







Huffman编码
实验目的
- 掌握二元Huffman编码的方法
- 了解Huffman编码效率以及冗余度的计算方法
- 了解用python实现Huffman编码的方法
实验要求
- 要求输入为信源符号的概率分布以及信源符号数,同时要验证输入是否为概率分布。
- 输入各个符号的Huffman编码。
- 要求计算出编码效率以及冗余度。
实验环境
| 项目 | 型号 |
|---|---|
| 电脑型号 | Lenovo Legion R7000 2020 |
| CPU | AMD Ryzen 5 4600H |
| 显卡 | LuminonCore/AMD Raden/NVIDIA GeForce |
| IDE | PyCharm 2022.1.3 |
| Python | Python 3.8 |
实验原理
Huffman编码介绍
Huffman编码是可变字长编码(VLC)的一种。Huffman编码是Huffman于1952年提出的一种编码方法,该方法依赖于字符出现的概率来构造异字头的平均码长最短的码字。他充分利用了信源概率分布的特性进行编码,是一种最佳的逐个符号的编码方法。
二元Huffman编码步骤
-
将 q q q个信源符号按概率分布 P ( s i ) P(s_i) P(si)大小,以递减次序排列起来,设:
p 1 ≥ p 2 ≥ p 3 ≥ . . . ≥ p q p_1 \geq p_2 \geq p_3 \geq ... \geq p_q p1≥p2≥p3≥...≥pq -
用0和1码符号分别分配给概率最小的两个信源符号,并将这两个概率最小的信源符号合并成一个新符号,并用这两个最小概率之和作为新符号的概率,从而得到只包含 q − 1 q-1 q−1个符号的新信源,称为S信源的缩减信源 S 1 S_1 S1。
-
把缩减信源 S 1 S_1 S1的符号仍按概率大小以递减次序排列,再将其最后两个概率最小的符号合并成一个新符号,并分别用0和1表示,这样又缩减成了 q − 2 q-2 q−2个符号的缩减信源 S 2 S_2 S2。
-
依次进行下去,直至缩减信源最后只剩下两个信源为止。将这最后两个符号分别用0和1码符号表示。最后这两个符号的概率和必为1.
-
然后从最后一级缩减信源开始,依编码路径由后向前返回,就得出各信源符号对应的码符号序列。
Huffman编码的特点
- Huffman编码是最优码,且一定是紧致码。
- Huffman码不唯一,但平均码长相等。
- Huffman的不同编码虽然码长相等,但方差不相等。
Huffman编码效率
平均码长:
L
ˉ
=
∑
i
=
1
q
P
(
s
i
)
l
i
\bar{L}=\sum_{i=1}^q P(s_i)l_i \quad
Lˉ=i=1∑qP(si)li
编码效率:
η
=
H
(
s
)
/
L
ˉ
\eta=H(s)/\bar{L}
η=H(s)/Lˉ
Huffman编码冗余度
r = 1 − η r=1-\eta r=1−η
实验内容
概述
本次实验主要分为两个部分,分别为;
- 对给定概率分布进行Huffman编码,并解码(Huffman)。
- 拓展实验:对实际文本进行Huffman编码压缩,并解码(HuffmanPro)。
内容分析
Huffman
首先构造一个二叉树节点类,用于存放各节点之间的关系和节点概率值,该节点类有如下几个属性。
| 成员 | probValue | prev | leftChild | rightChild |
|---|---|---|---|---|
| 说明 | 字符的概率 | 当前状态 | 左孩子 | 右孩子 |
然后利用上述构建的Node类构造Huffman树,并生成Huffman编码表。
| 成员 | 说明 |
|---|---|
| getProbDist() | 获得各符号概率分布节点 |
| creHuffTr() | 构建Huffman树 |
| huffEncoding() | 对符号进行Huffman编码 |
| HuffDecoding() | 对编码所得码符号进行解码 |
| average_code_length() | 计算码符号平均长度 |
| CodingEfficiency() | 计算编码效率 |
该部分步骤如下:
-
初始化各节点参量(具体见附件)。
-
获得各符号概率分布节点,并验证是否输入为概率分布
-
构建Huffman树,对信源符号按概率进行排序,并实现各层概率最小的两个信源符号进行合并,然后重新排序。依照此步骤反向建立Huffman树
-
对符号进行Huffman编码。开辟一个长度等于信源符号数的编码列表,用于存放各符号编码。然后对每一个符号沿着刚才建立的Huffman编码树获取编码结果,终止条件为到达树的根节点。过程中通过函数is_left()判断是编码为1或者为0.
-
对编码所得码符号进行解码。先获得Huffman编码树,然后一次遍历输入的编码序列,从根节点出发,沿着路径找到对应的叶子节点,获取对应的概率值。
-
计算码符号平均长度
-
计算编码效率
最后,输入数据,并调用该类中的方法,进而对Huffman编码进行测试,步骤如下:
- 先输入概率分布值和信源符号个数,同时判断概率值个数是否和信源符号数对应,以及概率分布是否有效。
- 如果相对应,则构建Huffman编码树,调用各方法,获得概率分布的编码,并计算编码效率和冗余度。接着对编码后的结果进行解码。
- 如果不对应,输出“个数不对等”。
HuffmanPro
在这一部分,我通过分析实际数据,对实际文本进行Huffman编码。这里,我选择的文本为英文版的HarryPotter.txt(节选)。由于在该部分考虑了实际的信源符号,所以部分方法和属性进行了改进。
首先构造一个类,用作二叉树的节点。
| 成员 | 说明 |
|---|---|
| name | 信源符号 |
| value | 信源符号个数 |
| left | 左孩子 |
| right | 右孩子 |
在该类Node中,添加了name属性,用于保存信源符号。同时,由于python计算精度问题,将概率分布替换为信源符号频数。
接着,构建Huffman类,其包含的属性方法如下:
| 成员 | 说明 |
|---|---|
| init() | 初始化各属性值 |
| createHuff() | 构建Huffman树 |
| get_code() | 获得编码结果 |
该部分步骤如下:
-
初始化Huffman树的结构,原理第一个构建的Huffman类,同时对代码结构进行了优化。同时在该部分初始化了相关属性值,比如编码缓存器Buffer,以及存放编码和信源符号的ltrs、name。
-
在这一部分,依据递归的思想,生成编码结果。程序从构建的Huffman树的根节点开始,通过递归,依次遍历其左孩子节点以及右孩子节点,知道节点为空,即到达叶子节点。在每一次遍历完成后,将遍历结果。即编码结果按顺序添加到编码列表ltrs,同时将对应的信源符号添加到信源符号列表names。
-
在该部分,调用递归createHuff(),并将所得的编码列表以及信源符号列表合并成一个码本字典,即dictionary。
最后,我们要在主程序中完成对Harry Potter.txt的编码和解码工作。
其中第一步,读取HarryPotter.txt文件,并对文件中的符号进行分割,并对分割的结果通过函数collections.Counter()进行词频统计得到对应的词频字典。然后将词频字典转换为元素为元组类型的列表,并将该列表输入,构建Huffman树。接着,输入HarryPotter.txt文件,通过构建的Huffman树对其进行编码,并将编码结果保存在modeOutput.txt文件中。
第二步,便是对我们的编码结果进行解码,进而重建出原文本。解码时,由于Huffman编码满足字首性,所以我们可以从modeOutput.txt首依次读取01字符,并将字符存入缓存器buffer,若与码本中的编码结果匹配,则输出,并清空缓存器,若不匹配,继续读取。最后将解码结果存入文件output.txt。
实验结果
Huffman
输入
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o1mF6Yd0-1667480496867)(C:\Users\32534\AppData\Roaming\Typora\typora-user-images\image-20221024161326237.png)]](https://i-blog.csdnimg.cn/blog_migrate/be754d48d0fd38e06e00534b4012a966.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lWo3g0SA-1667480406001)(C:\Users\32534\AppData\Roaming\Typora\typora-user-images\image-20221025104226190.png)]](https://i-blog.csdnimg.cn/blog_migrate/8b4d4135ebe8b6c63a485f9dfe38d15a.png)
构建Huffman树的节点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P3TT0EPi-1667480406002)(C:\Users\32534\AppData\Roaming\Typora\typora-user-images\image-20221024161426351.png)]](https://i-blog.csdnimg.cn/blog_migrate/ff16d985539fb693f65ac44eb41282c1.png)
输出

HuffmanPro
-
编码输入
此程序的输入为HarryPotter.txt(见附件1)
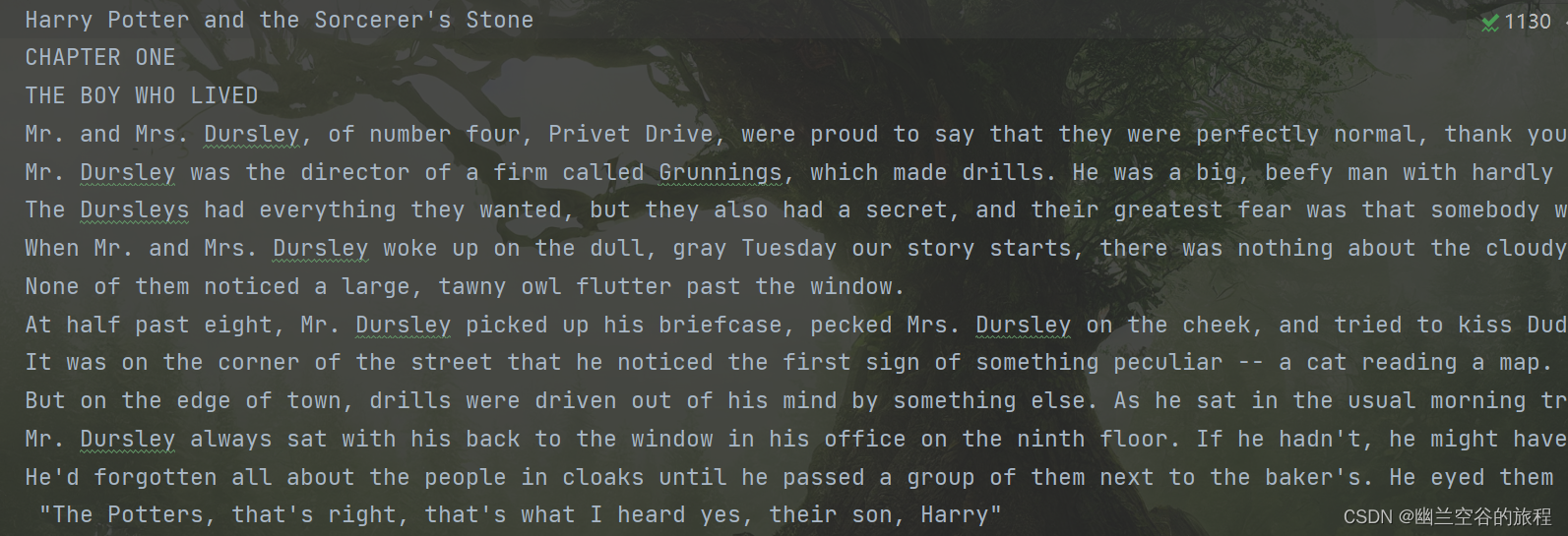
(部分截图)
-
编码输出
- 码本输出(见附件2)

-
编码结果输出(见附件3)

(部分截图)
-
解码输出
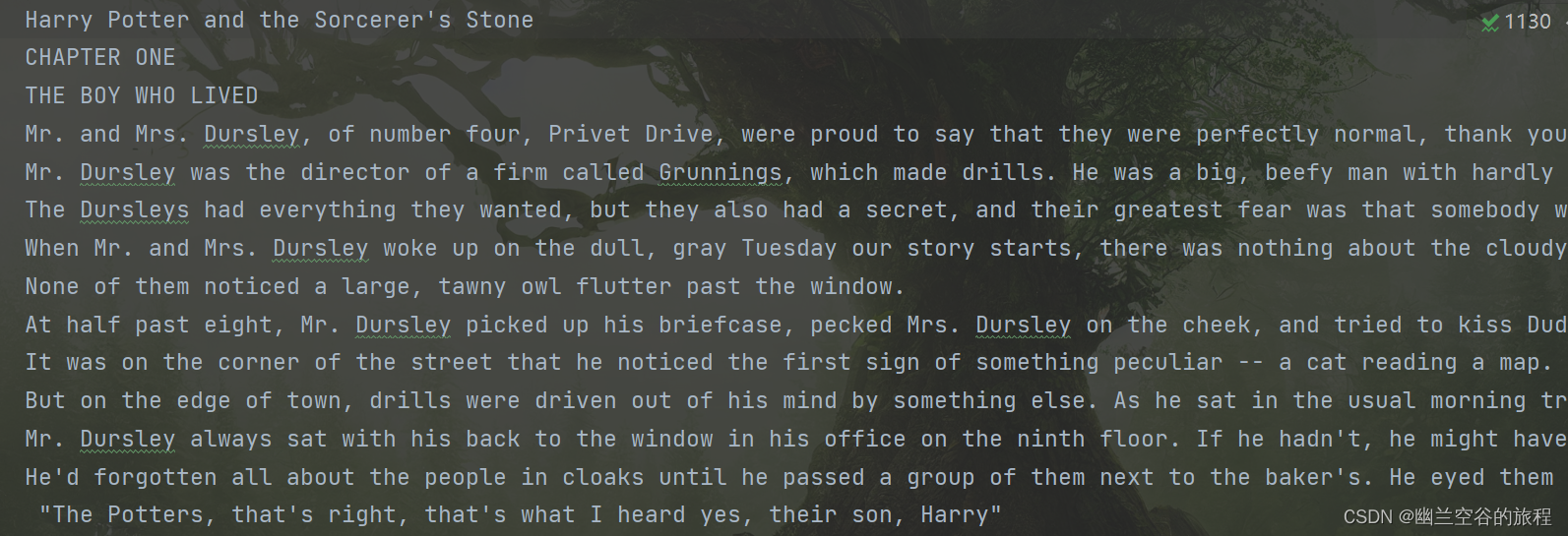
(部分截图)
- 编码前后字节数
| 编码前 | 编码后 |
|---|---|
| 442KB | 250KB |
(由于编码所得结果为txt文档,文档仍为ASCII编码,所以该处编码后字节数是根据编码所得0、1个数除以8除以1024所得)
实验结论
通过实验可以得出以下结论:
- 由于Huffman编码是基于概率分布,其核心在于对于出现概率高的信源编为短码,对于出现概率低的信源编为长码。因此Huffman对于信源符号概率分布不均匀的信源压缩效果较好,而对于信源符号概率分布较为均匀的信源,由于冗余度本身较低,其压缩空间不大,压缩效果较次。所以,对压缩过的文件进行再次压缩意义不大。
- 我们可以定义树结构,通过树结构中父节点与子节点的关系,将Huffman树表示出来,并实现概率的合并,编码与解码。
- 尽管Huffman编码的思想比较简单,但编码的复杂度较高。而且虽然平均码长可以达到最小,但是如果采取上述实验保存码表的方式,则会造成码表内存过大,不利于传输。
实验总结
通过Huffman编码实验,可以从实际操作上了解到Huffman编码有着较高的编码效率。同时可以通过调整理想概率分布,得出Huffman编码在怎样的条件下才能达到较高的编码效率。在对实际文本编码的过程中,体验到了Huffman编码在实际压缩中的应用。
但是,在实际做实验的时候,可以看到,我们在对编码后文件进行传输的时候,必须将码本一并存入压缩文件。但这就带来一个问题,码本应该怎么存储。我在实验中采取明文存储的方式,即将符号对应的编码保存为字典的形式。但由于保存字典的文件采用的是ASCII编码方式,这就导致最终码表存储的文件较大。通过查阅资料,可知有以下改进方案:范式Huffman编码,然后其码表存储采取范式Huffman的码表存储。
总之,通过实验体会到了信息论在实际生活中的应用,对这门课程有了更深的理解。
附件
代码Huffman.py
import math
class Node:
def __init__(self,probabilityValue):
self.probValue=probabilityValue
self.prev = None
self.leftChild=None
self.rightChild=None
def is_left(self):
return self.prev.leftChild==self
class huffman:
def __init__(self):
self.nodes=None
self.nodesHuff=None
self.sumOfProbs=0
self.temp=None
self.symbols=None
self.probs=None
def getProbDist(self,symbols,probs):
#type(symbols)==list and type(symbols)==list:
self.symbols=symbols
self.probs=probs
for pro in self.probs:
self.sumOfProbs+=pro
if int(self.sumOfProbs)==1:
self.nodes=[Node(prob) for prob in self.probs]
return self.nodes
else:
raise ValueError("概率和需为1")
def creHuffTr(self):
print(self.nodes)
self.nodesHuff=self.nodes[:]
while len(self.nodesHuff)!=1:
self.nodesHuff.sort(key=lambda object:object.probValue)
nodeLeft=self.nodesHuff.pop(0)
nodeRight=self.nodesHuff.pop(0)
nodeFather=Node(nodeLeft.probValue+nodeRight.probValue)
nodeFather.leftChild=nodeLeft
nodeFather.rightChild=nodeRight
nodeLeft.prev=nodeFather
nodeRight.prev=nodeFather
self.nodesHuff.append(nodeFather)
self.nodesHuff[0].prev=None
return self.nodesHuff[0]
def huffEncoding(self,huff):
coding=['']*len(self.nodes)
for i in range(len(self.nodes)):
temp=self.nodes[i]
print(temp)
while temp!=huff:
if temp.is_left():
coding[i]='1'+coding[i]
else:
coding[i]='0'+coding[i]
temp=temp.prev
return self.symbols,coding
def HuffDecoding(self,code,huff):
temp=huff
for i in range(len(code)):
if temp.leftChild!=0:
if code[i]=='1':
temp=temp.leftChild
else:
temp=temp.rightChild
return temp.probValue
# 计算平均码长
def average_code_length(self,values, codes):
a = 0.0
for i in range(len(codes)):
b = values[i] * len(codes[i])
a += b
return a
def CodingEfficiency(self,values,l):
a = 0.0
for i in range(len(values)):
b = values[i] * math.log(values[i], 2)
a -= b
a1=a/l
return a1
val=list(map(float,input("请输入概率分布:").split()))
#0.40 0.18 0.10 0.10 0.07 0.06 0.05 0.04
#0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125
num=int(input("信源符号个数:"))
#values = [0.40,0.18,0.10,0.10,0.07,0.06,0.05,0.04]
huff=huffman()
print(len(val))
if len(val)==num:
huff.getProbDist(['a','b','c','d','e','f','d','f'],val)
huff1=huff.creHuffTr()
symbol,codes=huff.huffEncoding(huff1)
for i in range(len(symbol)):
print("symbol:{0}'s encoding is {1}".format(symbol[i],codes[i]))
print('\n')
print("平均码长为:",huff.average_code_length(val,codes))
print("编码效率为:",huff.CodingEfficiency(val,huff.average_code_length(val,codes)))
print("冗余度为:",1-huff.CodingEfficiency(val,huff.average_code_length(val,codes)))
print('\n')
for i in range(len(val)):
value = codes[i]
decoding = huff.HuffDecoding(value, huff1)
print("code:'{0}''s decoding is {1}".format(value, decoding))
else:
print("个数不对等")
代码HuffmanPro.py
class Node:
def __init__(self,name=None,value=None):
self.name=name
self.value=value
self.left=None
self.right=None
class Huffman(object):
def __init__(self,characterSet):
valueSum=0
for character in characterSet:
valueSum+=character[1]
if True:#abs(valueSum-1)<=0.01
self.nodes = [Node(character[0], character[1]) for character in characterSet]
self.huffmanTree = self.nodes[:]
while len(self.huffmanTree) != 1:
self.huffmanTree.sort(key=lambda object:object.value,reverse=True)
left = self.huffmanTree.pop(-1)
right = self.huffmanTree.pop(-1)
current = Node(value=(left.value + right.value))
current.left = left
current.right = right
self.huffmanTree.append(current)
self.root=self.huffmanTree[0]
self.Buffer = list(range(19))
# else:
# raise ValueError("概率和需为1")
#self.huffmanTree=None
self.ltrs = []
self.names = []
def createHuff(self,tree,leng):
node = tree
if not node:
return
elif node.name:
print(node.name + ' encoding:', end='')
ltr=''
dictionary = dict()
for i in range(leng):
print(self.Buffer[i], end='')
ltr=ltr+str(self.Buffer[i])
print('\t')
self.names.append(node.name)
self.ltrs.append(ltr)
return
self.Buffer[leng] = 0
self.createHuff(node.left, leng + 1)
self.Buffer[leng] = 1
self.createHuff(node.right, leng + 1)
# 生成哈夫曼编码
def get_code(self):
self.createHuff(self.root, 0)
print(self.ltrs)
print(self.names)
dictionary = dict(zip(self.names, self.ltrs))
print(dictionary)
return dictionary
from collections import Counter
import math
if __name__=='__main__':
###############################编码#####################
#输入的是字符及其频数
l=list()
with open("/Predictive coding/001.txt","r") as f:
data=f.read()
for i in data:
l.append(i)
#print(l)
word=Counter(l)
#print(word)
k=[]
for type,value in word.items():
k.append((type,value))
print(k)
#test=[('a',5),('b',3),('c',10),('d',8),('f',12),('g',2)]
sum_k=0
for i in range(len(k)):
a=k[i][1]
sum_k=sum_k+a
k_freq=[]
for i in range(len(k)):
k_freq.append((k[i][0],k[i][1]/sum_k))
tree=Huffman(k)
modeDict=tree.get_code()
#########################指标计算#########################
sum_l=0
for i in k_freq:
b=len(modeDict[i[0]])
c=b*i[1]
sum_l+=c
print("平均码长sum_l=",sum_l)
hs=0.0
for i in k_freq:
b = i[1] * math.log(i[1], 2)
hs-=b
print("编码效率:",hs/sum_l)
######################解码################################
code=''
with open("/Predictive coding/002.txt", "w") as f:
for i in l:
f.write(modeDict[i])
code+=modeDict[i]
#f.write('0'*25)
output=''
buffer=''
for i in code:
buffer+=i
for (type,value) in modeDict.items():
if value==buffer:
output+=type
buffer=''
break
#print(output)
#pbar = tqdm(total=int(len(output/1000)))
#print(output)
with open('/Predictive coding/003.txt', 'w') as g:
g.write(output)
with open('modeOutput.txt', 'r') as h:
d=h.read()
print(len(d))

















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









