









今天继续分享我们的 SD 图生图功能哦,图生图我们分成两篇来分享哦,要不然都塞一篇里,我怕大家看不下去,嗯,是的,就是这个原因!!!
图生图呢,顾名思义,就是在原图的基础上进行升级重绘。讲的这么简单,其实功能还是有些许复杂的。
那我们废话不多说,直接开整。
—
我们可以看到,图生图相比文生图多了一些功能,接下来我们就来一个一个介绍哈。
「CLIP 反推」和「DeepBooru 反推」:让 SD 通过图片反向推导出提示词。我们以下下边这张图片为例:

「CLIP 反推」效果:a digital painting of a woman with long hair and a necklace on her neck and a necklace on her neck 「一幅长发女人的数字画,脖子上戴着项链,脖子上戴着项链」
「DeepBooru 反推」效果:1girl, artist_name, blurry, blurry_background, closed_mouth, curly_hair, depth_of_field, earrings, jewelry, lips, long_hair, looking_at_viewer, messy_hair, necklace, pendant, solo, wavy_hair「1女孩,艺术家名称,模糊,模糊的背景,闭着嘴,卷发,景深,耳环,珠宝,嘴唇,长发,看着观众,凌乱的头发,项链,吊坠,独奏,波浪发」
可以看到「DeepBooru 反推」更贴向于 SD 的提示词风格,并且描述更加细致。「CLIP 反推」则更加口语化。
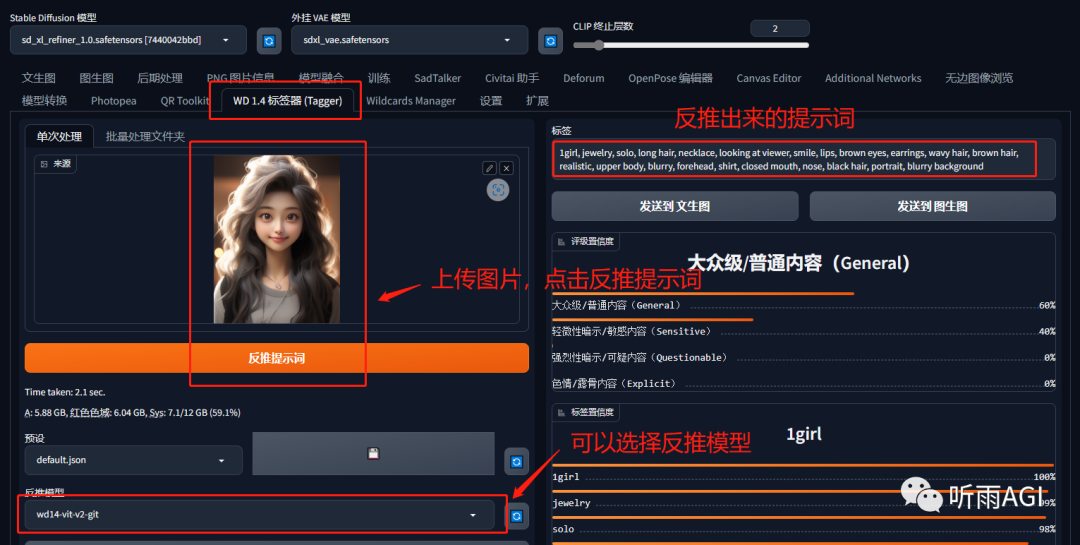
说到这里呢,推荐大家一个插件哦「WD 1.4 标签器」,它的功能也是反推提示词,效果比上边两种都要好喔,推荐大家使用它。在扩展中插件搜索中输入「tagger」,出来的第一个就是,安装重启。
「WD 1.4 标签器」效果:1girl, jewelry, solo, long hair, necklace, looking at viewer, smile, lips, brown eyes, earrings, wavy hair, brown hair, realistic, upper body, blurry, forehead, shirt, closed mouth, nose, black hair, portrait, blurry background「1女孩,珠宝,独唱,长发,项链,看着观众,微笑,嘴唇,棕色眼睛,耳环,波浪发,棕色头发,逼真,上身,模糊,前额,衬衫,闭口,鼻子,黑色头发,肖像,模糊背景」
—
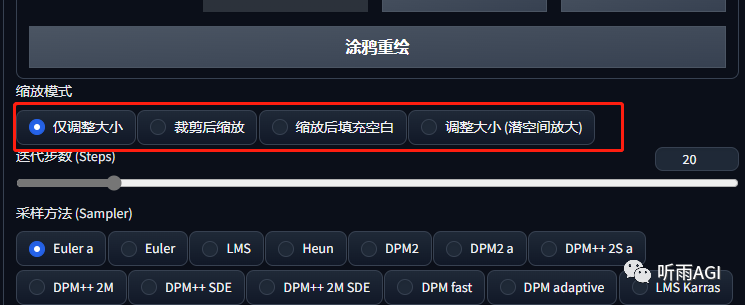
打住,又跑歪了,我们继续我们的图生图哈。我们可以看到在迭代步数上边,相比文生图功能多了一个缩放模式,我们先来说说这个缩放模式吧。
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3418322614, Size: 512x512, Model hash: 7440042bbd, Model: sd_xl_refiner_1.0, Denoising strength: 0, Clip skip: 2, ENSD: 31337, Version: v1.5.1
以下配置统一:重绘幅度设置为0,输出分辨率512*512
仅调整大小: 可以看到人物出现了变形。

裁剪后缩放: 裁剪掉了上下两边内容,如果是横向图的话,就是裁剪到左右两边的内容。

缩放后填充空白: 先把图片缩小指定的尺寸,然后再填充空白的部分,可以看到原图像的左右部分被填充了,大家仔细看应该还能看到填充的痕迹,问题不大,后续都可以调整。

调整大小「潜空间放大」: 这个也是和「仅调整大小」的区别就是会有很大的随机性,比如生成这样的,这张图我都不想放出来

—
重绘幅度: 也叫做降噪强度,主要是控制最终出图效果和原图的相似程度。数值越小,与原图越相似;数值越大,与原图的相似度越低。
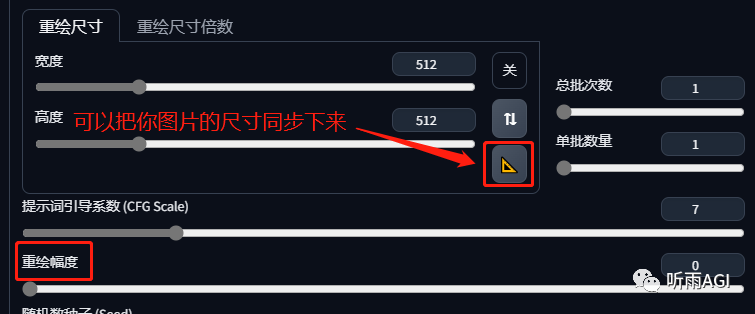
重绘幅度:0

重绘幅度:0.2

重绘幅度:0.4

重绘幅度:0.7

后续的出图就比较怪异了,我这里就不放了,小伙伴们有兴趣的可以自行体验哦。小伙伴们可以多调试一下,选择一个合适自己的参数值。小伙伴们也可以通过调整提示词来实现自己想要的效果。
—
涂鸦: 相当于我们画一个草图,涂鸦功能可以帮我们把草图融入我们的图片里。
可以看到在涂鸦栏里上传图片以后,右上角可以看到有5个按钮。
「1」回退,相当于撤销,可以一步一步撤销。
「2」橡皮擦,回到图片的初始状态,相当于全部撤销。
「3」删除,删除上传的图片。
「4」画笔大小,可以控制你画笔的大小,粗细。
「5」调色板,你的草图最终呈现的颜色

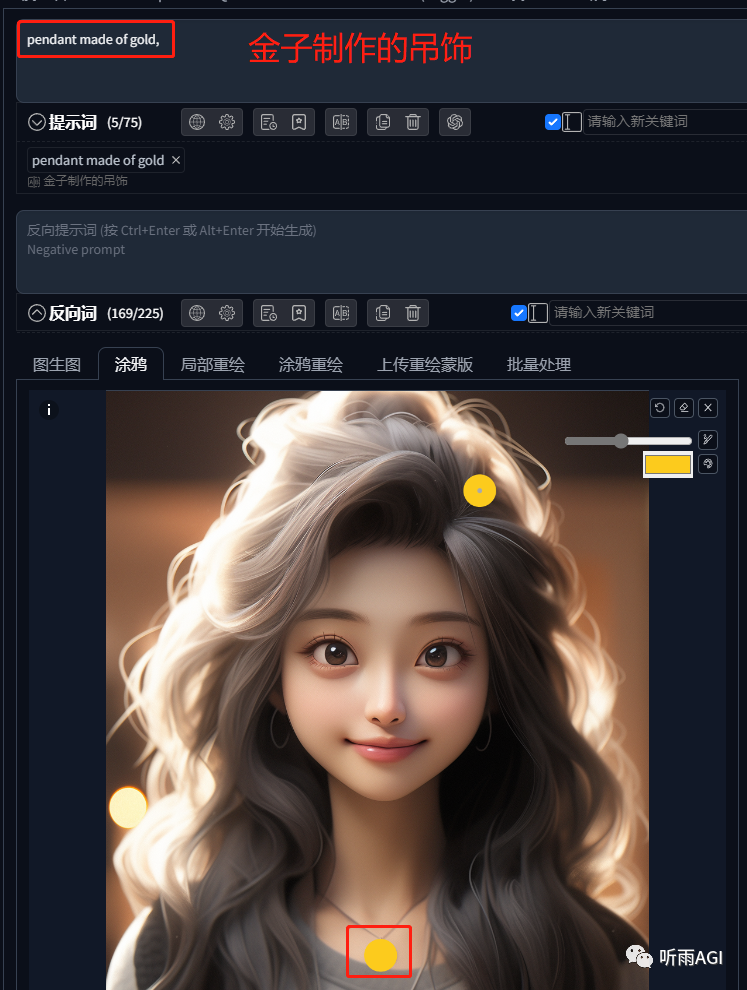
涂鸦功能是全图绘制,所以人物形象也会有所变化,想要人物不变的话,就要使用「局部涂鸦绘制」,这个我们下一篇会讲到。

今天的分享就先到这里了哦,小伙伴们动手动起来!
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍代码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入门stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









