







Storage存储
认识Storage
WebStorage主要提供了一种机制,可以让浏览器提供一种比cookie更加直观的key、value存储方式
- localStorage:本地存储,永久性的存储方法,关闭掉网页重新打开时,存储的内容依然保留
- sessionStorage:会话存储,本次会话中 进行存储
localStorage.setItem("key",value)
localStorage.getItem("key")
sessionStorage.setItem("key",value)
sessionStorage.getItem("key")
localStorage和sessionStorage的区别
- 关闭网页后,localStorage会保留,而 sessionStorage会被删除
- 在同一个tab标签页中,实现网页跳转(_self),两者都会保留
- 在一个标签页中,打开信的tab标签页,localStorage会被保存,sessionStorage则不会进行保存
Storage常见的属性和方法
属性
- length
localStorage.lenth//返回一个整数,表示存储在Storage中的数据项数量
方法
localStorage.setItem("key",value)
localStorage.getItem("key")
localStorage.key(index)//返回存储中的第n个key的名称
localStorage.removeItem("key")//移除某个key
localStorage.clear()//清空所有的key
实际开发中的应用
在实际开发中,通常会将storage的方法包装成一个对象,通过调用对象中的方法,进行使用
class Cache {
//先来判断是采用localStorage还是sessionStorage
constructor(isLocal = true) {
this.storage = isLocal ? localStorage : sessionStorage;
}
setCache(key, value) {
//对value进行字符串的转化处理
if (!value) {
throw new Error("value需要有值!");
}
this.storage.setItem(key, JSON.stringify(value));
}
getCache(key) {
//首先需要判断是否有key对应的存储
const result = this.storage.getItem(key);
if (result) {
return JSON.parse(result);
}
}
}
const myLocalStorage = new Cache();
const mySessionStorage = new Cache(false);
//通过调用实例方法,即可完成相应的本地(会话)存储
正则表达式
在某些特定场景进行会用,前期花费大量时间学习正则表达式,是比较低效的
什么是正则表达式
- 正则表达式(regex或者regexp 或者 RE)是计算机科学的一个概念
- 是一种字符串匹配利器,可以帮助我们搜索、获取、代替字符串
- 在JS中,正则表达式使用RegExp
//在JS中有两种方式可以创建正则表达式
// new RegExp(pattern(规则), flag(标识符))
// /pattern(规则)/flag(标识符)
let res1 = new RegExp("abc", "ig")
let res2 = /abc/ig
正则表达式的使用方法
调用正则表达式的实例方法
- test方法,检测某一个字符串是否符合正则的规则,返回boolean类型
//创建一个正则表达式实例对象
//调用实例方法test
//传入要判断的字符串
let rex = /abc/gi;
let message = "wefsdabc";
console.log(rex.test(message)); //true
- exec方法:使用正则执行一个字符串
let rex = /abc/gi;
let message = "wefsdabc";
console.log(rex.exec(message));
/*规则、字符串中第一个个符合规则的位置、字符串本身 */
//[ 'abc', index: 5, input: 'wefsdabc', groups: undefined ]
使用字符串的方法,传入一个正则表达式

//match和matchAll
let message = "qwdehabc qwnajfaBc qiwrABC";
let reg = /abc/gi;
console.log(message.match(reg)); //[ 'abc', 'aBc', 'ABC' ]
console.log(message.matchAll(reg)); //返回的是一个迭代器,可以使用for of或者.next()进行遍历
--------------------------
//replace和replaceAll
//将abc(忽略大小写)替换成123
let message = "qwdehabc qwnajfaBc qiwrABC";
let res = message.replace(/abc/ig, 123);
console.log(res);
--------------------------
//split中传入正则表达式
let message = "qwdehabc qwnajfaBc qiwrABC";
let reg = /abc/gi;
console.log(message.split(reg));//[ 'qwdeh', ' qwnajf', ' qiwr', '' ]
--------------------------
//search查找第一个符合规则的位置
let message = "qwdehabc qwnajfaBc qiwrABC";
let reg = /abc/gi;
console.log(message.search(reg));//5
修饰符flag的使用
常见的修饰符
g(global)匹配全部的
i(ignore)忽略大小写
m(multiple)多行匹配
let reg = /abc/ig
//匹配全局且忽略大小写的abc
规则-字符类
\d(digit)匹配数字0~9
\s(space)匹配空格符号,包含\t \n 等
\w(word)匹配拉丁字母或者数字或者下划线_
. 是一种特殊字符类,除了不能匹配换行符之外的所有字符
- 字符类是一个特殊的符号,匹配特定集中的任何符号
let reg = /\d/ig
let reg1 = /\s/ig
let reg2 = /\w/ig
let reg3 = /./ig
- 反向类
\D除了\d以外的任何字符
\S除了\s以外的任何字符
\W除了\w以外的任何字符
规则-锚点、词边界
^和$分别对应文本的开头和结尾
\b代表词边界,不允许\w的内容出现(即不允许出现字母、数字、下划线_)
//锚点的应用
let message = "my name is zhangcheng";
let regStart = /^my/gi;//以my为开头
let regEnd = /zhangcheng$/gi;//以zhangcheng为结尾
console.log(regStart.test(message));
console.log(regEnd.test(message));
//词边界的应用
//比如现在需要匹配单独的一个单词name
//只有name符合规则,aanamedd这种是不符合规则的
let message = "my name nnamea is zhangcheng";
let reg1 = /name/ig//这种能够匹配包含name的字符串
let reg2 = /\bname\b///这种就能匹配单独一个name单词的了
规则-转义字符
将特殊的字符,变为正常的字符,前面加一个\反斜杠即可,比如只想匹配一个.的正常字符 .
let message = "a.html"
let reg = /\./ig//即可匹配到点.这个字符
-
常见需要转义的字符
[ ] / \ ^ $ . | ? * + ( )
//匹配以js或者jsx结尾的字符串
let fileNames = ["a.html", "a.js", "home.jsx", "b.js", "c.js"];
let regStart = /\.jsx?$/;
let newFileNames = fileNames.filter((item) => regStart.test(item));
console.log(newFileNames);
//[ 'a.js', 'home.jsx', 'b.js', 'c.js' ]
规则–集合(Sets)和范围(Ranges)
需要从多个字符中,匹配其中之一
- [填入匹配的字符],将要匹配的字符,写在中括号中
- 集合:[aeo],匹配a e o中的任意一个
- 范围:
- 方括号中可以写具体的范围
- [a-z]表示小写字母从a-z均可以,[0-5]表示数字0-5均可以
- [0-9A-F]表示0-9的数字以及A-F的大写字母
- \d----表示[0-9]
- \w—表示[a-zA-Z0-9_]
//匹配手机号
//规则开头以1开头,第二位3-9,后面接9位数字
let reg = /^1[3-9]\d{9}$/;
let phoneArr = ["18039589634", "18039587516", "15421594152338"];
let newPhone = phoneArr.filter((item) => reg.test(item));
console.log(newPhone); //[ '18039589634', '18039587516' ]
- 排除范围
let reg = /[^0-9]/
//表示不在0-9范围之内
规则–量词
在匹配字符串的时候,通常是不知道其具体数量的,因此,需要使用量词
- 数量{n}
- 确切的位数{5}:代表5位
- 某个范围{3,5}:代表3-5位
- 缩写
- +:代表一个或者多个,相当于{1,}
- ?:代表0个或者1个,相当于{0,1},说明这个字符要么只出现1次,要么不出现
- *:代表0个或者多个,相当于{0,}
//匹配字符串中的所有标签
let htmlElement = "<div>hahah<span>123<p>456</p></span></div>";
let reg = /<\/?[a-z][a-z0-9]*>/gi;
console.log(htmlElement.match(reg));
规则–贪婪(Greedy)和惰性(lazy)模式
- 首先看一下以下情况
//需要匹配《》中间的内容
let message = "《活着》、《传说》、《渴望》";
//书名号中的内容,可能出现任意字符,因此使用. 同时会有多个使用+
let reg = /《.+》/gi;
console.log(message.match(reg));//[ '《活着》、《传说》、《渴望》' ]
- 通过以上现象我们可以看出,这种匹配方式将第一本书的《和最后一本书的》当成了匹配规则,并不是我们想要的,这种模式就是贪婪模式
- 我们需要开启懒惰模式
- 使用?即可开启
//需要匹配《》中间的内容
let message = "《活着》、《传说》、《渴望》";
//书名号中的内容,可能出现任意字符,因此使用. 同时会有多个使用+
let reg = /《.+?》/gi;
console.log(message.match(reg)); //[ '《活着》', '《传说》', '《渴望》' ]
规则-- 捕获组
- 规则中的一部分,可以用括号括起来(…),这称为 捕获组
- 这个有两个作用
- 用括号扩起来的内容,在结果的数组中,可以单独出现
- 括号的内容可以看作一个整体
//将上面的需求,转变成,只获取书名号中的文字
//需要匹配《》中间的内容
let message = "《活着》、《传说》、《渴望》";
//书名号中的内容,可能出现任意字符,因此使用. 同时会有多个使用+
let reg = /《(.+?)》/gi;
let result = message.matchAll(reg);
for (const item of result) {
console.log(item);
}
//通过下面的结果,可以知道,item[1]就是我们想要的结果

//匹配两个及以上的abc组合,abc不能匹配,abcabc可以匹配
let message = "afeuabchqwueabcabcwej";
let reg = /(abc){2,}/gi;
console.log(message.match(reg));
//若不加括号,则代表c出现两个或两个以上
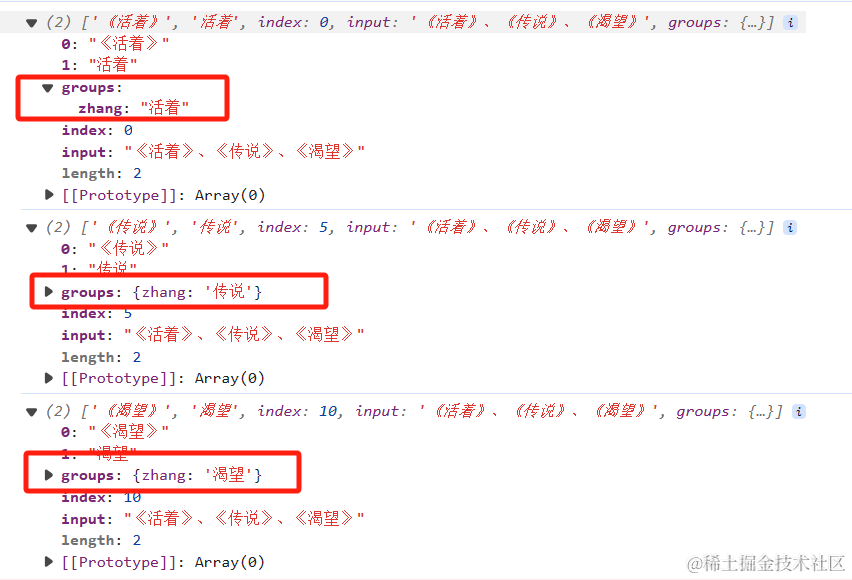
- 补充–捕获组命名
(?<命名>)
let message = "《活着》、《传说》、《渴望》";
//书名号中的内容,可能出现任意字符,因此使用. 同时会有多个使用+
let reg = /《(?<zhang>.+?)》/gi;
let result = message.matchAll(reg);
for (const item of result) {
console.log(item);
}
- 补充–非捕获组
有些时候,我们需要用捕获组指定匹配规则,但是并不希望它出现在最后的结果中
(?😃
let message = "《活着》、《传说》、《渴望》";
//书名号中的内容,可能出现任意字符,因此使用. 同时会有多个使用+
let reg = /(?:《)(?<zhang>.+?)(?:》)/gi;
let result = message.matchAll(reg);
for (const item of result) {
console.log(item);
}
//这样书名号就不会出现在结果中了
- 补充–正则表达式中的或
在正则表达式中,表达或的方式为 |
let reg = /(abc|cba|aaa)/
//匹配abc cba 或者aaa
//与[]不同的是,可以匹配一个组,而[]只能匹配单个字母
案例练习-歌词解析
当我们得到歌词的字符串,我们需要将该字符串中的歌词提取出来,制作成数组对象中,每个对象包含歌词的时间和歌词的文本
let singWords =
"[00:02.144]若爱是但求开心 我问\n[00:06.028]要不要求其伤心\n[00:24.601]论尽半生不懂爱\n[00:29.689]回头没有心计划未来\n[00:34.637]才来独处好好检讨什么叫爱\n[00:42.024]你 便 来\n[00:45.259]混乱里结识到你\n[00:50.370]浪漫叫一切粉饰同盼待\n[00:55.422]某一刹骤觉 感情深得可爱\n[01:01.819]在倾吐那刻回响\n[01:07.210]感情从不是爱\n[01:13.869]若爱是但求终身 你问\n[01:19.098]怕只怕求其终生 被困\n[01:24.122]你宠爱父母亲\n[01:27.117]我为良朋怜悯\n[01:29.436]怎都算是个好人\n[01:34.486]若爱是但求衷心 我问\n[01:39.735]要不要求其忠心\n[01:45.302]纵双方理念多相同\n[01:49.267]却不相融\n[01:51.974]莫论配衬\n[02:11.071]再会时\n[02:13.995]没料到深深拥抱\n[02:18.942]合力擦出了火花和意外\n[02:24.300]某一刹幻觉恋情可一可再\n[02:30.669]在参透那刻回想\n[02:35.918]恋情全不是爱\n[02:42.288]若爱是但求终身 你问\n[02:47.603]怕只怕求其终生 被困\n[02:52.843]你工作觅满分\n[02:55.640]我为前途勤奋\n[02:58.306]怎可再另有心神\n[03:03.036]若爱是但求衷心 我问\n[03:08.366]要不要求其忠心\n[03:13.806]纵双方理念多相同\n[03:17.510]却不相融\n[03:20.253]莫论配衬\n[03:24.856]若爱是但求安心\n[03:29.521]怕只怕求其安稳\n[03:44.750]若爱是但求今生 抱憾\n[03:50.267]要不要求其他生\n[03:55.511]看双方各自的本能\n[03:59.350]爱的伤痕\n[04:02.376]极度配衬\n[04:06.438]爱七色五味多纷陈\n[04:10.791]更多灰尘\n[04:14.740]落入五蕴";
//先将歌词字符串,按照\n进行分割成数组,
let singArr = singWords.split("\n");
//设置获取时间的正则
let timeReg = /\[(\d{2}):(\d{2})\.(\d{3})\]/i;
//用于存储歌词时间的数组
let newSingWords = [];
//遍历歌词数组,提取其中的时间
for (const item of singArr) {
// console.log(item.match(timeReg));
let timeItem = item.match(timeReg);
//通过分钟*60*1000
//秒钟*1000
//毫秒,需要根据得到的长度进行判断,若为3位则*1,若为两位则*10
let minutes = timeItem[1] * 60 * 1000;
let seconds = timeItem[2] * 1000;
let mSeconds = timeItem[3].length === 3 ? timeItem[3] * 1 : timeItem[3] * 10;
let newTime = minutes + seconds + mSeconds;
//之后获取歌词
let content = item.replace(timeReg, "");
newSingWords.push({ newTime, content });
}
console.log(newSingWords);















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









