







 本文介绍了在互联网时代,如何通过收集用户网络行为数据,构建大数据环境,包括使用Flume采集日志、HDFS存储、Hive构建数据仓库以及Spark进行分析。重点讲述了OLTP和OLAP的区别,以及数据仓库的层次结构,如事实表、维度表和不同数据层的设计与功能划分。
本文介绍了在互联网时代,如何通过收集用户网络行为数据,构建大数据环境,包括使用Flume采集日志、HDFS存储、Hive构建数据仓库以及Spark进行分析。重点讲述了OLTP和OLAP的区别,以及数据仓库的层次结构,如事实表、维度表和不同数据层的设计与功能划分。
概要
现在是互联网的时代, 每个人的生活中都会使用到互联网的各种应用, 我们会进行网络购物, 会进行新闻浏览, 视频浏览, 微信聊天等等, 当我们在使用互联网的时候, 我们的所有的数据都需要通过运行商(电信, 移动,联通)进行数据的发送和接收, 对于每一个访问, 运营商都可以获取到对应的请求信息, 我们可以通过 对网络请求的信息分析, 及时掌握互联网的动态和行业前沿, 并且根据用户的请求访问数据, 我们可以分析 互联网行业的发展现状和每个城市的互联网的发展程度等等. 通过对于互联网的发展的相关指标分析, 可 以为政府部门, 商业公司提供一些决策分析的数据.
- 为相关统计部门提供数据支持, 比如上网的用户时长, 上网的用户人数, 上网模式的占比等等
- 为行业发展的预测提供数据支撑
- 为企业发展提供数据支撑, 分析每个网站的访问情况
整体架构流程
整体框架如下图所示


技术细节
大数据环境搭建
集群规划如下,主要用到三台服务器Hadoop01、Hadoop02、Hadoop03。01作为集群的主节点和资源管理者,另外两台作为从节点

一些软件和环境配置如下

配置JDK等软件包时候,可以直接在其中一台服务器配置豪,通过同步软件分发到其他服务器上。当集群搭建好后,可以通过
start-all.sh stop-all.sh 开启和停止集群。并且可以通过jps 命令查看集群的启动效果。下图为集群启动成果后的效果。包括NameNode、DataNode等相关角色。
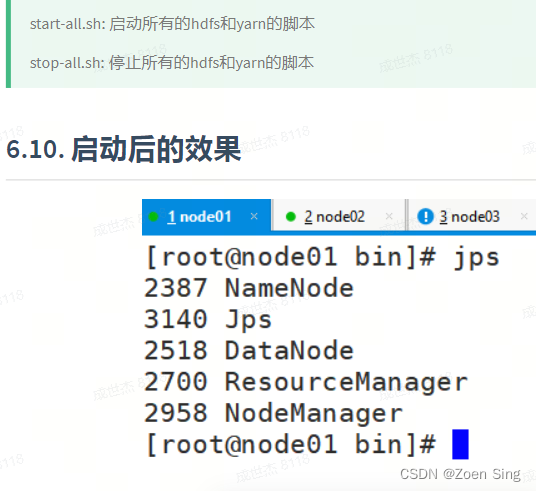
另外启动hive 和 Spark如下:启动hive:bin/hive ;启动spark:bin/spark-shell,但是安装pyspark时候要和集群的spark版本一致,否则代码会报错,而且需要指定pyspark的路径为anaconda
from pyspark import SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"]="/bigdata/server/anaconda3/envs/pyspark/bin/python3"
数据采集
数据采集软件为Flume, 前提条件是业务系统需要有hadoop的客户端。项目实践中使用的电信用户行为原始数据如下:包括上网的ip、方式、模式、访问网站等,例如通过ip可以获得用户所在的区域等。

安装好Flume 软件后,需要在lib目录添加一个ETL拦截器,在业务服务器的Flume的lib目录添加itercepter-etl.jar,这样做的目的是
- 处理标准的json格式的数据, 如果格式不符合条件, 则会过滤掉该信息
- 处理时间漂移的问题, 把对应的日志存放到具体的分区数据中
最后运行数据采集命令
bin/flume-ng agent --conf conf/ --name a1 --conf-file jobs/log_file_to_hdfs.conf -Dflume.root.logger=INFO,console
最终日志采集的效果如下:
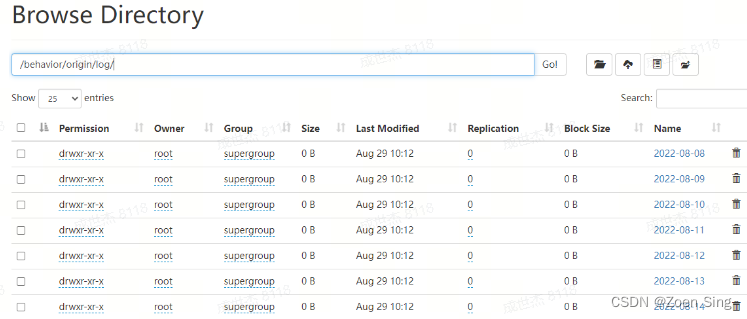
数据仓库建模与建设
- 联机事务处理过程(OLTP),也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。具有较强的数据一致性和事务操作
- OLAP是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。其中F是快速性(Fast),指系统能在数秒内对用户的多数分析要求做出反应;A是可分析性(Analysis),指用户无需编程就可以定义新的专门计算,将其作为分析的一部分,并以用户所希望的方式给出报告;M是多维性(Multi—dimensional),指提供对数据分析的多维视图和分析;I是信息性(Information),指能及时获得信息,并且管理大容量信息. 主要是一个数据分析系统, 要求有较快的时间响应
对于我们常用的关系型数据库, 对于数据一致性要求比较高, 基本都是我们的OLTP系统,而对于我们常见的数据分析系统, 主要是根据已有的业务数据进行统计分析, 比如管理驾驶舱数据统计分析,比如做BI报表, 做机器学习等, 这些我们会专门在一个数据分析系统OLAP系统进行统计分析
- 事实表。是指存储有事实记录的表,如系统日志、销售记录等;事实表的记录在不断地动态增长,所以它的体积通常远大于其他表。
- 维度表。维度表或维表,有时也称查找表,是与事实表相对应的一种表;它保存了维度的属性值,可以跟事实表做关联;相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。常见的维度表有:日期表(存储与日期对应的周、月、季度等的属性)、地点表(包含国家、省/州、城市等属性)等。维度是维度建模的基础和灵魂,
- ODS层: 存放业务系统采集过来的原始数据, 直接加载的业务数据, 不做处理
- DWD层: 对于ODS层的数据做基本的处理, 并且进行业务事实的分析和定位(不合法的数据处理, 空值的处理), 一行数据代表的是一个业务行为
- DWS层, 对于DWD层的业务数据进行按天或者按照一定的周期进行统计分析, 是一个轻度聚合的结果DIM层, 维度统计层, 对于需要统计分析(group by)的相关的条件进行统一的设计和规范, 比如时间, 地区, 用户等
- ADS(数据应用层): 需要的业务统计分析结果, 一般会把ADS层的数据抽取到业务数据库MySQL中。例如本项目的需求如下

对数据仓库分层,可以把复杂问题简单化不同的层次负责不同的功能定位;减少重复开发,对于DIM, DWS可以根据主题进行自上而下的设计, 抽取通用的功能;隔离原始数据 ODS层原始数据, 可以对统计结果进行回溯, 方便问题的定位
参考资料
https://www.bilibili.com/video/BV1L24y1o7f7/?spm_id_from=333.999.0.0















 2789
2789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









