







一、项目调研背景
1、linux环境下有非常好用的find命令,查找文档非常的便捷高效。
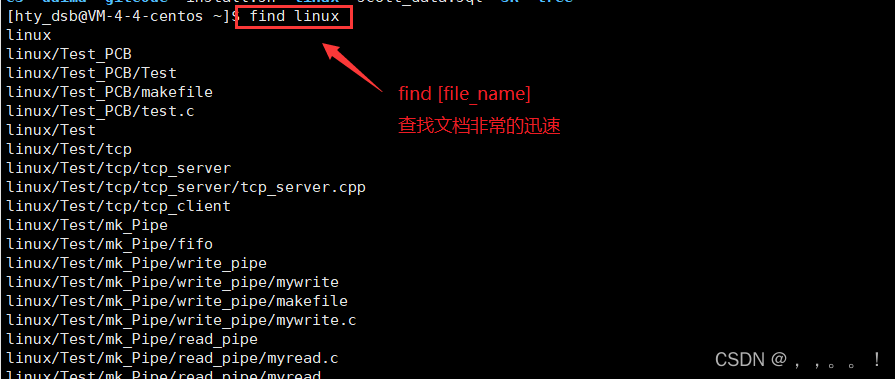
2、windows下文件夹框下的默认搜索是搜索时再进行暴力遍历查找,非常的慢。
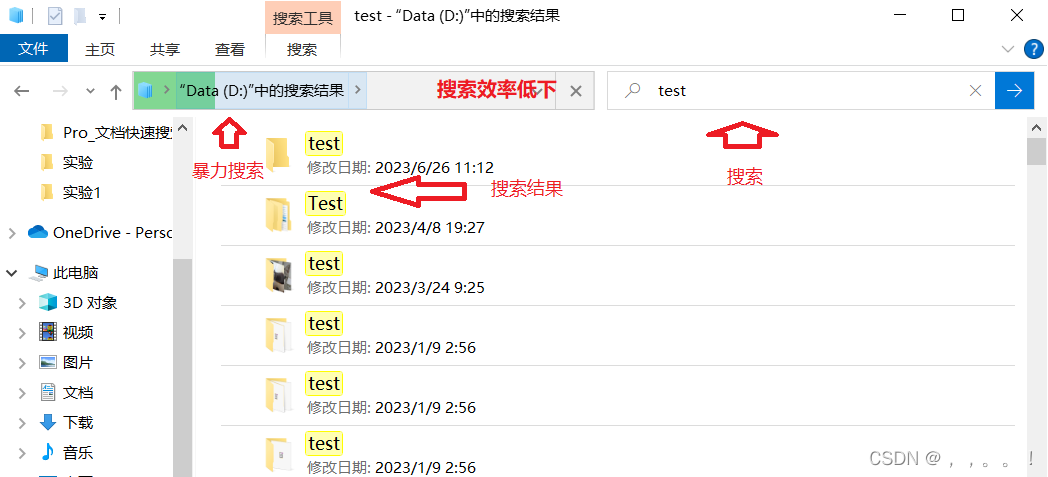
3、windows下有一个神器软件解决了这个问题,叫everything,是将文档信息检索以后,提前存储 到数据库,查找时在数据库进行搜索,速度快了很多。
缺点:只适用于NTFS格式
不能使用拼音搜索、也不能使用首字母搜索
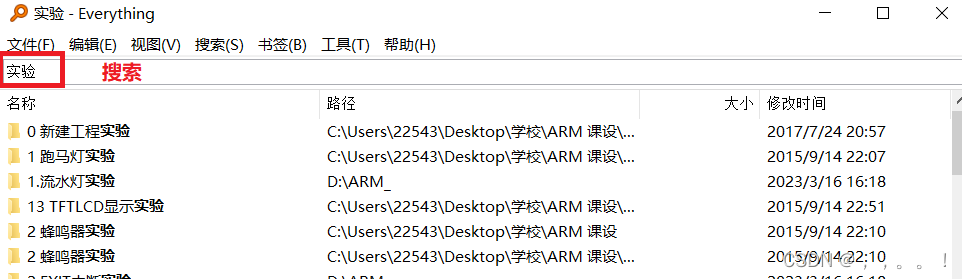
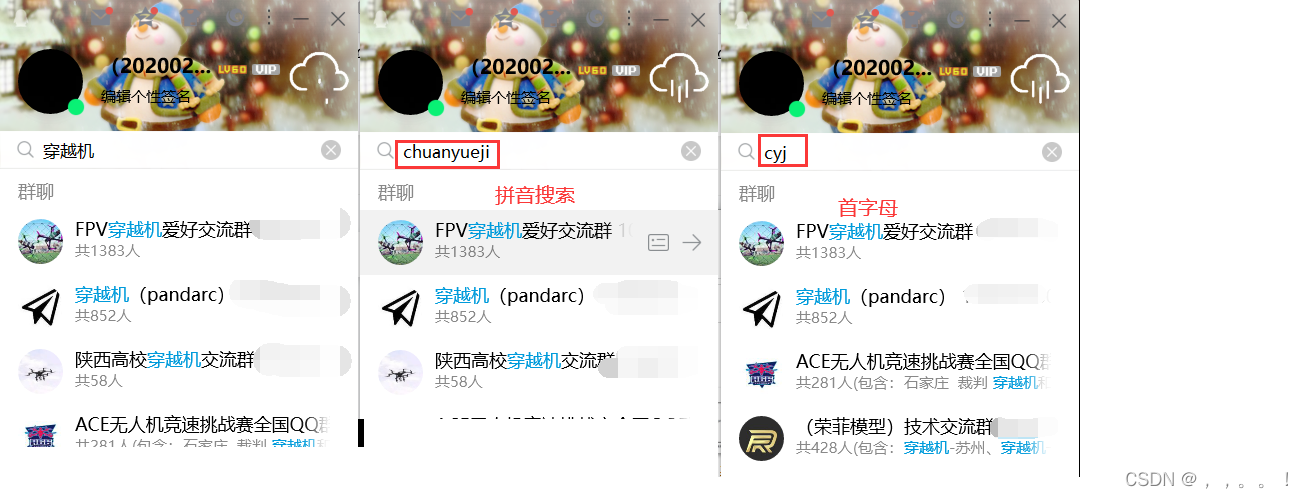
4、qq的搜索 --- 能够快速搜索,且支持拼音和首字母的搜索方式
5、通过以上的对比,希望自己能写一个针对文档搜索的工具,且能够快速搜索,以及能支持多种搜索方式的文档搜索工具。
二、项目需求分析
1、支持文档的常规搜索
2、支持拼音全拼搜索
3、支持拼音首字母搜索
4、支持搜索关键字高亮显示
5、扫描和监控(用户感知不到)
三、项目开发环境
1、编译器 : VS系列编译器 2013 or 2019 or 2022 .....
2、编程语言 : C++ / C++11
3、数据库 : sqlite3 (核心关键)
四、项目涉及的知识点
1、数据库操作:
(sqlite安装,创建数据库,创建表,插入数据,删除数据,创建索引,查询数据 (条件查询、 模糊查询))
2、静态库和动态库:静态库和动态的制作,动态库和动态的使用
3、设计模式(单例模式)
4、多线程
5、同步机制(互斥量、条件变量)
6、日志
7、汉字与拼音的转换
五、项目实现的基础理论

六、项目框架
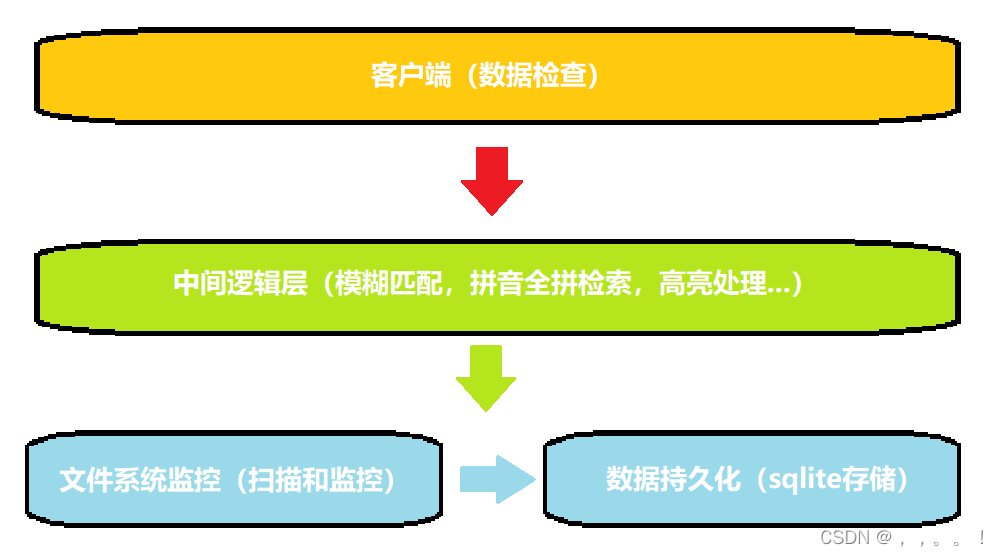
七、项目框架搭建
1、创建common.h 公共模块
2、创建DocFastSearchToolMain.cpp 驱动模块
3、创建sysutil.h 系统工具模块
八、系统工具模块
sysutil.h 和 sysutil.cpp
功能:扫描本地的文件的功能
8.1需要使用的函数
//功能是搜索与指定的文件名称匹配的第一个实例,若成功则返回第一个实例的句柄,否则返回-1L
long _findfirst( char *filespec, struct _finddata_t *fileinfo );
//_findnext函数提供搜索文件名称匹配的下一个实例,若成功则返回0,否则返回-1
int _findnext( long handle, struct _finddata_t *fileinfo );
//_findclose用于释放由_findfirst分配的内存,可以停止一个_findfirst/_findnext序列
int _findclose( long handle );8.2目录显示函数的实现
void DirectionList(const string &path, vector<string> &sub_dir, vector<string> &sub_file)
{
struct _finddata_t file;
//"D:\\C_project\\test";
string _path = path;
//"D:\\C_project\\test\\*.*";
_path += "\\*.*";
long handle = _findfirst(_path.c_str(), &file);
if(handle == -1)
{
printf("扫描目录失败.\n");
return;
}
do
{
if(file.name[0] == '.')
continue;
//cout<<file.name<<endl;
if(file.attrib & _A_SUBDIR)
sub_dir.push_back(file.name);
else
sub_file.push_back(file.name);
if(file.attrib & _A_SUBDIR)
{
//文件为目录(文件夹)
//"D:\\C_project\\test"
string tmp_path = path;
//"D:\\C_project\\test\\"
tmp_path += "\\";
//"D:\\C_project\\test\\git"
tmp_path += file.name;
//目录递归遍历
DirectionList(tmp_path, sub_dir, sub_file);
}
}while(_findnext(handle,&file) == 0);
_findclose(handle);
}九、数据管理模块
dataManager.h和dataManager.cpp
功能:管理数据
9.1SQLite
什么是SQLite?
SQLite是一个进程内的库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。它是一个零配置的数据库,这意味着与其他数据库不一样,您不需要在系统中配置。
就像其他数据库,SQLite 引擎不是一个独立的进程,可以按应用程序需求进行静态或动态连接。SQLite 直接访问其存储文件。
为什么要用SQLite?
-
不需要一个单独的服务器进程或操作的系统(无服务器的)。
-
SQLite 不需要配置,这意味着不需要安装或管理。
-
一个完整的 SQLite 数据库是存储在一个单一的跨平台的磁盘文件。
-
SQLite 是非常小的,是轻量级的,完全配置时小于 400KiB,省略可选功能配置时小于250KiB。
-
SQLite 是自给自足的,这意味着不需要任何外部的依赖。
-
SQLite 事务是完全兼容 ACID 的,允许从多个进程或线程安全访问。
-
SQLite 支持 SQL92(SQL2)标准的大多数查询语言的功能。
-
SQLite 使用 ANSI-C 编写的,并提供了简单和易于使用的 API。
-
SQLite 可在 UNIX(Linux, Mac OS-X, Android, iOS)和 Windows(Win32, WinCE, WinRT)中运行。
9.2sqlite C/C++的API使用
什么是API?
API(Application Program Interface)被定义为应用程序可用以与计算机操作系统交换信息和命令的标准集。一个标准的应用程序界面为用户或软件开发商提供一个通用编程环境,以编写可交互运行于不同厂商计算机的应用程序。
API不是产品,而是战略,所有操作系统与网络操作系统都有API。在网络环境中不同机器的API兼容是必要的,否则程序对其所驻留的机器将是不兼容的。
安装sqlite源码:
在 C/C++ 程序中使用 SQLite 之前,我们需要确保机器上已经有 SQLite 库 。
将源码下的sqlite3.h sqlite3.c拷贝到工程目录下即可。
数据库操作的重要接口:
//打开数据库
int sqlite3_open(const char *filename, sqlite3 **ppDb);
//关闭数据库
int sqlite3_close(sqlite3*);
//执行SQL语句
int sqlite3_exec(sqlite3*, const char *sql, sqlite_callback,
void *data, char **errmsg);
int sqlite3_get_table(
sqlite3 *db, /* An open database */
const char *zSql, /* SQL to be evaluated */
char ***pazResult, /* Results of the query */
int *pnRow, /* Number of result rows written here */
int *pnColumn, /* Number of result columns written here */
char **pzErrmsg /* Error msg written here */
);
void sqlite3_free_table(char **result);9.3封装sqlite数据库管理类
新增数据管理模块:dataManager.h
class SqliteManager
{
public:
SqliteManager();
~SqliteManager();
public:
void Open(const string &database); //打开或创建数据库
void Close(); //关闭数据库
void ExecuteSql(const string &sql); //执行SQL语句
void GetResultTable(const string &sql, char **&ppRet, int &row, int &col);
private:
sqlite3 *m_db;
};dataManager.cpp
#include"dataManager.h"
SqliteManager::SqliteManager():m_db(nullptr)
{}
SqliteManager::~SqliteManager()
{}
void SqliteManager::Open(const string &database)
{
int rc = sqlite3_open(database.c_str(), &m_db);
if (rc != SQLITE_OK)
{
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(m_db));
exit(1);
}
else
{
fprintf(stderr, "Opened database successfully\n");
}
}
void SqliteManager::Close()
{
int rc = sqlite3_close(m_db);
if (rc != SQLITE_OK)
{
fprintf(stderr, "Can't close database: %s\n", sqlite3_errmsg(m_db));
exit(1);
}
else
{
fprintf(stderr, "Close database successfully\n");
}
}
void SqliteManager::ExecuteSql(const string &sql)
{
char *zErrMsg = 0;
int rc = sqlite3_exec(m_db, sql.c_str(), 0, 0, &zErrMsg);
if (rc != SQLITE_OK)
{
fprintf(stderr, "SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}
else
{
fprintf(stdout, "Operation sql successfully\n");
}
}
void SqliteManager::GetResultTable(const string &sql, char **&ppRet, int &row, int &col)
{
char *zErrMsg = 0;
int rc = sqlite3_get_table(m_db, sql.c_str(), &ppRet, &row, &col, &zErrMsg);
if(rc != SQLITE_OK)
{
fprintf(stderr, "SQL Error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}
else
{
fprintf(stdout, "Get Result Table successfully\n");
}
}9.4封装数据管理类
目的:方便对数据库的操作,因为最后并不是对数据库进行操作,而是让本地文件和数据库的文件进行持续的对比,确保本地文件和数据库的文件是同步的,简而言之,并不直接去操作数据库。
//封装数据管理类
class DataManager
{
public:
DataManager();
~DataManager();
public:
void InitSqlite(); //初始化数据库
void InsertDoc(const string &path, const string &doc);
void DeleteDoc(const string &path, const string &doc);
void GetDoc(const string &path, multiset<string> &docs);
private:
SqliteManager m_dbmgr;
};
DataManager::DataManager()
{
m_dbmgr.Open(DOC_DB);
InitSqlite(); //创建表
}
DataManager::~DataManager()
{}
void DataManager::InitSqlite()
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "CREATE TABLE if not exists %s(\
id integer primary key autoincrement,\
doc_name text,\
doc_path text)", DOC_TB);
m_dbmgr.ExecuteSql(sql);
}
void DataManager::InsertDoc(const string &path, const string &doc)
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "INSERT INTO %s values(null, '%s', '%s')",
DOC_TB, doc.c_str(), path.c_str());
m_dbmgr.ExecuteSql(sql);
}
void DataManager::DeleteDoc(const string &path, const string &doc)
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "DELETE FROM %s where doc_path='%s' and doc_name='%s'",
DOC_TB, path.c_str(), doc.c_str());
m_dbmgr.ExecuteSql(sql);
}
void DataManager::GetDoc(const string &path, multiset<string> &docs)
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "SELECT doc_name from %s where doc_path='%s'",
DOC_TB, path.c_str());
char **ppRet = 0;
int row = 0, col = 0;
m_dbmgr.GetResultTable(sql, ppRet, row, col);
for(int i=1; i<=row; ++i)
docs.insert(ppRet[i]);
//释放表结果
sqlite3_free_table(ppRet);
}9.4.1 新增搜索函数
在dataManager类中新增函数:
使用like模糊匹配
void DataManager::Search(const string &key, vector<pair<string,string>> &doc_path)
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "SELECT doc_name, doc_path from %s where doc_name like '%%%s%%'",
DOC_TB, key.c_str());
char **ppRet;
int row, col;
m_dbmgr.GetResultTable(sql, ppRet, row, col);
for(int i=1; i<=row; ++i)
{
doc_path.push_back(make_pair(ppRet[i*col], ppRet[i*col+1]));
}
sqlite3_free_table(ppRet);
}9.4.2 利用RAII机制解决表结果的自动释放
我们万一忘记释放表结果就会导致内存泄漏,每搜索一次就会泄漏一次,如果搜的次数多的话,会导致内存资源被耗光;
手动释放表结果还是有点麻烦的,而且我们难免保证每次都会去释放表结果资源。
所以我们就想着能不能让他自动的去释放呢?
智能指针的思想RAll机制。
增加一个AutoGetResultTable类
在管理数据的时候,只要获取了表,每次才析构的时候都会释放表结果资源。
class AutoGetResultTable
{
public:
AutoGetResultTable(SqliteManager &db, const string &sql, char **&ppRet, int &row, int &col);
~AutoGetResultTable();
private:
SqliteManager &m_db;
char **m_ppRet;
};
AutoGetResultTable::AutoGetResultTable(SqliteManager &db, const string &sql,
char **&ppRet, int &row, int &col)
:m_db(db), m_ppRet(nullptr)
{
m_db.GetResultTable(sql, ppRet, row, col);
m_ppRet = ppRet;
}
AutoGetResultTable::~AutoGetResultTable()
{
if(m_ppRet)
sqlite3_free_table(m_ppRet);
}问题:在写这个类的时候怎么知道要传哪些参数呢?怎么知道要有哪些成员呢?
本身这个类就是要解决的释放空间,那么要是不把空间保存下来,拿什么去释放呢?所以在类中就把ppRet给保留下来,在释放空间时,释放m_ppRet所指空间。
十、扫描模块
ScanManager.h 和 ScanManager.cpp
功能:实现本地数据与数据库数据保持同步,
让数据库与本地数据进行对比,相同地方不变,不同地方进行修改,
为了使此过程效率提高,可以借助muliiset这个容器,利用其排序性(红黑树)
10.1同步数据库和本地数据
//同步本地文件和数据库文件的数据
void ScanManager::ScanDirectory(const string &path)
{
//1 扫描本地文件
vector<string> local_dir;
vector<string> local_file;
DirectionList(path, local_dir, local_file);
multiset<string> local_set;
local_set.insert(local_file.begin(), local_file.end());
local_set.insert(local_dir.begin(), local_dir.end());
//2 扫描数据库文件
multiset<string> db_set;
m_dbmgr.GetDoc(path, db_set);
//3 同步数据
auto local_it = local_set.begin();
auto db_it = db_set.begin();
while(local_it!=local_set.end() && db_it!=db_set.end())
{
if(*local_it < *db_it)
{
//本地有,数据库没有,数据库插入文件
m_dbmgr.InsertDoc(path, *local_it);
++local_it;
}
else if(*local_it > *db_it)
{
//本地没有,数据库有,数据库删除文件
m_dbmgr.DeleteDoc(path, *db_it);
++db_it;
}
else
{
//两者都有
++local_it;
++db_it;
}
}
while(local_it != local_set.end())
{
//本地有,数据库没有,数据库插入文件
m_dbmgr.InsertDoc(path, *local_it);
++local_it;
}
while(db_it != db_set.end())
{
//本地没有,数据库有,数据库删除文件
m_dbmgr.DeleteDoc(path, *db_it);
++db_it;
}
}10.2新增实时扫描功能
上面这个扫描是在搜索之前先进行了扫描,当程序运行之后,当更改本地数据之后无法同步数据库内容,如果想要同步的话,需要将程序重新启动,这个方法虽然可以解决问题但很不现实。
所以,有什么办法能实时的进行同步?
我们可以是用多线程的思想,让一个线程专门去扫描,达到实时同步。
在ScanManager类中新增构造函数和扫描线程函数:
class ScanManager
{
public:
ScanManager(const string &path);
public:
//........
//扫描线程
void ScanThread(const string &path);
private:
DataManager m_dbmgr;
};线程的函数就是一直在做着扫描的工作,当然一直在while(1)效率肯定不高,后面会使用条件变量让扫描更加高效
ScanManager::ScanManager(const string &path)
{
thread ScanObj(&ScanManager::ScanThread, this, path);
ScanObj.detach();
}
void ScanManager::ScanThread(const string &path)
{
while(1)
{
ScanDirectory(path);
}
}10.3扫描管理类的单例化
上面这个扫描管理类中有什么不妥的地方,每次扫描都需要实例化一个对象,那么要是别人也实例化出来一个对象的话会怎么样?
并不需要实例化很多对象,只需要实例化一个对象,然后启动一个专门的线程去扫描就行。
一个类只产生一个对象就是叫单例化。
使用到懒汉模式实现单例化:
class ScanManager
{
public:
static ScanManager& GetInstance(const string &path);
protected:
ScanManager(const string &path);
ScanManager(ScanManager &);
ScanManager& operator=(const ScanManager&);
private:
//DataManager m_dbmgr;
};
ScanManager& ScanManager::GetInstance(const string &path)
{
static ScanManager _inst(path);
return _inst;
}十一、对sqlite进行静态链接库的使用
为什么使用静态链接库?
函数实现的过程不想要告诉别人,保护我们的源码(藏起来)。
1、静态库和动态库
.lib称为静态链接库 .dll称为动态链接库
2、创建静态库工程
3、添加程序的头文件和源文件,不用写主函数,直接点击生成静态链接
4、在Debug下面就能找到生成的静态库
5、使用生成静态链接库
将程序的头文件.h + 静态链接库文件.lib 拷贝至工程
6、通过#pragma comment(lib, "xxxx.lib")
7、按照上述步骤制作sqlite的静态链接库
8、删除sqlite3.c,使用sqlite3.lib进行替换,然后通过命令引入静态库
#pragma comment(lib, "./sqlite3/sqlite3.lib")
十二、日志模块
1、什么是日志
网络设备、系统及服务程序等在运作时都会产生一个叫log的事件记录;每一行日志都记载着日期、时间、使用者及动作等相关操作的描述;它记录了用户访问系统的全过程:哪些人在什么时间,通过什么渠道(比如搜索引擎、网址输入)来过,都执行了哪些操作;系统是否产生了错误;甚至包括用户的 IP、HTTP 请求的时间,用户代理等。
2、日志的级别
日志一共分成5个等级,从低到高分别是:
DEBUG
INFO
WARNING
ERROR
CRITICAL
说明:
DEBUG:详细的信息,通常只出现在诊断问题上
INFO:确认一切按预期运行
WARNING:一个迹象表明,一些意想不到的事情发生了,或表明一些问题在不久的将来(例如。磁盘空间低”)。这个软件还能按预期工作。
ERROR:更严重的问题,软件没能执行一些功能
CRITICAL:一个严重的错误,这表明程序本身可能无法继续运行
这5个等级,也分别对应5种打日志的方法: debug 、info 、warning 、error 、critical。默认的是WARNING,当在WARNING或之上时才被跟踪。3、日志实现
//获取文件名
string GetFileName(const string &path);
//追踪日志
void __TraceDebug(const char *filename, int line, const char *function,
const char *date, const char *time,
const char *format, ...);
//错误日志
void __ErrorDebug(const char *filename, int line, const char *function,
const char *date, const char *time,
const char *format, ...);
#define TRACE_LOG(...) __TraceDebug(__FILE__, __LINE__, __FUNCTION__, __DATE__, __TIME__, __VA_ARGS__)
#define ERROR_LOG(...) __ErrorDebug(__FILE__, __LINE__, __FUNCTION__, __DATE__, __TIME__, __VA_ARGS__)
string GetFileName(const string &path)
{
char token = '\\';
size_t pos = path.rfind(token);
if(pos == string::npos)
return path;
return path.substr(pos+1);
}
void __TraceDebug(const char *filename, int line, const char *function,
const char *date, const char *time,
const char *format, ...)
{
#ifdef __TRACE__
fprintf(stdout, "[TRACE][%s:%d:%s %s:%s]:", GetFileName(filename).c_str(),
line, function,
date, time);
//读取可变参数
va_list args; //char *args;
va_start(args, format);
vfprintf(stdout, format, args);
va_end(args);
fprintf(stdout, "\n");
#endif
}
void __ErrorDebug(const char *filename, int line, const char *function,
const char *date, const char *time,
const char *format, ...)
{
#ifdef __ERROR__
fprintf(stdout, "[ERROR][%s:%d:%s %s:%s]:", GetFileName(filename).c_str(),
line, function,
date, time);
//读取可变参数
va_list args; //char *args;
va_start(args, format);
vfprintf(stdout, format, args);
va_end(args);
fprintf(stdout, "\n");
#endif
}十三、监控模块
只有扫描而没有监控的话,扫描线程就会一直死循环的扫描,文件少的时候还没啥大问题,文件多的话,每扫描一次所用时间变多,本地文件并没有改变,但是扫描线程还是在扫描,浪费资源。
这是,新增一个监控线程,当本地文件发生改变的时候,再去通知扫描线程进行扫描。
监控的文件改变情况:文件被删除,文件重命名,增加文件
需要引入几个API函数:
1、需要使用到的API接口
#include<windows.h>
HANDLE FindFirstChangeNotification(
LPCTSTR lpPathName, // pointer to name of directory to watch
BOOL bWatchSubtree, // flag for monitoring directory or
// directory tree
DWORD dwNotifyFilter // filter conditions to watch for
);
BOOL FindNextChangeNotification(
HANDLE hChangeHandle // handle to change notification to signal
);
DWORD WaitForSingleObject(
HANDLE hHandle, // handle to object to wait for
DWORD dwMilliseconds // time-out interval in milliseconds
);2、添加互斥量和条件变量
#include<mutex>
#include<condition_variable>
class ScanManager
{
//...............
mutex m_mutex;
condition_variable m_cond;
3、监控模块实现
void ScanManager::ScanThread(const string &path)
{
//初始化扫描
ScanDirectory(path);
while(1)
{
unique_lock<mutex> lock(m_mutex);
m_cond.wait(lock); //条件阻塞
ScanDirectory(path);
}
}
void ScanManager::WatchThread(const string &path)
{
HANDLE hd = FindFirstChangeNotification(path.c_str(), true,
FILE_NOTIFY_CHANGE_FILE_NAME | FILE_NOTIFY_CHANGE_DIR_NAME);
if(hd == INVALID_HANDLE_VALUE)
{
//cout<<"监控目录失败."<<endl;
ERROR_LOG("监控目录失败.");
return;
}
while(1)
{
WaitForSingleObject(hd, INFINITE); //永不超时等待
m_cond.notify_one();
FindNextChangeNotification(hd);
}
}unique_lock<mutex> lock(m_mutex); 这个锁对象是构造函数加锁,析构函数解锁
十四、中间逻辑层实现
1、准备工具函数
//汉字转拼音
string ChineseConvertPinYinAllSpell(const string &dest_chinese);
//汉字转拼音首字母
string ChineseConvertPinYinInitials(const string &name);2、实现拼音全拼和首字母的搜索
a.对数据库表新增字段
实现转拼音和转首字母之后,还需要在数据库的表中增加两列内容 doc_name_py 和 doc_name_initials
void DataManager::InitSqlite()
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "CREATE TABLE if not exists %s(\
id integer primary key autoincrement,\
doc_name text,\
doc_name_py text,\
doc_name_initials text,\
doc_path text)", DOC_TB);
m_dbmgr.ExecuteSql(sql);
}b.新增数据
void DataManager::InsertDoc(const string &path, const string &doc)
{
//汉字转拼音
string doc_py = ChineseConvertPinYinAllSpell(doc);
//汉字转首字母
string doc_initials = ChineseConvertPinYinInitials(doc);
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "INSERT INTO %s values(null, '%s', '%s','%s', '%s')",
DOC_TB, doc.c_str(), doc_py.c_str(), doc_initials.c_str(), path.c_str());
m_dbmgr.ExecuteSql(sql);
}c.新增拼音和首字母的搜索
void DataManager::Search(const string &key, vector<pair<string,string>> &doc_path)
{
//汉字转拼音
string doc_py = ChineseConvertPinYinAllSpell(key);
//汉字转首字母
string doc_initials = ChineseConvertPinYinInitials(key);
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "SELECT doc_name, doc_path from %s where doc_name like '%%%s%%' or\
doc_name_py like '%%%s%%' or doc_name_initials like '%%%s%%'",
DOC_TB, key.c_str(), doc_py.c_str(), doc_initials.c_str());
char **ppRet;
int row, col;
//m_dbmgr.GetResultTable(sql, ppRet, row, col);
AutoGetResultTable at(m_dbmgr, sql, ppRet, row, col);
doc_path.clear(); //清除之前搜索的数据
for(int i=1; i<=row; ++i)
{
doc_path.push_back(make_pair(ppRet[i*col], ppRet[i*col+1]));
}
//释放表结果
//sqlite3_free_table(ppRet);
}3、高亮显示搜索
原理:分割,把搜索到的文件名字符串分为三个部分:前缀,高亮部分,后缀
a.颜色打印函数
// 颜色高亮显示一段字符串
void ColourPrintf(const char* str)
{
// 0-黑 1-蓝 2-绿 3-浅绿 4-红 5-紫 6-黄 7-白 8-灰 9-淡蓝 10-淡绿
// 11-淡浅绿 12-淡红 13-淡紫 14-淡黄 15-亮白
//颜色:前景色 + 背景色*0x10
//例如:字是红色,背景色是白色,即 红色 + 亮白 = 4 + 15*0x10
WORD color = 9 + 0 * 0x10;
WORD colorOld;
HANDLE handle = GetStdHandle(STD_OUTPUT_HANDLE);
CONSOLE_SCREEN_BUFFER_INFO csbi;
GetConsoleScreenBufferInfo(handle, &csbi);
colorOld = csbi.wAttributes;
SetConsoleTextAttribute(handle, color);
printf("%s", str);
SetConsoleTextAttribute(handle, colorOld);
}b.实现高亮分割函数
把整个字符串分为三个部分:前缀,高亮部分,后缀。
在dataManager类中新增分割函数
//封装数据管理类
class DataManager
{
public:
static void SplitHighLight(const string &str, const string &key,
string &prefix, string &highlight, string &suffix);
};
void DataManager::SplitHighLight(const string &str, const string &key,
string &prefix, string &highlight, string &suffix)
{
//忽略大小的匹配
string strlower = str;
string keylower = key;
transform(strlower.begin(), strlower.end(), strlower.begin(), tolower);
transform(keylower.begin(), keylower.end(), keylower.begin(), tolower);
//原始字符串能够匹配
size_t pos = strlower.find(keylower);
if(pos != string::npos)
{
prefix = str.substr(0, pos);
highlight = str.substr(pos, keylower.size());
suffix = str.substr(pos+keylower.size(), str.size());
return;
}
//拼音全拼搜索分割
string str_py = ChineseConvertPinYinAllSpell(strlower);
pos = str_py.find(keylower);
if(pos != string::npos)
{
int str_index = 0; //控制原始字符串的下标
int py_index = 0; //控制拼音字符串的下标
int highlight_index = 0; //控制高亮显示字符串的起始位置
int highlight_len = 0; //控制高亮字符串的长度
while(str_index < str.size())
{
if(py_index == pos)
{
//记录高亮的起始位置
highlight_index = str_index;
}
if(py_index >= pos+keylower.size())
{
//关键字搜索结束
highlight_len = str_index - highlight_index;
break;
}
if(str[str_index]>=0 && str[str_index]<=127)
{
//原始字符串是一个字符
str_index++;
py_index++;
}
else
{
//原始字符串是一个汉字
string word(str, str_index, 2); //截取一个汉字 //校
string word_py = ChineseConvertPinYinAllSpell(word);//xiao
str_index += 2;
py_index += word_py.size();
}
}
prefix = str.substr(0, highlight_index);
highlight = str.substr(highlight_index, highlight_len);
suffix = str.substr(highlight_index+highlight_len, str.size());
return;
}
//首字母搜索
string str_initials = ChineseConvertPinYinInitials(strlower);
pos = str_initials.find(keylower);
if(pos != string::npos)
{
int str_index = 0;
int initials_index = 0;
int highlight_index = 0;
int highlight_len = 0;
while(str_index < str.size())
{
if(initials_index == pos)
{
//记录高亮的起始位置
highlight_index = str_index;
}
if(initials_index >= pos+keylower.size())
{
highlight_len = str_index - highlight_index;
break;
}
if(str[str_index]>=0 && str[str_index]<=127)
{
//原始字符串是一个字符
str_index++;
initials_index++;
}
else
{
//原始字符串是一个汉字
str_index += 2;
initials_index++;
}
}
prefix = str.substr(0, highlight_index);
highlight = str.substr(highlight_index, highlight_len);
suffix = str.substr(highlight_index+highlight_len, str.size());
return;
}
//没有搜索到关键字
prefix = str;
highlight.clear();
suffix.clear();
}十五、客户端模块
新增客户端模块sysFrame.h 和 sysFrame.cpp
1、界面核心技术system
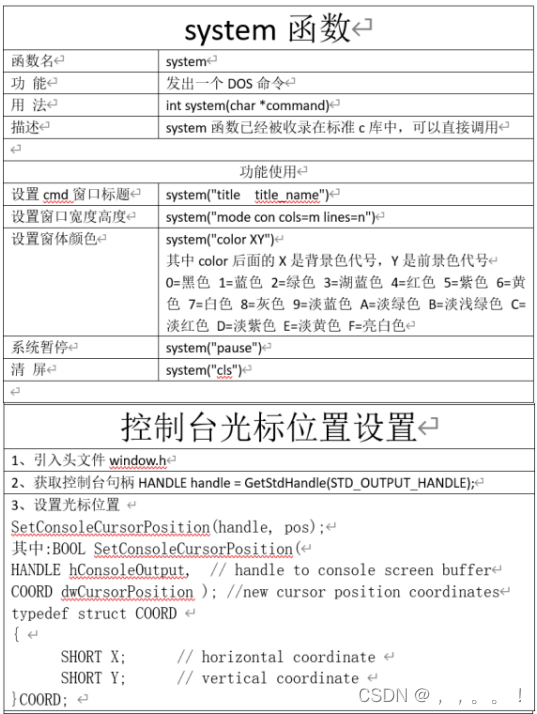
2、增加界面
void SetCurPos(int col, int row);
void HideCursor();
void DrawCol(int x, int y);
void DrawRow(int x, int y);
void DrawFrame(const char *title);
void DrawMenu();3、界面实现
#define WIDTH 120
#define HEIGHT 30
#define MAX_TITLE_SIZE 100
void SetCurPos(int col, int row)
{
//获取句柄
HANDLE hd = GetStdHandle(STD_OUTPUT_HANDLE);
//x代表列, y代表行
COORD pos = {col, row};
SetConsoleCursorPosition(hd, pos);
}
void HideCursor()
{
//获取句柄
HANDLE hd = GetStdHandle(STD_OUTPUT_HANDLE);
CONSOLE_CURSOR_INFO cur_info = {100, false};
SetConsoleCursorInfo(hd, &cur_info);
}
void DrawCol(int x, int y)
{
for (int i = 0; i < HEIGHT; ++i)
{
SetCurPos(x, y + i);
printf("||");
}
}
void DrawRow(int x, int y)
{
for (int i = 0; i < WIDTH - 4; ++i)
{
SetCurPos(x + i, y);
printf("=");
}
}
void DrawFrame(const char *title)
{
char buffer[MAX_TITLE_SIZE + 6 + 1] = "title "; //6:title%20 1:\0
strcat(buffer, title);
system(buffer); //设置系统标题
char mode[128] = { 0 };
sprintf(mode, "mode con cols=%d lines=%d", WIDTH, HEIGHT);
system(mode); //设置控制台的长度和宽度
system("color 0F");//设置颜色
DrawCol(0, 0);
DrawCol(WIDTH - 2, 0);
DrawRow(2, 0);
DrawRow(2, 2);
DrawRow(2, 4);
DrawRow(2, HEIGHT - 4);
DrawRow(2, HEIGHT - 2);
}
extern const char *title;
void DrawMenu()
{
//标题的设置
SetCurPos((WIDTH - 4 - strlen(title)) / 2, 1);
printf("%s", title);
//名称 路径
SetCurPos(2, 3);
printf("%-30s %-85s", "名称", "路径");
//退出设置
SetCurPos((WIDTH - 4 - strlen("exit 退出系统 .")) / 2, HEIGHT - 3);
printf("%s", "exit 退出系统 .");
DrawRow(2, HEIGHT - 6);
//SetCurPos((WIDTH-4-strlen("请输入:>"))/2, 15);
SetCurPos(2, HEIGHT - 5);
printf("%s", "请输入:>");
}4、重构搜索
const char *title = "文档快速搜索工具";
int main(int argc, char *argv[])
{
const string path = "C:\\Bit\\Code\\bit77\\Pro_文档快速搜索工具\\TestDoc";
//扫描目录
ScanManager &sm = ScanManager::GetInstance(path);
//搜索
DataManager &dm = DataManager::GetInstance();
vector<pair<string,string>> doc_path;
string key;
while(1)
{
//显示界面
DrawFrame(title);
DrawMenu();
cin>>key;
if(key == "exit")
break;
dm.Search(key, doc_path);
int row = 5; //默认5行
int count = 0; //显示的行数
string prefix, highlight, suffix;
for(const auto &e : doc_path) //e : doc_name doc_path
{
//高亮分割
string doc_name = e.first;
DataManager::SplitHighLight(doc_name, key, prefix, highlight, suffix);
//设置文档名显示位置
SetCurPos(2, row+count++);
cout<<prefix;
ColourPrintf(highlight.c_str());
cout<<suffix;
//设置路劲名显示位置
SetCurPos(33, row+count-1);
printf("%--85s\n", e.second.c_str());
}
SystemEnd();
SystemPause();
}
SystemEnd();
return 0;
}项目中遇到的问题:
遇到的问题挺多,主要有这个三个问题:资源的正确释放、搜索字符的高亮显示和使用监控模块监控文件的变化从而去调用扫描模块,如下对这三个问题进行逐一讨论:
对于资源的正确释放:发现这个问题是在让搜索线程死循环搜索时,发现程序开始莫名的报错,然后就发现内存资源被耗光。
然后想到了使用RAll的思想,每次去安全释放搜索表结果的资源;
搜索字符的高亮显示:
刚开始通过system“color XX” 将搜索的内容高亮处理,但是会把所有要打印的内容改变颜色,不能实现一行内容当中所匹配的几个字符的颜色改变;
然后想到了将字符串分割得到三个部分,只将匹配的到字符的颜色改变。
监控模块:在使用while(1)死循环加上扫描模块的时候,可以解决问题得到正确的结果,但是扫描路径下的文件变多的时候,扫描一次所使用的时间将会变得很长,而且很耗CPU资源。
然后想到了,怎么使用一个东西去监控文件数据是否发生变化,当文件数据真正的改变的时候这时候才会去通知扫描模块(条件变量),去扫描同步文件数据跟数据库数据,然后再加上单例的思想(懒汉模式),然后这个东西就是封装成了监控模块,使用条件变量,完成通知扫描模块的功能。
碰瓷一下Everything:
对比everything,这个项目就如同小小巫见大大巫,
做这个项目的目的,是为了使用数据库,熟悉数据库的简单操作,锻炼我们的编程能力。
1、Everything优缺点
优点:搜索效率高,不分路劲,搜索的是整个电脑
缺点:不支持拼音搜索,首字母搜搜, 只支持NTFS格式的分区
2、自己的项目优缺点
优点:持拼音搜索,首字母搜索,高亮显示
缺点:需要指定路劲搜索,如果数据量非常大,搜索效率可能会比较低下
3、Everything 原理
读取日志文件,不需要扫描目录,实现快速搜索。【一定要去了解,预防面试官问到】
everything搜索文件的速度之所以快得令人愤怒,主要原因是利用了NTFS的USNJournal特性,直
接从系统的主文件表里读取文件信息。















 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









