







介绍

由于把json中的数据转化成python内建数据类型很简单,所以我们在爬虫中尽量使用能返回json数据的url,就会尽量使用这种url。json是一种轻量级的数剧交互格式。json在数据交换中起到了一个载体的作用。
寻找json资源
在许多网页的url中可以把callback删除,这样更易获取完整的json
有callback参数时(像这样):
;jsonp1(
{
msg: "invalid_request_1284",
code: 1287,
request: "GET /rexxar/v2/subject_collection/tv_domestic/items",
localized_message: ""
}
)
删去可以获得一个完美的json:
{
msg: "invalid_request_1284",
code: 1287,
request: "GET /rexxar/v2/subject_collection/tv_domestic/items",
localized_message: ""
}
哪里能找到返回json的url:
手机版的浏览页面
抓包手机app的软件
数据类型转换
获得url地址
或区相应
转换成json或者dict(json.dumps json.loads)
import requests
import json
import parse_url
from pprint import pprint
url = "https://m.douban.com/rexxar/api/v2/subject_collection/tv_domestic/items?os=android&start=0&count=8&loc_id=108288&_=1625369161437"
html_str = parse_url(url) # 转化成json数据类型
#使用json.loads把json字符串转化为python类型
ret1 = json.loads(html_str)
pprint(ret1)
pprint(type(ret1))
#使用json.dumps能够把python类型转化为json字符串
with open("douban.json","w",encoding = "utf-8") as f:
f.write(json.dump(ret1,ensure_ascii=False,indent=4)) #控制各级首行缩进和控制编码不自动转换
f.write(str(ret1))
json使用时字符串应该都是双引号,如果不是双引号可以用replace或者eval实现字符串和python类型的简单转换
#使用json.load提取类文件中的数据 省略了读的步骤
with open("douban.json","r",encoding="utf-8") as f:
ret4 = json.load(f)
print(ret4)
print(type(ret4))
#使用json.dump放入python数据类型到类文件中
with open("douban.json","w",encoding="utf-8") as f:
json.dump(ret1,f)
正则表达式
正则表达式:特定字符和特定字符串组成的规则字符串,是一种字符串的过滤逻辑
常用的正则表达式方法:
re.complie(编译)
pattern.match(从头找一个)
pattern.search(找一个)
pattern.findall(找所有)
pattern.sub(替换)
一般字符:"." " \ " " […] "
".“能匹配所有字符,除了”\n"之外需要在DOTALL模式下匹配,可以简写成re.S
import re
print(re.findall(".", "\n"))
print(re.findall(".", "s"))
print(re.findall(".", "\n", re.DOTALL))
print(re.findall(".", "\n", re.S))
运行效果:

" \ ": 常用的转义字符
" […] ": 字符集,对应的位置可以是字符集中的任意字符。可以逐个列出也可以给出范围[abc] [a-c] 如果第一个字符是^则表示不取字符集中的字符,表示取反。
print(re.findall("[a-c]", "abc"))
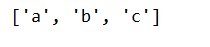
预定义字符集
\d:数字集[1-9]
\D:非数字集
\s:空白字符:[<空格>\t\r\n\f\v]
\S:非空白字符
\w:单词字符[A-Z a-z 0-9]
\W:非单词字符
数量词
*:匹配前一个字符0次或者无数次
+:匹配前一个字符1次或者无数次
?:匹配前一个字符0或1次
{m}:匹配一个字符m次














 4699
4699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









