









数据的分组及遍历
在本章中,我们使用的演示数据集为:
import pandas as pd
dic = {'ID':[1001,1002,1003,1004,1005,1006,1007,1008,1009,1010,1011],
'name':['张三','李四','王五','赵六','孙七','周八','吴九','郑十','张三','王五','郑十'],
'age':[18,19,20,20,22,22,18,19,19,23,20],
'class':['大一','大二','大三','大三','研一','研一','大一','大二','大一','大三','大二'],
'high':[150.00,167.00,180.00,160.00,165.00,168.00,172.00,178.00,175.00,177.00,177.50],
'gender':['男','女','男','女','男','男','女','男','男','男','男'],
'hobby':['小提琴','围棋','象棋','羽毛球','游泳','看小说','刷抖音','王者','钢琴','篮球','竖笛']}
df=pd.DataFrame(data = dic,
index = ['a','b','c','d','e','f','g','h','i','j','k'])
其中,ID代表学号,name代表名字,age表示年龄,class表示年级,high表示身高,gender表示性别,hobby表示爱好。数据中有重名的现象,但没有重复的数据。
下面我们开始介绍数据分组,pandas提供了一个高提供了一个高效灵活的groupby功能,可以帮助我们完成对数据的分组。接下来我们把这个数据依性别分成两组:
group = df.groupby('gender')
print(group)
运行之后看到生成的结果:
是一个地址信息。于是我们试图用循环把内容取到:
group = df.groupby('gender')
for i in group:
print(i)
看看结果:

这么看来,输出的是两个元组类型的数据,其中每个元组包含了分类的依据,即性别,以及该性别下对应人的信息,存储类型为DataFrame。为了验证这个猜想,将刚刚的代码稍作改动,大家可以自行尝试:
group = df.groupby('gender')
for i in group:
print(i)
print(type(i),type(i[0]),type(i[1]))
这样的话,我们可以这样设置循环,以便只取出元组中的DataFrame数据:
group = df.groupby('gender')
for i,j in group:
print(j)

如果需要查看分组后每组的数量,可以使用size方法,返回值是一个含有分组大小的Series类型:
group = df.groupby('gender')
print(group.size(),type(group.size()))

接下来,我们计算一下这个数据集中男女学生数量比:
group = df.groupby('gender')
print('女学生与男学生数量比为:',group.size()[0]/group.size()[1])
group.size()[0]可以直接拿到女学生的总数3,同样的,group.size()[1]也可以直接拿到男生的总数8。但是这种方法无法拿到我们的分组依据,即性别。
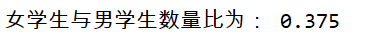
但是,.items方法就可以将分组依据(这里是性别男女)和数量存储到一个元组中,方便我们取用。这里的group.size().items()会生成两个元组:
group = df.groupby('gender')
for i in group.size().items():
print(i)

这样,我们就可以计算男女学生和男学生占总人数的比例,并由程序告诉我们这个比例来自男生还是女生。还记得shape方法吗?它可以帮助我们计算表格的行列数:
group = df.groupby('gender')
for i,j in group.size().items():
print('%s学生的占比为%.2f'%(i,j/df.shape[0]))

这里给大家介绍另一个方法,可以代替这种写法:
group = df.groupby('gender')
for i,j in group.size().items():
print('{}学生的占比为{:.2f}'.format(i,j/df.shape[0]))
读者可以自行运行试试看。.format()方法也可以完成对指定位置({ }内)的内容填充,并且这种方式也可以完成保留小数。其形式如上例中所示。
df.groupby(‘gender’)是根据gender列对整个数据进行分组,同样我们也可以只对一列数据进行分组,只保留我们需要的列数据。比如我们先根据性别分类,然后对年级进行分组:
group = df.groupby(df['gender'])['class']
print(group)
先来解释一下第一句代码,为先根据性别列进行分类,分类后依然是一个表格,然后将这个表格只保留班级列,赋值给group。同样能够实现这样功能的语句还有df[‘class’].groupby(df[‘gender’]),这句代码的逻辑是取出df中class列数据,并且对该列数据根据df[‘gender’]列数据进行分组操作 。
接下来我们看看运行结果:
又是一个地址。下面我们用循环来取出内容:
for i in group:
print(i)

输出是两个元组,每个元组类型中有两个元素,分别是分类的性别依据以及年级信息所组成的DataFrame表格。大家可以自己编写代码查看类型。
其实,还有一个简单实用的方法:
print(group.groups)
print(group.get_group('男'))

group.groups可以生成一个字典,字典的建是分类的依据,值是分组后的数据,用这条语句来查看分组后的情况非常方便;group.get_group(‘男’)可以根据分组的具体名字获取分组后每个组的行索引。但是需要注意的是,这种
多列分组
之前我们已经完成了对一列信息进行分组,但是这并不能解决全部问题,比如我们现在既想要对性别进行分组,又希望统计年级情况,这就需要进行多列分组了。强大的groupby()方法是支持多列分组的,我们只需要把多个分组依据放入列表再传递给groupby即可,例如:
group=df.groupby(['class','gender']) # 依据年级和性别进行分组
print(group.groups)
df1 = group.size()
print(df1)
for i,j in df1.items():
print(i,j)

模仿之前的方法书写代码,可以发现group.groups依然会生成一个字典,只不过字典的键有两个分组依据,值依然是该分组下的行索引,items方法输出的结果也和之前一样,这里不做展开叙述,但是我们需要注意一下size方法,因为返回的索引是多层的(先是年级,再是性别,而后才是人数),因此我们想要取到人数就需要把代码写成以下形式:
print(df1['大一'] # 查看大一分类的情况
print(df1['研一']['男']) # 查看研一男生的数量

当需要对三个或多个列进行分组的时候,也是相同的处理方式。大家是不是已经学会了呢?
分组的统计学操作
上面我们详细讲述了如何对数据进行分组,并搭配了size(),items()和shape()完成了一些简单的功能。现在请大家想一下,如果我们想要查询这批学生中男生年龄的中位数,平均数等,又该如何操作呢?
首先,group.get_group(‘男’)可以拿到分类为男生的信息,我们运行以下代码:
import pandas as pd
gro = df.groupby(df['gender']) # 针对性别分组
f_gro=gro.get_group('男') # 找到分组为男的数据进行保存
print(f_gro) # 查看f_gro保存内容

输出的是一个含有全部男生信息的表格,这符合我们的预期。然后我们进行数据统计(也称为数据聚合),这是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。让我们先来计算男生年龄的平均数以及中位数:
# 定义平均值函数
def mean (*data): # 使用可变参数
data=data[0] # 调用的时候传递一个数值列表,该列表在元组中是第0元素
sum=0
all=len(data)
for i in range(all):
sum+=data[i]
return sum/all
import pandas as pd
gro = df.groupby(df['gender']) # 针对性别分组
f_gro=gro.get_group('男') # 找到分组为男的数据进行保存
print('男生的平均年龄为:{}岁'.format(mean(f_gro['age'].to_list()))) # 将年龄列转化成列表传递给mean函数,求取平均值
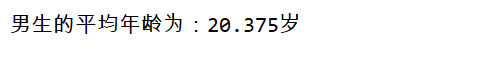
这样就渠道平均值了。但是这并不是最简单的方法,pandas里有许多常用的统计函数,其中就包括了平均数、中位数的求取,我们只需要学会调用就行:
| 函数 | 意义 |
|---|---|
| count() | 统计表中非空数据个数 |
| nunique() | 统计非重复数据的个数 |
| sum() | 统计表中所有数据佳和 |
| mean() | 计算表中数据平均值 |
| median() | 统计表中数据中位数 |
| max() | 求表中数据最大值 |
| min() | 求表中数据最小值 |
因此求取平均数和中位数的完整代码就可以写成:
import pandas as pd
gro = df.groupby('gender') # 按性别分类
f_gro = gro.get_group('男') # 提取性别为男的所有人的信息
f_mean = f_gro['age'].mean()# 获取平均值
f_max = f_gro['age'].max()# 获取最大值
f_min = f_gro['age'].min()# 获取最小值
print(f_mean,f_max,f_min)
运行结果:

我们还可以配合遍历取到所有组的统计学信息:
for gro_name,gro_df in gro:
f_gro = gro.get_group(gro_name)
f_mean = f_gro['age'].mean() # 获取平均值
f_max = f_gro['age'].max() # 获取最大值
f_min = f_gro['age'].min() # 获取最小值
f_mid = f_gro['age'].median() # 获取最小值
print('{}生的年龄平均值为{},最大值为{},最小值为{},中位数为{}'.format(gro_name,f_mean,f_max,f_min,f_mid))

这样是不是一下就简单很多?
数据统计的简化
上一节已经给大家介绍了统计的一些方法,但是像那样调用起来有些麻烦,为了使用灵活,pandas提供了一个agg()方法,看实例:
for gro_name,gro_df in gro:
f_gro = gro.get_group(gro_name)
f_se= f_gro['age'].agg(['mean','max','min','median'])
print('{}生的年龄平均值为{},最大值为{},最小值为{},中位数为{}'.format(gro_name,f_se[0],f_se[1],f_se[2],f_se[3]))
这段代码输出的结果和刚才是一样的,大家可以自行尝试一下。当然,agg方法的强大不止于此,它还可以引用我们自己写的函数:
def peak_range(df):
'''
计算最大值与最小值的差
'''
return df.max()-df.min()
for gro_name,gro_df in gro:
f_gro = gro.get_group(gro_name)
f_se= f_gro['age'].agg(['mean','max','min','median',peak_range])
print('{}生的年龄平均值为{},最大值为{},最小值为{},中位数为{},极差为{}'.format(gro_name,f_se[0],f_se[1],f_se[2],f_se[3],f_se[4]))

这个例子可以看出,我们在引用自定义函数时,只需要去掉引号就可以,即自定义的函数名字在传入agg()函数中时不需要转换成字符串。agg()方法会自动把当前分组的表传递给我们的自定义函数并获取该函数的返回值。
本节内容给大家介绍了groupby方法对数据进行分组及多列分组,并且对分组后的数据进行统计,希望看到这里的大家能够有所收获,喜欢的小伙伴可以点一下关注~















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









