






大家好,我是王海林,目前是Apache SeaTunnel社区的PMC Member。今天我为大家带来的主题是《Apache SeaTunnel 构建高效数据同步管道》。

Apache SeaTunnel是一站式数据集成平台,支持离线和实时数据同步,提供了灵活的扩展和高效的并行处理,确保数据一致性。
本文介绍了SeaTunnel的架构设计、核心功能、最佳实践以及如何参与社区共建,帮助用户快速上手并深入了解其强大功能。
接下来,我将从以下五个方面进行分享:
- 项目基本介绍
- 入门体验
- 核心设计揭秘
- 最佳实践推荐
- 参与社区共建
项目基本介绍
诞生背景
在数据集成的早期,主要以ETL(Extract, Transform, Load)概念为主。这一时期的主要任务是从客户的生产环境中同步各种生产系统产生的业务过程数据,例如ERP、CRM等。
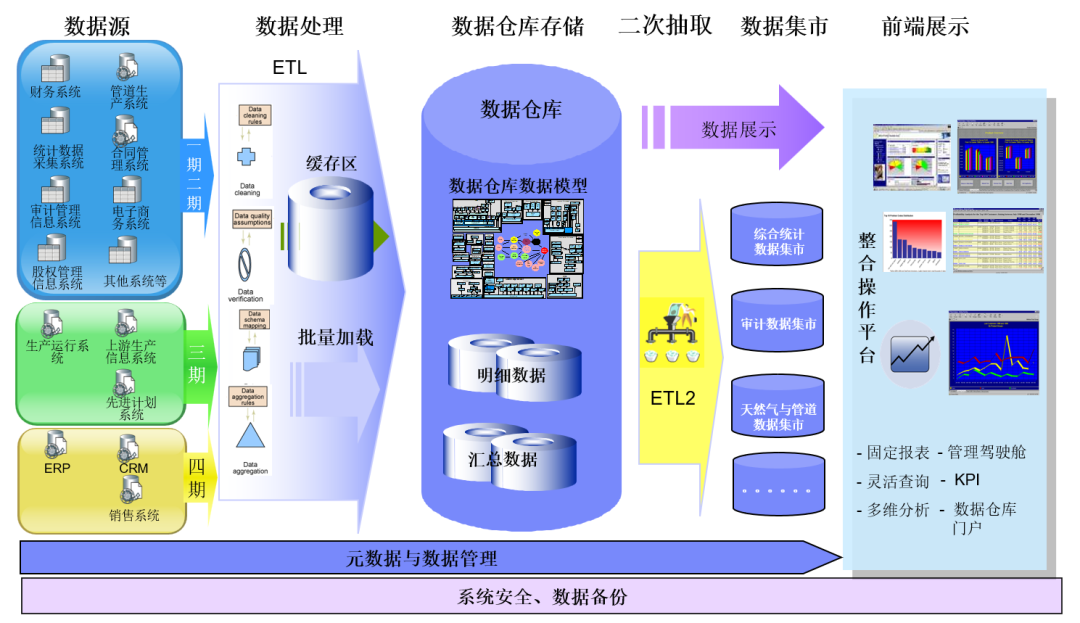
这些数据通常存储在关系数据库中,并通过专业的ETL工具进行抽取和同步,最终进入数据仓库,用于BI报表和统计分析。而这个时期代表性的ETL工具包括Informatica、Talend和Kettle,Kettle则是这个时期用得比较多的开源工具。
随着分布式技术的流行,如Hadoop和MPP(大规模并行处理)存储的普及,数据同步逐渐向同步时进行简单抽取,完成后再进行复杂加工和计算处理的方向发展,抽取过程开始使用MR(MapReduce)等程序框架。
近年来,新的概念EtLT(Extract, Transform, Load, Transform)逐渐兴起。
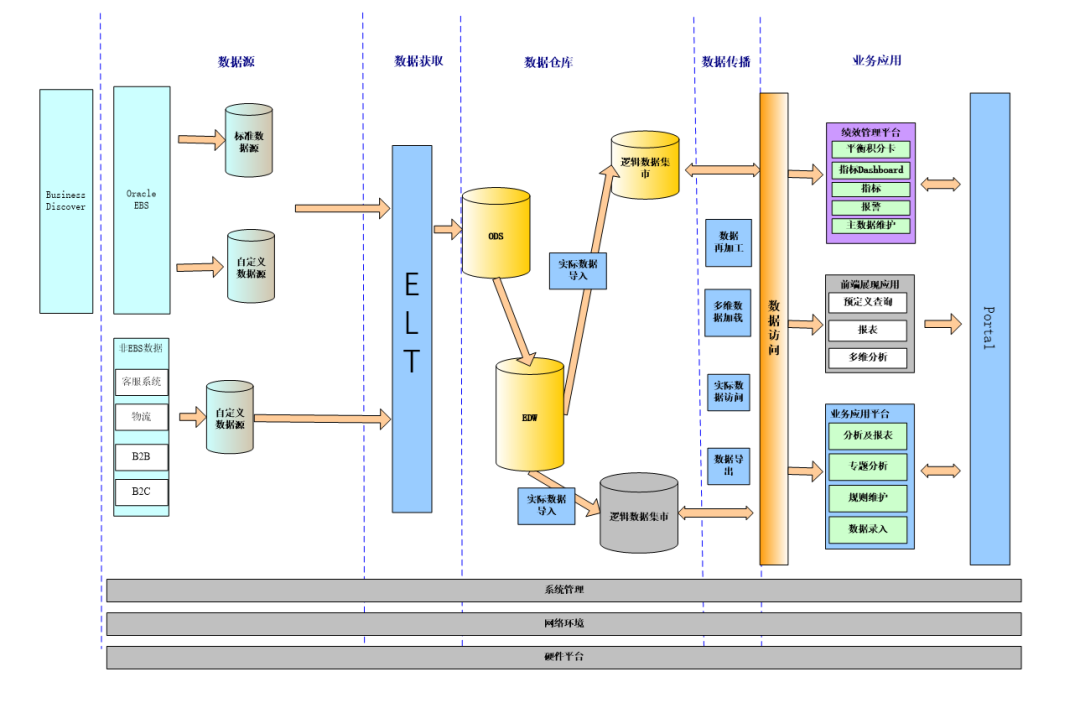
这种方法将ETL中的转换步骤(T)进行分离和提取,抽取过程中只做轻量级转换和脏数据清洗过滤,而将复杂分析和转换放在贴近业务的地方进行。
这一阶段的数据集成更加工程化,着重于处理性能和兼容性。
在这种背景下,Apache SeaTunnel应运而生。SeaTunnel专注于数据的抽取、轻量级转换和高效、快速、兼容性广泛的加载(Load),在数据集成的各个阶段都具有独特优势。
用户痛点
了解了数据集成的发展历程后,我们再看看数据集成阶段用户面临的主要痛点:
数据源的繁多
随着存储技术的发展,数据源种类迅速增加,并且存在各种版本兼容问题,不同版本可能同时使用,增加了管理的复杂性。
集成场景的复杂性
集成场景的复杂性也在增加,除了离线加载,还有实时监听性同步、全量加载、增量加载以及CDC(Change Data Capture)等。
降低影响及高性能
在这些场景中,还需要保证对数据源影响最小,不干扰业务使用,同时实现高吞吐、低延时和同步过程中的指标监控与量化。
数据一致性
此外,在满足多种场景的同时,必须保证数据的一致性,避免重复和丢失。这对数据集成技术提出了简单易用、易管理、易维护和可扩展的要求,以便应对复杂的集成需求和企业特有的问题。
Apache SeaTunnel 的解决方案
前面我们说到,SeaTunnel的目标是成为一站式的数据集成平台。截止到现在,对于SeaTunnel的用户来说,只需编写简单的任务配置文件,通过提交客户端运行任务即可。
大多数常见的数据存储源都已内置集成,无需额外开发,SeaTunnel的生态系统丰富,兼容数据库、消息队列、文件、云存储、数据湖仓和SaaS API等。
SeaTunnel采用插件架构,方便用户扩展和定义自己的数据流,支持多场景,如离线同步、实时同步和CDC。此外,SeaTunnel还支持运行监控,能够统计任务在运行过程中的读写和性能指标。
SeaTunnel具有checkpoint概念,支持分布式快照、中断暂停恢复和两阶段提交API,保证数据的一致性。
架构设计
SeaTunnel的架构设计基于插件化架构,从下图我们可以看到,左侧是用于读取数据的插件,右侧是用于写入数据的插件,当然我们图里面只放了一部分,更全的插件支持请访问官网查看。
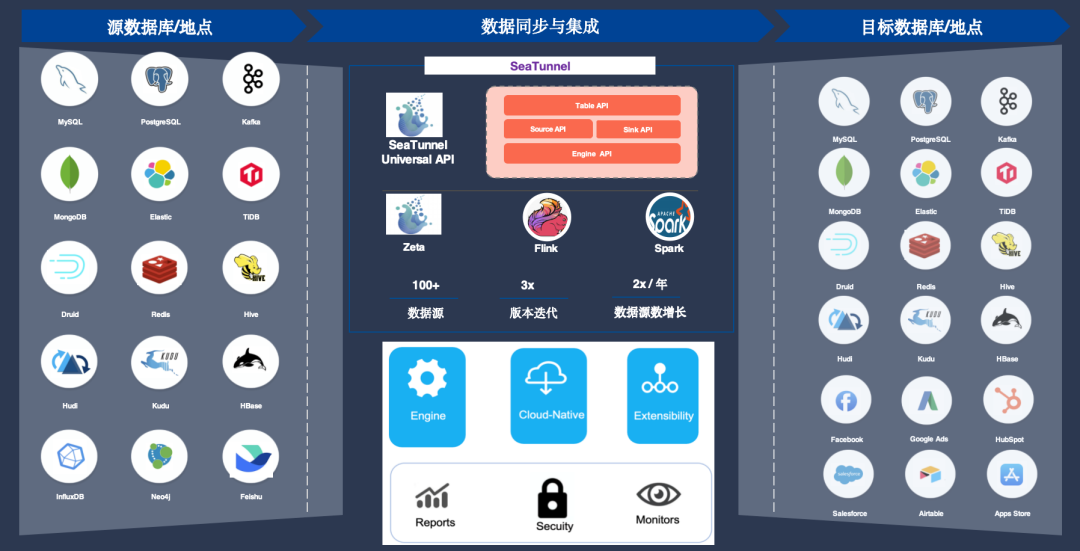
核心API设计主要包括Table API、Source API和Sink API。数据在读取后被转换为Table API,再通过Sink API写入目标存储。
SeaTunnel支持多种引擎,包括SeaTunnel社区专门为数据同步场景研发的Zeta引擎、Flink引擎和Spark引擎。用户可以将插件任务提交到不同的引擎运行。
入门体验
对SeaTunnel有了基本了解后,接下来,我将带大家进行一个简单的入门体验,帮助大家快速上手Apache SeaTunnel。
安装
如果是从官网下载SeaTunnel安装包,下载完成后需要进行插件的安装。由于安装包不包含插件,用户需要编辑插件的配置文件,并下载安装这些插件到安装包中。

如果是从源码编译安装,可以从GitHub克隆SeaTunnel工程,使用mvn命令打包dist模块,构建出一个完整的安装包。
该安装包包含所有连接器插件,无需额外下载。

任务配置
安装完成后,我们需要编写一个简单的任务配置文件来提交任务。
任务配置文件主要分为三个部分:
ENV:这里包含一些关于job的设置性配置。最主要的配置有两个,一个是parallelism,用于设置任务运行时的并行线程数。如果没有配置,默认是单线程运行;如果数据量较大,可以将其配置为多线程以提高读写速度。另一个是job.mode,用于标识任务是批处理(Batch)还是流处理(Stream)。
Source:在这一部分配置读取数据的插件。插件的名称和内部配置都在这个区块中。例如,以下示例中使用了JDBC插件,配置了result_table_name用于标识source在配置文件中的定位符。其他配置项根据具体插件的文档进行设置。
Sink:这一部分配置写入数据的插件。配置规则与Source类似,第一层是插件名称,内部配置项包括source_table_name,用于指定要接收的数据来源。例如,如果Source插件配置了my-source-1,那么Sink插件的source_table_name也应配置为my-source-1,表示数据流从Source到Sink的连接。
以下是一个简单的任务配置示例:
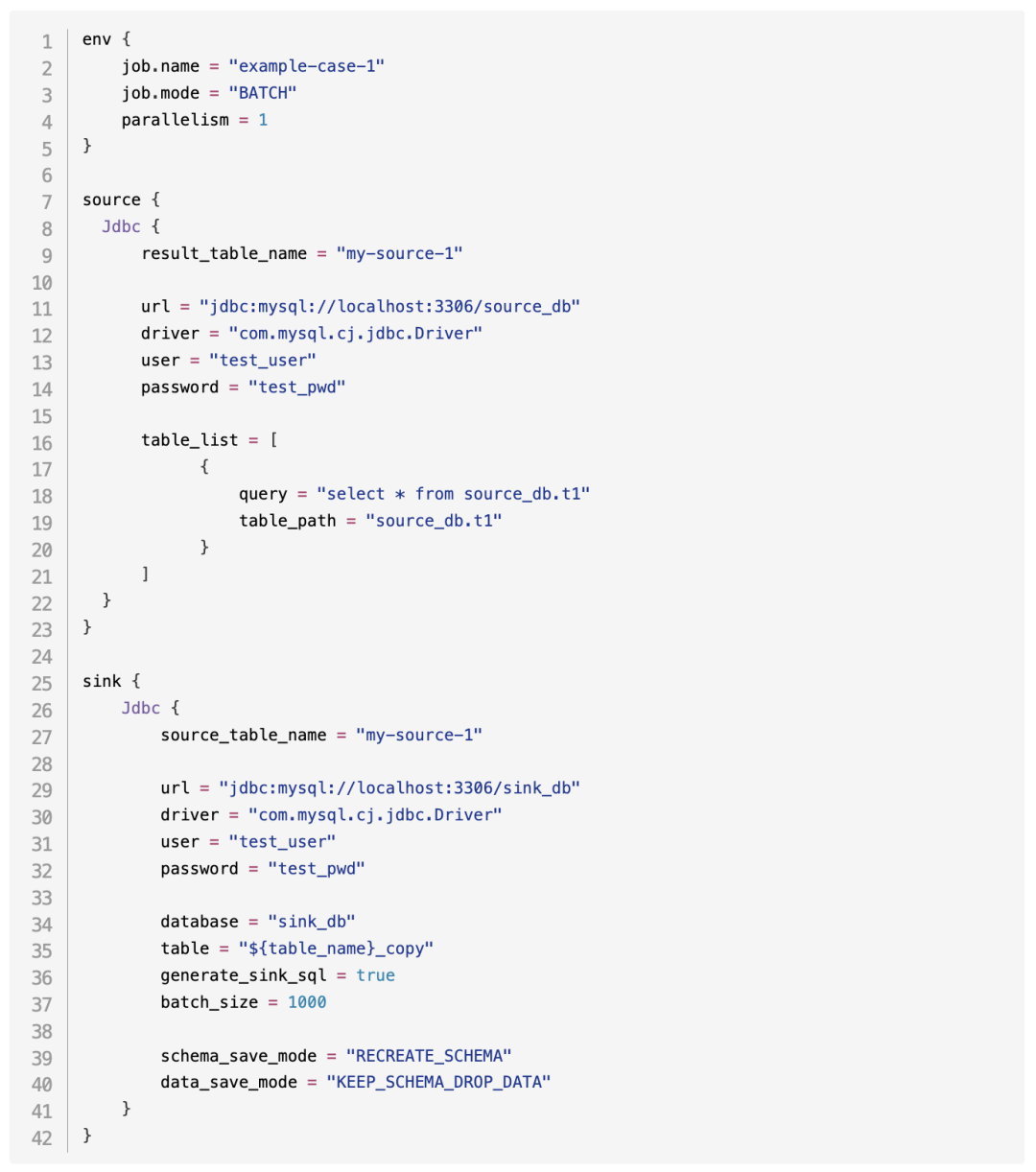
任务执行
接下来,我们需要执行这个简单的任务。
这里主要介绍Zeta引擎,在SeaTunnel的bin目录下,有一个seatunnel.sh脚本用于提交任务,提交任务的主要参数包括任务文件的路径和运行模式。
任务文件路径是刚刚编写并保存的配置文件的路径,-m是运行模式,运行模式可以是cluster或local。

cluster模式将任务提交到远程集群,这需要事先启动集群;
local模式则在本地运行任务,适合测试和无需启动集群的情况;
以下是一个简单的启动命令示例:
bin/seatunnel.sh -c config/example-job1.conf -m local通过这个命令,可以在本地运行我们刚刚配置的任务。
核心功能特性探讨
在前面简单体验了SeaTunnel之后,我们接下来探讨其核心功能设计和原理,以更好地理解SeaTunnel如何完成复杂的数据集成任务。
连接器的插件架构
SeaTunnel的连接器插件架构是其核心设计之一。
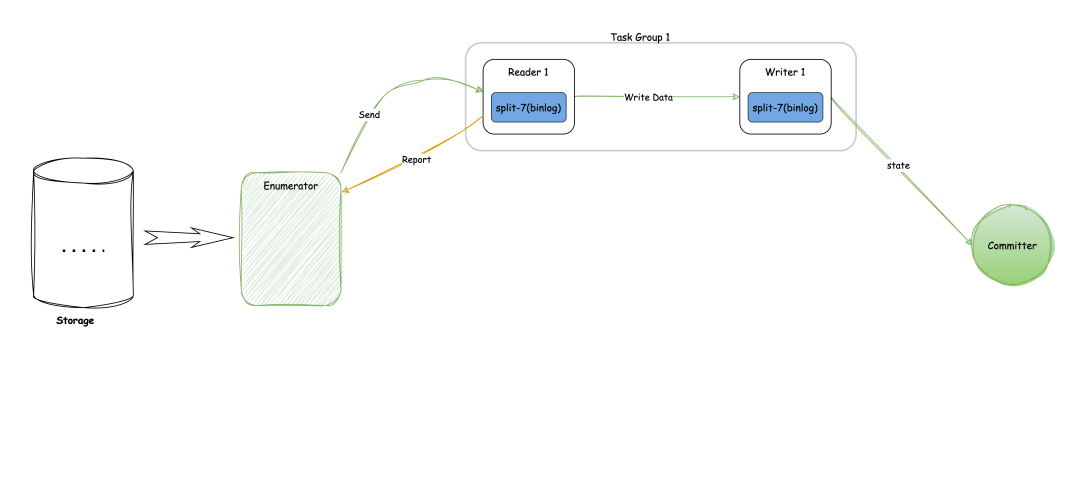
从下面这张图左侧来看的话,首先就是config,我们会编写任务的配置文件,然后 config 提交到引擎上面运行,从配置文件提交任务开始,SeaTunnel会首先解析配置文件,找到Source区块并对应到具体的Source插件代码。
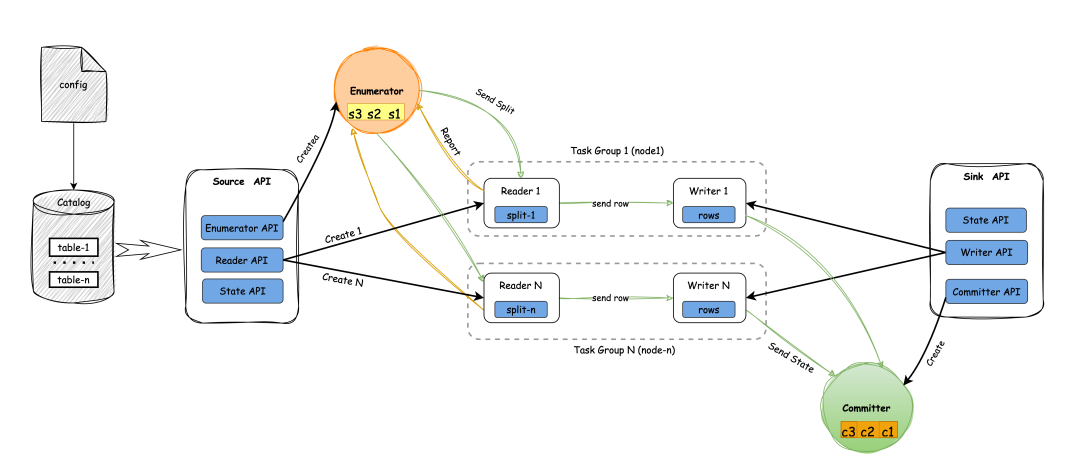
每个Source插件包含固定的结构,包括Enumerator API(枚举器)、Reader API(读取器)和State API(状态管理)。
Sink部分(图最右侧)与Source类似,也包含State API、Writer API(写入器)和Committer API(两阶段提交)。通过这种插件化的设计,SeaTunnel能够灵活应对各种数据源和目标存储的需求。
逻辑结构与运行结构
SeaTunnel的逻辑结构和运行结构通过图示可以更清晰地理解,黑色的线主要是逻辑结构,彩色的是运行结构。
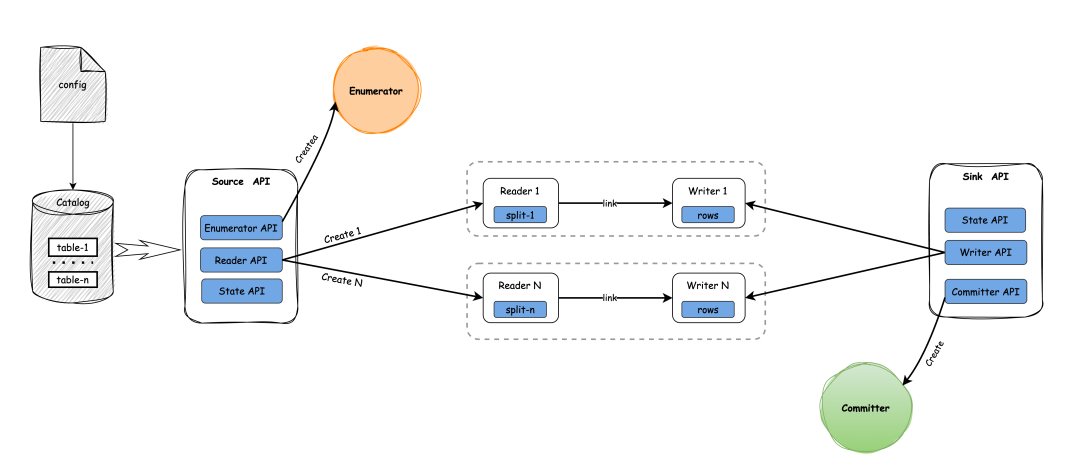
逻辑结构上,配置文件提交后,会创建Enumerator(枚举器)用于划分数据区块,然后通过Reader API创建读取器, Enumerator 会将数据块均匀发送给所有 Reader。
Reader数量与配置的并行线程数(parallelism)相对应,以实现并行数据读取。
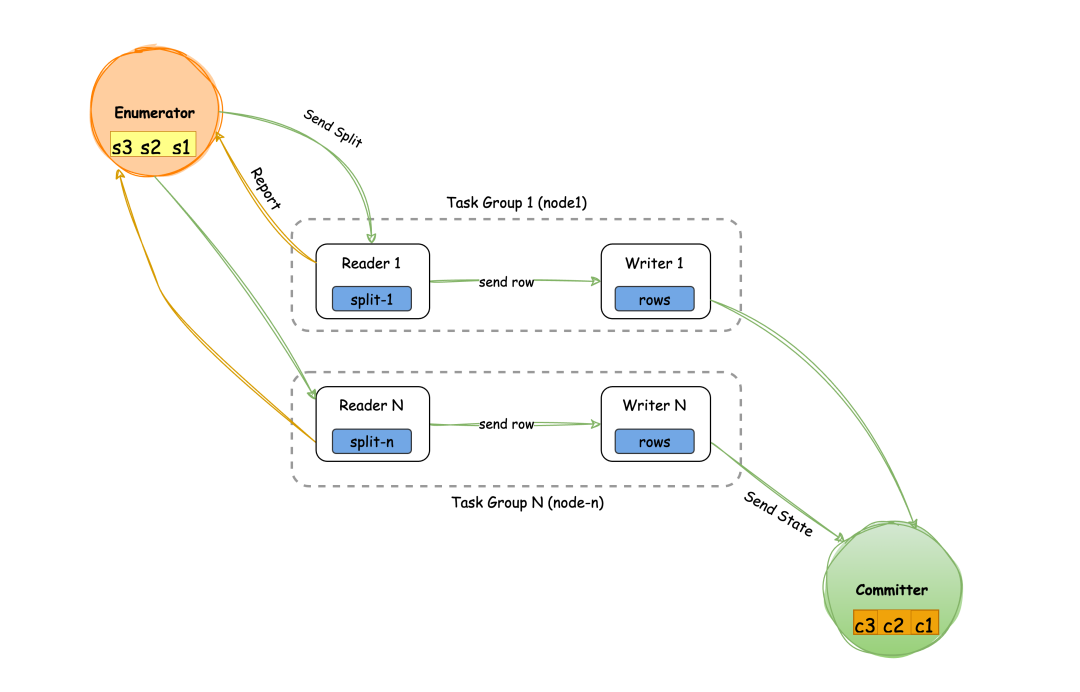
在Sink部分,配置文件会创建与Reader数量相同的Writer 并一一对应自动绑定进行数据写入,同时创建Committer用于所有 Writer 的状态提交。
通过这种逻辑转化和运行结构,SeaTunnel实现了数据从读取到写入的高效处理。
状态API的设计
在数据读写过程中,数据会从 Enumerator 开始流动到 reader 到 writer 到 committer ,那么这整个过程我们要实现中断恢复或者是异常情况的恢复,能够重新回到原来的起点去,接着读数据。
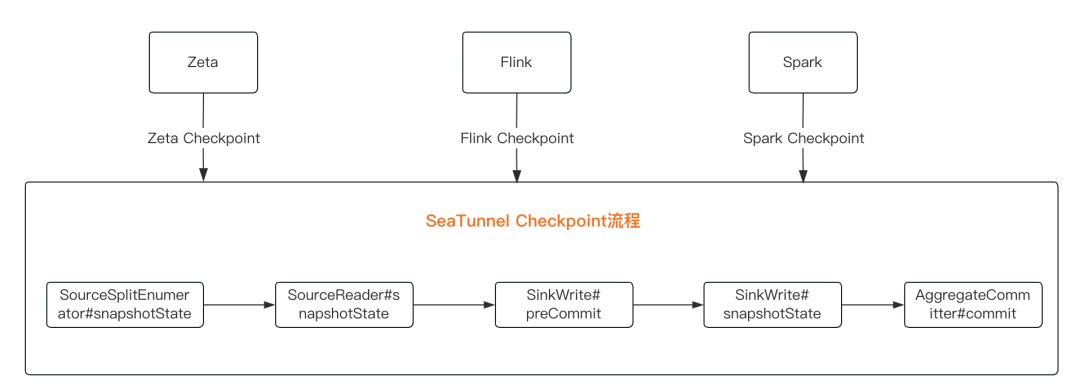
这个过程中,SeaTunnel通过状态API(State API)实现中断恢复和异常恢复。
每个运行节点会不断触发checkpoint(检查点),保存内存状态并持久化。
无论是Zeta、Flink还是Spark引擎,都需要通过splitEnumerator(枚举器)的snapshotState作为入口,将状态传递到Reader、Writer和Committer。
整个过程就是在不断地去保存所有运行节点的内存状态,然后每一次保存成功之后都能够持久化地存储下来。
接下来是运行时的逻辑结构。
最下面我们可以看到分布式快照管理器(checkpoint manager)会不断触发checkpoint,保存所有运行节点的内存状态并持久化。这样,在发生中断或异常时,可以从上一次成功的checkpoint恢复,配置触发的间隔,继续数据处理。
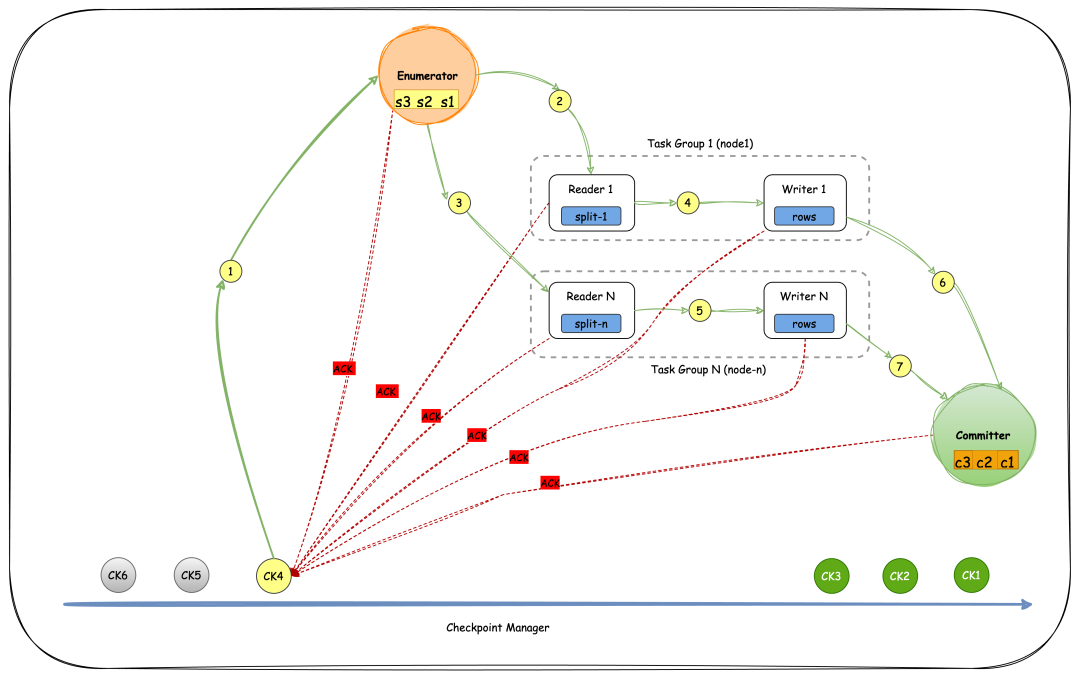
图里面我们可以看到在右侧,实际上是一些触发成功的,在左边是一些正在触发的和待触发的,那以 CK4 为例子看的话,它首先会从一开始发到枚举器Enumerator ,它在这个时候会保存自己内部的状态,有多少 split 没有发出去,有多少已经发出去了?然后枚举器会把这个 CK4 继续往后发到所有管理的 reader上面,也就是有多少并行度,这边就会发多少个出去,然后每个 reader 会去存储自身的状态,读了哪个 split?还剩多少?会把这些状态给存下来。
然后reader继续往后发,会发到对应的writer,我们可以看到reader各自会发各自的writer, writer 接收到了数据,如果有缓存的话,也会去保存一些状态,这个状态保存完之后,会把 CK4 的信号继续往后发,直到committer 收到所有 writer 的 CK4 信号,最终把这个checkpoint处理完,把它自身的还没有提交的状态保存下来。
已经提交过的这些信号全部都保存下来,这个过程会每一个节点都会给 checkpoint manager 来发 up 信号,那么我们一次成功的 checkpoint,就是所有的节点都能够流通 checkpoint 信号,并且都回了 Ack 包,所有的 Ack 都收到之后,我们认为这个 CK4 就完成了,那么它就会移动到CK3后面,咱们认为 CK4 完全成功,然后开始下一次的CK5,那么这就是我们为了达到断点恢复或者是异常恢复所做的切换设计。
类型映射与自动建表
在数据同步的过程中我们可能经常会遇到一个问题,就是有很多目标存储要去同步的话,那首先要去把表建起来,那如果表特别多的话就比较麻烦了,就会有很大量的操作工作。
还有一个就是我们源和 source 它们是不同的存储,数据类型是完全不一样的,也需要进行统一的兼容转换,SeaTunnel则提供了类型映射和自动建表功能,以解决异构数据类型的兼容和大量表的自动创建。
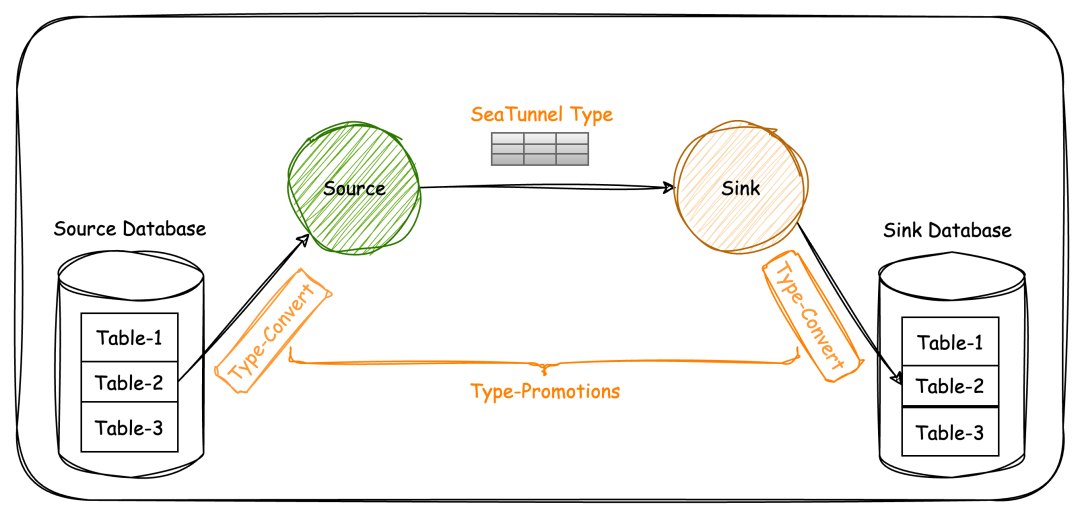
通过TypeConvert API,Source将外部系统类型导入到SeaTunnel类型,Sink将SeaTunnel类型导出到目标存储类型,实现统一的类型转换。
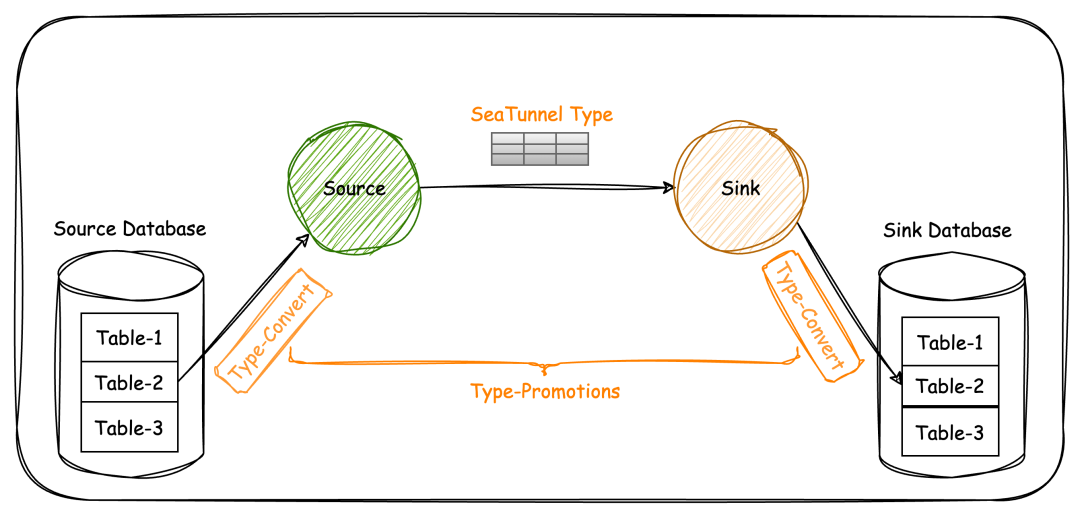
自动建表通过SchemaSaveModel和DataSaveModel定义表结构和数据处理策略。

例如,如果表已经存在,是否需要重建;如果表中已有数据,是否需要删除或执行自定义清理操作。每个连接器在其内部实现和处理这些API。
多表同步
在同步数据的过程中如果表很多的话,会对管理维护造成很大的一个困扰,对运维的负担也很大,甚至是对连接资源的消耗,如果都是独立地去做同步任务的话,那么表非常多的时候连接可能就没那么多,可能也不够用!
所以这块SeaTunnel支持在一个任务中进行多表同步,以减少管理和维护负担,并节省连接资源。
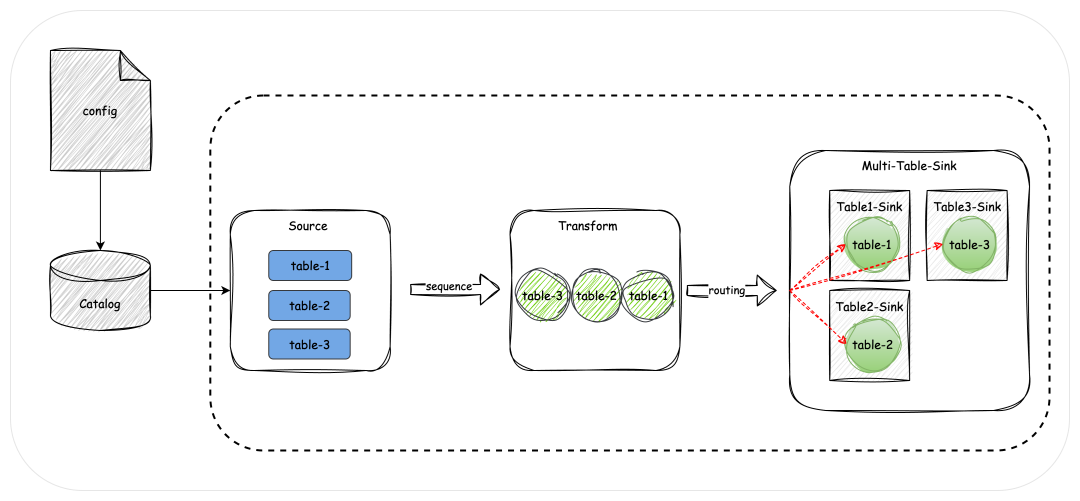
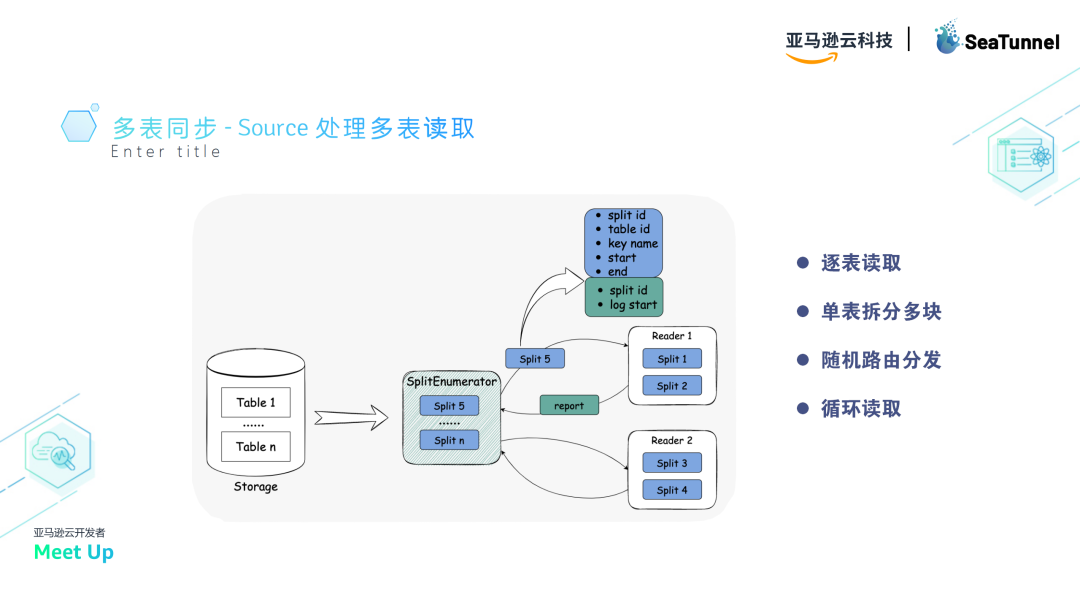
对于Source,通过枚举器(Enumerator)划分数据区块并分配给读取器(Reader),支持动态分配不同的表。
对于Sink,定义了SupportMultiTableSink接口,通过实现该接口,可以动态生成多表写入的执行计划。
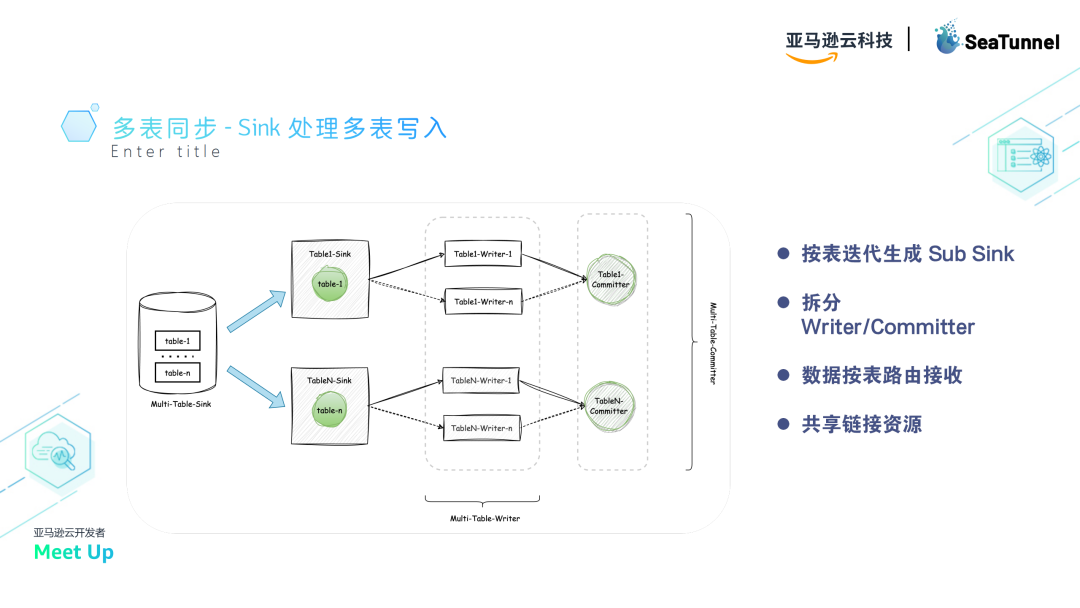
在运行时,Sink为每张表生成子Sink(Sub Sink),将其包裹在一个综合接口中,形成复杂的MultiTableSink。
这种设计不仅简化了任务管理,也优化了连接资源的使用。
共享缓存
在一些场景中,需要将一个存储中的数据写入多个存储。SeaTunnel通过共享缓存机制,避免重复读取数据。
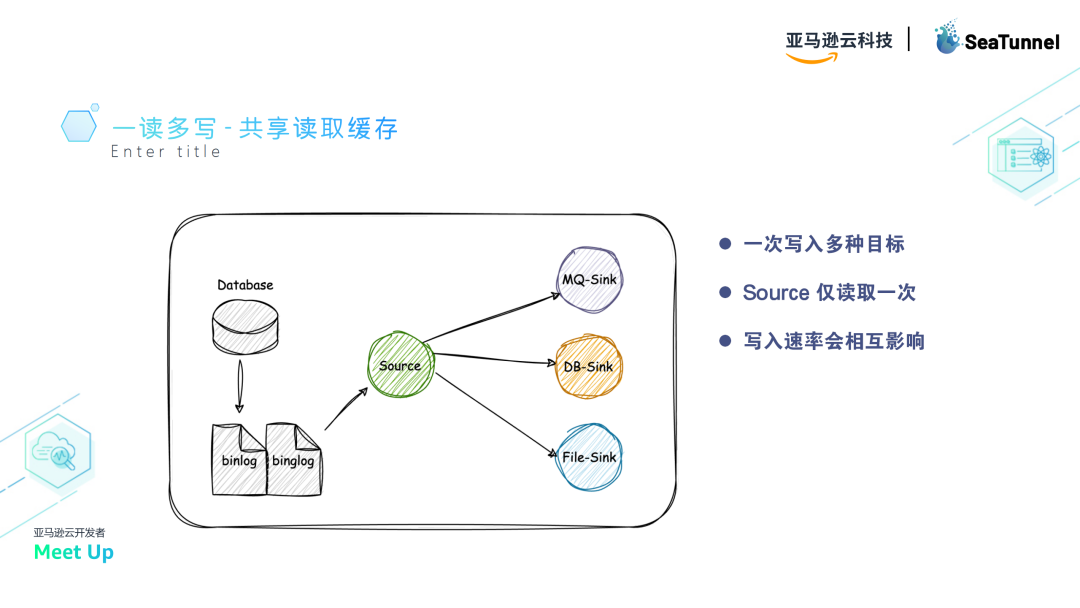
Source读取数据后放入缓存,不同的Sink可以从缓存中获取数据,减少对源端数据源的影响。
尽管共享缓存会带来写入速率的相互影响,但整体上优化了数据传输和资源使用。
CDC(Change Data Capture)设计流程
CDC(Change Data Capture)设计流程分为快照读取和增量读取两个阶段。
快照读取阶段处理已有表的历史数据,增量读取阶段通过binlog进行数据监听和读取。 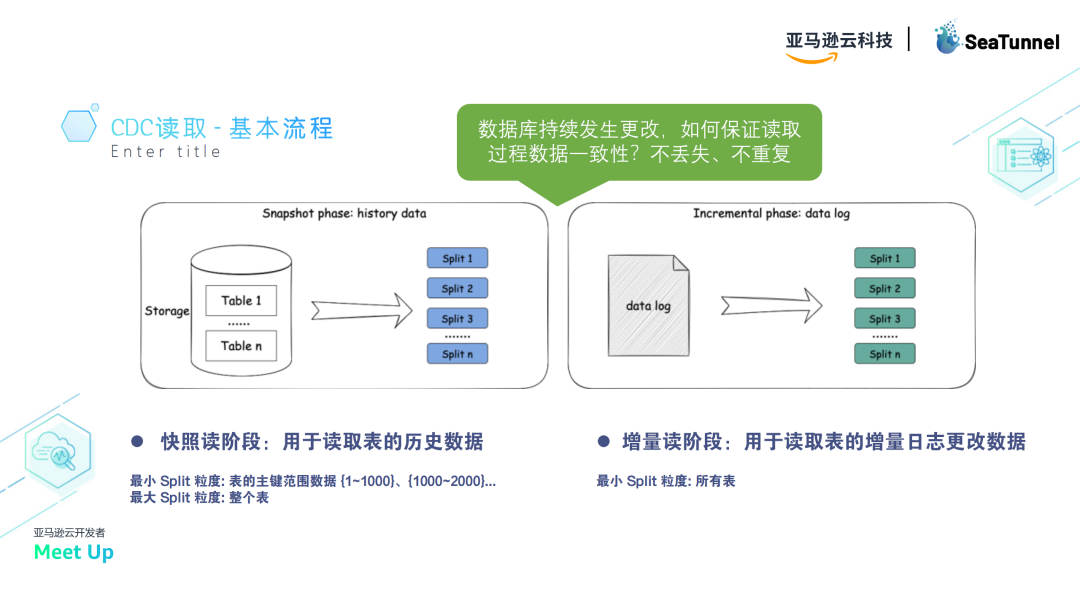
快照读取
首先,我们处理已有表的存量历史数据,这称为快照读取。在快照读取阶段,每个split(划分的最小粒度)对应一个表的一部分数据范围(从某个键到某个键)。
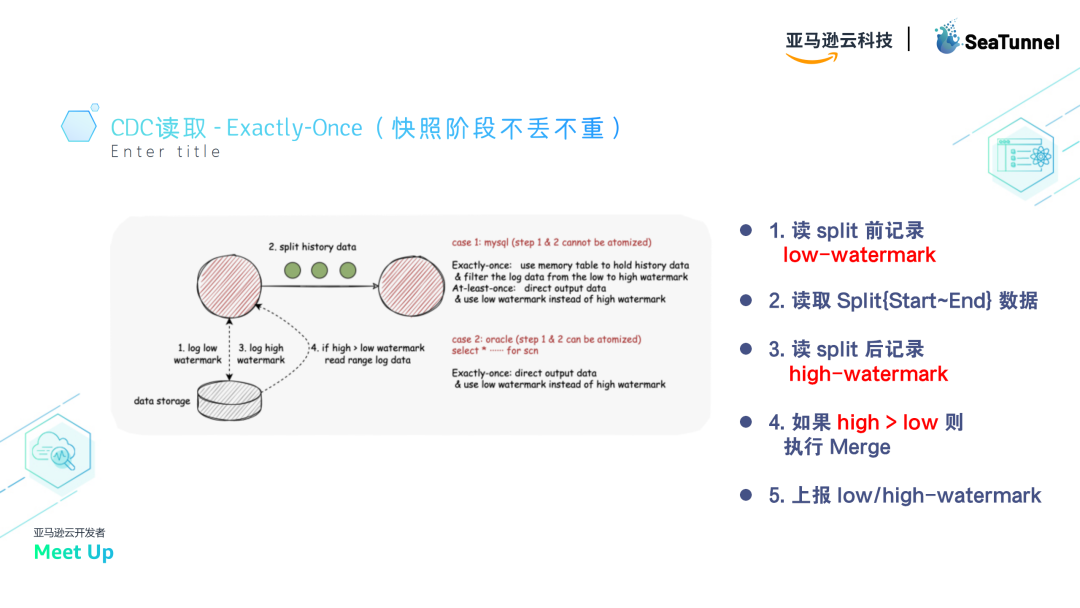
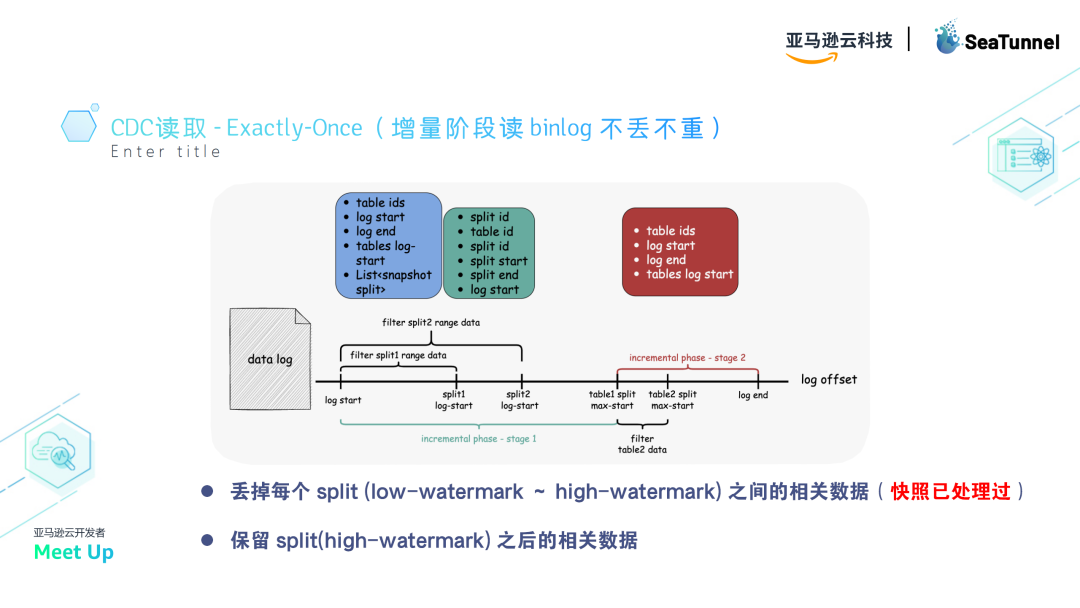
快照读取的目的是确保数据的一致性,这里有一个Exactly-Once的处理方法:
- 记录水位线:在每个split读取前后,分别记录low-watermark和high-watermark(日志上的水位线)。
- 比对水位线:读取完成后,比对水位线。如果水位线发生变化,说明数据在读取过程中被更改,需要合并数据并重读。
- 内存表处理:在读取时,先将数据放入内存表,并按键(key)索引。然后,从日志中捞取数据,并按键覆盖内存表中的数据。这样,即使数据发生变化,按键覆盖也能确保数据的一致性。如果数据被删除,内存表也会同步删除。
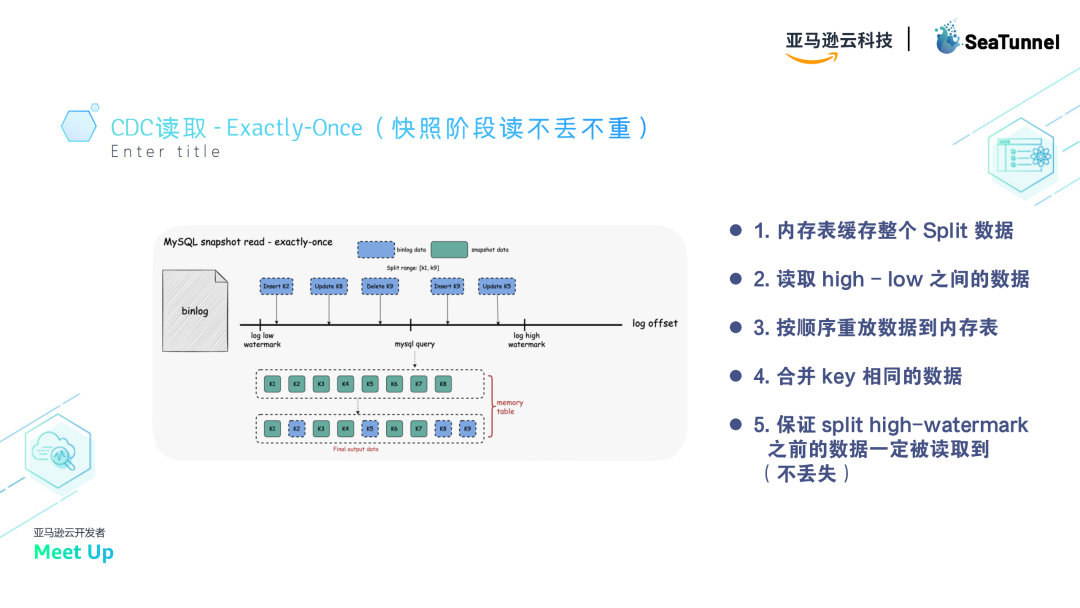
通过这种方式,快照读取阶段可以确保数据不重复、不丢失。
增量读取
在快照读取完成后,进入增量binlog读取阶段。
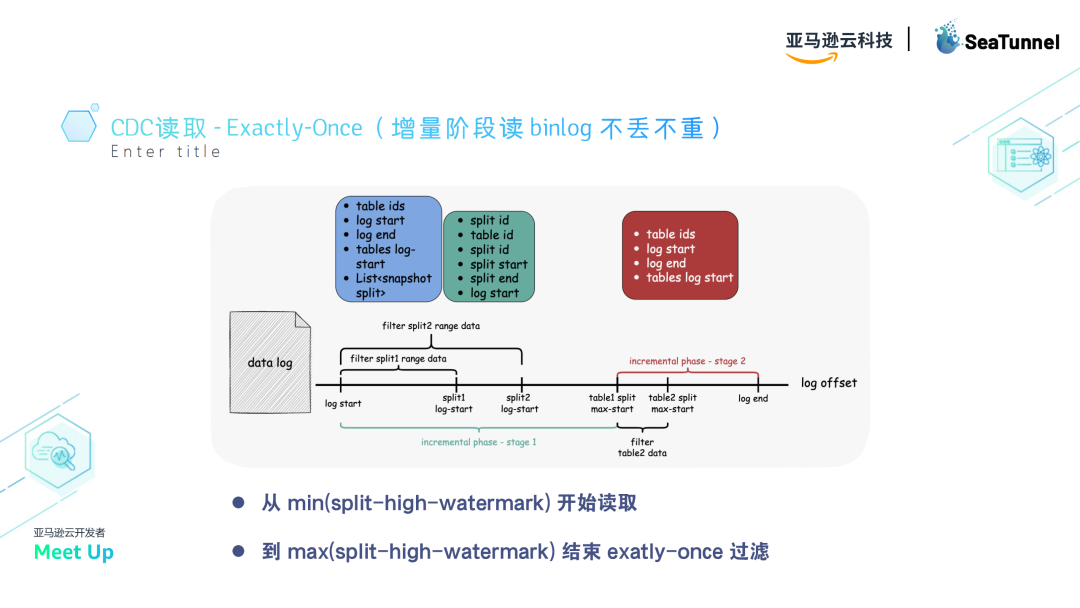
此时,处理的原则如下:
- 选择日志起点:从所有split中最小的high-watermark位置开始读取binlog。
- 过滤区间数据:过滤split与split之间的间隙数据,丢弃每个split的low-watermark和high-watermark之间的数据,保留high-watermark之后的数据。
- 确保一致性:通过过滤和回捞处理,确保增量读取的数据不重不丢。
数据一致性保证
从快照阶段到增量阶段,通过上述Exactly-Once的处理方式,可以保证数据一致性。每个阶段都通过记录和比对水位线,处理内存表,确保数据的准确性和完整性。
这种设计确保了在处理CDC读取时,即使数据在读取过程中被修改,也能通过严格的水位线管理和内存表合并,保证数据的一致性和准确性。
CDC 读取的动态加减表
在任务运行过程中,可能会需要动态地增加或减少同步的表。在传统设计中,这通常通过暂停任务、修改配置然后恢复任务来实现。
而在SeaTunnel中,这一过程与checkpoint机制密切相关。
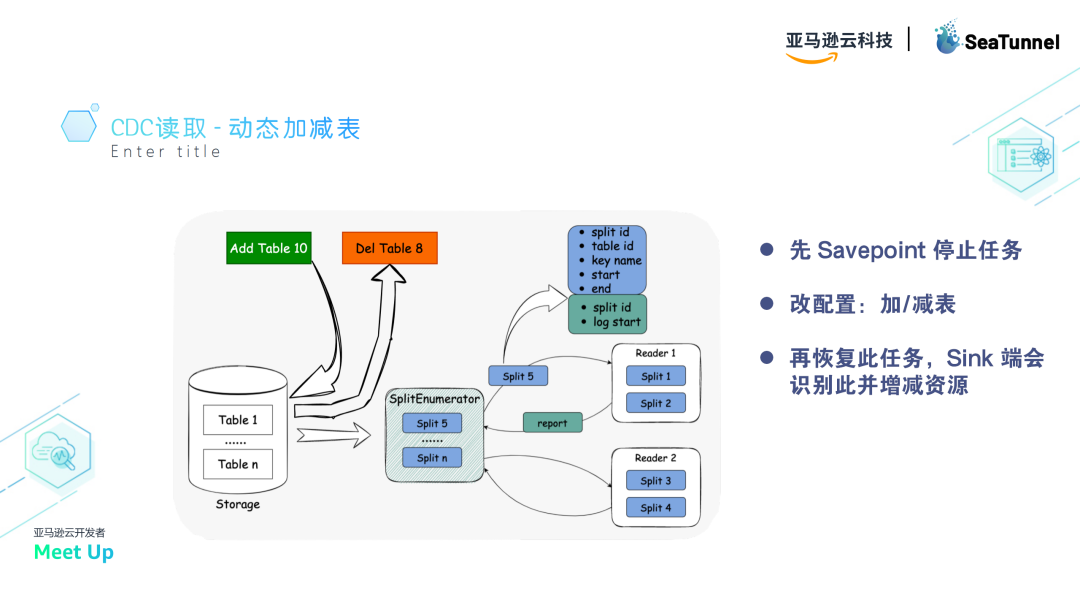
SeaTunnel会在状态切换时保存当前的任务状态,从而允许任务在特定状态下暂停并在恢复时继续执行,确保数据一致性。
CDC 写入的顺序保持
为了在并行读写过程中保持数据顺序,SeaTunnel采用了key拆分的方式。如果并行处理时同一个key的顺序被打乱,写入的数据就可能会发生错乱。
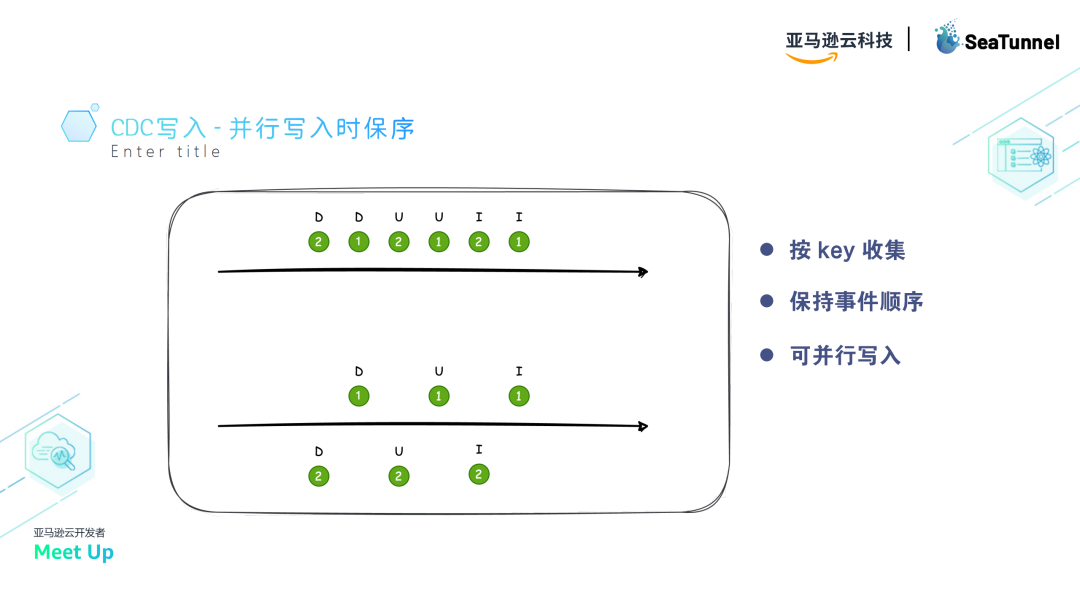
为了解决这个问题,SeaTunnel会将相同key的数据(如insert、update、delete)分配到同一写入线程中,确保这些操作按顺序执行。
例如,在日志中,i代表insert,u代表update,d代表delete。
如果一个key对应的数据依次发生了insert、update、delete操作,通过key拆分,这些操作会被分配到同一个写入线程,从而保持顺序一致性,避免数据错乱。
CDC 写入的Exactly-Once
为了实现写入的Exactly-Once语义,SeaTunnel在写入过程中也做了一些特殊处理。由于状态的暂停和恢复,可能会发生重读或重放某个checkpoint的数据。 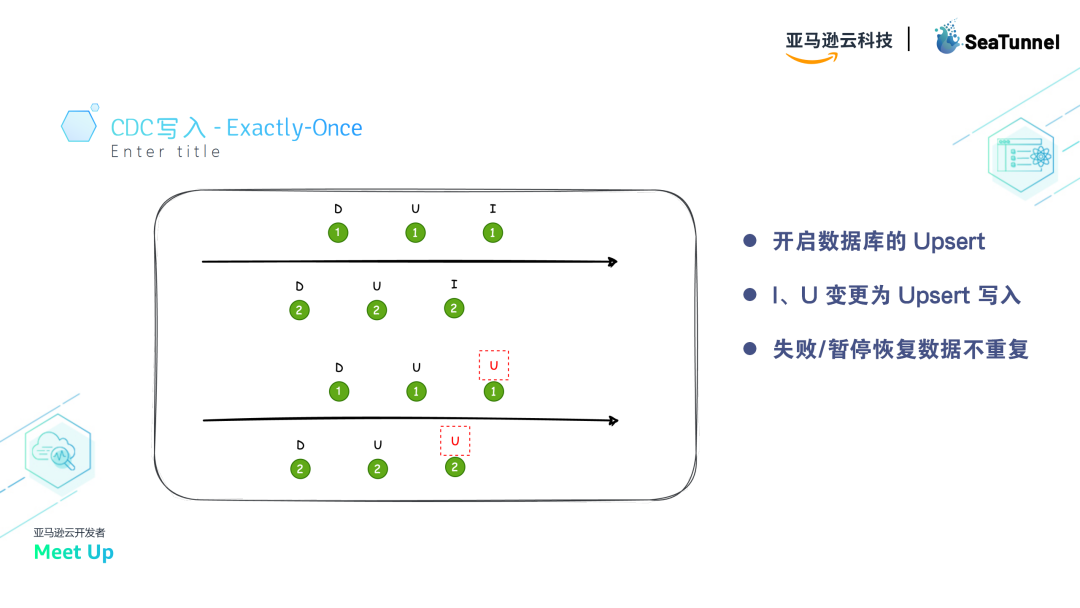
这时,Sink可以通过支持upsert操作来处理重复数据。具体来说,如果数据库支持upsert写入,那么insert和update操作都将被处理为upsert,确保数据的一致性。
CDC 资源优化
在CDC读取过程中,资源优化是一个重要的考虑因素。通常情况下,CDC读取会先读取历史数据,然后再读取增量的binlog数据。
历史数据量可能非常大,需要较多的并行读取线程;而binlog数据量相对较少,不需要那么多的读取线程。
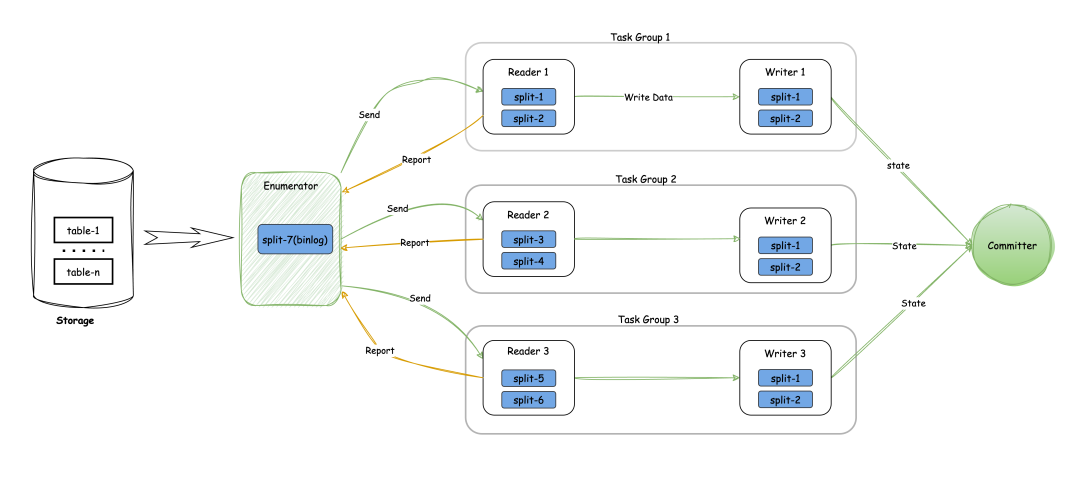
为了有效地管理资源,SeaTunnel引入了idle状态的概念。
以下是具体的处理方式:
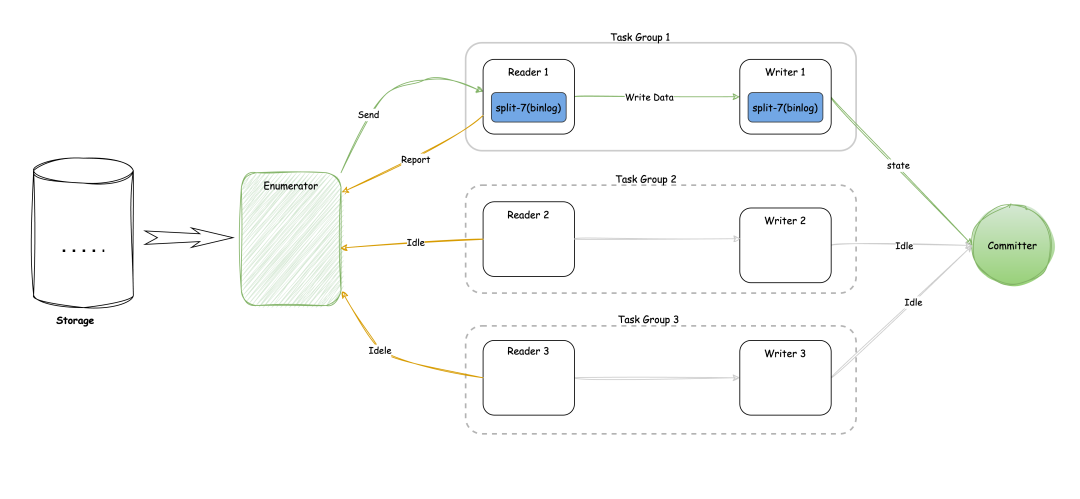
读取历史数据:在读取历史数据阶段,需要较多的并行读取线程以提高处理速度。
进入binlog阶段:一旦开始读取binlog数据,数据量通常较少,只需要一个并行任务去读取binlog数据。
报告idle状态:当某些读取线程处于空闲状态时,这些线程会向枚举器报告idle状态。
动态调整线程:枚举器接收到idle状态报告后,会动态地关掉所有处于idle状态的task group,只保留一个读取线程继续处理binlog数据。
释放资源:被关闭的task group会释放其占用的数据库连接资源,从而减少资源占用。
最佳实践
env 配置
并行线程 (parallelism)
- parallelism 表示任务并行线程的数量,即创建多少对 reader 和 writer 的组合。例如,设置 parallelism 为3,就会有三对reader和writer并行读写。
- 需要注意,并不是所有连接器插件都支持并行处理。在配置之前,要确保所使用的连接器支持该功能。
- 确认连接器是否支持数据切分。如果连接器的枚举器不支持数据切分,例如某些文件连接器,那么无论并行线程设置多少,其他线程都会空闲。例如,一个文件只能在一个线程中处理,其他线程则会处于空状态。
checkpoint.interval
- checkpoint.interval 主要用于流任务。对于批任务,该设置默认关闭。如果要配置流任务的 checkpoint.interval,建议不要设置得过短,以免影响数据读写同步的效率。
- 某些Sink插件在写数据时,会与checkpoint挂钩。checkpoint触发时,可能会刷新内存中的缓存数据。如果出现数据延迟,可能与 checkpoint.interval 的设置有关。
- 常见的触发错误是 CheckpointCoordinator inside have error,通常表明在checkpoint执行时,writer或committer在将数据写入目标库时失败或超时。可以通过调整checkpoint执行的超时时间来解决此问题。
Source 分片注意事项
Source任务配置中的分片是提高并行读写效率的关键。要确保Source支持分片,并了解其配置方法。
不同的连接器有不同的分片方式,配置分片键的类型、大小和数量也会影响读取效率。
此外,数据的分布情况也会导致倾斜问题,需要根据具体场景进行优化。
Sink 的多表配置
用户反馈比较多的一个问题是多表配置。
目前,多表配置在文档上还有一些未完善的地方。Source的表到Sink是迭代的,Sink可以通过变量提取动态分配表信息,如${database_name}、${table_name}等。变量可以组合使用,添加前后缀,例如${database_name}_xyz、${table_name}_abc等。
像Paimon、Iceberg、Doris 、Starrocks 、Hive 等连接器都可以通过这种方式提取多表信息进行写入,具体配置方式根据场景和数据库有所不同。
以下是一些代码示例:






参与社区共建
欢迎大家参与SeaTunnel社区的共建。我们需要大家一起来共同维护和丰富我们的连接器生态。可以通过官网的DOWNLOAD链接选择合适的版本进行试用。
在试用过程中,如果发现问题,可以在GitHub Issue上反馈。如果想参与新功能的开发或Bug修复,也可以在Issue中找到需要帮助的问题。
参与贡献:https://github.com/apache/seatunnel/issues?q=is:open+is:issue+label:"help+wanted"
平时的交流和寻求帮助,可以通过邮件列表或者关注社区公众号。感谢大家的支持和参与!
本文由 白鲸开源科技 提供发布支持!
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











