







参数估计——《概率论及其数理统计》第七章学习报告(点估计)
前言
拖更了好久了,最近一直在忙别的科目,emmm改在期末前做一下第七章的学习报告。
因为教学的设置原因,这次只做了第七章参数估计中的点估计,后续如果有机会会出一期完整版。
教程和之前一样,浙大第四版+第五版。
MindMap
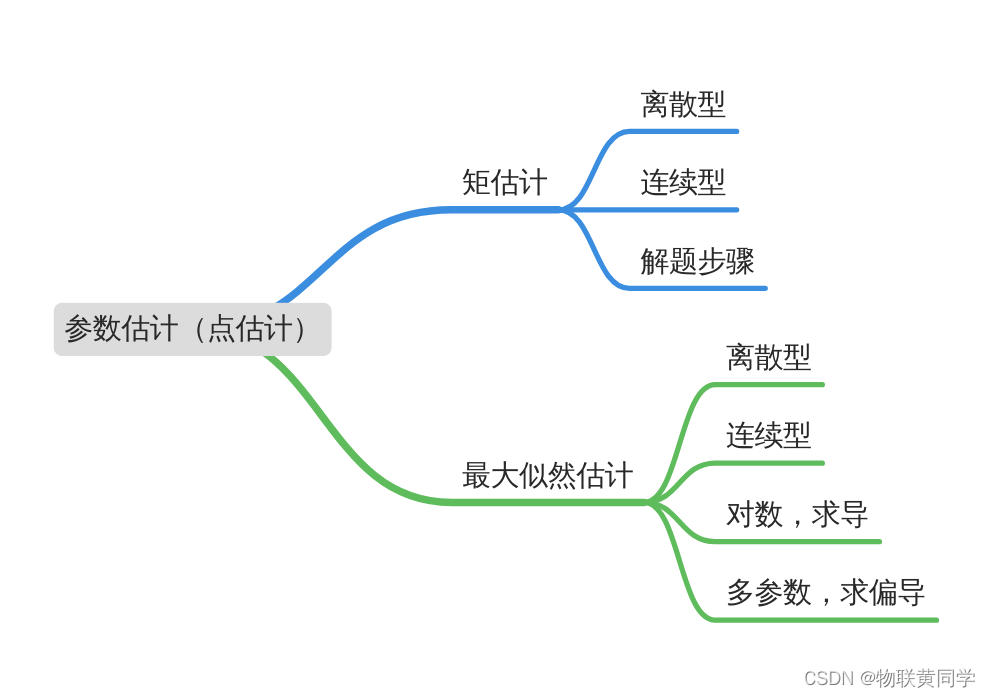
点估计分为 矩估计法 和 最大似然估计法 两种。
矩估计法
我们之前学过在第四章的时候接触过一点矩的相关知识,比如说原点矩、中心矩等。在这里,我们是用 样本矩 去估计 总体矩, 然后从而对相关参数的估计。
我们根据随机变量 X 的类型,即离散型还是连续型,来做划分。
若X 为 离散型:
分
布
律
为
:
P
{
X
=
x
0
}
=
p
(
x
;
θ
1
,
θ
2
,
.
.
.
,
θ
k
)
,
这
里
的
θ
i
,
就
是
我
们
要
求
的
待
估
计
参
数
。
得
到
总
体
X
的
前
k
阶
矩
:
μ
l
=
E
(
X
l
)
=
∑
x
∈
R
x
x
l
p
(
x
;
θ
1
,
θ
2
,
.
.
.
,
θ
k
)
分布律为:P\{X=x0\} = p(x;\theta_1, \theta_2, ..., \theta_k), 这里的\theta_i,就是我们要求的待估计参数。 \\ 得到总体X 的前k阶矩:\mu_l = E(X^l) = \sum_{x\in R_x}{x^lp(x;\theta_1, \theta_2, ...,\theta_k)}
分布律为:P{X=x0}=p(x;θ1,θ2,...,θk),这里的θi,就是我们要求的待估计参数。得到总体X的前k阶矩:μl=E(Xl)=x∈Rx∑xlp(x;θ1,θ2,...,θk)
若是 连续型:
概
率
密
度
:
f
(
x
;
θ
1
,
θ
2
,
.
.
.
,
θ
k
)
μ
l
=
E
(
X
l
)
=
∫
−
∞
∞
x
l
f
(
x
;
θ
1
,
θ
2
,
.
.
.
,
θ
k
)
d
x
概率密度:f(x;\theta_1, \theta_2, ..., \theta_k) \\ \mu_l = E(X^l) = \int_{-\infty}^\infty{x^lf(x;\theta_1, \theta_2, ..., \theta_k)dx}
概率密度:f(x;θ1,θ2,...,θk)μl=E(Xl)=∫−∞∞xlf(x;θ1,θ2,...,θk)dx
而样本矩则为
A
l
=
1
n
∑
i
=
1
n
X
i
l
A_l = \frac{1}{n}\sum_{i = 1}^{n}{X_i^l}
Al=n1i=1∑nXil
所谓的矩估计法 就是用样本矩去作为总体矩的 估计量。
解决步骤
- 我们先列举出矩,这里列举矩的数量取决于我们待估计的参数的数量。
- 然后计算出参数的关于矩的式子。
- 用样本矩来替代上面的总体矩。
- 最后记得估计的参数上面记得加一个尖角标。
最大似然估计法
我们还是分离散和连续来讨论。
离散型
分布律
P
{
X
=
x
}
=
p
(
x
;
θ
)
,
θ
∈
Θ
设
X
1
,
X
2
,
.
.
.
,
X
n
的
一
个
样
本
值
,
我
们
可
以
知
道
X
i
,
i
∈
[
1
,
k
]
的
概
率
P\{X=x\} = p(x;\theta), \theta \in \Theta \\ 设X_1, X_2, ..., X_n 的一个样本值,我们可以知道 X_i,i\in [1, k]的概率
P{X=x}=p(x;θ),θ∈Θ设X1,X2,...,Xn的一个样本值,我们可以知道Xi,i∈[1,k]的概率
可以得到
P
{
X
1
=
x
1
,
X
2
=
x
2
,
.
.
.
,
X
n
=
x
n
}
=
L
(
θ
)
=
L
(
x
1
,
x
2
,
.
.
.
,
x
n
;
θ
)
=
∏
i
=
1
n
p
(
x
i
;
θ
)
,
θ
∈
Θ
P\{X_1 = x_1, X_2 = x_2, ..., X_n = x_n\} = L(\theta) = L(x_1, x_2, ..., x_n;\theta) = \prod_{i=1}^{n}p(x_i;\theta), \theta\in \Theta
P{X1=x1,X2=x2,...,Xn=xn}=L(θ)=L(x1,x2,...,xn;θ)=i=1∏np(xi;θ),θ∈Θ
这个函数L 就是 样本的 似然函数。
而之所以该方法叫 最大似然估计法,就是我们取的 θ的估计参数值,是一个最大参数值
L
(
x
1
,
x
2
,
.
.
.
,
x
n
;
θ
^
)
=
max
θ
∈
Θ
L
(
x
1
,
x
2
,
.
.
.
,
x
n
;
θ
)
L(x_1, x_2, ...,x_n; \hat{\theta}) = \max_{\theta\in\Theta}{L(x_1, x_2, ... , x_n; \theta)}
L(x1,x2,...,xn;θ^)=θ∈ΘmaxL(x1,x2,...,xn;θ)
连续型
概率密度
∏
i
=
1
n
f
(
x
i
;
θ
)
\prod_{i=1}^{n}{f(x_i;\theta)}
i=1∏nf(xi;θ)
似然函数
L
(
θ
)
=
L
(
x
1
,
x
2
,
.
.
.
,
x
n
;
θ
^
)
=
∏
i
=
1
n
f
(
x
i
;
θ
)
L(\theta)=L(x_1, x_2, ...,x_n; \hat{\theta}) =\prod_{i=1}^{n}{f(x_i;\theta)}
L(θ)=L(x1,x2,...,xn;θ^)=i=1∏nf(xi;θ)
如果我们取一个对数然后再求导,就可以得到
d
d
θ
l
n
L
(
θ
)
=
0
\frac{d}{d\theta}{lnL(\theta)} = 0
dθdlnL(θ)=0
就得到 对数似然方程。
为啥求导?因为要取最大值,所以求导数值为0的情况,当然这里忽略极小值和边界。
步骤上基本和矩估计差别不大,也是计算,只不过更多是在求导然后解决方程上。
多参数的情况下,只需要求偏导即可。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









