









很奇怪的事情,最近收到的邀请问答都是关于彩票的,这让我有个想法呀!今天就用Python来试一试,学习为主。重点是学知识,很简单的一个案例,先用爬虫爬取开奖结果并保存,在分析下爬取的数据,做下数据可视化。话不多说,小编学历有限,不喜欢码字,直接开撸。
先看下怎么获取开奖结果,小编比较懒,就用最简单的方法,代码很少,但是可以把2003年至今的开奖全部爬下来。
思路如下:
- 打开彩票网站(获取html文件)
- 找到第一期开奖结果(筛选数据)
- 录入excel(数据导出)
- 找到下一期的开奖结果(获取html文件+筛选数据)
- 重复操作3、4步直到录入了所有开奖结果
一步一步来,要获得双色球开奖号码,首先我们需要打开彩票网站
https://kaijiang.500.com/shtml/ssq/20093.shtml
用request库,可以很方便地得到html文件。requests.get()函数返回一个response对象,传递参数url是目标网页地址。requests.get()函数后面加上“.text”,以便将response对象转换成字符串。
import requests
def turn_page():
url = "http://kaijiang.500.com/ssq.shtml"
html = requests.get(url).text
在浏览器打开上述url,右击选择【查看源文件】,通过分析源文件,找到需要爬取的数据,制定合适的爬取方案。从图中可以看到,这个源文件包含了每一期的网页链接,并且所有链接都在一个类名为“iSelectList”的
这意味着我们能够一次就把所有链接保存到一个列表中,之后只需按照列表顺序逐个打开链接爬取数据就可以了。

想要得到html源文件,可以使用BeautifulSoup
BeautifulSoup是一个可以从HTML或XML文件中提取数据的第三方库
BeautifulSoup()函数有两个参数,第一个参数是要解析的HTML/XML代码,第二个参数是解析器。
在这里我们以前面requests.get()返回的html作为第一个参数,'html.parser’是Python内置的解析器(标准库)
解析html后,得到一个BeautifulSoup 的对象,即变量soup
BS支持大部分的CSS选择器,在BS对象的.select()方法传入字符串参数,即可使用CSS选择器的语法查到tag(标签)
前面我们已经知道,开奖号码的页面链接在一个class为“iSelectList”的
而链接是用标签标示的,所以我们在select()方法中传入的参数是“div.iSelectList a”
即,选择所有在class为“iSelectList”的
import requests
from bs4 import BeautifulSoup
def turn_page():
url = "http://kaijiang.500.com/ssq.shtml"
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
pageList = soup.select("div.iSelectList a")
现在我们已经得到包含所有结果链接的标签并赋值给列表变量pageList
用一个for循环语句,遍历pageList中的每一个元素,p[‘href’]用于提取链接,p.string用于提取标签中的字符串(即期数)
import requests
from bs4 import BeautifulSoup
def turn_page():
url = "http://kaijiang.500.com/ssq.shtml"
html = requests.get(url).text soup = BeautifulSoup(html,'html.parser')
pageList = soup.select("div.iSelectList a")
for p in pageList:
url = p['href'] #提取链接
page = p.string #提取字符串
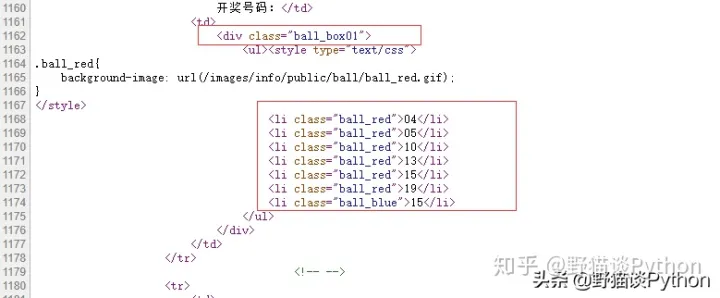
通过观察源文件,发现开奖号码由无序标签(ul li)定义,并且在一个class为“ball_box01”的
声明一个函数download(),形参url是要提取开奖号码的页面链接,page是开奖期数
变量html和soup和前面一样,在此不再赘述
用CSS选择器语法select(‘div.ball_box01 ul li’)得到开奖号码所在的
- 标签,赋值给列表变量list
-
声明一个空的列表变量ball,for循环语句遍历list,提取每一个开奖号码(li.string)并添加到ball列表
def download(url,page): html = requests.get(url).text soup = BeautifulSoup(html,'html.parser') list = soup.select('div.ball_box01 ul li') ball = [] for li in list: ball.append(li.string)声明一个函数write_to_excel(),形参page是开奖期数,ball是相应期数开奖号码
用Python的file方法把每一期的开奖号码写入csv表格文件中
为了避免出现乱码,打开csv文件时加上encoding=“utf_8_sig”
def write_to_excel(page,ball): f = open('双色球开奖结果.csv','a',encoding='utf_8_sig') f.write(f'第{page}期,{ball[0]},{ball[1]},{ball[2]},{ball[3]},{ball[4]},{ball[5]},{ball[6]}\n') f.close()声明函数main(),作为程序入口
如果exists()函数发现存在同名的csv文件,就会删除
在主函数main()调用turn_page()函数
def main(): if(os.path.exists('双色球开奖结果.csv')): os.remove('双色球开奖结果.csv') turn_page()至此,开奖结果的爬取与保存已完成,整合看下结果
完整的代码:
import requests import osfrom bs4 import BeautifulSoup def download(url, page): html = requests.get(url).text soup = BeautifulSoup(html, 'html.parser') list = soup.select('div.ball_box01 ul li') ball = [] for li in list: ball.append(li.string) write_to_excel(page, ball) print(f"第{page}期开奖结果录入完成") def write_to_excel(page, ball): f = open('双色球开奖结果.csv', 'a', encoding='utf_8_sig') f.write(f'第{page}期,{ball[0]},{ball[1]},{ball[2]},{ball[3]},{ball[4]},{ball[5]},{ball[6]}\n') f.close()def turn_page(): url = "http://kaijiang.500.com/ssq.shtml" html = requests.get(url).text soup = BeautifulSoup(html, 'html.parser') pageList = soup.select("div.iSelectList a") for p in pageList: url = p['href'] page = p.string download(url, page)def main(): if (os.path.exists('双色球开奖结果.csv')): os.remove('双色球开奖结果.csv') turn_page()if __name__ == '__main__': main()运行结果如下:
看下是否有保存

我们打开这个工作表,是不是有数据了?为什么只有这么点数据呢,原因是小编只需要2020年的开奖结果,所以就手动停止了程序。
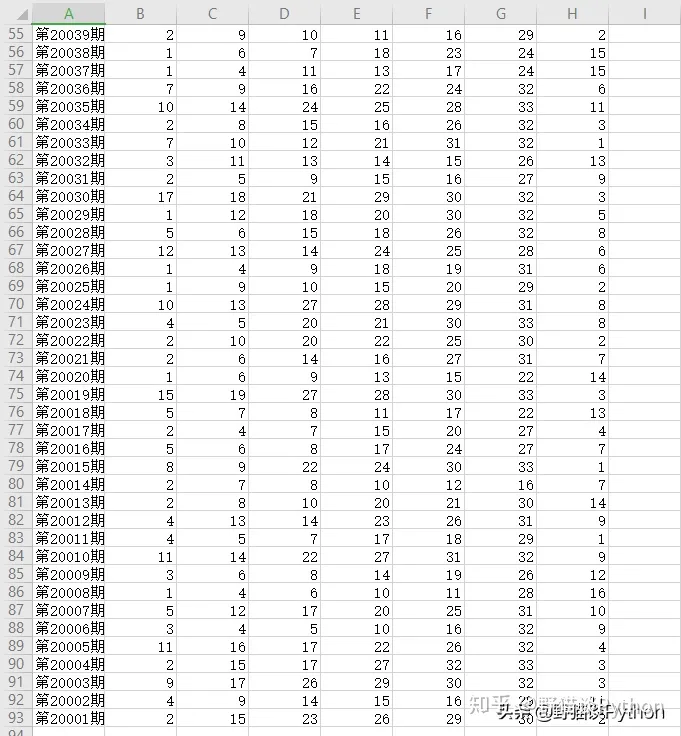
来吧,数据有了,我们来进行数据分析
下面就统计下蓝球在今年出现的频率,并实现数据可视化,直接撸(代码里面有解释)
import pandas as pd import numpy as npimport matplotlib.pyplot as plt#读取双色球开奖结果.csv文件df = pd.read_table('双色球开奖结果.csv',header=None,sep=',') # print df # print df[1:3] #第2到第3行(索引0开始为第一行,1代表第二行,不包含第四行) # print df.loc[0:10,:] #第1行到第9行的全部列 # print df.loc[:,[0,7]] #全部行的第1和第8列 tdate = sorted(df.loc[:,0]) #取第一列数据 # print tdate tdate1 = [] #将tdate数据读取到列表中for i in tdate: tdate1.append(i) print(tdate1) # s = pd.Series(tdate1, index=tdate1)s = pd.Series(range(1,len(tdate1)+1), index=tdate1) #将期数转换为对应的数值从1开始 # print s tblue = list(reversed(df.loc[:,7])) #对数据取反 print(tblue) fenzu = pd.value_counts(tblue,ascending=False) #将数据进行分组统计,按照统计数降序排序print(fenzu) x=list(fenzu.index[:]) #获取蓝色号码y=list(fenzu.values[:]) #获得蓝色统计数量print(x) print(y) # print type(fenzu) plt.figure(figsize=(10,6),dpi=70) #配置画图大小、和细度 plt.legend(loc='best') # plt.plot(fenzu,color='red') #线图 plt.bar(x,y,alpha=.5, color='b',width=0.8) #直方图参数设置 plt.title('The blue ball number') #标题 plt.xlabel('blue number') #x轴内容 plt.ylabel('times') #y轴内容 plt.show() #显示图运行结果如下:
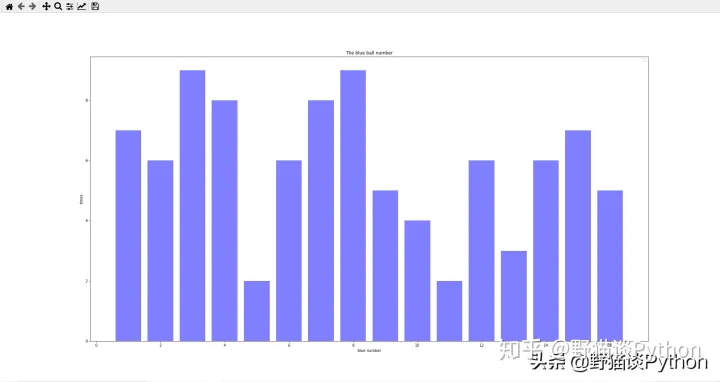
可以看到,2020年的开奖结果中,蓝球出现次数最多的是3与8,出现了9次。
红球的来了,往下看
import pandas as pd import numpy as npimport matplotlib.pyplot as plt#读取文件df = pd.read_table('双色球开奖结果.csv',header=None,sep=',') # print df # print df[1:3] # print df.loc[0:10,:] # print df.loc[:,1:6] tdate = sorted(df.loc[:,0]) # print tdate h1 = df.loc[:,1] h2 = df.loc[:,2] h3 = df.loc[:,3] h4 = df.loc[:,4] h5 = df.loc[:,5] h6 = df.loc[:,6] #将数据合并到一起all = h1.append(h2).append(h3).append(h4).append(h5).append(h6) alldata = list(all)print(len(alldata)) fenzu = pd.value_counts(all,ascending=False)print(fenzu) x=list(fenzu.index[:])y=list(fenzu.values[:])print(x) print(y) # print type(fenzu) plt.figure(figsize=(10,6),dpi=70) plt.legend(loc='best',) # plt.plot(fenzu,color='red') plt.bar(x,y,alpha=.5, color='r',width=0.8) plt.title('The red ball number') plt.xlabel('red number') plt.ylabel('times') plt.show()结果如下:
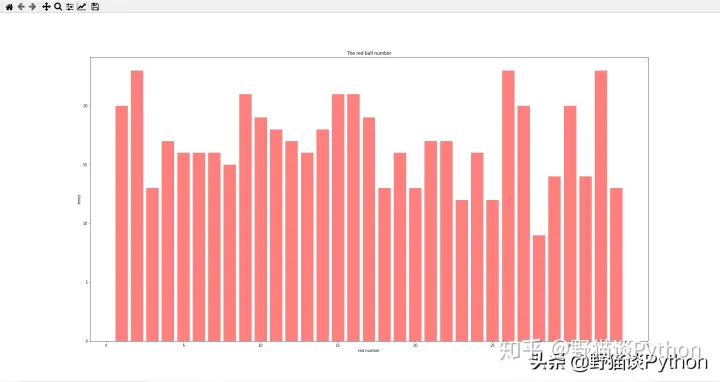
可以看到,2020年的开奖结果中,红球出现次数最多的是2,9,15,16,26,32这六个数。很简单的一个案例,学习为主,脚踏实地,打铁还需自身硬呢,多学点技术,充实自己,还怕老板不给高工资吗?
一个简单的爬虫和数据分析分享给大家,想自己练习的直接复制代码就行了,除了统计还可以试一下用线性回归算法预测下一期的数据,学习为主,切勿当真,感谢每一个一直都在支持我的小可爱,谢谢你们一直的陪伴!
最后:关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
👉[[CSDN大礼包:《python安装包&全套学习资料》免费分享]](安全链接,放心点击)

Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

入门学习视频

Python实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









