







软件测试所有内容笔记正在陆续更新中,笔记已经在本地记录,全部为自己手动记录的笔记及总结,正在开始更新中,后续会逐步更新并完善到
软件测试学习内容总结专栏。
本节内容:Linux与Bash课程
文章目录
1. Linux系统与Shell环境准备
-
Windows 与 Linux 界面比较

-
Linux 目录结构

-
Linux 基本命令
- ls: 列出目录
- cd:切换目录
- pwd:显示目前的目录
- mkdir:创建一个新的目录
- rmdir:删除一个空的目录
- cp: 复制文件或目录
- rm: 移除文件或目录
- mv: 移动文件与目录,或修改文件与目录的名称
-
Shell 基础
-
常见的 shell
Bourne Shell(/usr/bin/sh或/bin/sh)
Bourne Again Shell(/bin/bash)
C Shell(/usr/bin/csh)
K Shell(/usr/bin/ksh)
Shell for Root(/sbin/sh -
运行shell
- chmod +x ./test.sh #使脚本具有执行权限
./test.sh #执行脚本 - /bin/sh test.sh
- chmod +x ./test.sh #使脚本具有执行权限
-
2. Linux常用命令之 文件处理
1. 连接服务器
-
ssh --Mac系统

-
xshell --Windows系统

2. 文件
-
查看帮助
- –help (ls --help)
- man (man ls)
-
文件管理

- ls -la:详细显示所有目录、文件信息
- -l:显示目录、文件的详细信息,
- -a:显示目录下所有文件,包括隐藏文件
- ls -l 可简写为ll
- cd:直接从其他目录切换到home目录
- mkdir a/b/c -p:
- -p 可以逐层(递归)创建目录
- rm -r c:
- -r 删除目录时需添加(删文件直接加文件名)
- rm -rf c:
- -f 强制删除,不管有没有目录都不报错
- rm -ri c:
- -i 提示是否删除 y/n
- ls -la:详细显示所有目录、文件信息
- 拷贝:cp
- 移动/重命名:mv
- 建立链接文件:ln
- 查找文件:find
- 查看文件内容:cat、less、more、head、tail
- 打包压缩:tar
复制
- cp 原文件的位置 目标目录的位置
- 复制文件
- cp -a 原目录的位置 目标目录的位置
- 复制目录加 -a
重命名/移动
- mv 旧文件名 新的文件名
- 重命名
- mv 文件名 目录名
- 移动文件
- mv 文件名 目录名/新文件名
- 移动并重命名文件
链接
- ln -s 需要链接的文件名 连接位置
- -s 建立软连接
- ln -s ./a/a.txt .
- 将当前位置a目录下的a.txt文件链接到当前目录
查找文件
- find 文件位置 -name 文件名
- 用文件名搜索加-name
- find ./ -name a.txt
- 搜索当前目录下文件名为a.txt的文件
- find ./ -name ‘*.txt’
- 搜索当前目录下后缀名为.txt的文件
查看文件
- cat 文件名
- 显示文件所有内容
- less 文件名
- 一屏一屏显示 b 往前翻,f 往后翻,空格 往后翻,回车 一行一行后翻
- more 和less类似
- head 文件名
- 默认展示文件前10行
- head -n 展示行数 文件名
- head -n 3 a.txt
- tail 和 head 类似
- 默认显示文件后10行
压缩文件
- tar -zcvf 压缩后的文件名 需要压缩的文件名
- -z 通过gzip格式压缩,
- -v 显示指令执行过程,
- -c 建立新的备份文件,
- -f 指定备份文件
- tar -zcvf f.tar.gz 1.txt 2.txt
- 将1.txt 2.txt压缩为f.tar.gz
解压缩
- tar -xf 压缩的文件名 -C 解压的目录名
- -C 大写 指定解压缩的目录
- tar -xf f.tar.gz
- 解压文件
- tar -xf f.tar.gz -C ./a/
- 将f.tar.gz解压缩到当前目录的a文件下

文件类型:d,-,l,b,c,
权限属性 连接 所有者 用户组 大小 修改日期 文件或目录名
权限属性:拥有者 所数组 其他人
3. 网络
-
查看网卡信息
ifconfig -
测试远程主机连通性
- ping
- -c:ping的次数
- -i:每次ping的时间间隔
ping -c 3 -i 3 101.200.136.153 - ping
-
netstat:打印Linux网络系统的状态信息
- -t 列出所有tcp
- -u 列出所有udp
- -l 只显示监听端口
- -n 以数字形式显示地址和端口号
- -p 显示进程的pid和名字
netstat -tnp -
退出 Linux 系统
- exit
3. Linux常用命令之 性能统计
硬件简介

1. CPU
- 查看 CPU 信息:cat /proc/cpuinfo
- 负载信息:top
top:持续监视系统性能
ps:查看进程信息
-aux 显示所有进程,包括用户,分组情况
-
测试系统负载
- {yes > /dev/null & } && sleep 30 $$ ps -ef | grep yes | awk ‘{print $2}’ | xargs kill
- for i in $(seq 0 $(($(cat /proc/cpuinfo | grep processor |wc -l)-l))); do taskset -c $i yes > /dev/null & done && sleep 30 && ps -ef | grep yes |awk ‘{print $2}’ |xargs kill

-
top
- -d 间隔时间,
top -d 4每隔4秒更新一次 - -n 获取多次cpu的执行情况,top -n 4 只更新4次
- -p 获取指定端口的进程的数据
- -b 批处理模式
top -p 6547 -d 1 -n 4- 参数含义
- Tasks:进程总数
- running:正在运行的进程数
- sleeping:睡眠的进程数
- stopped:停止的进程数
- zombie:僵尸进程数
- -d 间隔时间,
-

-

2. 内存
- 显示内存信息:
free -h

3. IO(Input Output)
-
安装

-
硬盘 IO
-
在命令行分别输入下面 ‘写 读’ 命令测试系统的读写的速度,使用
iostat查看读写情况 -
/dev/null/ 空设备,/dev/zero/ 特殊文件
-
写:读取 zero 文件并写入 test.iso 文件
-
读:将 test.iso 文件加载到空设备 null 上

-
使用命令
iostat 1查看CPU,硬盘的使用情况 (在Ubuntu命令行输入命令)-
iostat -c:只看CPU的使用率 -
iostat -d:只看设备的读写情况

-
解释

-
-
-
网络IO
- iftop

- iftop
4. Linux常用 统计命令
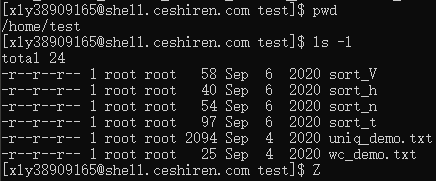
1. 排序:sort
-
sort --help
-
练习数据在服务器上
/home/test目录下 -
ssh xly38909165@shell.ceshiren.com 密码:hogwarts
-
sort 常用参数
- -b:忽略开头的空白字符
- -f:将小写字母看作为大写字母
- -h:根据存储容量排序(KB、MB、GB)
- -n:按数字排序
- -o:把结果写入文件
- -r:以相反的顺序来排序
- -t:指定分隔符。默认为空格
- -V:按数字版本排序
- -k:指定排序的关键字。与-t参数配合使用
- 参考:https://wangchujiang.com/linux-command/c/sort.html
-
cat sort_h
-
cat sort_h|sort 默认排序
-
cat sort_h|sort -h 根据 容量大小 从小到大排序
-
cat sort_h|sort -hr 根据容量大小从大到小排序
-
cat sort_n
-
cat sort_n|sort
-
cat sort_n|sort -n 按 数字大小 从小到大排序
-
cat sort_n|sort -nr 按数字大小从大到小排序
-
cat sort_n|sort -nr -o 1.txt 将排序结果输出
-
cat sort_t
-
cat sort_t|sort -t . -k 1 根据 . 分隔后 按照第1列排序
-
cat sort_t|sort -t . -k 2 根据 . 分隔后 按照第2列排序
-
cat sort_t|sort -t S -k 3 根据 S 分隔后 按第3列排序
-
cat sort_t|sort -t S -k 4 根据 S 分隔后 按第4列排序

-
cat sort_V
-
cat sort_V|sort
-
cat sort_V|sort -V
2. 去除重复:uniq
-
uniq 去重只会检查上下行是否重复,不检查跨行内容;所以 uniq 去重前会先进行排序,将相同内容放一起
-
uniq 常用参数(只检查上下行是否重复)
- -c:统计重复出现的次数
- -d:所有邻近的重复行只被打印一次。重复次数要>=2次
- -D:所有邻近的重复行将全部打印
- -f:跳过对前n个列的比较
- -s:跳过对前n个字符的比较
- -w:只对每行前n个字符进行比较
-
uniq -c uniq_demo.txt
-
uniq -c -f 2 uniq_demo.txt 加-f跳过对前2列的比较
-
cat uniq_demo.txt |sort -k 3|uniq -c
-
cat uniq_demo.txt |sort -k 3|uniq -c -f 2
-
cat uniq_demo.txt |sort -k 3|uniq -c -f 2|sort 默认排序
-
cat uniq_demo.txt |sort -k 3|uniq -c -f 2|sort -k 1 按第1列直接排序
-
cat uniq_demo.txt |sort -k 3|uniq -c -f 2|sort -k 1 -n 从小到大排序
-
cat uniq_demo.txt |sort -k 3|uniq -c -f 2|sort -k 1 -nr 将 uniq_demo.txt 内容按空格分隔后按第3列排序(-t省略为默认),并且跳过前2列内容统计重复出现的次数,在将得到的内容按空格分隔后按第1列以数字大小从大到小排序(省略-t)
-
cat uniq_demo.txt |uniq -f 2 跳过对前2行的比较对第3列去重(只比较上下行)
-
cat uniq_demo.txt |uniq -f 2 -d 对第3列去重,比较所有
-
cat uniq_demo.txt |uniq -f 2 -D 去重并打印所有邻近重复行,没有重复的行(只有一行的数据)不会打印
-
cat uniq_demo.txt |uniq -s 14 -D 跳过前14个字符
-
cat uniq_demo.txt |uniq -w 2 -c 比较前2个字符
3. 字符统计:wc
-
wc 常用参数
- -c:统计字节数:chars
- -l:统计行数
- -w:统计单词数
- -L:打印最长行的长度
-
wc --help
-
cat wc_demo.txt |wc 打印结果显示为:行数 单词数 字符数(包括空格 换行符)
-
cat wc_demo.txt |wc -l 统计行数
-
cat wc_demo.txt |wc -w 统计单词数
-
cat wc_demo.txt |wc -c 统计字符数
-
cat wc_demo.txt |wc -L 打印出最长行的长度
5. Linux三剑客与管道使用
1. 管道
-
什么是管道?
Linux提供管道符“|”将两个命令隔开,管道符左边命令的输出就会作为管道符右边命令的输入 -
示例
echo "hello1234"| grep 'hello'
2. 正则表达式
-
什么是正则?
正则表达式就是
记录文本规则的代码

-
演练环境
-
举例
- 找出所有的hi单词 \bhi\b
- hi单词后面有lucy单词 \bhi\b.*\blucy\b
- 以0开头,然后是两个数字,然后是一个连字 号“-”,最后是8个数字 0\d{2}-\d{8}
-
常用元字符


- 实战
- 匹配以字母a开头的单词
- \ba\w*\b
- 匹配刚好6个字符的单词
- \b\w{6}\b
\b.{6}\b
- 匹配1个或更多连续的数字
- \d+
- 5位到12位QQ号
- ^\d{5,12}$
- 匹配以字母a开头的单词
3. grep
-
定义
根据用户指定的模式(pattern)对目标文本进行 过滤,显示被模式匹配到的行 -
命令形式

-
选项
- -v 显示不被pattern匹配到的行
- -i 忽略字符大小写
- -n 显示匹配的行号
- -c 统计匹配的行数
- -o 仅显示匹配到的字符串
- -E 使用ERE,相当于egrep
-
实战1
- 查找文件内容包含root的行数
- grep -n root test.txt
- 查找文件内容不包含root的行
- grep -nv root test.txt
- 查找文件内容包含root的行数
-
实战2
- 查找以s开头的行
- grep ^s test.txt
- 查找以n结尾的行
- grep n$ test.txt
- 查找以s开头的行
4. sed
- 定义
sed是流编辑器,一次处理一行内容

-
命令形式
sed [-hn..][-e<script>][-f<script FILE>][FILE]
-
命令解析
-
sed [-hn..][-e<script>][-f<script文件>][文本文件]- -h 显示帮助。
- -n 仅显示script处理后的结果。
-
sed [-hnV][-e<script>][-f<script文件>][文本文件]- -e<script> 以选项中指定的script来处理输入的文本文件。
- -f<script文件> 以选项中指定的script文件来处理输入的文本文件。
-
-
常用动作

- a :新增 sed -e ‘4 a newline’
- -e:指定脚本(脚本内容为4 a newline)
- 在第4行后面新增加1行,增加的内容为newline
- c :取代 sed -e ‘2,5c No 2-5 number’
- 用c后面的内容取代2行到5行的内容
- d :删除 sed -e '2,5d’
- 删除2到5行
- i :插入 sed -e ‘2i newline’
- 在第2行前面插入1行,插入的内容为newline
- p :打印 sed -n ‘/root/p’
- 两个正斜杠间的内容为正则,root为正则表达式
- 塞尔达匹配到正则后打印
- s :取代 sed -e 's/old/new/g’
- 用new取代old
- /g 代表全局,一行存在多个匹配(替换)的情况下加,负责只替换第1个
- a :新增 sed -e ‘4 a newline’
-
实战1
- 查看帮助
man sed- 查看信息:用j向下翻页,用k向上翻页
- 可以使用/来进行查找(比如:/-a)
- 用n向下翻页,N向上翻页
sed -h
- 在第四行后添加新字符串
sed -e '4 a newline testfile' test.txt- sed为流处理,在模式空间进行,不对原文件进行修改
- 查看帮助
-
实战2

-
实战3



5. awk
- 定义
把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行后续处理

-
命令形式

-
命令解析
awk ‘pattern + action’ [filenames]- -pattern 正则表达式
- -action 对匹配到的内容执行的命令(默认为输出每行内容)
-
常用参数
- FILENAME awk浏览的文件名
- BEGIN 处理文本之前要执行的操作
- END 处理文本之后要执行的操作
- FS 设置输入域分隔符,等价于命令行 -F选项
- NF 浏览记录的域的个数(列数)
- NR 已读的记录数(行数)
- OFS 输出域分隔符
- ORS 输出记录分隔符
- RS 控制记录分隔符
- $0 整条记录
- $1 表示当前行的第一个域…以此类推
-
实战1
- 大括号{}里面代表动作,大括号外面代表正则
awk -F : '/root/{print $7}' /etc/passwdawk -F : 'NR==2{print $0}' /etc/passwd

-
实战2

6. Bash编程语法
1. 变量
-
规则
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头
- 中间不能有空格,可以使用下划线(_)
- 不能使用标点符号
- 不能使用bash里的关键字(可用help命令查看保留关键字)
-
定义与使用变量
- 定义变量
your_name="abc" - 调用变量
echo $your_name
- 定义变量
-
只读变量
a="123"readonly a
-
删除变量
- unset variable_name
- 不能删除只读变量
-
变量类型
- 字符串:your_name=“hogwarts”
- 拼接字符串:greeting=“hello, “$your_name” !”
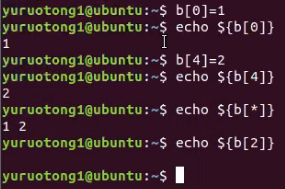
- 数组 array_name=(value0 value1 value2 value3)
- 取数组 valuen=${array_name[n]}
- 单独赋值 array_name[0]=value0
-
实战1
- 使用变量
- a = “abc”
- echo $abc
- 删除变量
- unset a
- 使用变量
-
实战2
- *或@打印整个数组
- 指定哪个,哪个有值


2. 控制语句
- 条件分支:if
-
if 定义

-
if
- 使用大于或小于要用2个中括号
- 如果要使用1个 就要用-gt -lt

-
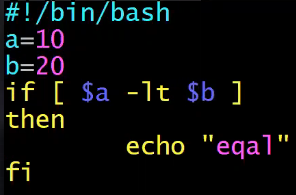
实战
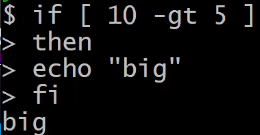
- 比较两个变量的大小并输出不同的值
- i f [ $a -eq $b ]; then echo “equal”; elif [ $a -lt $b ];then echo “small”; elif [ $a -gt $b ];then echo “big”;fi
- 比较两个变量的大小并输出不同的值
-
- 循环:for
-
for 定义

-
for

-
实战
- 循环读取文件内容并输出
- for i in $(cat dir.txt);do echo $i;done
- $加()括起来表示整个内容是一个命令
- 循环读取文件内容并输出
-
- 循环:while
-
while 定义
while condition do command done -
while
int=1 while(($int<=5)) do echo $int let "int++" done -
实战
- 循环读取文件内容并输出
- while read line;do echo $line;done<dir.txt
- 循环读取文件内容并输出
-
如果读取的文件中一行内容中有空格(abc 123),使用for循环会分开打印两行内容,使用while打印一行
7. Bash脚本编写
1. Bash 基本使用
-
read 命令
- read命令是用于从终端或者文件中读取输入的内部命令
- 读取整行输入
- 每行末尾的换行符不被读入
-
read 命令使用
- 从标准输入读取输入并赋值给变量
- read var
- 从标准输入读取多个内容
- read var1 var2 var3
- 不指定变量(默认赋值给REPLY)
- read
- 从标准输入读取输入并赋值给变量
-
脚本传参 传递
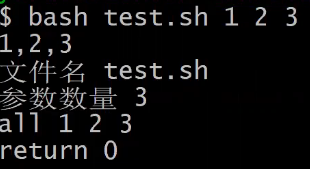
$0脚本名称$1~$n获取参数$#传递到脚本的参数个数$$脚本运行的当前进程ID号$*以一个单字符串显示所有向脚本传递的参数$?显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误
2. 基本运算
-
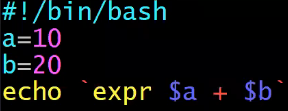
算数运算1
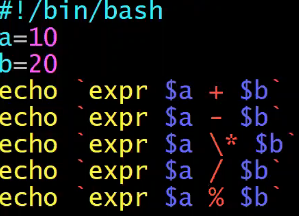
- a=10 b=20
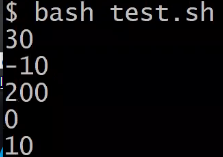
+加法expr $a + $b结果为 30-减法expr $a - $b结果为 -10*乘法expr $a \* $b结果为 200/除法expr $b / $a结果为 2- 要使用反引号括起来
- 乘法要写转义
-
算数运算2
- a=10 b=20
%取余 `expr $a % $b` 结果为 10=赋值a=$b将把变量 b 的值赋给 a==相等 相同则返回 true:[ $a == $b ] 返回 false!=不相等 不相同则返回 true:[ $a != $b ] 返回 true
-
算数运算3
- -eq 检测相等 [ $a -eq $b ] 返回 false
- -ne 检测不相等 [ $a -ne $b ] 返回 true
- -gt 检测左边是否大于右边 [ $a -gt $b ] 返回 false
- -lt 检测左边是否小于右边 [ $a -lt $b ] 返回 true
- -ge 检测左边是否大于等于右边 [ $a -ge $b ] 返回 false
- -le 检测左边是否小于等于右边 [ $a -le $b ] 返回 true
3. bash 与 linux命令组合
-
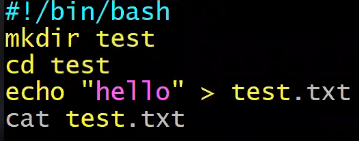
bash与目录命令
- 创建目录并生成文件
- mkdir test
- cd test
- echo “hello” > test.txt
- ls
- 创建目录并生成文件
-
bash与内存
- 统计内存使用
for i in `ps aux |awk '{print $6}' |grep -v 'RSS'` count=$[$count+$i] echo "$count/kb"
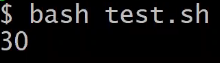
bash test.sh 123
#
echo $1,$2,$3
.




8. linux进阶命令
what
- curl is a tool to transfer data from or to a server
- support protocols
- DICT,FILE,FTP,FTPS,GOPHER,HTTP,HTTPS,IMAP
- without user interaction
proxy support
curl -x 127.0.0.1:8888 https://www.baidu.com
get
- -G:使用get请求
- -d:指定请求数据
curl https://www.baidu.comcurl -G https://www.baidu.comcurl -X GET https://www.baidu.com
post
- -d:指定post请求体
curl -d 'login=1234' https://www.baidu.comcurl -X POST https://www.baidu.com
other
- 保存响应内容
curl -o tmp.html https://www.baidu.com
- 输出通信的整个过程
curl -v https://www.baidu.com
- 不输出错误和进程信息
curl -s https://www.baidu.com
iq
- A jq program is a filter
- it takes an input, and produces an output
- https://stedolan.github.io/jq/
using
- . 格式优化
echo '{"a":11,"b":12}' | jq '.'- it takes an input, and produces an output
常用方法1
- 内容提取
echo '{"foo":42,"bar":"less interesting data"}' | jq .foo
常用方法2
- 从数组中提取单个数据
echo '[{"a":1,"b":2},{"c":3,"d":4}]' | jq .[0]
- 从数组中提取所有数据
echo '[{"a":1,"b":2},{"c":3,"d":4}]' | jq .[]
- 过滤多个值
echo '[{"a":1,"b":2},{"c":3,"d":4}]' | jq .[0,1]
常用方法3
- 数据重组成数组
echo '{"a":1,"b":2,"c":3,"d":4}' | jq '[.a,.b]'
- 数据重组成对象
echo '{"a":1,"b":2,"c":3,"d":4}' | jq '{"tmp":.b}'















 1823
1823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









