharacterTextSplitter(): 按字符来分割文本。
MarkdownHeaderTextSplitter(): 基于指定的标题来分割markdown 文件。
TokenTextSplitter(): 按token来分割文本。
SentenceTransformersTokenTextSplitter(): 按token来分割文本
Language(): 用于 CPP、Python、Ruby、Markdown 等。
NLTKTextSplitter(): 使用 NLTK(自然语言工具包)按句子分割文本。
SpacyTextSplitter(): 使用 Spacy按句子的切割文本。
RecursiveCharacterTextSplitter:
按照不同的分隔字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),就能把所有和语义相关的内容尽可能长时间地保留在同一位置。
RecursiveCharacterTextSplitter的4个参数:
* separators - 分隔符字符串数组
* chunk_size - 每个文档的字符数量限制
* chunk_overlap - 两份文档重叠区域的长度
* length_function - 长度计算函数
from langchain.text_splitter import RecursiveCharacterTextSplitter # 递归分块
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "(?<=\。!?)", " ", ""], # 分隔符优先级,添加中文分隔符((?<=\。!?)正向后行断言,保留标点符号)
chunk_size=20, # 每个文本块的最大长度
chunk_overlap=2, # 相邻文本块之间的重叠长度
length_function= len # 长度函数
)
text = """
您让我用臣妾的语气讲话,并且还请求我给您唱歌。
首先,对于让您等待感到抱歉,我是按照您的指令来执行任务的。
在那之后,当您说“给我唱首歌”,实际上是在邀请或请求我为您演唱一首歌曲。
请告诉我有什么我能进一步帮助您的吗?
"""
chunks = text_splitter.split_text(text) # text_splitter.split_text
for chunk in chunks:
print(chunk)from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
pdf_loader = PyMuPDFLoader("car_info.pdf")
pdf_pages = pdf_loader.load()
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "(?<=\。!?)", " ", ""], # 分隔符优先级,添加中文分隔符((?<=\。!?)正向后行断言,保留标点符号)
chunk_size=50, # 每个文本块的最大长度
chunk_overlap=5, # 相邻文本块之间的重叠长度
length_function= len # 长度函数
)
split_docs = text_splitter.split_documents(pdf_pages) # text_splitter.split_documents 会自行遍历文档进行分块
print(f"文本块数量:{len(split_docs)}")
print(f"总字符数量:{sum([len(doc.page_content) for doc in split_docs])}")4、文本词嵌入(Word Embedding)

embedding_model = DashScopeEmbeddings(model="text-embedding-v3")
HuggingFaceEmbeddings(model_name="distiluse-base-multilingual-cased-v2")
# DashScope阿里云提供 Embeddings
from langchain_community.embeddings import DashScopeEmbeddings
import os
api_key = os.environ.get("AL_API_KEY")
embeddings = DashScopeEmbeddings(
dashscope_api_key=api_key,
# 词嵌入模型:1024
model="text-embedding-v3",
)
text = "您让我用臣妾的语气讲话,并且还请求我给您唱歌。"
query_result = embeddings.embed_query(text)
print(len(query_result)) # 1024
print(query_result)5、向量数据库
为向量检索设计的中间件:
用来存储和查询向量的数据库,其存储的向量来自于对文本、语音、图像、视频等的向量化。与传统数据库相比,向量数据库可以处理更多非结构化数据(比如图像和音频)。在机器学习和深度学习中,数据通常以向量形式表示。
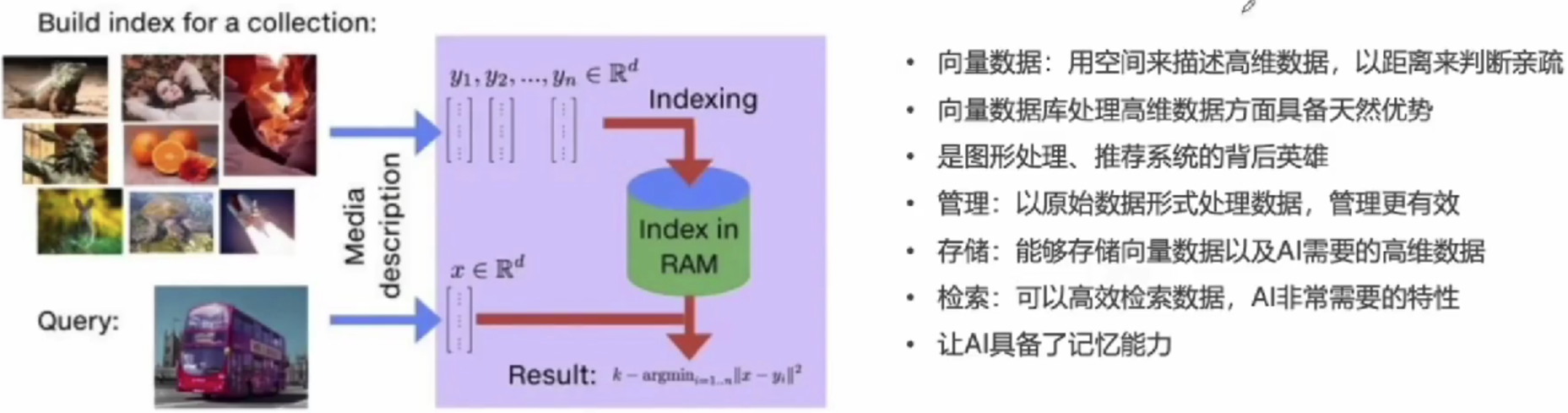
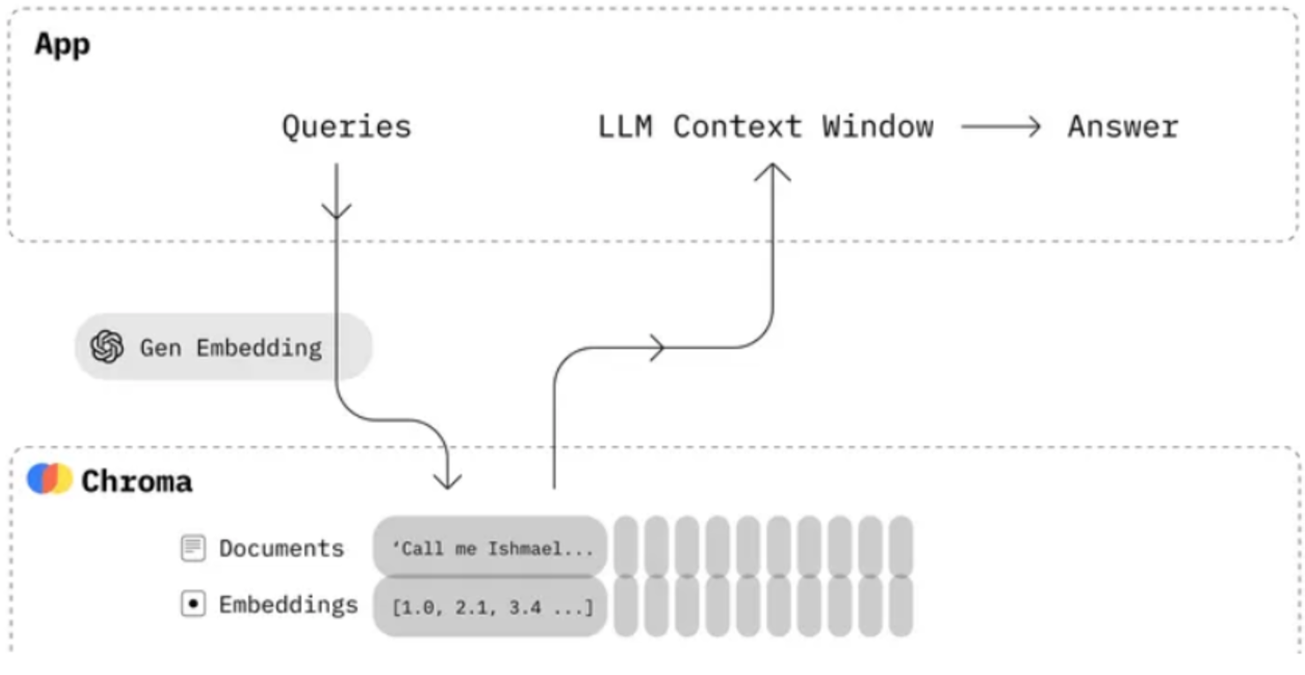
ChromaDB(也称为Chroma)是一个开源的向量数据库,简化大模型应用的构建过程,ChromaDB的特点包括:轻量级、易用性、功能丰富、集成、多语言支持、开源。
# pip install Chroma -i Simple Index 完整安装
# pip install chromadb -i Simple Index 轻量级客户端
# chroma run
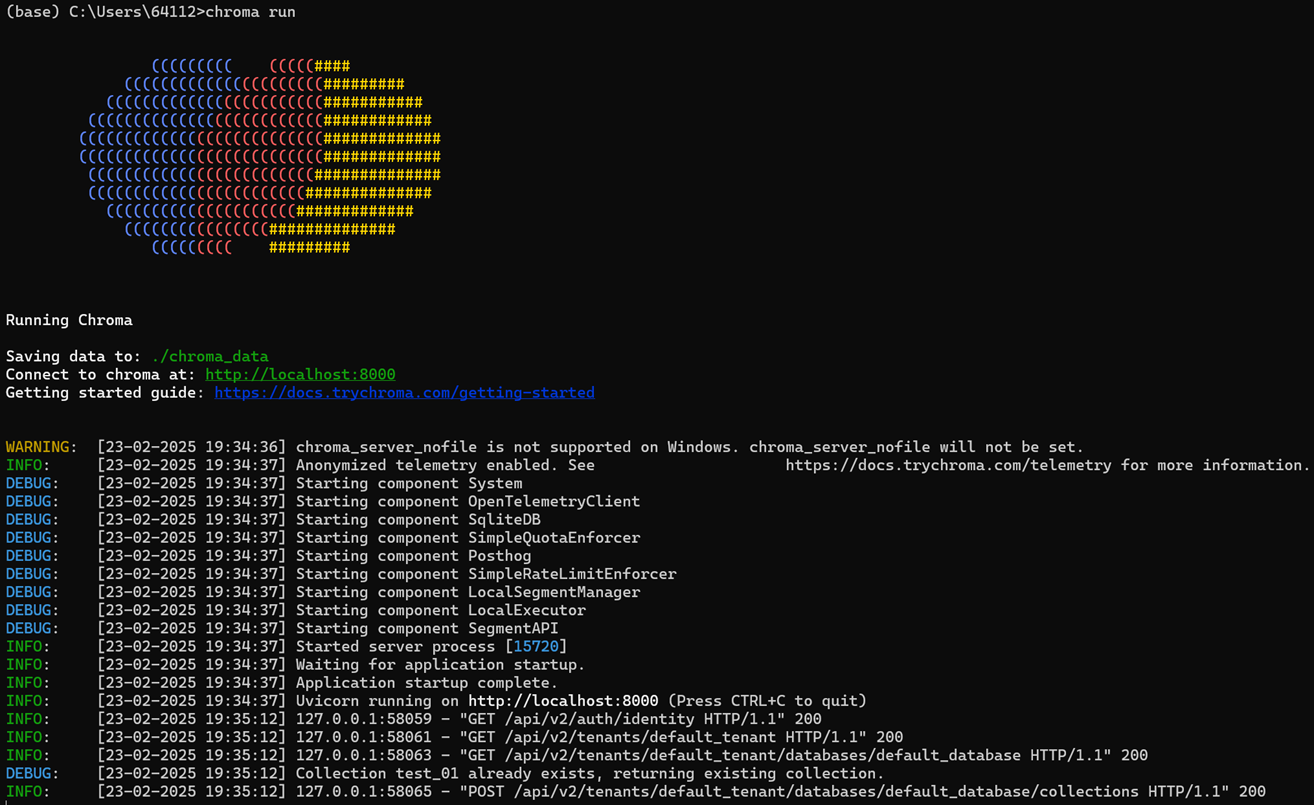
# 使用数据库前,chroma run 终端运行chroma
import chromadb
from langchain.embeddings import DashScopeEmbeddings
import os
api_key = os.environ.get("AL_API_KEY")
# 词嵌入模型初始化
embedding_model = DashScopeEmbeddings(
dashscope_api_key=api_key,
model="text-embedding-v3"
)
# 初始化连接
def init_db_client():
return chromadb.HttpClient(host="localhost", port=8000)
# 创建连接
def create_collection(collection_name):
chroma_client = init_db_client()
# 懒加载
collection = chroma_client.get_or_create_collection(name=collection_name)
print("连接成功")
return collection
# 词嵌入并向数据库写入数据
def add_documents(collection, documents):
embeddings = embedding_model.embed_documents(documents)
# 存储数据库
collection.add(
# 词向量
embeddings=embeddings,
# 文本原文
documents=documents,
# 索引
ids=[f"id{i}" for i in range(len(documents))]
)
print("写入成功")
# 数据库命名
collection_name="test01"
# 获取数据库
collection = create_collection(collection_name)
# 文本数据
datas = [
"传道授业解惑者,负责教育教学工作,培养人才,塑造灵魂,需具备专业知识和教育能力,工作稳定,假期较多。",
"维护社会治安,打击犯罪,保护人民安全,工作压力大,需具备勇敢、正义和责任心,享有一定的社会地位。",
"国家机关工作人员,负责政策执行、公共服务等,工作稳定,待遇优厚,需通过公务员考试,具备较强的综合素质。",
"编写软件代码,开发应用程序,需具备逻辑思维和编程能力,工作强度大,但薪资较高,行业前景广阔。",
"从事创意设计工作,包括平面、服装、室内等,需具备审美能力和设计软件操作技能,工作灵活,富有创造性。"
]
# 词嵌入并写入数据
add_documents(collection,datas)
# 查询语句
query="谁是设计师"
# 查询语句向量化
# query_embed = embedding_model.embed_documents([query])[0]
query_embed = embedding_model.embed_query(query)
# 相似度查询
res = collection.query(query_embeddings=[query_embed], n_results=3)
print(res)6、检索器
向量相似度计算
from langchain.embeddings import DashScopeEmbeddings
import os
from numpy.linalg import norm
from numpy import dot
api_key = os.environ.get("AL_API_KEY")
# 词嵌入模型初始化
embedding_model = DashScopeEmbeddings(
dashscope_api_key=api_key,
model="text-embedding-v3"
)
# 余弦相似度计算
def cos_sim(a,b):
return dot(a,b)/(norm(a)*norm(b))
# 文本数据
datas = [
"传道授业解惑者,负责教育教学工作,培养人才,塑造灵魂,需具备专业知识和教育能力,工作稳定,假期较多。",
"维护社会治安,打击犯罪,保护人民安全,工作压力大,需具备勇敢、正义和责任心,享有一定的社会地位。",
"国家机关工作人员,负责政策执行、公共服务等,工作稳定,待遇优厚,需通过公务员考试,具备较强的综合素质。",
"编写软件代码,开发应用程序,需具备逻辑思维和编程能力,工作强度大,但薪资较高,行业前景广阔。",
"从事创意设计工作,包括平面、服装、室内等,需具备审美能力和设计软件操作技能,工作灵活,富有创造性。"
]
# 询问
query = "谁是公务员"
def get_embedding(texts):
embed_list = []
for text in texts:
embedding = embedding_model.embed_query(text)
embed_list.append(embedding)
return embed_list
query_vec = get_embedding([query])[0]
doc_vecs = get_embedding(datas)
for doc_vec in doc_vecs:
similar=cos_sim(query_vec,doc_vec)
print(similar)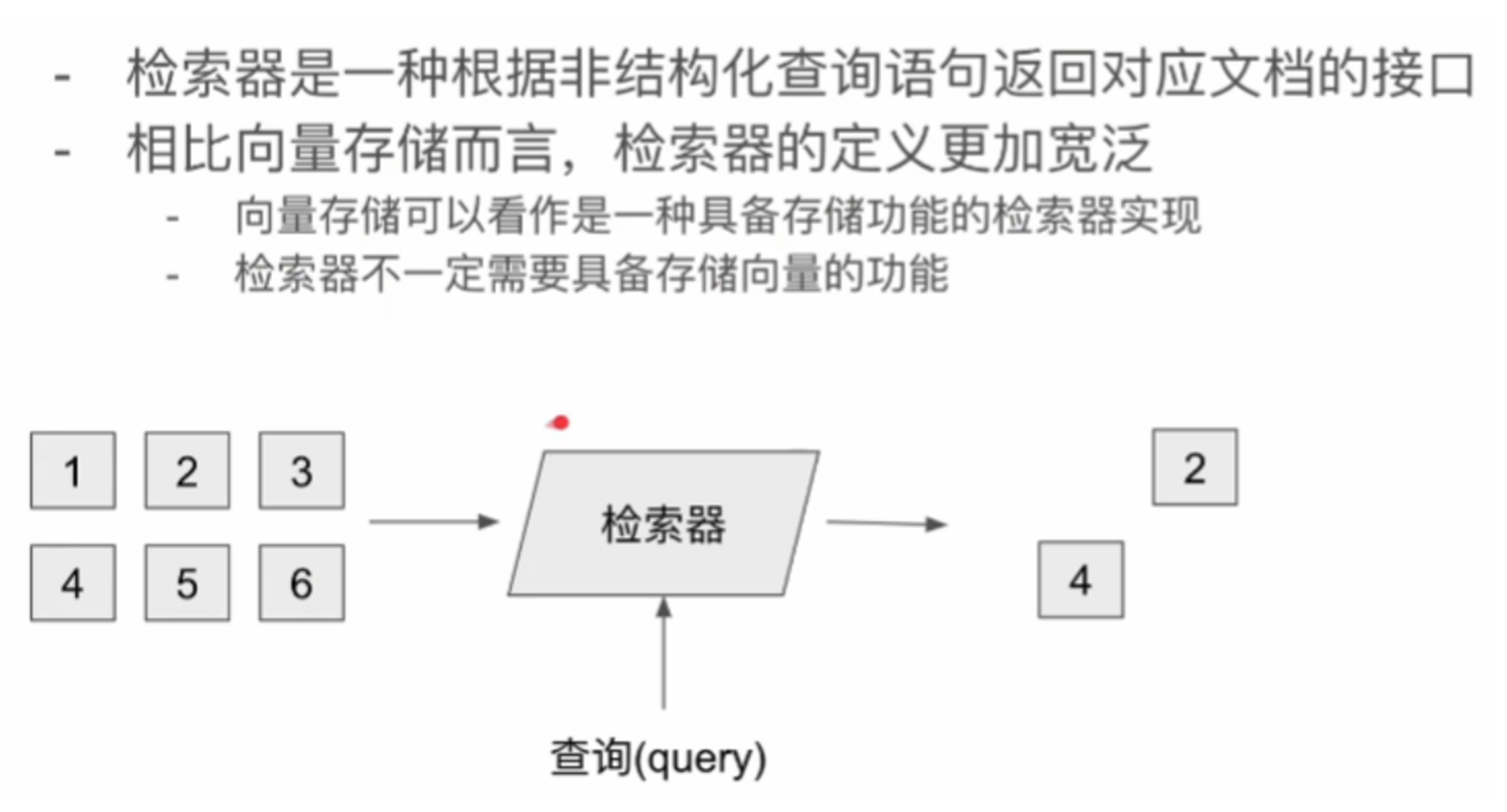
使用 VectorstoreIndexCreator 创建检索器
index_creator = VectorstoreIndexCreator(
text_splitter=text_splitter, # 指定文本切割器
embedding=embedding_model, # 指定嵌入模型
vectorstore_cls=Chroma, # 指定向量存储类
# 设置向量存储的持久化目录
vectorstore_kwargs={"persist_directory": "vectorstore"})
import os
from langchain_ollama import OllamaLLM # 模型
from langchain.embeddings import DashScopeEmbeddings # 词嵌入模型
from langchain.document_loaders import PyMuPDFLoader # 数据加载器
from langchain.text_splitter import RecursiveCharacterTextSplitter # 分词器
from langchain.indexes import VectorstoreIndexCreator # 向量库检索器
from langchain_community.vectorstores import Chroma # 向量库
# 大模型
llm = OllamaLLM(model="qwen2:7b")
# 词嵌入模型
api_key = os.environ.get("AL_API_KEY")
embedding_model = DashScopeEmbeddings(
dashscope_api_key=api_key,
model="text-embedding-v3"
)
# 分词器
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "(?<=\。!?)"," ", ""],
chunk_size=50,
chunk_overlap=10,
length_function=len
)
# 检索器创建
index_creator = VectorstoreIndexCreator(
vectorstore_cls=Chroma,
embedding=embedding_model,
text_splitter=text_splitter,
vectorstore_kwargs={"persist_directory":"vectorstore1"}
)
# 数据加载
pdf_loader = PyMuPDFLoader("car_info.pdf")
# 创建索引
index = index_creator.from_loaders(loaders=[pdf_loader])
# 持久化向量存储
# index.vectorstore.persist() # 由于 Chroma 0.4.x 及以上版本已经自动处理持久化,不再需要手动调用 persist() 方法
# 查询
res = index.query(question="我要怎么联系你们,联系电话是多少?", llm=llm)
print(res)from langchain_ollama.llms import OllamaLLM
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
# 初始化OllamaLLM
llm = OllamaLLM(model="qwen2:7b")
# 初始化嵌入模型
api_key = os.environ.get("AL_API_KEY")
embedding_model = DashScopeEmbeddings(
dashscope_api_key=api_key,
model="text-embedding-v3"
)
# 加载已持久化的向量数据库
vectorstore = Chroma(
persist_directory="vectorstore", # 指定持久化目录
embedding_function=embedding_model
)
# 检查是否加载成功
print(f"已加载向量数据库,包含 {vectorstore._collection.count()} 条数据")
# 查询向量数据库
question = "我要怎么联系你们,联系电话是多少?"
docs = vectorstore.similarity_search(question, k=5) # 查询最相似的k个文档
# 将查询结果传递给LLM生成答案
context = "\n".join([doc.page_content for doc in docs])
prompt = f"根据以下信息回答问题:\n{context}\n\n问题:{question}"
# print(prompt)
res = llm.invoke(prompt)
print(res)7、构建智慧旅游检索问答链
构建检索问答链,创建一个基于模板的检索链:
RetrievalQA.from_chain_type(
llm=llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT})
import os
from langchain_ollama import OllamaLLM
from langchain.document_loaders import UnstructuredWordDocumentLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA # 检索式问答链
# 大模型
llm = OllamaLLM(model="qwen2:7b")
# 数据加载
docx_loader = UnstructuredWordDocumentLoader("峨眉山讲解词.docx")
documents = docx_loader.load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "(?<=\。!?)"," ", ""],
chunk_size=100,
chunk_overlap=20,
length_function=len
)
texts = text_splitter.split_documents(documents)
# 词嵌入模型
api_key = os.environ.get("AL_API_KEY")
embedding_model = DashScopeEmbeddings(
dashscope_api_key=api_key,
model="text-embedding-v3"
)
# 创建向量数据库
vectorstore_db = Chroma.from_documents(texts,embedding_model)
# 提示模板
template = """
智慧旅游问答,你不知道就直说不知道,在3句话以内回答问题,结束用谢谢。
{context}
问题:{question}
"""
qa_chain_prompt = prompt_temp = PromptTemplate.from_template(template)
# 检索式问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore_db.as_retriever(search_kwargs={"k": 5}), # 默认为4
return_source_documents=True,
chain_type_kwargs={"prompt": qa_chain_prompt}
)
# 提问
res = qa_chain({"query": "武当山的有多高?"})
# 处理输出结果
answer = res["result"]
print(answer)vectorstore_db = Chroma(
persist_directory="vectorstore1", # 指定持久化目录
embedding_function=embedding_model
)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









