






self-attention
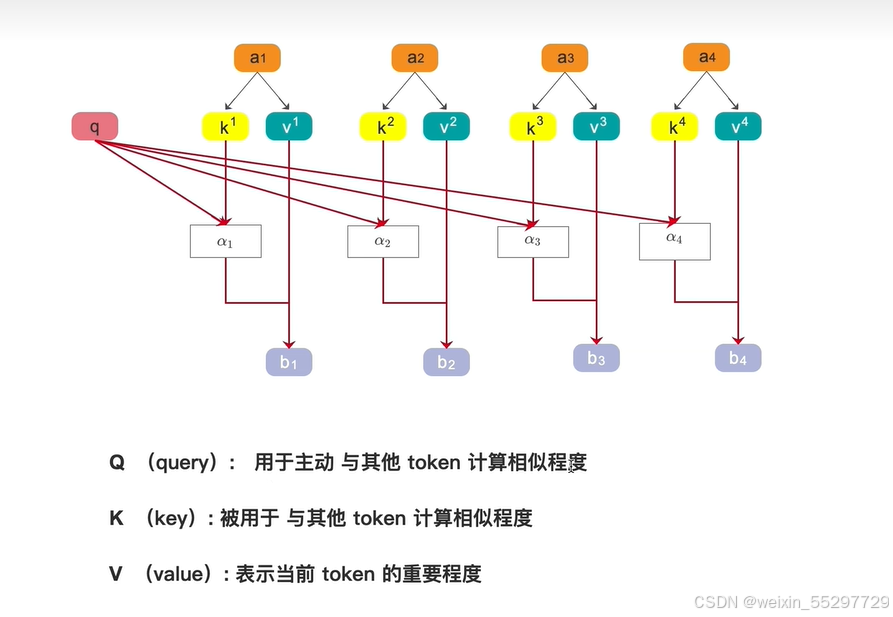
QKV的理解
以购物软件中的商品查询机制为例,输入query,会返回得分从高到低的排序。总分由相似度和value计算得出,相似度又由query和key做计算得出。

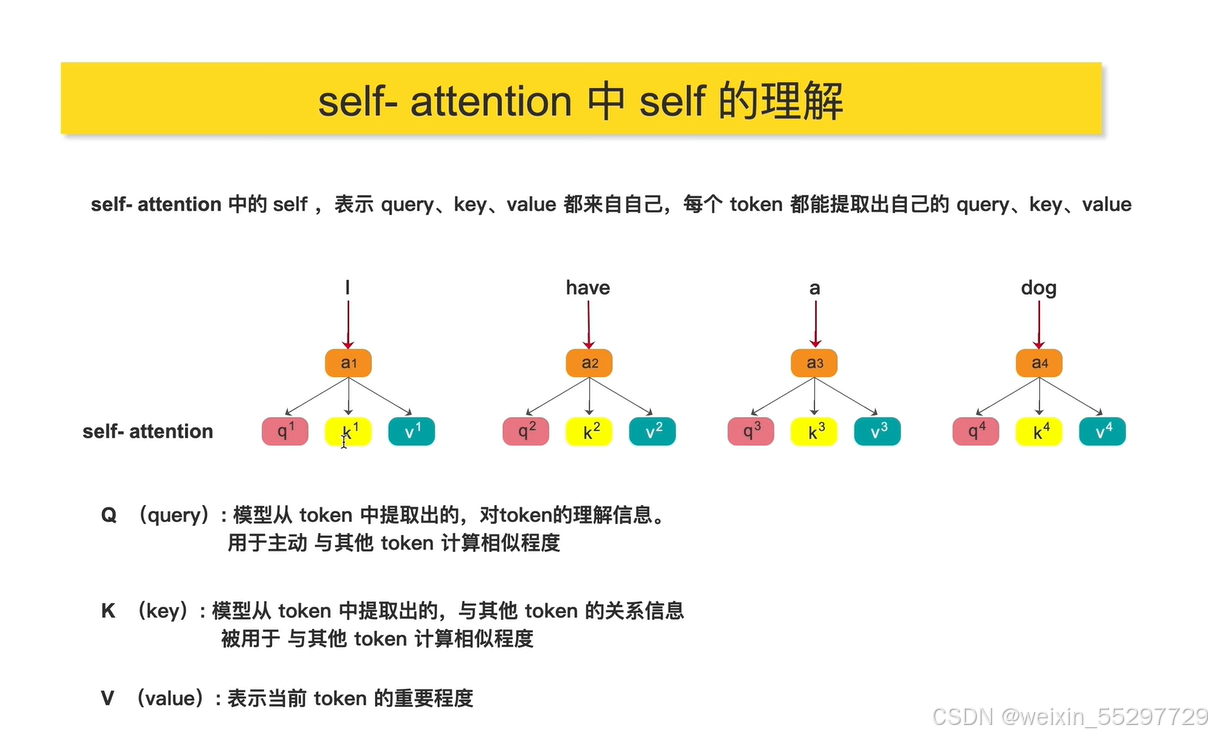
自注意力机制中的query来自于自己
用一个token的query和另一个token的key相乘获取两个token的相似度
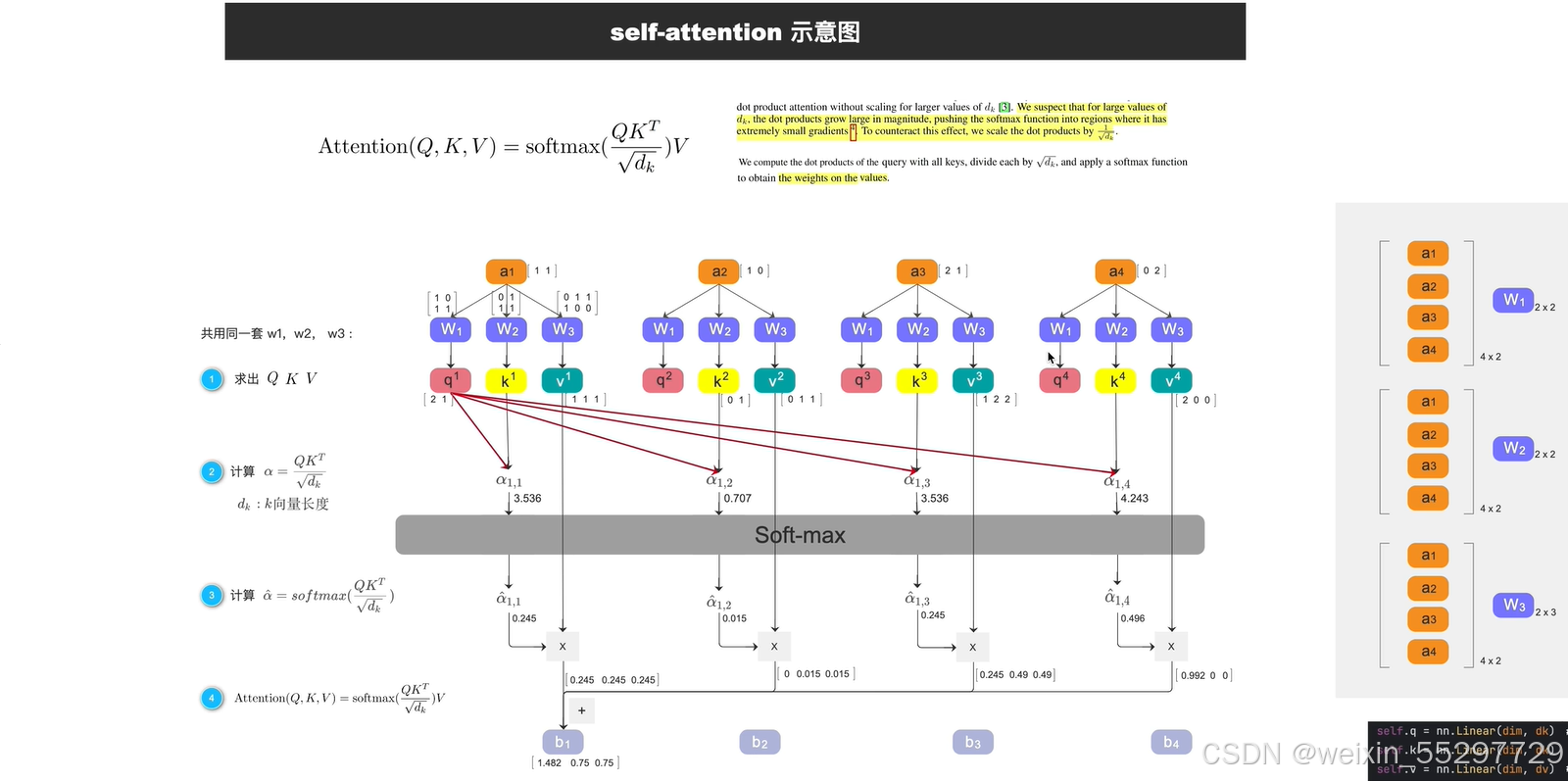
计算过程
以a1举例
- 首先用q1和所有token的k做乘法操作
- 得到的结果送入soft-max分类器
- soft-max的各个输出与对应token的v做乘法
- 相加得到最终的结果b1
如此往复可以得到全部的四个b
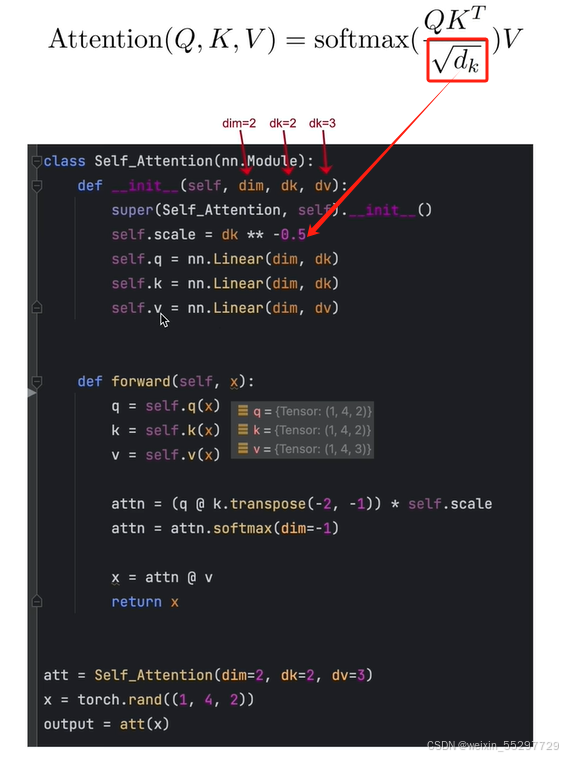
代码实现
需要保证q的维度和v的维度相同,因为后续要做乘法运算
位置编码
为了解决token调换位置对最终输出b不会造成影响的问题提出了位置编码
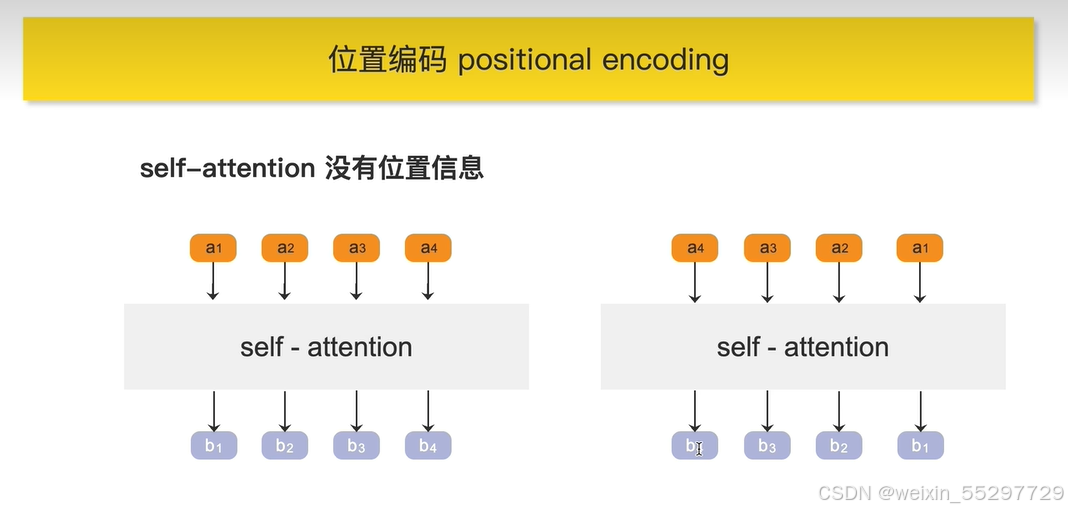
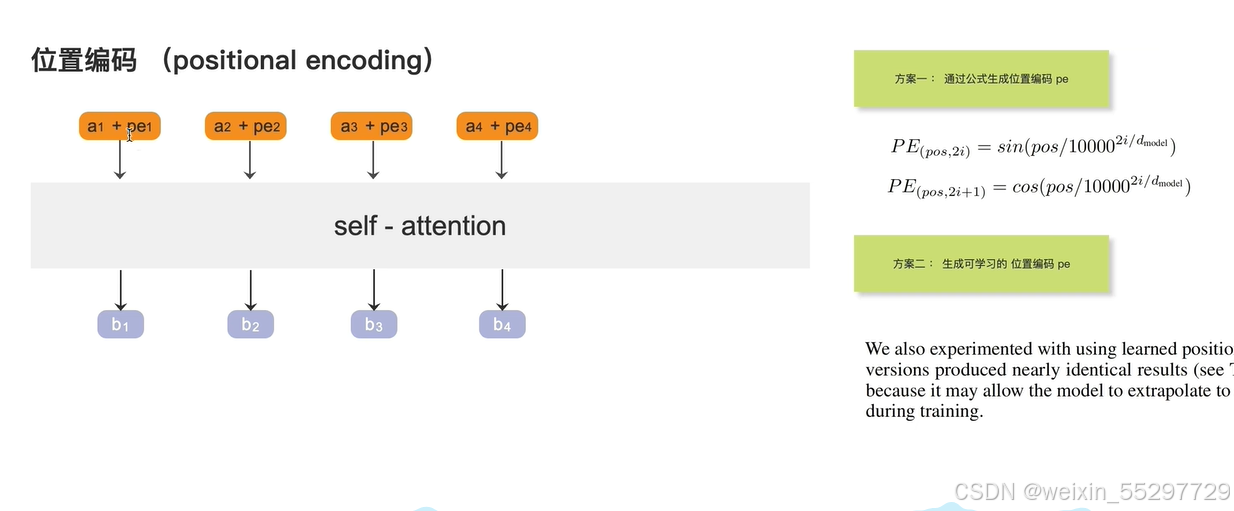
位置编码生成后直接加在对应token上
生成方法有两种:
- 通过公式生成奇数位置和偶数位置的编码
- 生成可学习的位置编码
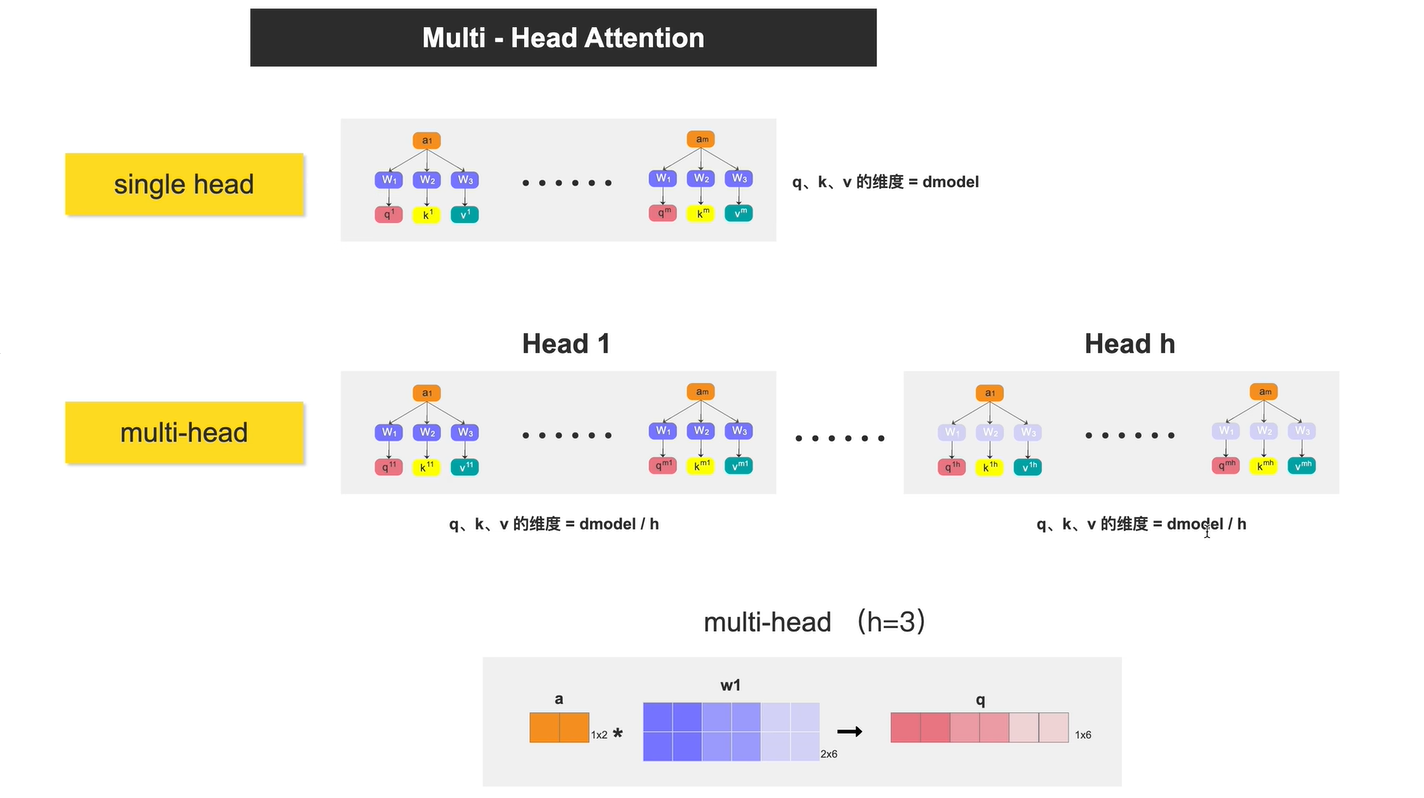
muti-head attention
计算过程
实现方法为把w分为head份,a和w相乘得到对应的head个q,例如图中a[1,2],w1[2,2x3]分成3份,a与w1相乘得到q[1,2x3]
另一种表示:也可以看成是把单头注意力生成的q,k,v分成head份
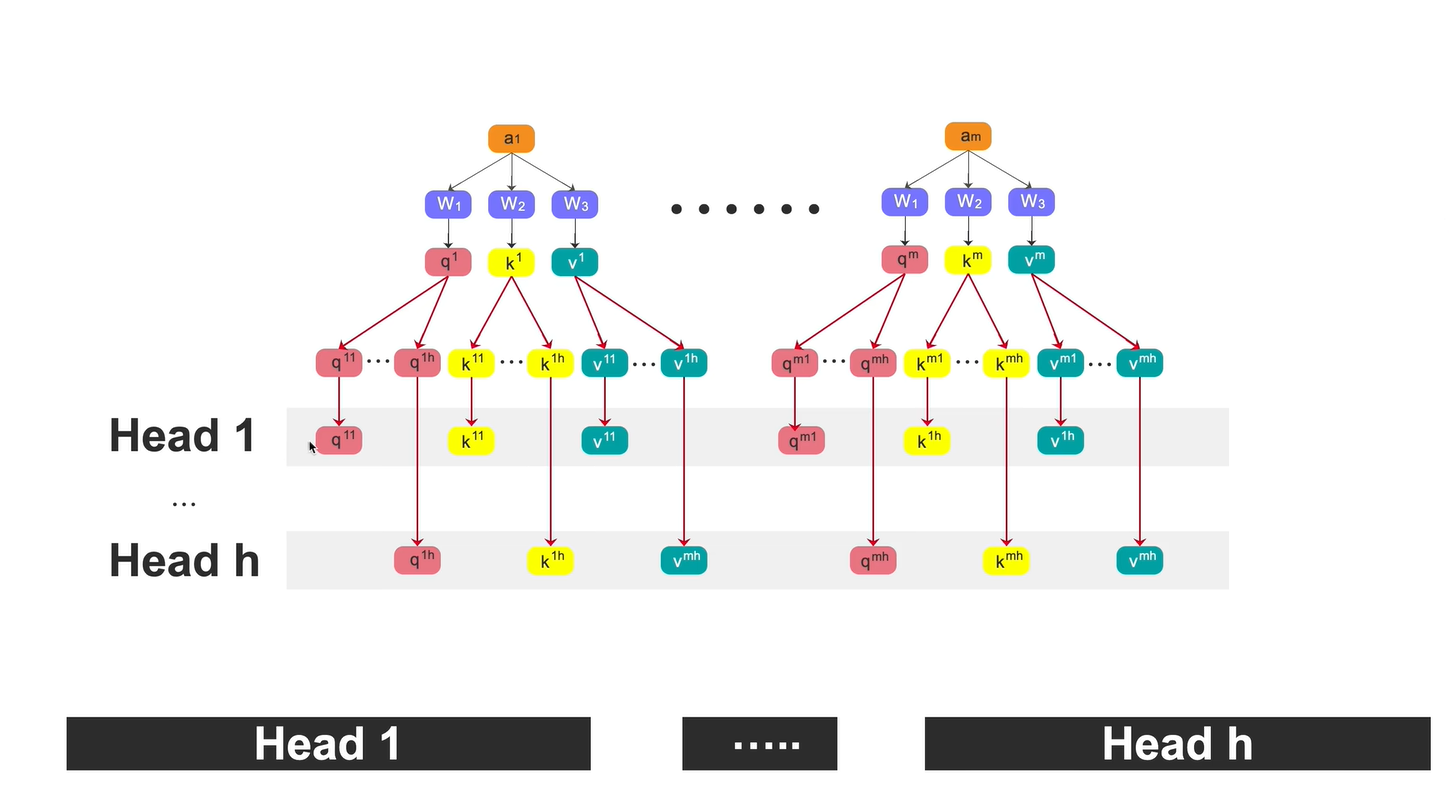
之后每个head分别做自注意力机制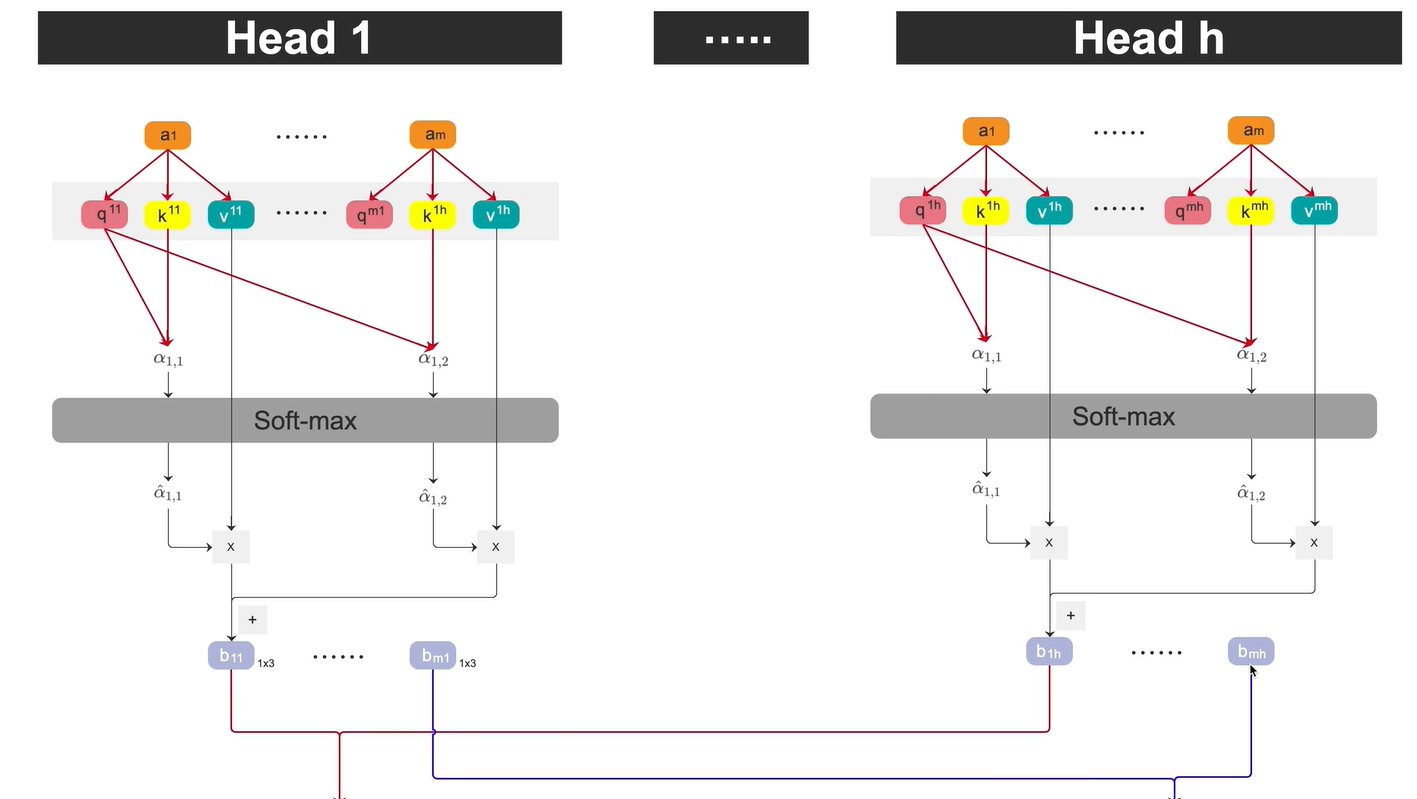
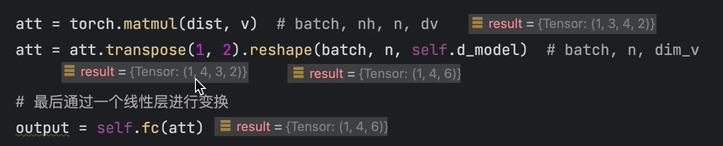
将每个头对应位置的b concat得到新的b1-bm,再将b1-bm做一次全连接
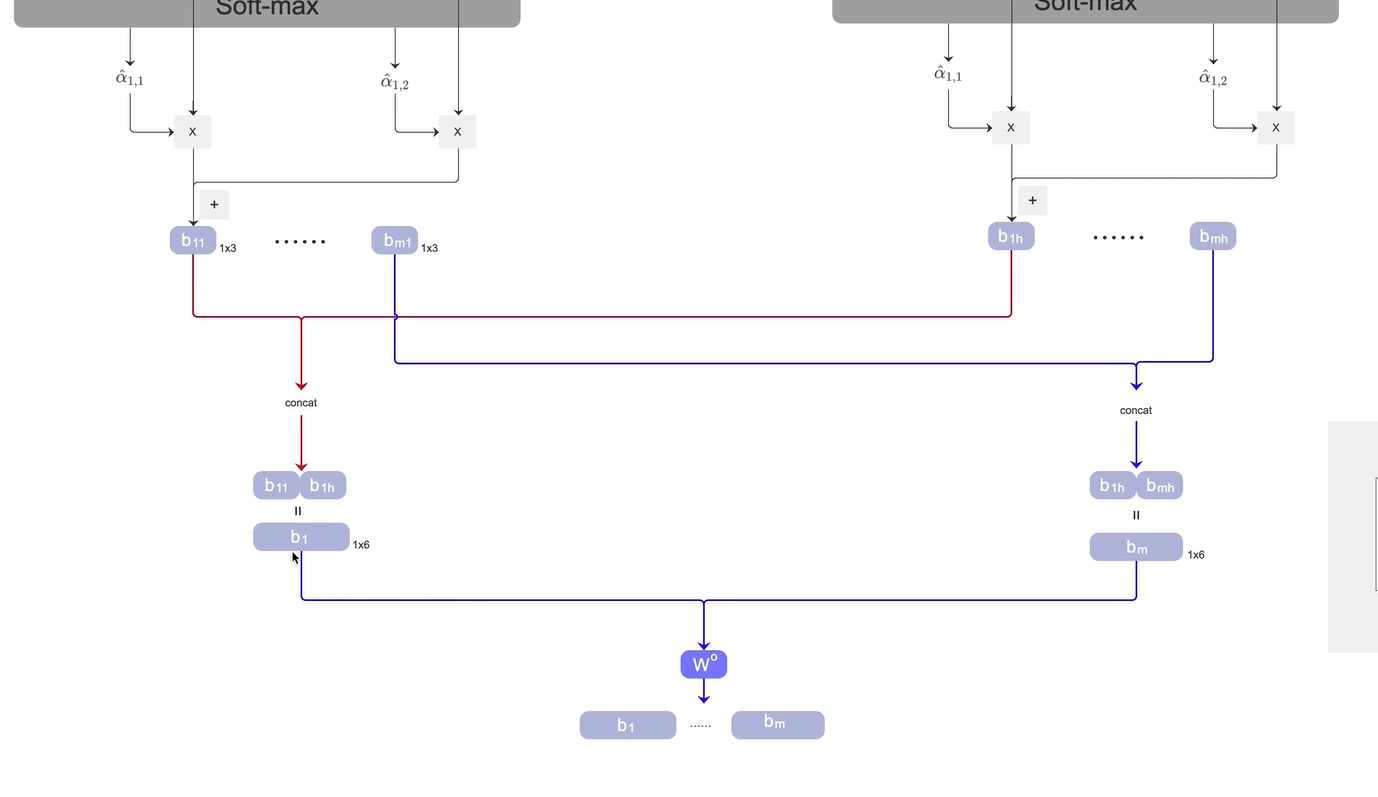
代码实现
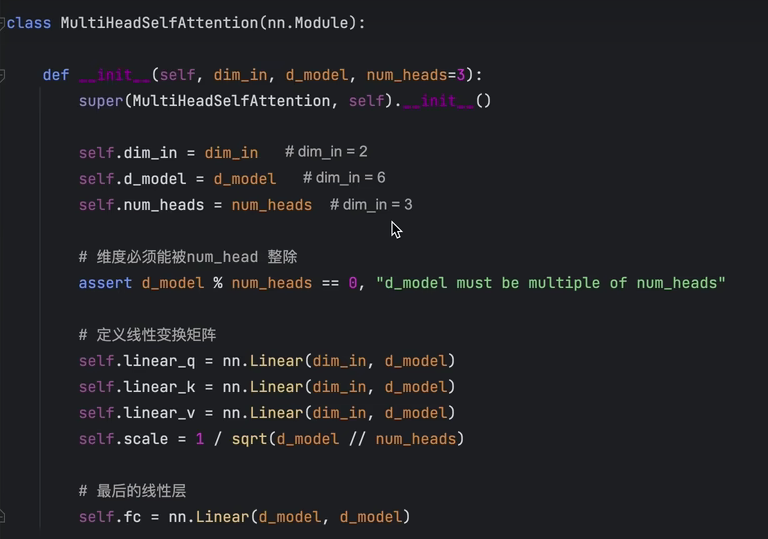
随机生成一个batch为1,token个数为4,token长度为2的tensor

dim_in,d_model都是向量长度,dim_in是输入的token长度,d_model是token生成的q,k,v的长度。num_heads是多头注意力的头个数
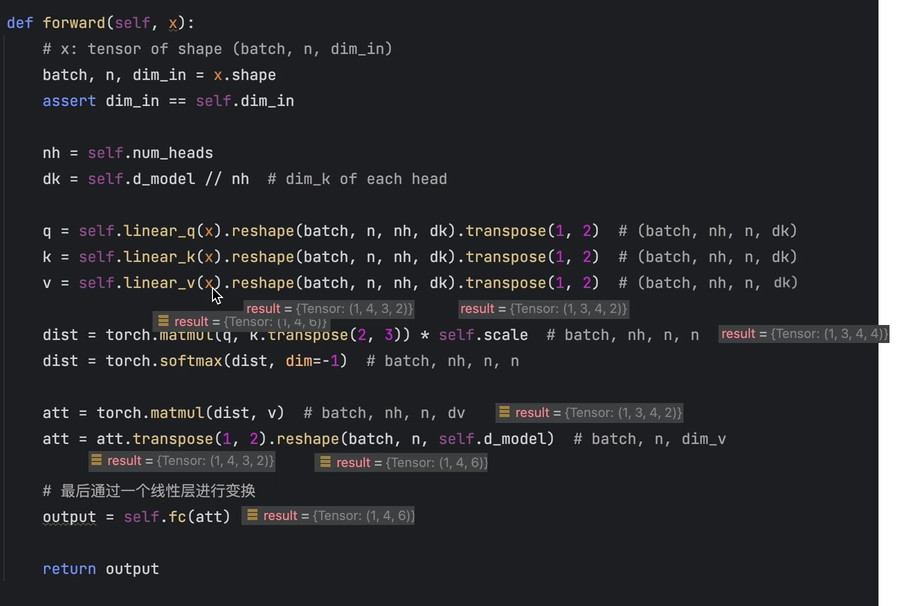
forward中可以看到qkv的维度变化:
- 经过全连接由[1,4,2] -> [1,4,6]
- 经过reshape将d_model=6拆解为(nh=3)x(dk=2)这里d_model是单头的q,k,v维度,多头注意力将其分为nh=3份,每个头的q,k,v最后一维为dk=2,转换后的维度为[1,4,3,2]
- 再通过transpose将nh和n位置互换,将nh维度提前用于做多头的并行计算,变换后维度为[1,3,4,2]
相似度分数dist计算:

注意力计算

















 1512
1512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









