







一、背景意义
随着科技的不断发展,计算机视觉和深度学习技术在各个领域得到了广泛应用,尤其是在物体识别和分类方面。在水产养殖和宠物行业,金鱼作为一种受欢迎的观赏鱼类,其品种繁多,形态各异,因此对金鱼的识别和分类具有重要意义。基于机器视觉的金鱼图像识别项目,旨在利用深度学习技术对金鱼进行有效识别和分类,以提高养殖管理的效率和科学性。利用机器视觉和深度学习技术,可以实现对金鱼的自动识别与分类,帮助养殖者更有效地管理鱼群,提高养殖效率,减少人工成本。
二、数据集
2.1数据采集
数据采集是构建图像识别数据集的第一步。该过程包括:
- 图像来源选择:选择合适的图像来源,包括拍摄现场的金鱼、在线图像库、养殖场或水族馆。确保所采集的图像具有多样性。
- 分类确定:根据项目需求,明确数据集的分类。在本项目中,主要分类为幼鱼(baby_fish)和成鱼(live_goldfish)。
- 数据采集工具:使用高质量的相机或设备拍摄金鱼图像,确保图像清晰度高、细节丰富。此外,可以从公开的图像数据库中下载相关的金鱼图像。
- 样本数量:确保每个分类下的样本数量充足,以便于后续模型训练和评估。一般建议每个类别至少收集数百张图像。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
- 去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示金鱼类特征是数据质量的关键。
- 统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
- 分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
数据标注是指对采集到的图像进行分类和标记,以便于模型学习。该过程包括:
- 标注工具选择:使用专业的图像标注工具,如LabelImg、LabelMe或VGG Image Annotator,方便对图像进行标注。
- 标注规范:为每张图像分配相应的标签。对于本项目,幼鱼的图像标记为“baby_fish”,成鱼的图像标记为“live_goldfish”。
- 质量检查:进行标注后的质量检查,确保每个图像的标签准确无误。可以通过随机抽样或双重标注等方式进行验证。
- 保存标注信息:将标注信息保存为适合模型训练的格式,如XML、JSON或CSV,以便后续使用。
在构建金鱼图像识别数据集的过程中,使用LabelImg进行数据标注是一个复杂且耗时的任务,涉及多个环节。首先,用户需安装LabelImg并熟悉其界面和功能,为后续的标注工作做好准备。在图像导入阶段,用户需要将数百张金鱼图像合理组织,以便于分类(幼鱼和成鱼)。标注过程是最为繁琐的部分,用户需逐张图像使用矩形框工具绘制边界框,准确定位金鱼的轮廓,并为每个边界框分配相应的标签,这一过程要求用户具备专业知识和高度集中力。由于数据集庞大,标注工作需要重复进行,增加了工作量并要求用户在长时间操作中保持准确性。此外,标注完成后,用户需进行严格的质量检查,确保每个标签的准确性,必要时重新标注部分图像,以保持数据集的一致性和高质量。最后,标注结果需导出为适合模型训练的格式,并管理存储路径,确保与图像文件的对应关系清晰。

包含781张金鱼图片,数据集中包含以下几种类别
- 鱼苗:金鱼的幼鱼阶段。
- 活体金鱼:金鱼的一种,通常指已经成活并供观赏的金鱼。
2.3数据预处理
数据预处理是为提高模型训练效果而对数据进行的处理步骤。该过程包括:
- 图像尺寸调整:将不同尺寸的图像统一调整为相同的尺寸(如640x640像素),以适应模型输入要求。
- 数据增强:应用数据增强技术,如随机裁剪、旋转、翻转和颜色调整,增加数据的多样性,防止模型过拟合。
- 归一化处理:对图像进行归一化处理,将像素值缩放到0到1的范围,提升模型训练的稳定性。
- 数据划分:将数据集划分为训练集、验证集和测试集,通常遵循70%用于训练,20%用于验证,10%用于测试的比例,以便于评估模型性能。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
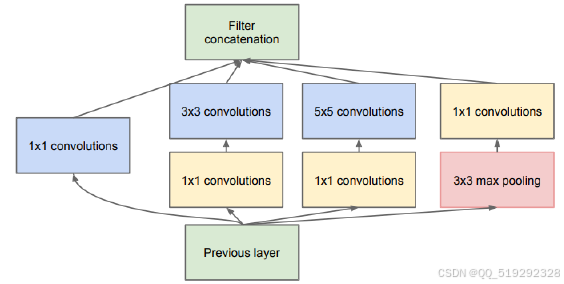
多分支卷积神经网络通过并行的多个卷积分支同时提取不同层次和类型的特征,从而增强特征提取能力。这种结构能够捕捉丰富的输入信息,适用于复杂的视觉任务,如物体识别和图像分割。各分支可使用不同的卷积核、池化和全连接层,最终通过特征拼接、加权融合或级联融合等方式整合输出,显著提高模型的表达能力和性能,适应多变的应用场景。
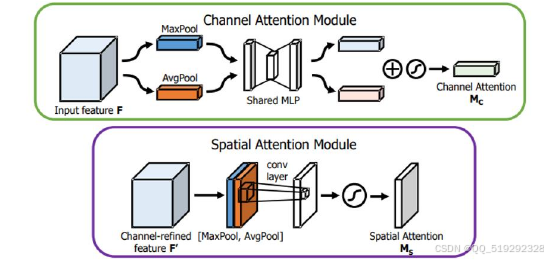
通过对特征进行加权,注意力机制增强了重要信息的权重,使目标信息更易于被检测。目前,注意力机制已经向多种方向发展,包括基于卷积通道、空间信息和位置信息的设计。其中,SE单元通过全局平均池化巧妙提取通道信息,仅调整卷积通道的特征权重而不改变特征大小。混合注意力机制的代表是CBAM,它同时关注空间和通道两个维度。CBAM首先在空间维度上应用平均池化和最大池化,将特征图压缩为一维向量以生成通道注意力特征图。接着,通过对通道进行压缩,再利用标准卷积层生成空间注意力映射。这样的设计允许模型更有效地聚焦于重要特征区域,从而提升目标检测的准确性和鲁棒性。
3.2模型训练
1. 数据集预处理
在开始YOLO项目之前,首先需要对观赏鱼数据集进行预处理。这包括加载图像数据和相应的标注信息,将数据集划分为训练集、验证集和测试集,并生成与YOLO格式兼容的标注文件,以便模型训练和评估。
# 示例代码段 - 数据集加载和预处理
import numpy as np
import cv2
# 加载图像和标注信息
def load_data(image_path, annotation_path):
images = np.array([cv2.imread(img) for img in image_path])
annotations = np.array([np.loadtxt(ann) for ann in annotation_path])
return images, annotations
# 划分数据集
train_images, train_annotations = load_data(train_image_paths, train_annotation_paths)
val_images, val_annotations = load_data(val_image_paths, val_annotation_paths)
test_images, test_annotations = load_data(test_image_paths, test_annotation_paths)
# 生成YOLO格式的标注文件
# 这里需要将标注信息转换为YOLO格式,保存为.txt文件
2. 模型训练
使用准备好的训练数据,开始训练YOLO模型,如YOLOv3或YOLOv4。在训练过程中,可以调整网络结构、超参数和损失函数以优化模型性能。
# 示例代码段 - YOLO模型训练
from yolo_model import YOLOv3
model = YOLOv3(input_shape=(416, 416, 3), num_classes=num_classes)
model.compile(optimizer='adam', loss='yolo_loss')
model.fit(train_images, train_annotations, batch_size=16, epochs=50, validation_data=(val_images, val_annotations))
3. 模型评估
使用验证集数据对训练好的模型进行评估,计算模型在检测观赏鱼类别和边界框位置上的性能指标,如精度、召回率等。
# 示例代码段 - 模型评估
loss, accuracy = model.evaluate(test_images, test_annotations)
print(f"Test loss: {loss}, Test accuracy: {accuracy}")
4. 模型部署
训练好的YOLO模型可以部署到实际应用中,用于观赏鱼的检测和识别。这可能涉及将模型集成到应用程序或服务中,以实现实时检测或批量处理图像数据。
四、总结
金鱼图像识别分类项目旨在利用深度学习技术实现对金鱼的自动识别与分类,数据集主要包含幼鱼和成鱼两个类别。项目涉及数据采集、标注和预处理三个关键环节,其中使用LabelImg工具进行细致的图像标注,尽管过程复杂且工作量巨大,但确保了数据集的高质量和准确性。通过这些准备工作,我们为后续模型训练奠定了坚实基础,期望推动水产养殖的智能化,提高养殖管理的效率和科学性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









