







目录
五、训练
7. 开始训练
for epoch in range(config.max_epoch):
print('Epoch: {}'.format(epoch))从这里开始进入循环开始训练,为了详细讲述代码,后续代码将不嵌套循环讲解。
7.1 训练集上训练
7.1.1 可视化进度条&初始化梯度
# 可视化进度条
progress = tqdm.tqdm(total=batch_num, ncols=75, desc='Train {}'.format(epoch))
# 初始化梯度
optimizer.zero_grad()7.1.2 训练集上训练
for batch_idx, batch in enumerate(DataLoader(
train_set, batch_size=config.batch_size // config.accumulate_step,
shuffle=True, drop_last=True, collate_fn=train_set.collate_fn)):
# 前向传播计算损失
loss = model(batch)
loss = loss * (1 / config.accumulate_step)
loss.backward()
# 根据积累的步数更新模型参数
if (batch_idx + 1) % config.accumulate_step == 0:
progress.update(1)
global_step += 1
# 梯度裁剪,防止梯度爆炸
torch.nn.utils.clip_grad_norm_(
model.parameters(), config.grad_clipping)
optimizer.step()
# 跟新学习率调度器
schedule.step()
optimizer.zero_grad()
progress.close()7.1.2.1 前向传播
这里我们再来看一下前向传播计算损失是具体如何实现的。看model.py中的forward(batch)函数
# 前向传播
def forward(self, batch):
编码器Encoding
首先定义了一个编码器,
bert_outputs = self.encode(batch.piece_idxs, batch.attention_masks, batch.token_lens)
batch_size, _, _ = bert_outputs.size()这里调用了一个名为encode的函数,该函数接受输入数据batch.piece_idxs、batch.attention_masks和batch.token_lens,并返回BERT模型的输出bert_outputs。
具体来看一下encode函数,也在model.py中
def encode(self, piece_idxs, attention_masks, token_lens):
"""Encode input sequences with BERT
:param piece_idxs (LongTensor): 单词切片索引
:param attention_masks (FloatTensor): 注意力掩码
:param token_lens (list): 标记长度列表
"""
# 获取批次大小和输入张量的第二个维度大小。
batch_size, _ = piece_idxs.size()
# 通过调用BERT模型对输入序列进行编码,得到所有的BERT输出。all_bert_outputs[0]包含了BERT的最后一层隐藏状态的表示
all_bert_outputs = self.bert(piece_idxs, attention_mask=attention_masks)
bert_outputs = all_bert_outputs[0]
# 将BERT中的倒数第三层替换为输出层
if self.use_extra_bert:
extra_bert_outputs = all_bert_outputs[2][self.extra_bert]
bert_outputs = torch.cat([bert_outputs, extra_bert_outputs], dim=2)
# 如果multi_piece的值为'first',则对于多词片段的单词,选择每个序列的第一个片段。使用token_lens_to_offsets函数将标记长度转换为偏移量,并使用torch.gather选择相应的BERT表示。
if self.multi_piece == 'first':
# select the first piece for multi-piece words
offsets = token_lens_to_offsets(token_lens)
offsets = piece_idxs.new(offsets)
# + 1 because the first vector is for [CLS]
offsets = offsets.unsqueeze(-1).expand(batch_size, -1, self.bert_dim) + 1
bert_outputs = torch.gather(bert_outputs, 1, offsets)
# 如果multi_piece的值为'average',则对于多词片段的单词,取所有片段的平均值。使用token_lens_to_idxs 函数将标记长度转换为索引,并使用torch.gather选择相应的BERT表示,然后乘以掩码进行平均。
elif self.multi_piece == 'average':
# average all pieces for multi-piece words
idxs, masks, token_num, token_len = token_lens_to_idxs(token_lens)
idxs = piece_idxs.new(idxs).unsqueeze(-1).expand(batch_size, -1, self.bert_dim) + 1
masks = bert_outputs.new(masks).unsqueeze(-1)
bert_outputs = torch.gather(bert_outputs, 1, idxs) * masks
bert_outputs = bert_outputs.view(batch_size, token_num, token_len, self.bert_dim)
bert_outputs = bert_outputs.sum(2)
# 如果 multi_piece不是'first'也不是'average',则抛出一个值错误。
else:
raise ValueError('Unknown multi-piece token handling strategy: {}'
.format(self.multi_piece))
bert_outputs = self.bert_dropout(bert_outputs)
return bert_outputs根据代码的叙述其实就是将BERT中的编码端拿了过来,得到每个词的上下文表示,就像论文中提到的一样使用了BERT的导数第三层作为输出层输出。
识别器Identification
# 将实体类型的索引转换为独热编码,并进行处理。
entity_types = batch.entity_type_idxs.view(batch_size, -1)
entity_types = torch.clamp(entity_types, min=0)
entity_types_onehot = bert_outputs.new_zeros(*entity_types.size(),
self.entity_type_num)
entity_types_onehot.scatter_(2, entity_types.unsqueeze(-1), 1)这一阶段分为两步,
- 首先使用前馈神经网络FFN数据计算实体和触发词的标签得分
# 通过前馈神经网络 self.entity_label_ffn 和 self.trigger_label_ffn 计算实体标签和触发词标签的分数。
entity_label_scores = self.entity_label_ffn(bert_outputs)
trigger_label_scores = self.trigger_label_ffn(bert_outputs)- 然后对实体标签和触发词标签的分数进行处理,包括对分数用条件随机场(CRFs)层进行计算
并且计算对数自然函数
entity_label_scores = self.entity_crf.pad_logits(entity_label_scores)
entity_label_loglik = self.entity_crf.loglik(entity_label_scores, batch.entity_label_idxs, batch.token_nums)
trigger_label_scores = self.trigger_crf.pad_logits(trigger_label_scores)
trigger_label_loglik = self.trigger_crf.loglik(trigger_label_scores, batch.trigger_label_idxs, batch.token_nums) 由于损失所以无需保存到新的变量中去,只要直接加符号就行。
分类器Classification
scores = self.scores(bert_outputs, batch.graphs, entity_types_onehot)
(
entity_type_scores, mention_type_scores, event_type_scores,
relation_type_scores, role_type_scores
) = scores
entity_type_scores = entity_type_scores.view(-1, self.entity_type_num)
event_type_scores = event_type_scores.view(-1, self.event_type_num)
relation_type_scores = relation_type_scores.view(-1, self.relation_type_num)
role_type_scores = role_type_scores.view(-1, self.role_type_num)
mention_type_scores = mention_type_scores.view(-1, self.mention_type_num)通过调用 scores 函数计算各种分类任务的得分,然后将得分展平成一维张量。
这里来具体看一下scores函数
def scores(self, bert_outputs, graphs, entity_types_onehot=None,
predict=False):
'''
这是一个函数定义,函数名为 scores。该函数用于计算各种类型的得分,接受BERT模型的输出 bert_outputs,以及表示图结构的 graphs,还有一个可选参数 entity_types_onehot 和一个布尔参数 predict。
Args:
bert_outputs:
graphs:
entity_types_onehot:
predict:
Returns:
'''-
使用graphs_to_node_idxs函数将图结构graphs转换为用于表示实体和触发词的索引、掩码和长度。
(
entity_idxs, entity_masks, entity_num, entity_len,
trigger_idxs, trigger_masks, trigger_num, trigger_len,
) = graphs_to_node_idxs(graphs)
# 获取BERT模型输出的大小。
batch_size, _, bert_dim = bert_outputs.size()
# 将索引和掩码转换为与BERT输出相同设备和数据类型的张量
entity_idxs = bert_outputs.new_tensor(entity_idxs, dtype=torch.long)
trigger_idxs = bert_outputs.new_tensor(trigger_idxs, dtype=torch.long)
entity_masks = bert_outputs.new_tensor(entity_masks)
trigger_masks = bert_outputs.new_tensor(trigger_masks)-
计算节点类型的得分。以实体类型得分为例,其余节点类型得分计算类似首先,使用 torch.gather 从BERT输出中选择相应的实体表示,然后通过掩码将实体的表示取出,最后对实体的表示进行求和,并通过前馈神经网络 self.entity_type_ffn 得到j节点类型的得分。
# 计算实体类型的得分。首先,使用 torch.gather 从BERT输出中选择相应的实体表示,然后通过掩码将实体的表示取出,最后对实体的表示进行求和,并通过前馈神经网络 self.entity_type_ffn 得到实体类型的得分。
entity_idxs = entity_idxs.unsqueeze(-1).expand(-1, -1, bert_dim)
entity_masks = entity_masks.unsqueeze(-1).expand(-1, -1, bert_dim)
entity_words = torch.gather(bert_outputs, 1, entity_idxs)
entity_words = entity_words * entity_masks
entity_words = entity_words.view(batch_size, entity_num, entity_len, bert_dim)
entity_reprs = entity_words.sum(2)
entity_type_scores = self.entity_type_ffn(entity_reprs)
# 计算提及类型的得分,通过前馈神经网络 self.mention_type_ffn 得到。
mention_type_scores = self.mention_type_ffn(entity_reprs)
# 计算触发词类型的得分。与计算实体类型的方法相似,通过前馈神经网络 self.event_type_ffn 得到触发词类型的得分。
trigger_idxs = trigger_idxs.unsqueeze(-1).expand(-1, -1, bert_dim)
trigger_masks = trigger_masks.unsqueeze(-1).expand(-1, -1, bert_dim)
trigger_words = torch.gather(bert_outputs, 1, trigger_idxs)
trigger_words = trigger_words * trigger_masks
trigger_words = trigger_words.view(batch_size, trigger_num, trigger_len, bert_dim)
trigger_reprs = trigger_words.sum(2)
event_type_scores = self.event_type_ffn(trigger_reprs)-
计算关系类型的得分,通过前馈神经网络 self.mention_type_ffn 得到。
# 计算实体之间关系类型的得分。首先,生成实体对的索引,然后通过 torch.gather 从BERT输出中选择相应的实体表示,最后通过前馈神经网络 self.relation_type_ffn 得到关系类型的得分
ee_idxs = generate_pairwise_idxs(entity_num, entity_num)
ee_idxs = entity_idxs.new(ee_idxs)
ee_idxs = ee_idxs.unsqueeze(0).unsqueeze(-1).expand(batch_size, -1, bert_dim)
ee_reprs = torch.cat([entity_reprs, entity_reprs], dim=1)
ee_reprs = torch.gather(ee_reprs, 1, ee_idxs)
ee_reprs = ee_reprs.view(batch_size, -1, 2 * bert_dim)
relation_type_scores = self.relation_type_ffn(ee_reprs)
# 计算触发词和实体之间关系类型的得分,与计算实体关系类型的方法类似。
te_idxs = generate_pairwise_idxs(trigger_num, entity_num)
te_idxs = entity_idxs.new(te_idxs)
te_idxs = te_idxs.unsqueeze(0).unsqueeze(-1).expand(batch_size, -1, bert_dim)
te_reprs = torch.cat([trigger_reprs, entity_reprs], dim=1)
te_reprs = torch.gather(te_reprs, 1, te_idxs)
te_reprs = te_reprs.view(batch_size, -1, 2 * bert_dim)- 对于实体类型的信息,将实体类型的得分(经过softmax处理)或者独热编码信息拼接到触发词和实体之间的关系类型的得分中,最后通过前馈神经网络self.role_type_ffn得到最终的关系类型得分。
if self.use_entity_type:
if predict:
entity_type_scores_softmax = entity_type_scores.softmax(dim=2)
entity_type_scores_softmax = entity_type_scores_softmax.repeat(1, trigger_num, 1)
te_reprs = torch.cat([te_reprs, entity_type_scores_softmax], dim=2)
else:
entity_types_onehot = entity_types_onehot.repeat(1, trigger_num, 1)
te_reprs = torch.cat([te_reprs, entity_types_onehot], dim=2)
role_type_scores = self.role_type_ffn(te_reprs)
- 最后返回计算得到的各种类型的得分
return (entity_type_scores, mention_type_scores, event_type_scores,
relation_type_scores, role_type_scores)回到前向传播函数forward中来,然后应该计算各类型分类任务的损
## 损失计算阶段:
# 计算分类任务的损失,包括实体类型、事件类型、关系类型、角色类型和提及类型。
classification_loss = self.entity_criteria(entity_type_scores,
batch.entity_type_idxs) + \
self.event_criteria(event_type_scores,
batch.event_type_idxs) + \
self.relation_criteria(relation_type_scores,
batch.relation_type_idxs) + \
self.role_criteria(role_type_scores,
batch.role_type_idxs) + \
self.mention_criteria(mention_type_scores,
batch.mention_type_idxs)
# 计算总体损失,包括分类任务的损失和实体标签、触发词标签的对数似然损失。这是整个前向传播的最终损失。
loss = classification_loss - entity_label_loglik.mean() - trigger_label_loglik.mean()## 损失计算阶段:
# 计算分类任务的损失,包括实体类型、事件类型、关系类型、角色类型和提及类型。
classification_loss = self.entity_criteria(entity_type_scores,
batch.entity_type_idxs) + \
self.event_criteria(event_type_scores,
batch.event_type_idxs) + \
self.relation_criteria(relation_type_scores,
batch.relation_type_idxs) + \
self.role_criteria(role_type_scores,
batch.role_type_idxs) + \
self.mention_criteria(mention_type_scores,
batch.mention_type_idxs)
# 计算总体损失,包括分类任务的损失和实体标签、触发词标签的对数似然损失。这是整个前向传播的最终损失。
loss = classification_loss - entity_label_loglik.mean() - trigger_label_loglik.mean()这里计算了一个局部的总体损失,知识将分类器的损失和识别器的似然函数的损失合并了。文中的总体损失还包括全局特征的损失,在下一步中,我们会加上。
全局特征 global features
# global features
if self.use_global_features:
# 计算全局的图的得分
gold_scores = self.compute_graph_scores(batch.graphs, scores)
# 生成局部最优图
top_graphs = self.generate_locally_top_graphs(batch.graphs, scores)
# 计算局部最优图的得分
top_scores = self.compute_graph_scores(top_graphs, scores)
# 计算全局损失
global_loss = (top_scores - gold_scores).clamp(min=0)
# 将全局损失的均值加到总体损失中。
loss = loss + global_loss.mean()
return loss其中计算全局特征图的得分是通过函数compute_graph_scores函数完成,
def compute_graph_scores(self, graphs, scores):
# 解释:这个函数的目的是计算给定一组图和对应的模型输出的得分。
(
entity_type_scores, _mention_type_scores,
trigger_type_scores, relation_type_scores,
role_type_scores
) = scores
# 解释:从模型输出中解包实体类型、触发词类型、关系类型和角色类型的得分。
label_idxs = graphs_to_label_idxs(graphs)
# 解释:使用 `graphs_to_label_idxs` 函数将图结构转换为用于索引模型输出的标签索引。
label_idxs = [entity_type_scores.new_tensor(idx,
dtype=torch.long if i % 2 == 0
else torch.float)
for i, idx in enumerate(label_idxs)]
# 解释:将得到的标签索引转换为PyTorch张量,并根据索引的奇偶性选择相应的数据类型。偶数索引对应离散的标签,奇数索引对应连续的标签。
(
entity_idxs, entity_mask, trigger_idxs, trigger_mask,
relation_idxs, relation_mask, role_idxs, role_mask
) = label_idxs
# 解释:解包标签索引,得到实体、触发词、关系和角色的索引以及相应的掩码。
# Entity score
entity_idxs = entity_idxs.unsqueeze(-1)
entity_scores = torch.gather(entity_type_scores, 2, entity_idxs)
entity_scores = entity_scores.squeeze(-1) * entity_mask
entity_score = entity_scores.sum(1)
# 解释:使用 `torch.gather` 函数,根据实体的索引从实体类型得分中提取相应的分数。然后,应用实体的掩码,将无效的部分置零,并对每个实体的分数进行求和,得到实体得分。
# Trigger score
trigger_idxs = trigger_idxs.unsqueeze(-1)
trigger_scores = torch.gather(trigger_type_scores, 2, trigger_idxs)
trigger_scores = trigger_scores.squeeze(-1) * trigger_mask
trigger_score = trigger_scores.sum(1)
# 解释:类似地,计算触发词的得分。
# Relation score
relation_idxs = relation_idxs.unsqueeze(-1)
relation_scores = torch.gather(relation_type_scores, 2, relation_idxs)
relation_scores = relation_scores.squeeze(-1) * relation_mask
relation_score = relation_scores.sum(1)
# 解释:类似地,计算关系的得分。
# Role score
role_idxs = role_idxs.unsqueeze(-1)
role_scores = torch.gather(role_type_scores, 2, role_idxs)
role_scores = role_scores.squeeze(-1) * role_mask
role_score = role_scores.sum(1)
# 解释:类似地,计算角色的得分。
score = entity_score + trigger_score + role_score + relation_score
# 解释:将实体、触发词、关系和角色的总体分数相加,得到总体得分。
global_vectors = [generate_global_feature_vector(g, self.global_feature_maps, features=self.global_features)
for g in graphs]
global_vectors = entity_scores.new_tensor(global_vectors)
global_weights = self.global_feature_weights.unsqueeze(0).expand_as(global_vectors)
global_score = (global_vectors * global_weights).sum(1)
# 解释:计算全局特征的得分。使用 `generate_global_feature_vector` 函数获取每个图的全局特征向量,然后通过权重将全局特征与模型的全局特征权重相乘,并对每个图的得分进行求和。
score = score + global_score
# 解释:将全局特征的得分与实体、触发词、关系和角色的总体得分相加,得到最终的图得分。
return score
# 解释:函数返回最终的得分。这个得分可以用于训练过程中的优化,例如用于计算损失或进行模型的更新。
具体的计算方法因为torch中已经集成了,所以并没有文章中介绍的那么麻烦。注意到我们将全局特征的损失也加到了最后得到联合目标函数(联合损失函数)
我们再回到forward函数来,最后我们再forward函数里返回一个总的loss
return loss7.1.2.2 反向传播
然后再回到train.py中来,下面喀什反向传播计算损失的梯度,由于之前定义的优化器,所以反向传播很简单,如下
loss.backward()7.1.2.3 更新模型的参数
if (batch_idx + 1) % config.accumulate_step == 0:
progress.update(1)
global_step += 1
# 梯度裁剪,防止梯度爆炸
torch.nn.utils.clip_grad_norm_(
model.parameters(), config.grad_clipping)
optimizer.step()
# 跟新学习率调度器
schedule.step()
optimizer.zero_grad()7.1.2.4 关闭训练集训练进程
progress.close()7.1.3 在验证集上进行交叉验证
跟训练集上差不多,直接附上代码,有注释的,可以对应到上面的训练集里去看
# 验证集
progress = tqdm.tqdm(total=dev_batch_num, ncols=75,
desc='Dev {}'.format(epoch))
best_dev_role_model = False
dev_gold_graphs, dev_pred_graphs, dev_sent_ids, dev_tokens = [], [], [], []
for batch in DataLoader(dev_set, batch_size=config.eval_batch_size,
shuffle=False, collate_fn=dev_set.collate_fn):
progress.update(1)
# 预测验证集数据
graphs = model.predict(batch)
# 是否忽略第一个行(根据配置)
if config.ignore_first_header:
for inst_idx, sent_id in enumerate(batch.sent_ids):
if int(sent_id.split('-')[-1]) < 4:
graphs[inst_idx] = Graph.empty_graph(vocabs)
# 清理图结构
for graph in graphs:
graph.clean(relation_directional=config.relation_directional,
symmetric_relations=config.symmetric_relations)
dev_gold_graphs.extend(batch.graphs)
dev_pred_graphs.extend(graphs)
dev_sent_ids.extend(batch.sent_ids)
dev_tokens.extend(batch.tokens)
progress.close()
# 评估开发性能
dev_scores = score_graphs(dev_gold_graphs, dev_pred_graphs,
relation_directional=config.relation_directional)
# 更新最佳性能和保存最佳角色模型
for task in tasks:
if dev_scores[task]['f'] > best_dev[task]:
best_dev[task] = dev_scores[task]['f']
if task == 'role':
print('Saving best role model')
torch.save(state, best_role_model)
best_dev_role_model = True
# 保存验证集结果
save_result(dev_result_file,
dev_gold_graphs, dev_pred_graphs, dev_sent_ids,
dev_tokens)7.1.4 在测试集上的测试
# test set
progress = tqdm.tqdm(total=test_batch_num, ncols=75,
desc='Test {}'.format(epoch))
test_gold_graphs, test_pred_graphs, test_sent_ids, test_tokens = [], [], [], []
for batch in DataLoader(test_set, batch_size=config.eval_batch_size, shuffle=False,
collate_fn=test_set.collate_fn):
progress.update(1)
# 预测测试集
graphs = model.predict(batch)
if config.ignore_first_header:
for inst_idx, sent_id in enumerate(batch.sent_ids):
if int(sent_id.split('-')[-1]) < 4:
graphs[inst_idx] = Graph.empty_graph(vocabs)
# 清理图结构
for graph in graphs:
graph.clean(relation_directional=config.relation_directional,
symmetric_relations=config.symmetric_relations)
test_gold_graphs.extend(batch.graphs)
test_pred_graphs.extend(graphs)
test_sent_ids.extend(batch.sent_ids)
test_tokens.extend(batch.tokens)
progress.close()
test_scores = score_graphs(test_gold_graphs, test_pred_graphs,
relation_directional=config.relation_directional)
7.2 记录结果,并且获取最优的模型得分
test_scores = score_graphs(test_gold_graphs, test_pred_graphs,
relation_directional=config.relation_directional)
if best_dev_role_model:
save_result(test_result_file, test_gold_graphs, test_pred_graphs,
test_sent_ids, test_tokens)
# 将结果记录,并且写入日志文件
result = json.dumps(
{'epoch': epoch, 'dev': dev_scores, 'test': test_scores})
with open(log_file, 'a', encoding='utf-8') as w:
w.write(result + '\n')
print('Log file', log_file)
# 从日志文件中获取角色任务的最佳得分
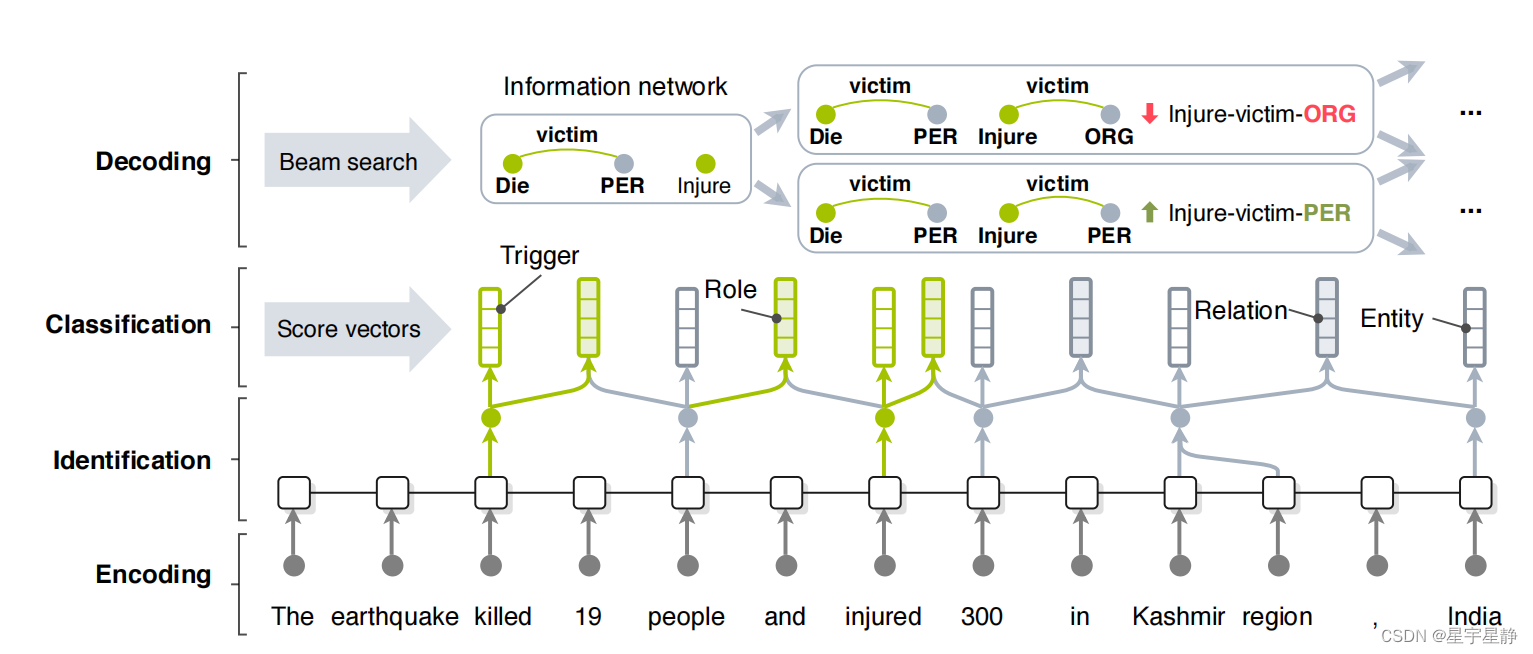
best_score_by_task(log_file, 'role')以上就是训练的全过程,我十分详细的介绍了所有其网络模型如下,可以由介绍结合图示观看。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











