







实验二 预测分析算法的设计与实现
一、实验目的
通过预测分析算法的设计与实现,加深对自上而下语法分析方法的理解,尤其是对自上而下分析条件的理解。
二、实验内容
输入文法及待分析的输入串,输出其预测分析过程及结果。
- 参考数据结构
(1)/定义产生式的语法集结构/
typedef struct{
char formula[200];//产生式
}grammarElement;
grammarElement gramOldSet[200];//原始文法的产生式集
(2)/变量定义/
char terSymbol[200];//终结符号
char non_ter[200];//非终结符号
char allSymbol[400];//所有符号
char firstSET[100][100];//各产生式右部的FIRST集
char followSET[100][100];//各产生式左部的FOLLOW集
int M[200][200];//分析表 - 判断文法的左递归性,将左递归文法转换成非左递归文法。(该步骤可以省略,直接输入非左递归文法)。
- 根据文法求FIRST集和FOLLOW集。
(1)/求 First 集的算法/
(2)/求 FOLLOW 集的算法/
-
构造预测分析表。
-
构造总控程序。
程序流程图如下图1所示:
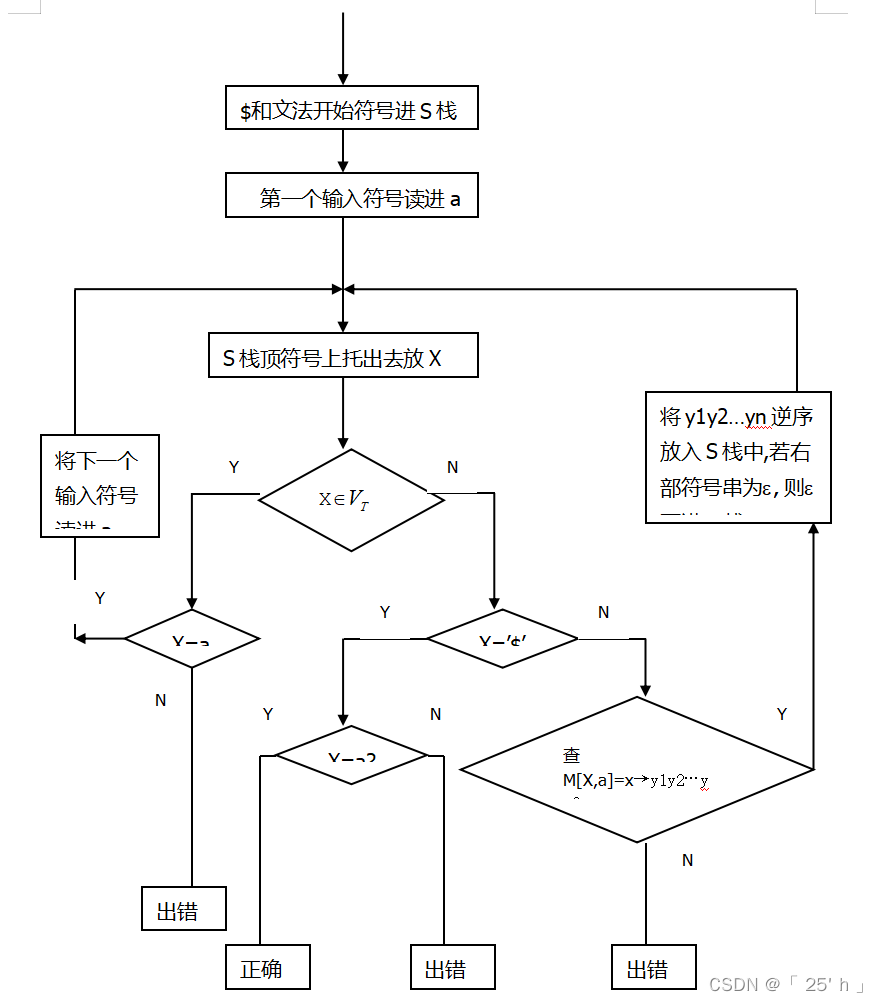
- 对给定的输入串,给出分析过程及结果。
package StringToJAVA;
import java.io.*;
import java.util.*;
/**
* @author [25'h]
* @datetime 2022.10.28
* 注意:程序中将ε默认为终结符,在输入的文本文件中需要标出
*/
public class Parsing {
public static String startLabel;//开始符
public static ArrayList<String> terSymbol = new ArrayList<>();// 终结符
public static ArrayList<String> non_ter = new ArrayList<>();// 非终结符
public static HashMap<String, List<String>> formula = new HashMap<>();//产生式
public static HashMap<String, HashMap<String, String>[]> firstAndFollow = new HashMap<>();//FIRST 和 FOLLOW
/*
firstAndFollow的数据含义:
- key : 非终结符
- value : 非终结符对应的FIRST 和 FOLLOW 集及其产生原因的产生式右部
- 1 非终结符对应的FIRST
- key FIRST集
- value FIRST集的产生右部
- 2 非终结符对应的FOLLOW
- key FOLLOW集
- value 无意义
*/
public static boolean[] booleansFirst;// 辅助变量
public static boolean[] booleansFollow;
public static String objString;// 目标匹配字符串
public static void main(String[] args) {
File file = new File("src/StringToJAVA/test3.txt");
BufferedReader bufferedReader;
try {
// 读取文法和目标式子
bufferedReader = new BufferedReader(new FileReader(file));
startLabel = bufferedReader.readLine();
// 读取非终结符
non_ter.addAll(Arrays.asList(bufferedReader.readLine().split(" ")));
booleansFirst = new boolean[non_ter.size()];// 初始化辅助变量
booleansFollow = new boolean[non_ter.size()];
// 初始化firstAndFollow中的Map对象
for (String s : non_ter) {
firstAndFollow.put(s, new HashMap[]{new HashMap<String, String>(), new HashMap<String, String>()});
}
// 读取终结符
terSymbol.addAll(Arrays.asList(bufferedReader.readLine().split(" ")));
//将产生式右部或表达式分离
String s;
while ((s = bufferedReader.readLine()).contains("->")) {
String[] split = s.split("->");
formula.put(split[0], Arrays.asList(split[1].split("\\|")));
}
objString = s;
generateFirstSET();// 生成FIRST集
generateFollowSET();// 生成FOLLOW集
show();// 显示FIRST和FOLLOW信息
match();// 匹配
} catch (Exception e) {
e.printStackTrace();
}
}
private static void match() {
System.out.println("\n匹配过程");
int index = 0;//objString匹配位置标记
Stack<String> stack = new Stack<>();
stack.push("#");
stack.push(startLabel);
while (!stack.isEmpty()) {
showDetail(stack, index);
String peek = stack.peek();
String sub = objString.substring(index, index + 1);
if (peek.equals("#") && sub.equals("#")) break;//到结尾符号了
if (peek.equals("#")) throw new RuntimeException("匹配错误");// 堆栈到结尾了,objString没有到
// 注意:"#"符号绝不能进入下面的程序,会将"#"识别为非终结符,造成空指针
if (terSymbol.contains(peek)) {// 若栈顶为终结符,必须匹配,否则出错
if (peek.equals(sub)) {// 成功匹配
index++;
stack.pop();
} else {
throw new RuntimeException("匹配错误");
}
} else {// 栈顶为非终结符
HashMap<String, String>[] hashMaps = firstAndFollow.get(peek);// 去除该非终结符的FIRST和FOLLOW集
String s = hashMaps[0].get(sub);// 非终结符peek和sub组合需要的产生式为s
if (s != null) {// 不为空就反向压入栈中
stack.pop();
for (int i = s.length() - 1; i >= 0; i--) {
stack.push(s.substring(i, i + 1));
}
} else {// s为空说明FIRST没有sub,就需要判断peek的FIRST集中是否存在空,这样可以进一步查看FOLLOW是否存在sub
if (hashMaps[0].containsKey("空")) {//peek的FIRST集中存在空
if (hashMaps[1].containsKey(sub)) {//FOLLOW集中存在sub,就用FIRST中产生空的产生式
String ve = hashMaps[0].get("空");//FIRST中产生空的产生式
stack.pop();
//将替换掉peek换成产生式ve,注意若是空,则跳过
for (int i = ve.length() - 1; i >= 0; i--) {
String substring = ve.substring(i, i + 1);
if (!substring.equals("空")) {
stack.push(substring);
}
}
} else {
throw new RuntimeException("匹配错误");
}
} else {
throw new RuntimeException("匹配错误");
}
}
}
}
System.out.println("成功");
}
/**
* @param stack 堆栈中现在的状态
* @param index 匹配到objString的第index个字符了
* 显示匹配过程信息
*/
private static void showDetail(Stack<String> stack, int index) {
StringBuffer buffer= new StringBuffer();
for (String s : stack) {
buffer.append(s);
}
System.out.printf("%-10s%-10s", buffer.toString(), objString.substring(index));
System.out.println();
}
/**
* 生成FOLLOW集
*/
private static void generateFollowSET() {
firstAndFollow.get(startLabel)[1].put("#", null);// 起始符FOLLOW定有"#"
for (String s : non_ter) {//对于每一个非终结符
if (!booleansFollow[non_ter.indexOf(s)])// 没有计算过就计算
generateEveryFollowSET(s);
}
}
/**
* @param curNonTer 当前计算Follow的非终结符
*/
public static void generateEveryFollowSET(String curNonTer) {
//s左部
for (String s : formula.keySet()) {
// 对于每一个右部
for (String eachRight : formula.get(s)) {
//右部不存在该非终结符
if (!eachRight.contains(curNonTer)) continue;
modifyFollow(curNonTer, s, eachRight);
}
}
booleansFollow[non_ter.indexOf(curNonTer)] = true;
}
/**
* @param curNonTer FOLLOW 目标非终结符
* @param left 左部
* @param eachRight 右部
*/
private static void modifyFollow(String curNonTer, String left, String eachRight) {
int index = eachRight.indexOf(curNonTer);// 目标非终结符所在索引
if (index == eachRight.length() - 1) {//若curNonTer在右部最后,添加FOLLOW(left)--->FOLLOW(curNonTer)
if (left.equals(curNonTer)) return;//若一样,没必要算,算了就会死递归
if (!booleansFollow[non_ter.indexOf(left)]) {//未计算过,就先计算
generateEveryFollowSET(left);
}
firstAndFollow.get(curNonTer)[1].putAll(firstAndFollow.get(left)[1]);
} else {// 若curNonTer不在右部最后
if (terSymbol.contains(eachRight.substring(index + 1, index + 2))) {// 紧接的后面是终结符
firstAndFollow.get(curNonTer)[1].put(eachRight.substring(index + 1, index + 2), null);
} else {//紧接的后面是非终结符
func(curNonTer, left, eachRight, index + 1);
}
}
}
/**
* @param curNonTer FOLLOW 目标非终结符
* @param left 当前产生式左部
* @param eachRight 当前产生式右部
* @param index 当前计算位置标记
*/
private static void func(String curNonTer, String left, String eachRight, int index) {
HashMap<String, String> curFollow = firstAndFollow.get(curNonTer)[1];
if (eachRight.length() == index) {// eachRight中curNonTer后均是非终结符,且其中的所有非终结符均能推导出空,成功到了最后,就可以将左部的FOLLOW添加进来
if (left.equals(curNonTer)) return;
if (!booleansFollow[non_ter.indexOf(left)]) {// 未计算过,就先计算
generateEveryFollowSET(left);
}
curFollow.putAll(firstAndFollow.get(left)[1]);
return;
}
String sub = eachRight.substring(index, index + 1);// eachRight中curNonTer后的字符依次取出
if (terSymbol.contains(sub)) {// 终结符
curFollow.put(sub, null);
return;
}
// 不能添加空
if (curFollow.containsKey("空")) {
curFollow.putAll(firstAndFollow.get(sub)[0]);
} else {
curFollow.putAll(firstAndFollow.get(sub)[0]);
curFollow.remove("空");
}
// eachRight中curNonTer后的非终结符能推出空
if (firstAndFollow.get(sub)[0].containsKey("空")) {
func(curNonTer, left, eachRight, index + 1);
}
}
/**
* 生成FIRST集
*/
public static void generateFirstSET() {
for (String s : non_ter) {
if (!booleansFirst[non_ter.indexOf(s)])
generateEveryFirstSET(s);
}
}
/**
* @param curNonTer 生成curNonTer的FIRST集
*/
public static void generateEveryFirstSET(String curNonTer) {
List<String> list = formula.get(curNonTer);// 所有右部
HashMap<String, String> curFirst = firstAndFollow.get(curNonTer)[0];//先将curNonTer的FIRST集提出来
for (String eachRightFormula : list) {// 对于每一个右部
String firstChar = eachRightFormula.substring(0, 1);//第一个终结符或者非终结符
if (terSymbol.contains(firstChar)) {//是终结符
curFirst.put(firstChar, eachRightFormula);
} else {//非终结符号
modify(firstAndFollow.get(curNonTer)[0], curNonTer, eachRightFormula, 0);
}
}
booleansFirst[non_ter.indexOf(curNonTer)] = true;
}
/**
* @param curFirst curNonTe的FIRST集
* @param curNonTer FIRST 目标非终结符
* @param eachRightFormula 产生式右部
* @param index 处理的位置索引
* 产生式右部从左边开始的非终结符进行逐步递归处理
*/
public static void modify(HashMap<String, String> curFirst, String curNonTer, String eachRightFormula, int index) {
if (index >= eachRightFormula.length()) {//所有的符号均为非终结符,并且均可推出空(可以说是FIRST中有空)
curFirst.put("空", eachRightFormula);// 添加空
return;
}
String firstChar = eachRightFormula.substring(index, index + 1);// 处理的当前的非终结符
if (firstChar.equals(curNonTer)) return;// 防止死递归
if (!booleansFirst[non_ter.indexOf(firstChar)]) {// 未存在,先处理
generateEveryFirstSET(firstChar);
}
// 不是最后不能添加firstAndLast.get(firstChar)[0]中的空
// 注意这里只需要添加键值,value不能添加,需要赋值当前产生式右部,在创建FOLLOW时并不用,因为FOLLOW的value用不到,随意赋值
if (curFirst.containsKey("空")) {
for (String s : firstAndFollow.get(firstChar)[0].keySet()) {
curFirst.put(s, eachRightFormula);
}
} else {
for (String s : firstAndFollow.get(firstChar)[0].keySet()) {
curFirst.put(s, eachRightFormula);
}
curFirst.remove("空");
}
// 若能推出空,就会持续向后扩展
if (firstAndFollow.get(firstChar)[0].containsKey("空")) {
modify(curFirst, curNonTer, eachRightFormula, index + 1);
}
}
public static void show() {
System.out.println("开始符号:" + startLabel);
System.out.println("非终结符:" + Arrays.toString(non_ter.toArray()));
System.out.println("终结符" + Arrays.toString(terSymbol.toArray()));
System.out.println("文法:");
for (String obj : formula.keySet()) {
System.out.println(obj + "--->" + Arrays.toString(formula.get(obj).toArray()));
}
System.out.println("\n非终结符号的FIRST和FOLLOW集:");
for (String s : firstAndFollow.keySet()) {
System.out.println(s + "\t" + Arrays.toString(firstAndFollow.get(s)[0].keySet().toArray()) + Arrays.toString(firstAndFollow.get(s)[1].keySet().toArray()));
}
System.out.println("\n每个非终结符的FIRST集对应的原因:");
for (String s : firstAndFollow.keySet()) {
System.out.println(s + "\t" + Arrays.toString(firstAndFollow.get(s)[0].values().toArray()));
}
}
}
示例
test2.txt:
E
E T A F B
+ * ( ) i 空
E->TA
A->+TA|空
T->FB
B->*FB|空
F->(E)|i
(i+i)#
输出:
"D:\Program Files\Java\jdk1.8.0_291\bin\java.exe" "-javaagent:D:\IntelliJ IDEA 2020.1\lib\idea_rt.jar=55037:D:\IntelliJ IDEA 2020.1\bin" -Dfile.encoding=UTF-8 -classpath "D:\Program Files\Java\jdk1.8.0_291\jre\lib\charsets.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\deploy.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\access-bridge-64.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\cldrdata.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\dnsns.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\jaccess.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\jfxrt.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\localedata.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\nashorn.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\sunec.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\sunjce_provider.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\sunmscapi.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\sunpkcs11.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\ext\zipfs.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\javaws.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\jce.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\jfr.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\jfxswt.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\jsse.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\management-agent.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\plugin.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\resources.jar;D:\Program Files\Java\jdk1.8.0_291\jre\lib\rt.jar;D:\code_management\algorithm\out\production\algorithm" StringToJAVA.Parsing
开始符号:E
非终结符:[E, T, A, F, B]
终结符[+, *, (, ), i, 空]
文法:
A--->[+TA, 空]
B--->[*FB, 空]
T--->[FB]
E--->[TA]
F--->[(E), i]
非终结符号的FIRST和FOLLOW集:
A [空, +][), #]
B [*, 空][), +, #]
T [(, i][), +, #]
E [(, i][#, )]
F [(, i][), *, +, #]
每个非终结符的FIRST集对应的原因:
A [空, +TA]
B [*FB, 空]
T [FB, FB]
E [TA, TA]
F [(E), i]
匹配过程
#E (i+i)#
#AT (i+i)#
#ABF (i+i)#
#AB)E( (i+i)#
#AB)E i+i)#
#AB)AT i+i)#
#AB)ABF i+i)#
#AB)ABi i+i)#
#AB)AB +i)#
#AB)A +i)#
#AB)AT+ +i)#
#AB)AT i)#
#AB)ABF i)#
#AB)ABi i)#
#AB)AB )#
#AB)A )#
#AB) )#
#AB #
#A #
# #
成功
Process finished with exit code 0















 1076
1076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











