







目录
Microsoft Azure Public Datasets
UCI Machine Learning Repository
Awesome Public Datasets on Github
机器学习中最重要的是数据集。哪里可以找到最好的机器学习数据集?我把我10年来压箱底的东西都拿出来了,不看绝对后悔!!!
在机器学习的过程中,优秀的数据集能够帮助我们应用不同的算法模型,从而让我们快速成长。但在自学机器学习的过程中,由于生活中很难找到标准的测试数据集,学习者往往很难保持长久的积极性,从而影响学习进度。
但是这些又不能阻碍我们学习进步,那怎么办?
今天给大家推荐3种解决方式:
- 从身边获取有效的数据进行机器学习或数据分析。
- 白嫖免费的公共资源。
- 付费数据集,比如价格不菲的医疗影像数据。
先给大家看看我的主页,里面有我日常在数据分析机器教学中使用过的导航网站。

普通人身边的机器学习数据
其实在我们日常生活和工作中,无时不刻不在产生数据,但我们往往都忽略了它,有很多平台利用这一点薅了我们的羊毛。对于我们个人来说,采集这些信息去进行机器建模学习效果并不是很好,所以我们还需要借助更广阔的互联网资源。
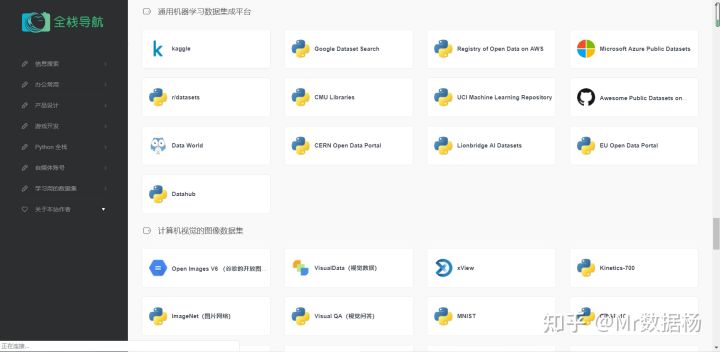
优秀的通用机器学习数据集成平台
数据集聚合平台收集了数千个数据集合。国内有很多这种平台,比如 阿里天池、DC竞赛、DF竞赛等等,但是这些平台对新手不是很友好,一方面是因为专业性比较强(很多新手不懂业务逻辑,没有办法做数据预处理 很多业务逻辑都不懂根本没法做数据预处理),另一方面是因为个人感觉这些平台在用一些低廉的奖金来骗方案、模型以及业务逻辑,这部分就不多解释了。
对于初学者来说掌握科学上网是必备的,因为机器学习的内容最早都来源于欧美,对于这些内容的理解、对数据的应用相较于国内更成熟,同样国内很多论文也是在国外内容的基础上衍生出来的。
同时还要知道的是,对数据要求比较严格的是数据标注,但国内暂时还没有一个平台能够完整提供这些领域的内容,而且还有很多山寨的是聚合数据平台,因为太多了就不一一列举了。这些平台基本上从国外网站、或者各种同行之间互相搬,没有实际意义,而且有很多数据是残缺的,完全就是在收智商税。既然我们要学习,那不如直接找到国外的原始根源数据集进行练手,避免被收智商税。
而且你会发现很多很多在线的机器学习相关课程的数据集都不会脱离下面这些平台。
整理不易,建议点赞收藏。
PS:如果打不开的话需要科学上网哟
既然要做这块那我们不如直接找到国外的原始根源数据集进行练手,避免被收智商税。
整理不容易,请收藏。所有网站打不开的都需要科学上网。
kaggle
Kaggle: Your Machine Learning and Data Science Community 是一个社区驱动的机器学习平台,每天都有无数爱好者在平台更新,是截至目前更新最频繁的数据聚合集成平台。是一个共有工具和资源的数学科学社区,其中包括了各种外部贡献的机器学习数据集,从健康到运动,再到食物、旅行、教育等等。
对于我们而言,平台内有大量教程科学系,覆盖了数百个不同的现实ML问题。虽然说数据质量参差不齐,但是所有数据都是免费的,而且还可以上传自己数据集。
整体来看,kaggle训练数据的最佳场所之一,同时也是是拥有最大的在线数据集库之一。

Google Dataset Search
Google Dataset Search 谷歌数据集搜索来自Google 的搜索引擎,拥有超过2500万个数据集,工作原理类似于Google Scholar。可以帮助我们查找免费提供的在线数据,在这里能够找到经济、金融数据,还有由WHO、Statista或哈佛等组织上传的数据集。

Registry of Open Data on AWS
可以借助 Registry of Open Data on AWS 来自于亚马逊,使用时可根据需求找到的数据进行研究。在数据库创建者中会发现 Facebook Data for Good、NASA Space Act Agreement 和 Space Telescope Science Institute。

Microsoft Azure Public Datasets
Public data sets for Azure analytics - Azure SQL公共数据集为应用程序开发人员和研究人员定期更新数据库。包含 Microsoft 收集的有关其用户的美国政府数据、其他统计和科学数据以及在线服务信息。此外 Azure 提供了一系列工具,可帮助创建自己的云数据库,将 SQL 工作负载迁移到 Azure,同时保持完整的 SQL Server 兼容性,以及构建数据驱动的移动和 Web 应用程序。

r/datasets
r/datasets 是一个集分享、查找和讨论数据集的社区,有点像带有专业属性类型的论坛。在这里所有人都可以发布自己的开源数据库,有的时候还能得到意想不到的数据集,可以用它尝试去做一些模型来学习。
CMU Libraries
Databases A-Z 是卡耐基梅隆大学自有的公共数据集集合,提供了很多其他聚合器没有的美国文化、音乐、历史方面的数据库,学习者可以将其用于自己的研究。

UCI Machine Learning Repository
UCI Machine Learning Repository 可以说这个平台以一己之力养活了国内许多山寨平台,国内有很多山寨数据聚合平台都是从这个平台搬运内容。这个平台提供了507个数据集,包括了银行营销、汽车评估、肺癌诊断等主题。
除了一些山寨数据平台,还有很多开发机器学习课程的数据也是从这里搬走的,比如传说中的波士顿房价预测。
Awesome Public Datasets on Github
Awesome Public Datasets on Github 相对小众,其实它是一个非常好的开源合集,里面有按行业划分的在线可用的最佳数据集,有很多人都不知道这个数据集,因为在git上只知道搬运代码。
Data World
Data World 与 Google 数据集搜索引擎非常相似,但是知道的人没那么多,很少被提到。这个数据平台的特点是,不同于其他平台,Data World除了能够显示数据集本身的内容以外,还显示包含数据的子文件数据,这个功能在查询人口统计或是地理位置信息上的优势就非常明显了。
CERN Open Data Portal
CERN Open Data Portal 是日内瓦的欧洲核研究组织的开放数据门户。欧洲核研究组织是欧洲最负盛名的研究机构之一,他们的粒子碰撞数据在全球无人能及。同样,他们的开放数据门口也非常吸引人,收集并提供了超过 2 PB 的包含(粒子物理学)的数据,但对我们普通人来说,或许用不到这些内容。

Lionbridge AI Datasets
Lionbridge AI Datasets 是一家提供数据收集、注释和验证服务的公司。这个平台的数据集很全面,除了自定义标签环境外,我们日常感兴趣的各种数据集都能找到。

EU Open Data Portal
data.europa.eu 是欧盟机构和其他实体发布的公共数据的访问点,包括了与经济、农业、教育、就业、气候、金融、科学等相关的数据。整体而言类型很多,但是其数据均来源于欧盟。

Datahub
Datahub 是 Datopian 和 Open Knowledge International 的一个项目,其目的是为数据创建工具和应用程序。构建的 CKAN 是世界领先的数据门户平台。是一个发现和分享高质量数据集、与他人联系和分享知识的社区。

那么以上差不多就是冷门热门,比较齐全的数据集了,毕竟名气大,用途广的也就那么几个;而且做数据分析久了以后会发现很多数据都是相同或是有相似地方的。
接下来按照不同类别说明一些优秀的垂直领域的数据集。
机器学习和数据科学的最佳公共数据集
计算机视觉的图像数据集(20)
现在有很多机器学习的项目理念和实验室研究项目正是基于训练视觉数据的。计算机视觉能够将图像或视频数据集用于图像采集、图像分类、图像分析和语义分割等,对此进行一系列计算视觉任务,在医学成像、汽车自动驾驶、面部识别等领域都有运用。
只有大量且高质量的训练数据,才能为计算机视觉构建强大的机器学习、深度学习模型。
1.Open Images V6 (谷歌的开放图像数据集)
Open Images V6 储存量非常多,已经超过了900万,包括了对象边界框、对象分割和标签。它非常多样化,不仅包含复杂样本,并且每张图像还包括多个对象。
2.VisualData(视觉数据)
VisualData 是计算机视觉数据集的聚合器,学习者可以在其中找到用于机器学习的医学数据集、图像数据集和其他用于商业、教育和其他类型 ML 研究的机器学习数据样本。
3.xView
xView 是最大的公开可用的高空图像存储之一,其中一个庞大的高空图像公共数据集包含超过 100 万张对象图像,其中包含来自世界各地复杂场景的 60 个类别,并使用边界框进行注释。
4.Kinetics-700
Kinetics 内包含高质量的大规模深度学习数据集,包括了人与对象和人与人交互的视频剪辑,非常适合训练人类动作识别模型。一个大型、高质量的 URL 视频数据集,会链接到大约 650000 个 Youtube 视频剪辑,涵盖 700 个人类行为类别。这些视频包括人与物体的互动,以及人与人的互动。
5.ImageNet(图片网络)
ImageNet 是计算机视觉中最受欢迎和最大的数据集之一,是根据 WordNet 层次结构组织的,主要用于深度计算机视觉的图像。它目前在 1000 个类别中拥有 1281167 张用于训练的图像和 50000 张用于验证的图像。
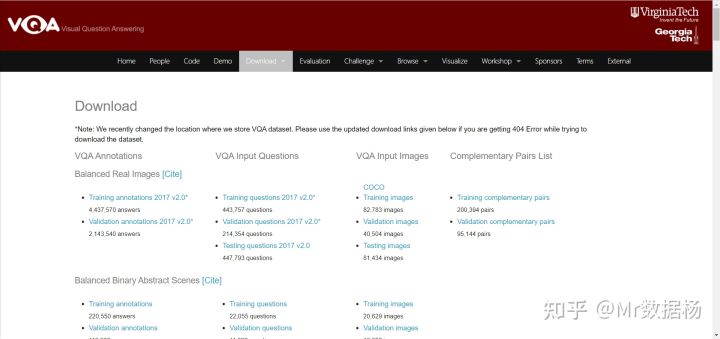
6.Visual QA(视觉问答)
Visual QA 包含关于超过 265016 张图像的开放式问题,可用于更好地理解计算机视觉建模和语言处理。一个包含关于图像的开放式问题的新数据集包括 265016 张图像,每张图像至少三个问题,每个问题十个答案。
7.MNIST
MNIST 数据库是手写数字识别的样本集合,其中有一个包含 60000 多个示例的训练集以及一个 10000 个的测试集,它也是最早我们进行机器学习入门常用的一个数据集。在网站上还将找到一个表格,该表格比较了应用于该数据集的不同类型分类器的有效性,对于初学者非常友好。

8.CIFAR-10
CIFAR-10 是用于训练深度学习计算机视觉算法的图像集合。该数据库由 10 类 60000 张 32x32 彩色图像组成,每类有 6000 张图像。

9.COCO
COCO 是一个定期更新的数据库,用于在上下文中进行对象分割和识别,由 Microsoft、Facebook 和 Mighty AI 赞助。大规模对象检测、分割、关键点检测和字幕开源数据集,包含超过 200,000 个标记图像。

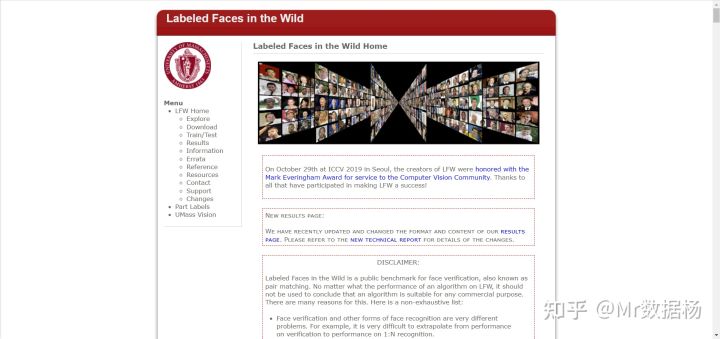
10.Labeled Faces in the Wild(标记的面孔)
Labeled Faces in the Wild 是用于训练和测试人脸识别模型的数据集。一个包含 13000 张面部照片的高质量数据库,专为开发面部识别项目而设计,每张脸都标有图中人物的名字。
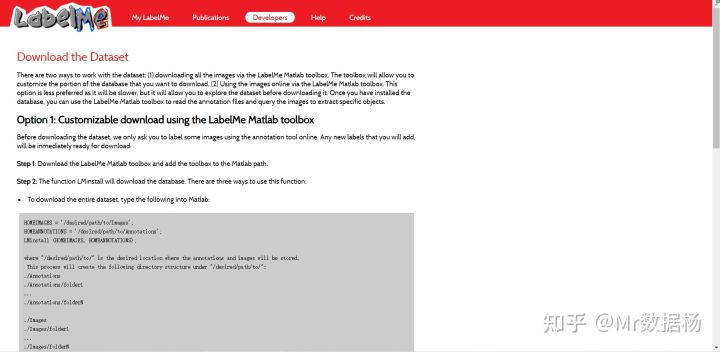
11.Labelme
Labelme 由 MIT 计算机科学与人工智能实验室 (CSAIL) 创建的广泛数据集。包含 187240 个图像、62197 个带注释的图像和 658992 个标记的对象。
12.LSUN
LSUN ,包含 10 个场景类别(例如教堂、餐厅等)和 20 个对象类别(例如鸟、飞机等)中的每一个的大约一百万个标记图像。旨在为大规模场景分类和理解提供不同的基准。

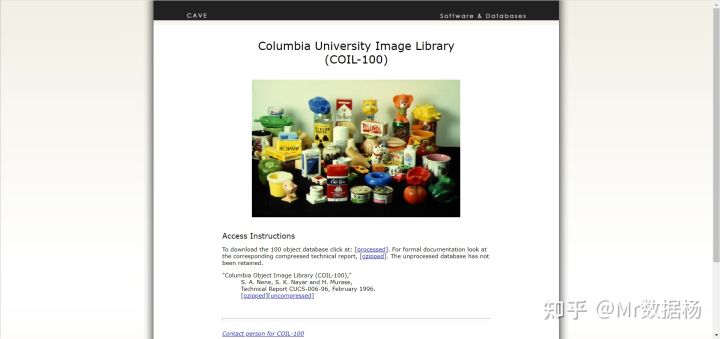
13.COIL100
COIL100 包含 100 个对象的 7200 个彩色图像(每个对象 72 个图像)的数据集,以 360 度旋转的每个角度成像。由哥伦比亚大学智能系统研究中心收集。
14.Visual Genome(视觉基因组)
Visual Genome 一个庞大而详细的数据集和知识库,带有超过 100000 张图像的字幕。
15.Google’s Open Images(谷歌开放图像)
Google’s Open Images 是一个由超过 900 万张带有丰富注释的不同图像的集合。包含 6000 个类别的图像级标签注释、对象边界框、对象分割和视觉关系。这个大型图像数据库是很多数据科学项目的重要数据来源。
16.Indoor Scene Recognition(室内场景识别)
Indoor Scene Recognition 是一个识别包含 7 个室内类别的 5620 张图像的数据库。每个类别至少有 100 张 jpg 格式的图像。

17.CelebFaces(名人面孔)
CelebFaces 超过 20 万张名人图像的大规模数据集。每个图像包含 40 个属性注释。这些图像涵盖了一系列姿势变化和杂乱的。

18.Stanford Dogs Dataset(斯坦福犬数据集)
Stanford Dogs Dataset,是一个包括了自世界各地的 120 种狗的图像的数据集。它包含 120 个类别的 20580 张图像,通过类标签和边界框进行注释。想要对狗狗有研究的千万不要错过!!!
19.Places
Places 是麻省理工学院计算机科学与人工智能实验室提供的数据集。在205 个场景类别中有超过 250 万张图像。每张图片都带有一个类别标签。学习者可以使用它来训练深度神经网络以理解各种场景。
20.Cityscapes Dataset(城市景观数据集)
Cityscapes Dataset 一个大规模数据集,包含在来自 50 个不同城市的街景中记录的各种立体视频序列。它带有 5000 帧的像素级注释和一组 20000 个弱注释帧,可用于语义分割和训练深度神经网络以了解城市场景。

自然语言处理数据集(17)
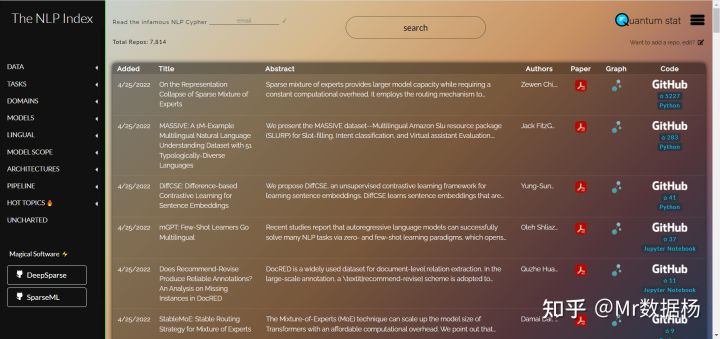
1.The NLP Index(NLP 指数)
The NLP Index 是一个用于 NLP 相关任务的 841 个数据集的集合,包括文档分类、自动图像字幕、对话、聚类、意图分类、语言建模或机器翻译。
2.Enron Email Dataset(安然电子邮件数据集)
Enron Email Dataset 是由 CALO 项目(学习和组织的认知助手)收集和准备的数据集。包括了由安然公司 158 名员工生成的超过 600000 封电子邮件。

3.Google Books Ngram Viewer(Google 图书 Ngram 查看器)
Google Books Ngram Viewer 有从 Google 图书语料库中提取的大量单词。“n”指定元组中元素的对应的单词或字符数量。

4.The Wikipedia Corpus(维基百科语料库)
The Wikipedia Corpus 是一个庞大的数据集,包含超过 400 万篇文章的 19 亿字的数据集。使用时可以按单词、短语、词性、同义词、术语比较等进行搜索。此外可以从语料库中的 4400000 篇文章中的任何一篇中创建和使用特定主题的虚拟语料库。

5.SMS Spam Collection in English(英文垃圾短信收集)
SMS Spam Collection in English 是一个小型数据集,包含 5574 条带有 SMS 标记的消息(英文),用于手机垃圾邮件研究,能够被标记为合法或垃圾邮件。

6.Multidomain Sentiment Analysis Dataset(多域情感分析数据集)
Multidomain Sentiment Analysis Dataset 是一个比较旧的数据集,包含了来自亚马逊的正面和负面产品评论。评论包含从 1 到 5 星的评级。

7.Stanford Sentiment Treebank(斯坦福情绪树库)
Stanford Sentiment Treebank 以烂番茄评论为基础,是一个带有情感注释的大型电影评论数据集。它包含 10000 多条数据。这个标准情绪数据集的原始代码由 Matlab 编写。

Sentiment140,包含使用 Twitter API 提取的 160 万条推文的数据集(最初它不是开源的,但现在可以在 Kaggle 上免费获得)。推文已经过注释(0 = 负面,2 = 中性,4 = 正面),可用于检测情绪。此 Twitter 数据以 CSV 格式提供,已删除表情符号。反正这种东西微信、微博估计打死也不会公布这些内容。

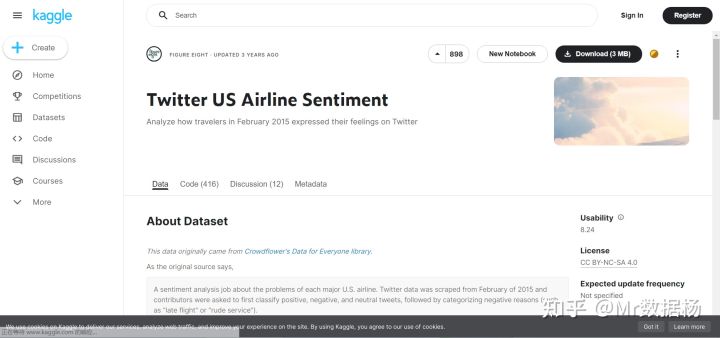
9.Twitter US Airline Sentiment(Twitter 美国航空公司情感)
Twitter US Airline Sentiment 包含自 2015 年 2 月以来关于美国各大航空公司的推文的数据集。推文分为正面、负面或中性。它包括 Twitter ID、情绪信心评分、负面原因、航空公司名称、转发计数等功能。
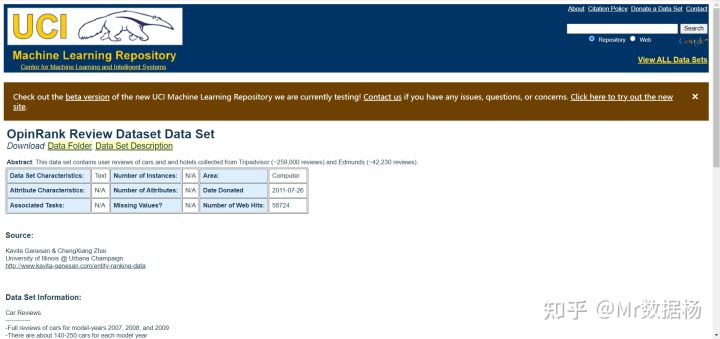
10.OpinRank Review Dataset(OpinRank 审查数据集)
OpinRank Review Dataset 从 Tripadvisor 和 Edmunds 收集的大量关于汽车和酒店的评论。有近 260000 条酒店评论和 42230 条汽车评论。
11.Amazon Review Data (2018)(亚马逊评论数据 (2018))
Amazon Review Data (2018) 2014 年亚马逊评论数据集的更新版本。它包含 1996 年 5 月至 2018 年 10 月期间收集的 2.331 亿条评论。其他功能包括产品元数据(描述、类别信息、价格、品牌和图像特征)和链接(也查看/还买了图表)。

12.Sentiment Lexicons for 81 Languages(81 种语言的情感词典)
Sentiment Lexicons for 81 Languages 在 Kaggle 上发布的数据集。包含 81 种语言的正面和负面情绪词典。情感是基于英语情感词典构建的。

该数据集通常用于机器学习技术的文本应用实验,例如文本分类和文本聚类。
13.Legal Case Reports Dataset(法律案例报告数据集)
Legal Case Reports Dataset 一个小型数据集,包含 4000 个法律案例的文本摘要,可以从 UCI 机器学习存储库下载。用于训练自动文本摘要的极好数据源。

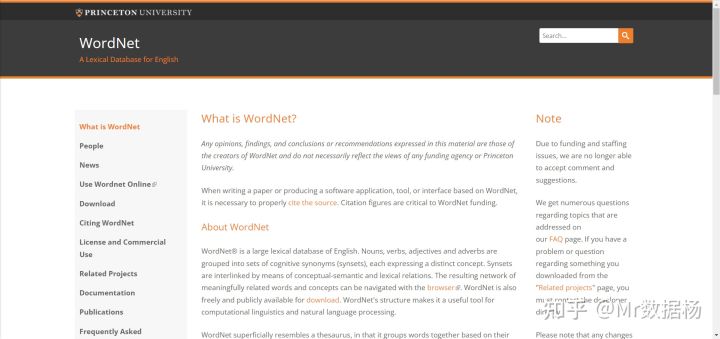
14.WordNet
WordNet 是一个词汇数据库,包含分组为同义词集的所有词性。这种结构使其成为自然语言处理和语言研究的绝佳工具。
15.20 Newsgroups(20 个新闻组)
20 Newsgroups 来自 20 多个不同新闻组的 20,000 份文档的集合。内容涵盖了各种主题,其中一些密切相关,以供参考。提供三个版本:原始版本、按日期排序和删除重复版本。 是一个数据集,包含来自 20 个不同新闻组的 18000 多个文本文档,包括体育、技术、艺术、娱乐等。
16.IMDB Movie Reviews Dataset(IMDB 电影评论数据集)
IMDB Movie Reviews Dataset 来自 IMDB 的 50000 条电影评论的庞大集合(原始和预处理的电影评论,用于通过深度学习进行情感分析)。包含 25000 条高度两极分化的电影评论用于训练和 25000 条用于测试。负面评论得分低于 4 分(满分 10 分),正面评论得分超过 7 分(满分 10 分)。
17.Yelp Reviews(Yelp 评论)
Yelp Reviews 是一个开放数据集,包含超过 860 万条评论和 20 万张图片,可用于个人和学术目的的用户评论、商业信息和图像。还包含超过 120 万个业务属性,例如营业时间、停车位、可用性和氛围。

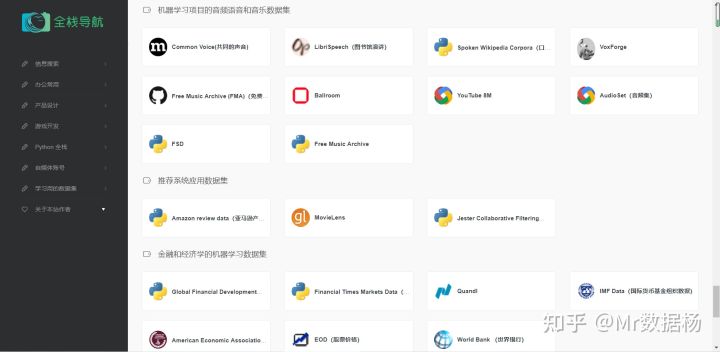
音频语音和音乐数据集(10)
1.Common Voice(共同的声音)
Common Voice 用于训练语音技术的高质量开源和多语言语音数据集。该项目由志愿者领导,使用麦克风录制示例句子并查看其他用户的录音。
2.LibriSpeech(图书馆演讲)
LibriSpeech 来自有声读物的大约 1000 小时阅读英语语音的高质量数据集。所有音频数据都经过仔细分割和对齐。

3.Spoken Wikipedia Corpora(口语维基百科语料库)
Spoken Wikipedia Corpora 口语维基百科语料库,包括来自英语、德语和荷兰语维基百科的数百篇文章。该数据源的优势归结为多样化的读者和主题。

4.VoxForge
VoxForge 一个开放的语音数据集,用于收集英语、德语、意大利语、葡萄牙语或西班牙语等语言的转录语音。
5.Free Music Archive (FMA)(免费音乐档案 (FMA))
Free Music Archive (FMA) 用于音乐分析的数据集。包含完整长度和 HQ 音频、预先计算的功能以及轨道和用户级元数据。音频数据来自 16341 位艺术家的 106574 首曲目和 14854 张专辑,按 161 种流派的分级分类排列。
6.Ballroom
Ballroom 包含交际舞信息的音乐数据集(在线课程等)。许多舞蹈风格的一些特色摘录以真实音频格式提供。实例总数为 698,持续时间约为 30 秒。

7.YouTube 8M
YouTube 8M 拥有超过 600 万个视频、经过人工验证的标签以及大约 26 亿个音频和视频功能。
8.AudioSet(音频集)
AudioSet 具有手动注释音频事件的丰富数据集。它包含 632 个音频事件类和从 YouTube 视频中提取的 2,084,320 个人工标记的 10 秒声音片段的集合。
9.FSD
FSD 包含大量的声音样本,从人类和动物的声音到音乐和机械噪音。

10.Free Music Archive
Free Music Archive 是用于音乐分析的数据集。

推荐系统应用数据集(3)
1.Amazon review data(亚马逊产品数据)
Amazon review data 包含在亚马逊上销售的数百万件商品的元数据和评论。对于任何对推荐系统感兴趣的人来说,这个绝对比你用爬虫去抓淘宝、京东、拼多多这些平台数据要好用的多。

2.MovieLens
MovieLens 是一个为用户提供个性化电影推荐的网站,还有一个开源数据集可以使用它来训练的模型。

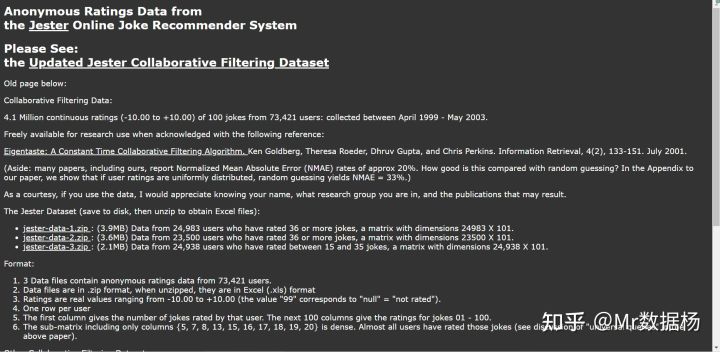
3.Jester Collaborative Filtering Dataset (Jester 协同过滤数据集)
Jester Collaborative Filtering Dataset 拥有来自 7W+ 名用户的百个笑话的超过 400 万个评分。
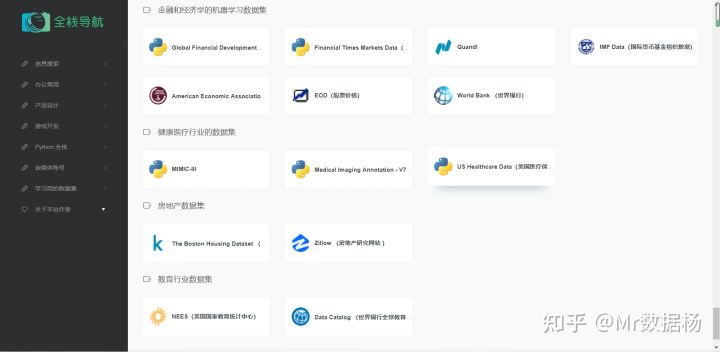
金融和经济学的机器学习数据集(7)
收集的大量财务记录可以使用易于访问的丰富公共数据集来训练模型。机器学习已广泛用于算法交易、股市预测、投资组合管理和欺诈检测,这已经不是什么秘密了.此外多年来深度学习的发展使测试经济模型、更轻松地收集新数据源以及预测行为以帮助制定政策。
1.Global Financial Development (GFD)(全球金融发展 (GFD))
Global Financial Development (GFD) 涵盖全球 214 个经济体的金融系统特征的广泛数据集。包含自 1960 年以来收集的年度数据。

2.Financial Times Markets Data(金融时报市场数据)
Financial Times Markets Data 包含来自世界各地的金融市场的最新数据源,该数据集包含有关股票和股票价格、股票、货币、债券和商品表现的信息。
3.Quandl
Quandl 是一个拥有丰富的金融、经济和替代数据数据集的平台。数据有两种格式:时间序列(一段时间内的数据)和表格(数字和未排序的数据类型,如字符串等)。
4.IMF Data(国际货币基金组织数据)
IMF Data 是国际货币基金组织发布与国际货币基金组织贷款、汇率以及其他经济和金融指标相关的数据。
5.American Economic Association (AEA)(美国经济协会 (AEA))
American Economic Association (AEA) 一个链接到一些最有用和最流行的经济数据源的网站,包括美国宏观经济数据以及个人层面的全球收入、就业和健康数据。

6.EOD(股票价格)
股票市场,量化交易数据起源于 EOD 股票价格 存储有关美国股票当日股票价格、股息和拆分的历史数据。
7.World Bank (世界银行)
World Bank Open Data 无需注册即可访问的来自世界银行的开放数据。包含有关人口统计数据、宏观经济数据和关键发展指标的数据。进行大规模数据分析的重要数据来源。最重要的是支持中文!支持中文!支持中文!

健康医疗行业的数据集(3)
1.MIMIC-III
MIMIC-III 是一个开源匿名数据集,包含 40,000 多名重症监护患者的健康数据。涵盖的参数包括人口统计、生命体征、实验室测试和药物摄入量,这种类型的东西在国内太难找了。

2.Medical Imaging Annotation - V7 Darwin
Medical Imaging Annotation - V7 Darwin 是放射科医生每天都对医学图像进行注释(或标记)。这可以在 DICOM 查看器中完成,其中包含基本注释功能,例如边界框、箭头,有时还包含多边形。机器学习 (ML) 有时可能会利用这些标签,但它们的格式通常与 ML 研究的需求不一致,例如缺少实例 ID、属性、标签队列或 Pytorch 或 TensorFlow 等深度学习框架的正确格式。

3.US Healthcare Data(美国医疗保健数据)
卫生保健和公共卫生的统计数据和数据集。可以找到从 FDA 和 USDA 食品成分数据库收集的有关人口健康、疾病、药物和健康计划的数据。
房地产数据集(2)
1.The Boston Housing Dataset (波士顿住房数据集)
The Boston Housing Dataset 老掉牙用烂的有关波士顿马萨诸塞州住房的数据。

2.Zillow (房地产研究网站 )
Housing Data - Zillow Research 是有关美国按大小、类型和等级划分的房价和租金的信息。

教育行业数据集(2)
1. NEES(美国国家教育统计中心)
National Center for Education Statistics (NCES) Home Page, a part of the U.S. Department of Education,包含美国和国际教育机构和教育人口统计数据的网站。
2.Data Catalog (世界银行全球教育统计数据集 )
Data Catalog 包含有关教育的 4000 多个国际可比指标的数据。
最后的总结
上面的数据集基本上能满足个人起步学习用于机器学习、计算机视觉、数据分析、数据挖掘和数据可视化项目。
数据集在机器学习中非常重要,需要大量的数据,但手头可能缺少数据。但是互联网上的公开数据种类繁多,从日本公开的数据到海外公开的数据都有。如果可以选择适合要构建的系统和目的的数据集,肯定会有所帮助。
赶紧下载其中一个数据集加入数据分析的行列吧。
















 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











