







 本文介绍了如何使用Python的openpyxl库处理Excel表格,通过读取原始数据,筛选出每个公司的数据,并将其保存为单独的Excel文件,从而实现自动化和提高工作效率。
本文介绍了如何使用Python的openpyxl库处理Excel表格,通过读取原始数据,筛选出每个公司的数据,并将其保存为单独的Excel文件,从而实现自动化和提高工作效率。
1.问题描述
最近在处理一堆工作上的excel表格中,总是遇到一批重复性的操作问题。为了节约时间,提高效率,尝试用python代码来处理这一类重复性的excel操作问题。
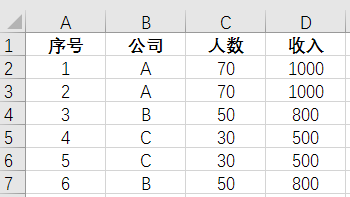
如上图所示:
假如现在有这样一张原始数据表格原始数据.xlsx,存在大量的数据(这里仅列举部分做演示)。我们需要做的工作是将每一个公司的数据单独筛选出来,然后将筛选出来的每一个公司的数据重新保存为一个新的excel表格。
2.解决过程
2.1 问题分析:
假如数据量很大,按上述过程将存在大量重复性的操作。我们计划使用python来处理这类问题,那么需要考虑如下问题:
- 首先,寻找python对应的库来操作读取和写入excel文件。
- 第二,对于所有公司,每个公司只取值一次存入列表。
- 第三,定义一个函数,该函数参数为某公司,通过该函数可以获取某公司对应的所有行的数据。
- 第四,将公司列表的每一个值作为参数传入函数,通过循环遍历所有的公司,然后每调用一次函数做一次保存。
2.2 解决思路
第一,经过查阅文档。发现使用openpyxl库可以解决excel文件读写问题。
from openpyxl import load_workbook,Workbook
# 这里使用pycharm环境,与.py放入同一路径,因此加载路径省略
# load_workbook用于加载表格,Workbook用于创建表格
workbook = load_workbook('原始数据.xlsx')
sheet = workbook.active
第二,每个公司的名称只取一次存入列表
#先取出所有公司码
totalcorp = sheet['B']
corp = []
for co in totalcorp:
corp.append(co.value)
#通过一个循环删除重复的公司代码
i = 0
while i < len(corp):
if corp.count(corp[i]) > 1:
pos = corp.index(corp[i])
temp1 = corp[:pos+1]
temp2 = corp[pos+1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









