







安装Hive3.1.2
- 下载并解压Hive安装包
sudo tar -zxvf ./Downloads/apache-hive-3.1.2-bin.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv apache-hive-3.1.2-bin hive # 将文件夹名改为hive
sudo chown -R hadoop:hadoop hive # 修改文件权限
- 配置环境变量
使用vim编辑器打开.bashrc文件
vim ~/.bashrc
在该文件最前面一行添加如下内容:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export HADOOP_HOME=/usr/local/hadoop
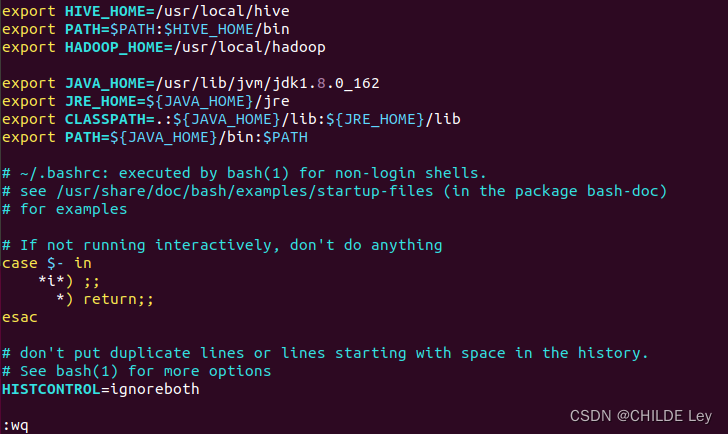
运行如下命令使配置立即生效:
source ~/.bashrc
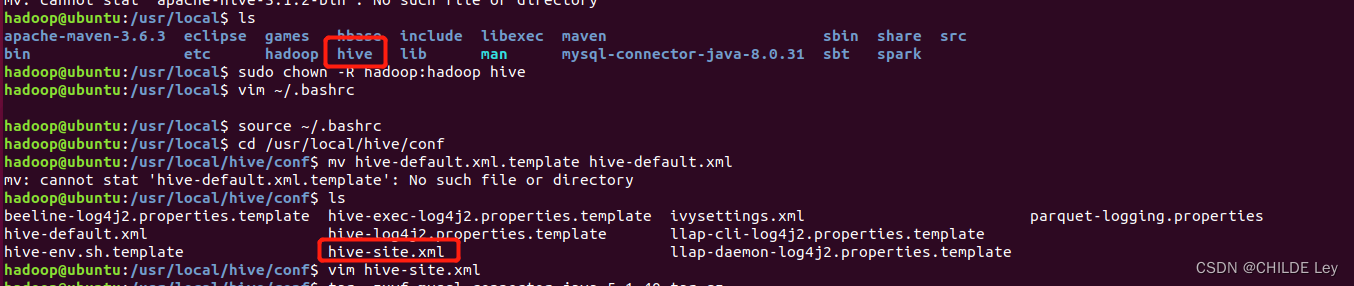
- 修改/usr/local/hive/conf下的hive-site.xml
将hive-default.xml.template重命名为hive-default.xml
cd /usr/local/hive/conf
mv hive-default.xml.template hive-default.xml
用vim编辑器新建一个配置文件hive-site.xml
vim hive-site.xml
在hive-site.xml中添加如下配置信息
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>
安装并配置mysql
- 安装mysql
更新软件源,安装

注意:此处遗漏jdbc包下载,导致后面报错
2. 启动和关闭mysql服务器:

mysql节点处于LISTEN状态表示启动成功
-
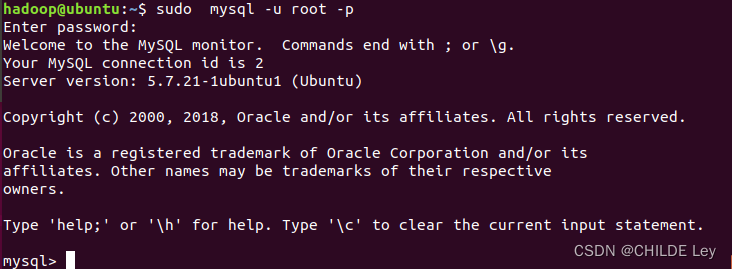
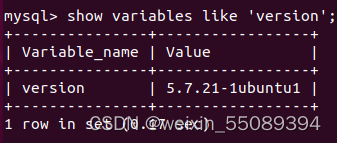
登陆mysql shell
-
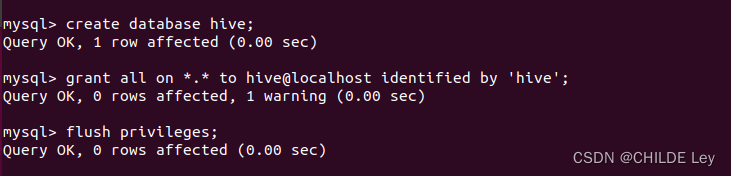
新建hive数据库
create database hive;
- 配置mysql允许hive接入
grant all on *.* to hive@localhost identified by 'hive';
flush privileges;
quit退出shell模式

关闭mysql服务器
service mysql stop
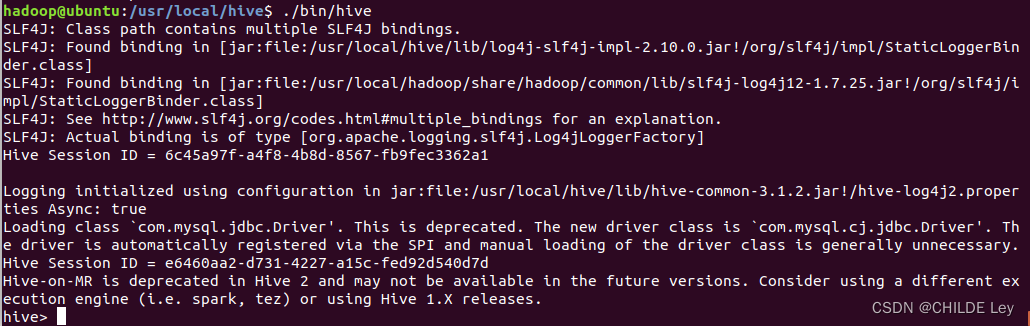
- 启动hive
先启动hadoop集群
cd /usr/local/hadoop #进入Hadoop安装目录
./sbin/start-dfs.sh
cd /usr/local/hive
./bin/hive
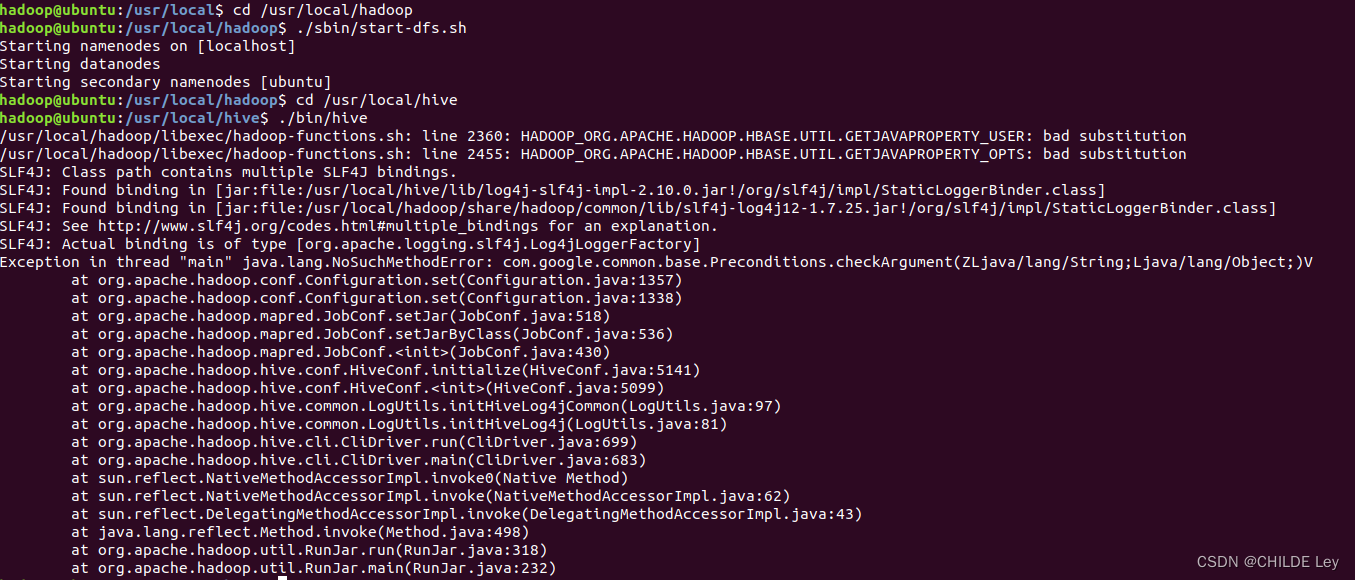
Exception in thread “main” java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:518)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.(JobConf.java:430)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141)
at org.apache.hadoop.hive.conf.HiveConf.(HiveConf.java:5099)
at org.apache.hadoop.hive.common.LogUtils.initHiveLog4jCommon(LogUtils.java:97)
at org.apache.hadoop.hive.common.LogUtils.initHiveLog4j(LogUtils.java:81)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:699)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:318)
at org.apache.hadoop.util.RunJar.main(RunJar.java:232)
报错:java.lang.NoSuchMethodError:
com.google.common.base.Preconditions.checkArgument
原因:com.google.common.base.Preconditions.checkArgument 这是因为hive内依赖的guava.jar和hadoop内的版本不一致造成的。
解决:
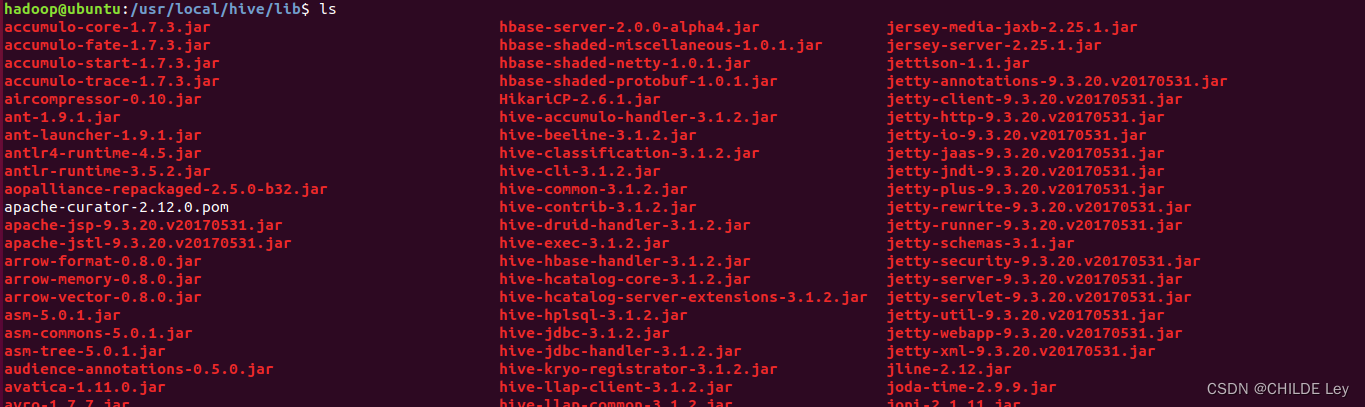
查看hadoop和hive中的guava.jar版本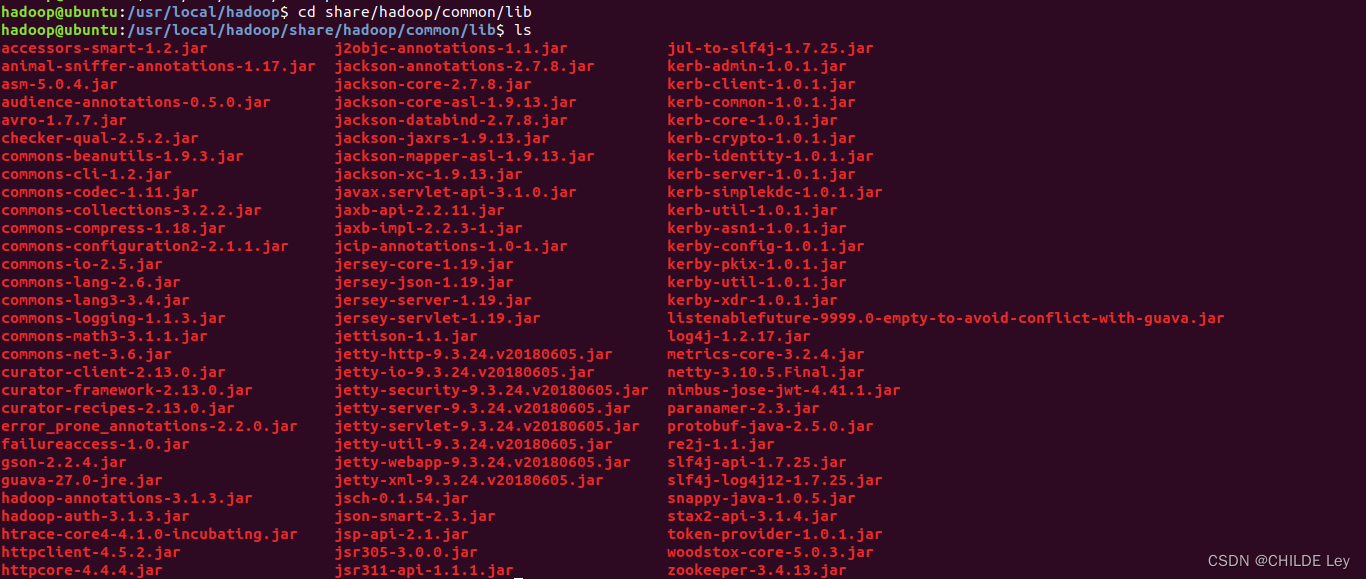
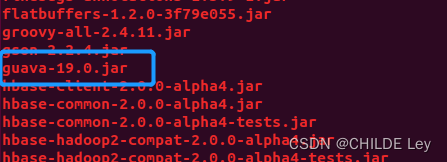
hive中的版本较低,删掉
rm -rf guava-19.0.jar
并拷贝高版本的

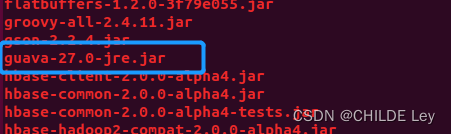
此后,hive按理说不会因guava版本冲突而报错,可正常运行

猜测是缺少jdbc驱动
下载mysql-connector-java驱动,复制到lib中
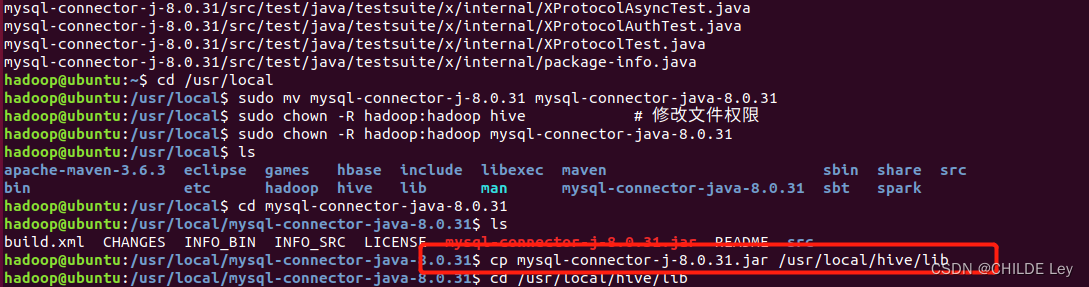
又报新错
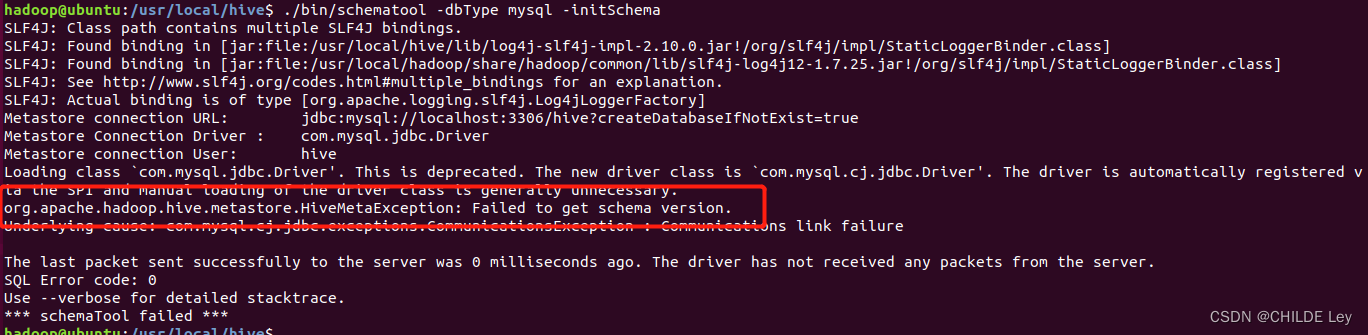
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
Underlying cause: com.mysql.cj.jdbc.exceptions.CommunicationsException : Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
SQL Error code: 0
Use --verbose for detailed stacktrace.
*** schemaTool failed ***
网上找的方法都解决不了
重装一遍,可以运行了
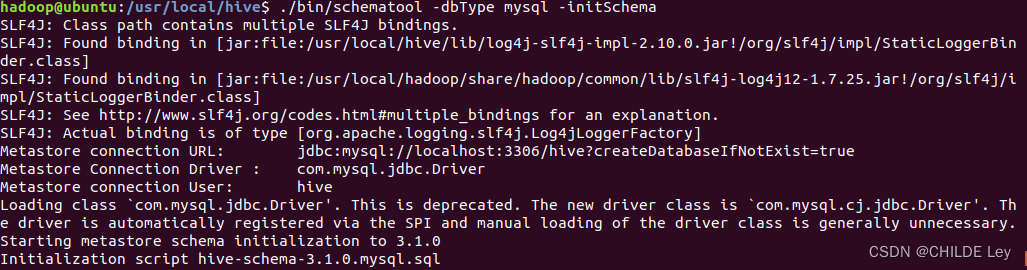

小结:关键在于jbsc驱动的配置
Hive的常用HiveQL操作
a.基本数据类型
TINYINT: 1个字节
SMALLINT: 2个字节
INT: 4个字节
BIGINT: 8个字节
BOOLEAN: TRUE/FALSE
FLOAT: 4个字节,单精度浮点型
DOUBLE: 8个字节,双精度浮点型STRING 字符串
b.复杂数据类型
ARRAY: 有序字段
MAP: 无序字段
STRUCT: 一组命名的字段
- 创建、修改和删除数据库
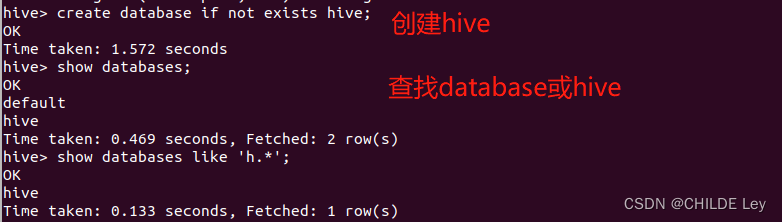
create database if not exists hive; #创建数据库
show databases; #查看Hive中包含数据库
show databases like 'h.*'; #查看Hive中以h开头数据库
describe databases; #查看hive数据库位置等信息
alter database hive set dbproperties; #为hive设置键值对属性
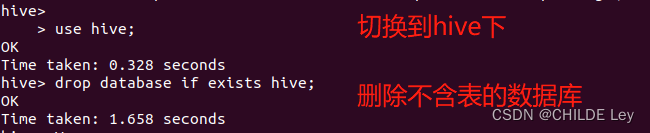
use hive; #切换到hive数据库下
drop database if exists hive; #删除不含表的数据库
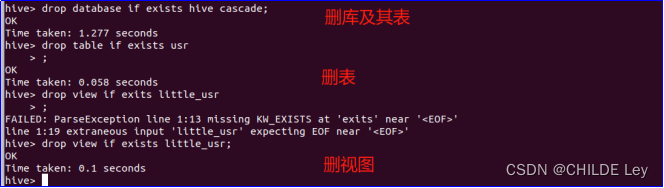
drop database if exists hive cascade; #删除数据库和它中的表

- 创建、修改和删除表
#创建内部表(管理表)
create table if not exists hive.usr(
name string comment 'username',
pwd string comment 'password',
address struct<street:string,city:string,state:string,zip:int>,
comment 'home address',
identify map<int,tinyint> comment 'number,sex')
comment 'description of the table'
tblproperties('creator'='me','time'='2016.1.1');
#创建外部表
create external table if not exists usr2(
name string,
pwd string,
address struct<street:string,city:string,state:string,zip:int>,
identify map<int,tinyint>)
row format delimited fields terminated by ','
location '/usr/local/hive/warehouse/hive.db/usr';
#创建分区表
create table if not exists usr3(
name string,
pwd string,
address struct<street:string,city:string,state:string,zip:int>,
identify map<int,tinyint>)
partitioned by(city string,state string);
#复制usr表的表模式
create table if not exists hive.usr1 like hive.usr;
show tables in hive;
show tables 'u.*'; #查看hive中以u开头的表
describe hive.usr; #查看usr表相关信息
alter table usr rename to custom; #重命名表
#为表增加一个分区
alter table usr2 add if not exists
partition(city=”beijing”,state=”China”)
location '/usr/local/hive/warehouse/usr2/China/beijing';
#修改分区路径
alter table usr2 partition(city=”beijing”,state=”China”)
set location '/usr/local/hive/warehouse/usr2/CH/beijing';
#删除分区
alter table usr2 drop if exists partition(city=”beijing”,state=”China”)
#修改列信息
alter table usr change column pwd password string after address;
alter table usr add columns(hobby string); #增加列
alter table usr replace columns(uname string); #删除替换列
alter table usr set tblproperties('creator'='liming'); #修改表属性
alter table usr2 partition(city=”beijing”,state=”China”) #修改存储属性
set fileformat sequencefile;
use hive; #切换到hive数据库下
drop table if exists usr1; #删除表
drop database if exists hive cascade; #删除数据库和它中的表





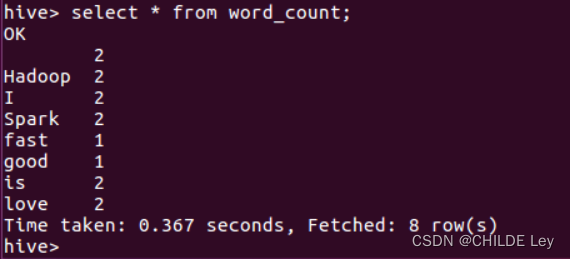
运行wordcount程序















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









