






Html实体编码
1.数字表示法
实体编码如名字一样,因为在编写Html时会有正常情况无法输入的字符,比如空格之类的。所以采用字符的数字表示法和实体表示法,来表示正常情况无法输入的字符,用以逃脱了浏览器的限制
由于一些原因,HTML 语言并不能显示所有的Unicode编码,所以为了解决问题,HTML使用 Unicode 码点表示字符,这样浏览器会自动将码点转成对应的字符。其中Unicode编码简称万国码,它的字符长度不可变长,一个英文占1个字节,一个汉字占3个字节,UTF-8 编码作为 Unicode字符集的一种表达方式,即为可变长的Unicode码。
每个字符有一个 Unicode 号码,称为码点(code point)。如果知道码点,那么就能查到这是什么字符。
字符的码点表示法主要有以下两种:
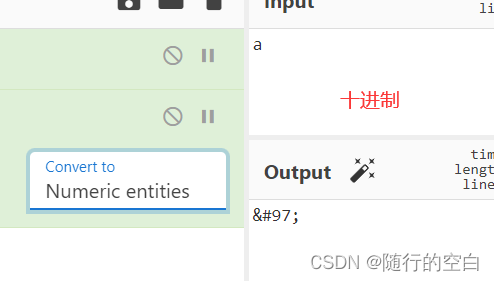
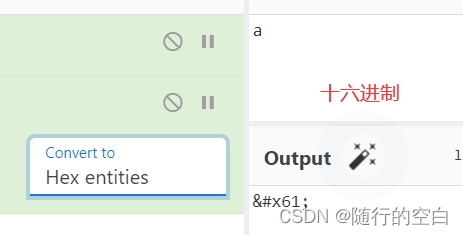
&#N;(十进制,N代表码点&#xN;(十六进制,N代表码点)
比如,字符a可以写成a(十进制),a(十六进制),\u0061;(十六进制),浏览器会自动转换它们。
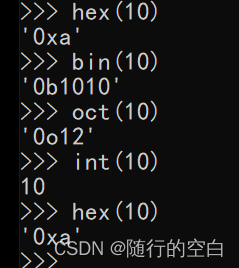
注意:进制对应(python演示)
bin 二进制
oct 八进制
int 十进制
hex 十六进制
2.实体表示法
HTML 为一些特殊字符,规定了容易记忆的名字,实体的写法是&name;,其中的name是字符的名字。
<:<>:>":"':'&:&©:©#:#§:§¥:¥$:$£:£¢:¢%:%*:$ast;@:@^:^±:±- 空格:
Url编码
URL 是“统一资源定位符”(Uniform Resource Locator)的首字母缩写,中文译为“网址”,表示各种资源的互联网地址
URL 的各个组成部分,只能使用以下这些字符。
-
26个英语字母(包括大写和小写)
-
10个阿拉伯数字
-
连词号(
-) -
句点(
.) -
下划线(
_)
URL 字符转义的方法是,是在字符的十六进制 ASCII 码前面加上百分号(%)
!:%21#:%23$:%24&:%26':%27(:%28):%29*:%2A+:%2B,:%2C/:%2F::%3A;:%3B=:%3D?:%3F@:%40[:%5B]:%5D空格:%20
字符转义在实现网页上的一些绕过时必不可少,举例来说,有一个网页的 URL 是foo?bar.html,即文件里面包含一个问号,那么需要写成foo%3Fbar.html。
URL 的合法字符,其实也可以采用这种转义方法,但是不建议使用。比如,字母a的十六进制 ASCII 码是61,转义形式后就是%61。因此,www.apple.com又可以写成www.%61pple.com,浏览器一样识别。
补充:
Url由协议、主机、端口、路径、查询参数以及锚点组成
协议端口
其中主要协议端口如下:
http -> 80
https -> 443
ftp -> 20 21
telnet -> 23
ssh -> 22
DNS -> 53
dhcp -> 67 68
pop3 -> 110
ladp(域控制器) -> 389
mysql 3306
sqlserver-> 1433
Oracle -> 1521
windows远程连接 -> 3389
redis nosql -> 6379















 6136
6136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









