









Spring循环依如何解决?
循环依赖是什么?
class A{
B b;
}
class B{
A a;
}
//简单来说就是A的创建依赖于B,B的创建依赖于A。
在一般场景下,如何解决循环依赖的问题?
我们知道对象的创建一般有:
无参构造器+属性Set方法初始化对象
有参构造器直接初始化对象
//通过有参构造器初始化
class A{
B b;
public A(B b) {
this.b = b;
}
}
class B{
A a;
public B(A a) {
this.a = a;
}
}
class client{
//我们发现会无限套娃下去,有参构造器方法不能使用
new A(new B(new A(new B())))
}
//通过无参参构造器初始化
class A{
B b;
public void setB(B b) {
this.b = b;
}
}
class B{
A a;
public void setA(A a) {
this.a = a;
}
}
class client{
//可以发现无参构造器+set方法可以完成任务
A a = new a();
B b = new b();
a.setB(b);
b.setA(a);
}
通过上面的场景,我们就可以知道利用Set方法可以解决循环依赖,那在Spring中也是如此,但增加了亿丝细节
我们在使用Spring时,常讲Spring容器,也就是我们不去new对象,而是从容器中取对象,那这个容器到底是什么?
容器顾名思义,就是存放数据对象的地方,又是在内存中的,每次我们向容器里取对象时都会提供一个对象名,或者是类型信息,然后容器返回相应的数据,那在Java基础中,我们学习到的Map结构,就很符合这样要求,通过Key,Value来存储对象信息。所以其实Spring容器就是通过一个Map来实现的,也就是这个家伙Map<String, Object> singletonObjects,但更确切的来说它叫做一级缓存,专门存放已经完整经过生命周期的对象(对象初始化后,参数也赋值了)。那既然有一级缓存就可能有其他级缓存,确实Spring有三层缓存,而这三层缓存就是来解决循环依赖的关键!!!
三级缓存为哪三级,分别是干嘛的?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
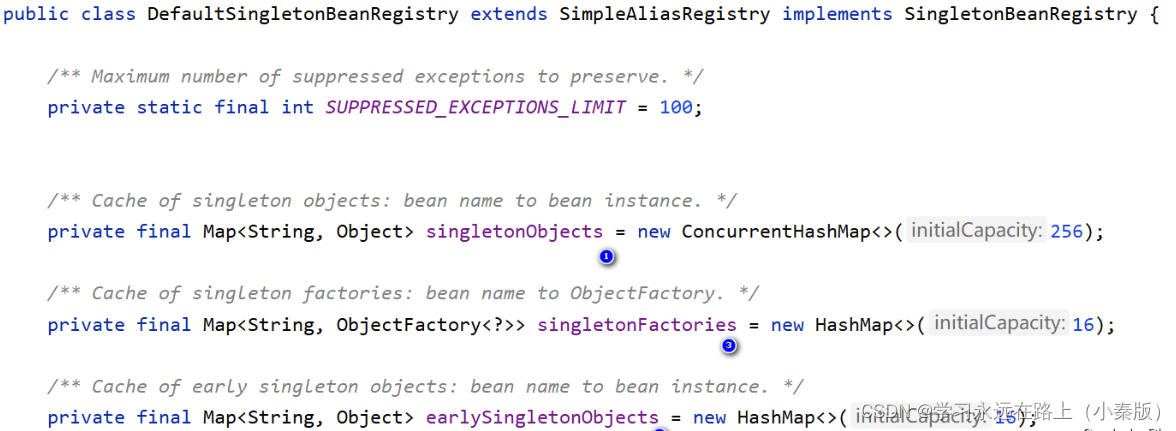
上图就Spring中的源码,三个Map对象的就是三级缓存
singletonObjects:一级缓存存放完整生命周期的Bean,我们从容器中取对象,就从这里找的。earlySingletonObjects:二级缓存存放半生命周期的Bean,可以理解为通过无参构造器想堆空间申请内存了,但是没有对属性赋值。singletonFactories:三级缓存存放创建Bean的工厂。
我们知道Spring容器中可以设置对象为多例模式和单例模式,每种模式都可以解决循环依赖问题吗?
单例模式我们知道是存放在一级缓存中的,那prototype模式的对象是否也在一级缓存中?
下面我们先来看看当创建prototype对象时,底层发生了什么
public <T> T getBean(String name, Class<T> requiredType) throws BeansException {
this.assertBeanFactoryActive();
//获取目标bean
return this.getBeanFactory().getBean(name, requiredType);
}
@Override
public <T> T getBean(String name, Class<T> requiredType) throws BeansException {
//一般do开头的方法都是干实事儿的,重点关注
return doGetBean(name, requiredType, null, false);
}
// Eagerly check singleton cache for manually registered singletons.
// 可以看到不管是不是单例模式都会来一级缓存寻找,但是这里没有找到
Object sharedInstance = getSingleton(beanName);
if (!typeCheckOnly) {
//标记对象是否之前创建过了
markBeanAsCreated(beanName);
}
//这里只有第一次创建时会进来,标记为该类型对象已经创建,第二次获取bean实例时就知道之前已经创建了,直接退出
protected void markBeanAsCreated(String beanName) {
if (!this.alreadyCreated.contains(beanName)) {
synchronized (this.mergedBeanDefinitions) {
if (!this.alreadyCreated.contains(beanName)) {
// Let the bean definition get re-merged now that we're actually creating
// the bean... just in case some of its metadata changed in the meantime.
clearMergedBeanDefinition(beanName);
//这里记录之前创建过的对象
this.alreadyCreated.add(beanName);
}
}
}
}
//判断是否为isPrototypel类型对象
else if (mbd.isPrototype()) {
// It's a prototype -> create a new instance.
Object prototypeInstance = null;
try {
beforePrototypeCreation(beanName);
//这里就要创建prototypeInstance实例了
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
//重点
bean = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
}
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
if (logger.isTraceEnabled()) {
logger.trace("Creating instance of bean '" + beanName + "'");
}
RootBeanDefinition mbdToUse = mbd;
// Make sure bean class is actually resolved at this point, and
//在动态解析类的情况下克隆bean定义
// clone the bean definition in case of a dynamically resolved Class
// which cannot be stored in the shared merged bean definition.
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
// Prepare method overrides.
try {
mbdToUse.prepareMethodOverrides();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(),
beanName, "Validation of method overrides failed", ex);
}
try {
// Give BeanPostProcessors a chance to return a proxy instead of the target bean instance.
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
catch (Throwable ex) {
throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName,
"BeanPostProcessor before instantiation of bean failed", ex);
}
try {
//这里do开头,是重点
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isTraceEnabled()) {
logger.trace("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
// No special handling: simply use no-arg constructor.
//要通过无参构造器创建了
return instantiateBean(beanName, mbd);
//获取实例化策略,然后实例化对象
beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, parent);
/**
* Return the instantiation strategy to use for creating bean instances.
*/
protected InstantiationStrategy getInstantiationStrategy() {
return this.instantiationStrategy;
}
//马上要创建了
return BeanUtils.instantiateClass(constructorToUse);
//利用反射要真正创建实例了
return ctor.newInstance(argsWithDefaultValues);
public class A {
private B b;
public B getB() {
return b;
}
public void setB(B b) {
this.b = b;
}
//进入A的无参构造器,实例化对象
public A() {
System.out.println("---A created success");
}
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
//填充属性
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
以上断点代码就是Spring中的源码显示,大家感兴趣,也可以自己打一遍。
小总结:
- 我们可以看到为什么当变量设置为prototype时,每次返回的对象都不一样.
- 因为在Spring容器中根本没有缓存之前的对象,而是每次都实例一个新的对象进行返回。
- 而在单例模式时,会将对象放到缓存中,这样你下次再要对象时,直接从一级缓存中找。
- prototype也叫做原型,很多人以为是利用了原型设计模式,存第一次创建的实例,然后每次拷贝一个新的返回。
- 但根据源码阅读发现创建的实例根本没有存储在容器中,哪来的拷贝。
不看源码你就被坑了,但是也不要相信我的话,你最好自己再看一遍。 - 推荐一个博主写的文章:https://blog.csdn.net/FanYien/article/details/117898188。
- 但根据源码阅读发现创建的实例根本没有存储在容器中,哪来的拷贝。
- 那prototype能解决循环依赖问题吗?
- 不能,因为假如说A类中有一个B属性需要注入,当实例化A时需要注入B,而B现在没有,需要先实例一个B对象,实例B的时候一个A注入,但容器中找不到之前创建的A,所以需要自己再实例一个A对象,循环往复,因为每次返回的对象都不同。Spring官网也明确禁止了。
- 所以我们说Spring解决循环依赖的前提是对象是单例模式下的,并通过Set方法构建。
- 那单例模式下是如何解决循环依赖的?
- 这里推荐另一个博主写的,写的非常详细:https://blog.csdn.net/oneby1314/article/details/113789384
- 其实总结下来就是,利用三层缓存来解决,现在容器需要注入一个A对象时,先去一级缓存中找,没有的话则容器直接实例化一个A(没有对属性赋值)并放入三级缓存,当需要注入A对象的B时,也去容器找,没有的话再实例化一个B,当给B对象的A赋值时,也去一级缓存找,没有则去二级缓存找,再没有去三级缓存,这是发现找到了之前的A,则直接注入,B这就算完整了放在一级缓存,又回到A的初始化,去一级缓存找,发现有一个B,则对A也初始化。这样循环依赖就解决掉了。具体可以看上面博主的文章。
- 看完后突然感觉似乎一层缓存也可以解决循环依赖问题,为什么Spring要用三层?
- 这里我是看了https://juejin.cn/post/6930904292958142478这位博主的文章才理解一些
- 大致是说三级缓存是Spring在结合
AOP跟Bean的生命周期的设计,保证如果需要代理时,保证在Bean生命周期最后一步再完成代理。
总结
这算是我第一次自己读Spring源码,在之前一般遇到问题我都是看有没有别人的总结,觉的源码我肯定看不了,看别人的总结又方便又快捷。今天是因为当我再来回顾这些知识的时候,脑子里出现很多问题,感觉作者并没有说清楚,而且众说纷纭,那我们就自己做实验,自己去寻找答案吧,虽然开始做是耗时耗力,但能让你的心慢慢沉下来,浮躁是读不了源码的,感谢之前一位朋友的建议,生活上我们很多事情不需要太较真,但学习必须较真!!!,文笔有限,如果觉得哪里写的有问题,也欢迎提醒我进行修改。最后建议大家,全信书不如无书,自己去打断点看源码得到的才是最真实的。















 3760
3760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









