









在数据处理篇6中,我们讲到了如何处理时间信息,接下来,我们来应用刚学到的知识处理一些实际问题。老规矩,请大家先下载 习题资源。
现在我们完成两个习题:
习题1
1. 算出2016到2019年,每年5月份的总销售额
想要完成这个任务其实很简单,我们只需要取出2016到2019年每年五月的全部数据,再进行求和即可。先看看我们需要如何操作表格:

从表格中不难看出,我们只需要把订单日期转化成索引,再进行取值,取值完成之后调用求和函数得到最后的结果即可:
import pandas as pd
data = pd.read_excel('Commerce.xls')
# 将订单日期设置为数据的索引
data.index = data['订单日期']
# 分别计算每年5月份的销售额
sales16 = data.loc['2016-05']['销售额'].sum()
sales17 = data.loc['2017-05']['销售额'].sum()
sales18 = data.loc['2018-05']['销售额'].sum()
sales19 = data.loc['2019-05']['销售额'].sum()
print(sales16)
print(sales17)
print(sales18)
print(sales19)
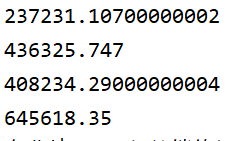
发现我们确实拿到了想要的结果,但是由于存储方式的原因,部分数据出现了异常。解决的办法也很简单,只需要保留三位小数即可。
2. 2018年各地区的5月份的总销售额对比
这个题的思路和钢材类似,我们首先取到2018年5月的信息,然后根据不同的地区进行分类,在求其加和即可:
# 获取2018年五月份数据
sales18 = data.loc['2018-05']
# 根据地区分组
groups = sales18.groupby('地区')
# 分别计算各地区销售总额
for group_name,group_df in groups:
sales_all = group_df['销售额'].sum()
print('{}地区5月份总销售额是{:.3f}'.format(group_name,sales_all))

是不是也不难呢?
习题2
1. 计算出2018年各个季度的总销售额
首先我们要知道1-3月为第一季度,4-6为第二季度,7-9为第三季度,10-12为第四季度。然后我们需要将2018年的信息按个季度拆开保存,在对每个保存起来的表格求和取值即可:
import pandas as pd
data = pd.read_excel('Commerce.xls')
# 将订单日期设置为数据的索引
data.index = data['订单日期']
sales18=[] # 用于储存各季度的销售信息
sales18.append(data.loc['2018-01':'2018-3'])
sales18.append(data.loc['2018-04':'2018-6'])
sales18.append(data.loc['2018-07':'2018-9'])
sales18.append(data.loc['2018-10':'2018-12'])
for i in range(len(sales18)):
print('18年第{}季度销售总额为{}'.format(i+1,sales18[i].sum().loc['销售额']))

2. 计算出2018年各季度各地区的总销售额
在上一题中我们已经完成了数据的分季度存储,因此完成这个需求只需要对每个存储内容进行按地区分类,以及对结果求和即可:
or i in range(len(sales18)):
gro = sales18[i].groupby('地区')
print('第Q{}季度各地区销量:'.format(i+1))
for area,val in gro:
print('{}地区度销售额为:{:.3f}'.format(area,val['销售额'].sum()))

认真完成之前学习的小伙伴一定很熟悉这样的方法吧,本次习题的难度并不高,只是帮组大家进一步理解实践所引的实战使用。下期我们将会开启一个新的征程,学习数据的可视化。下期再见~















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









