






该文档围绕 DeepSeek 展开多方面的介绍与分析,主要内容如下:
DeepSeek 概述
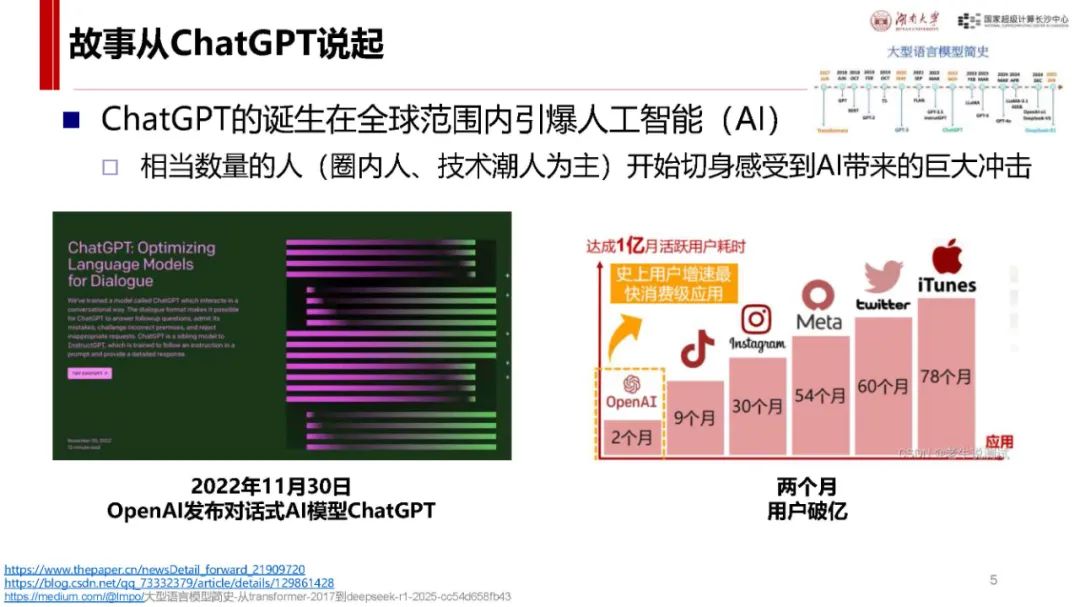
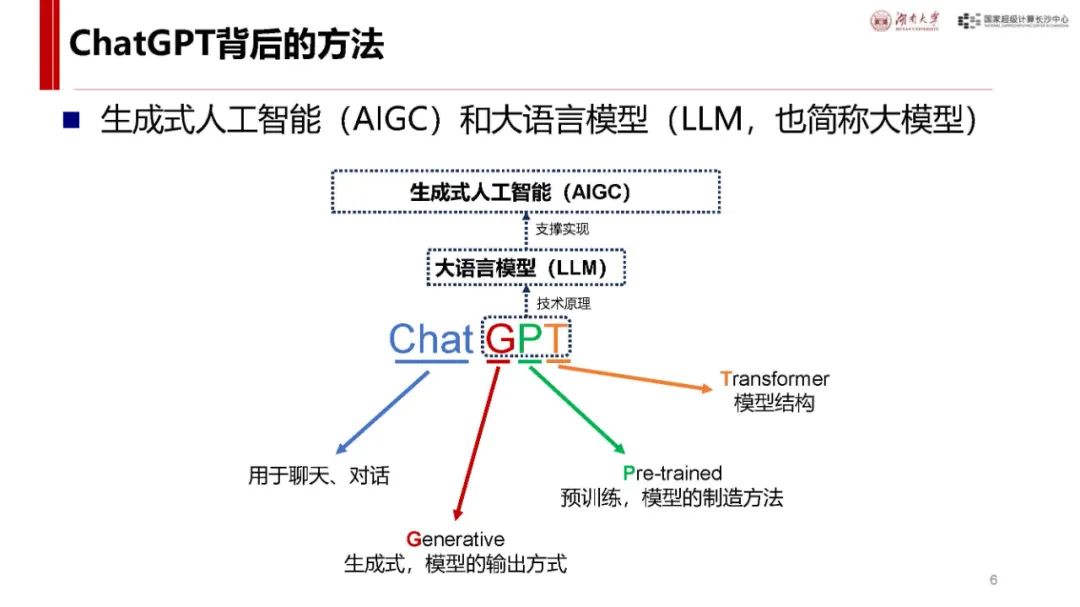
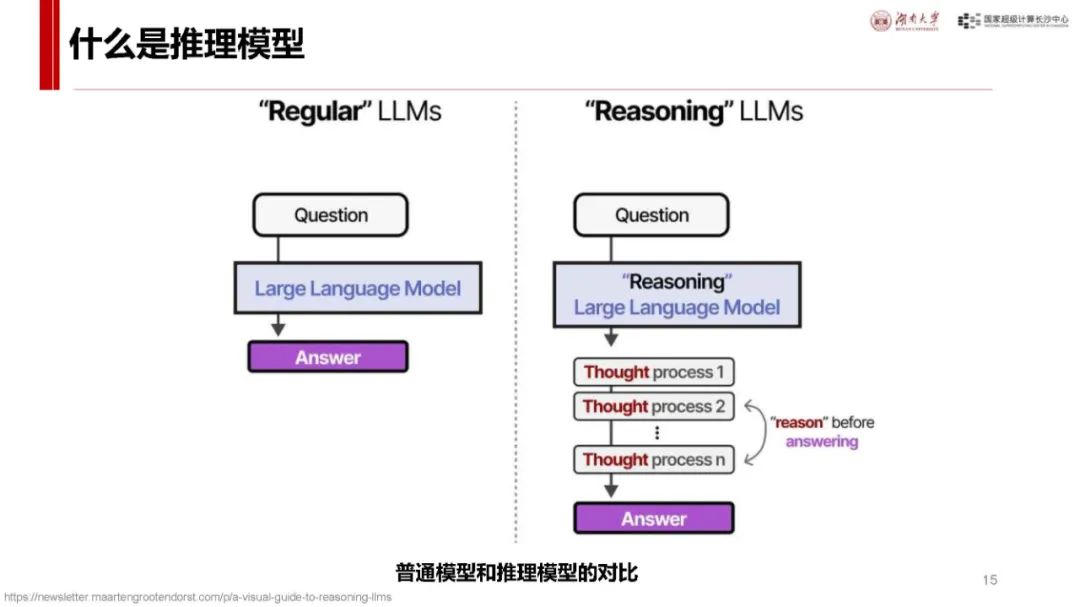
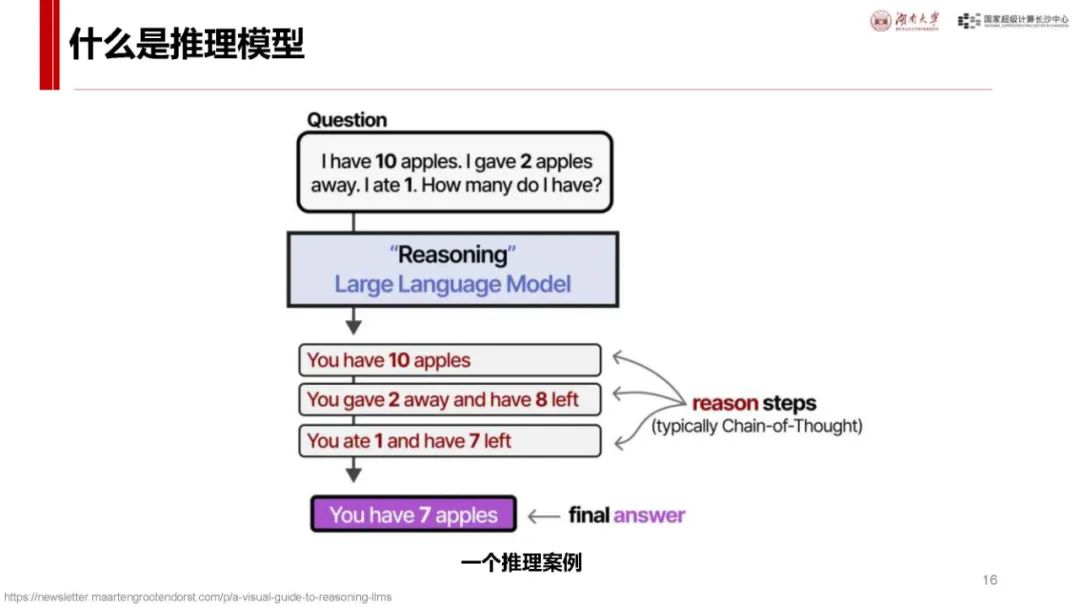
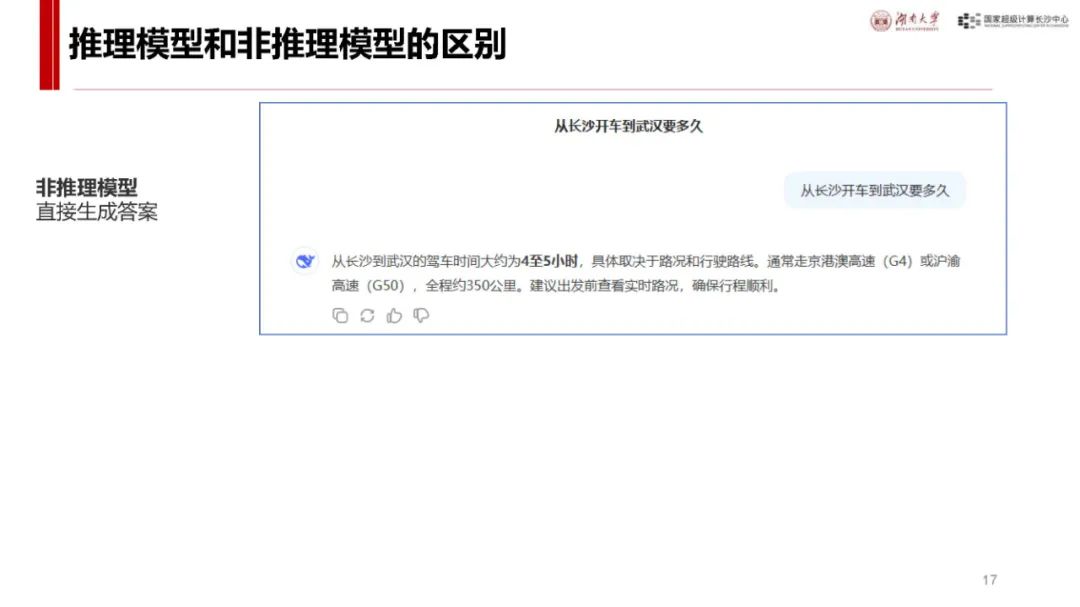
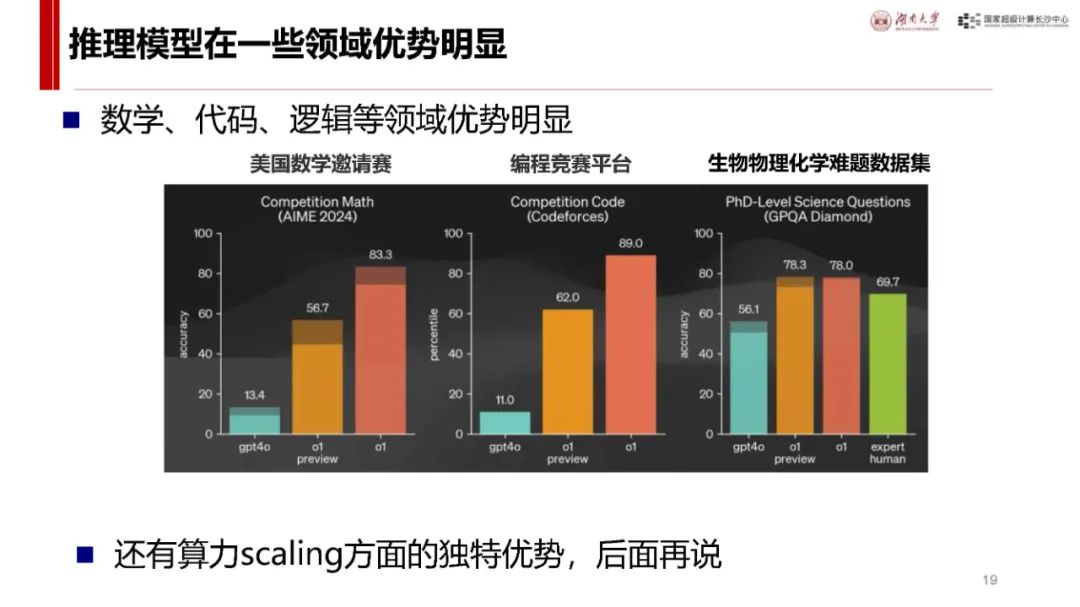
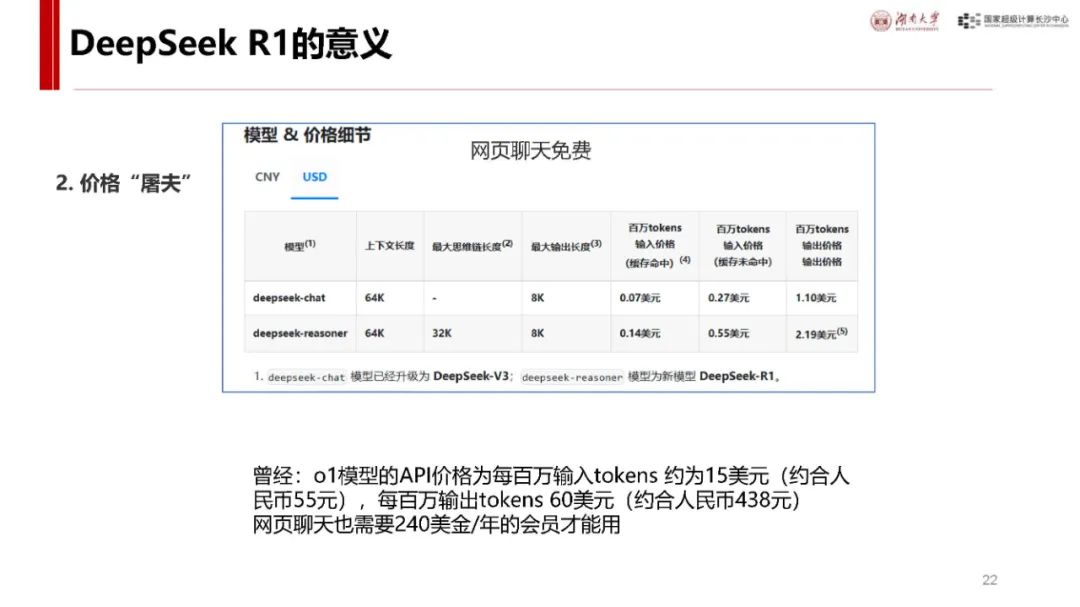
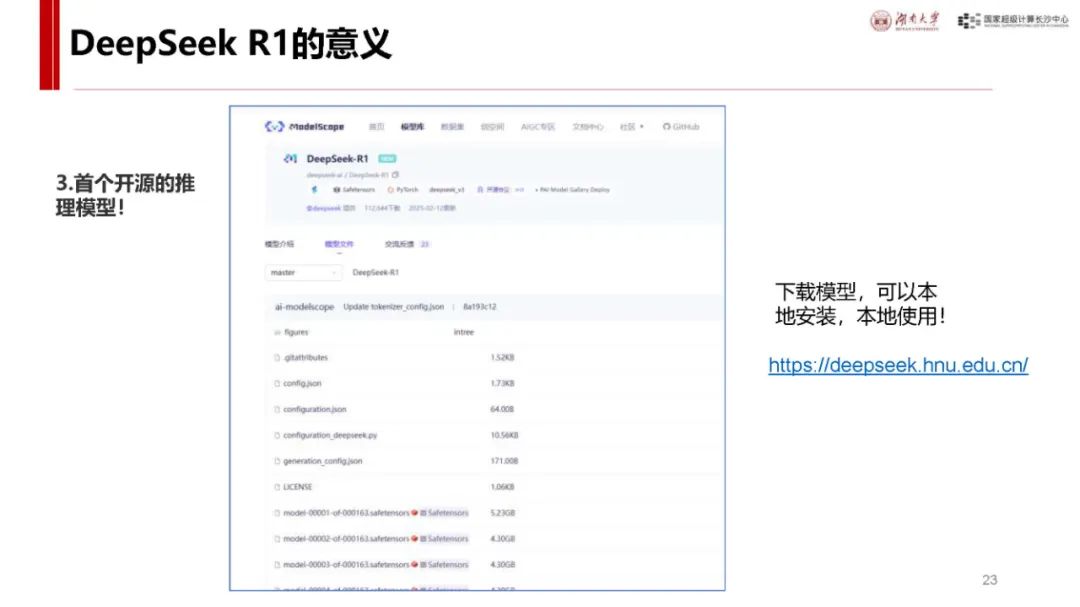
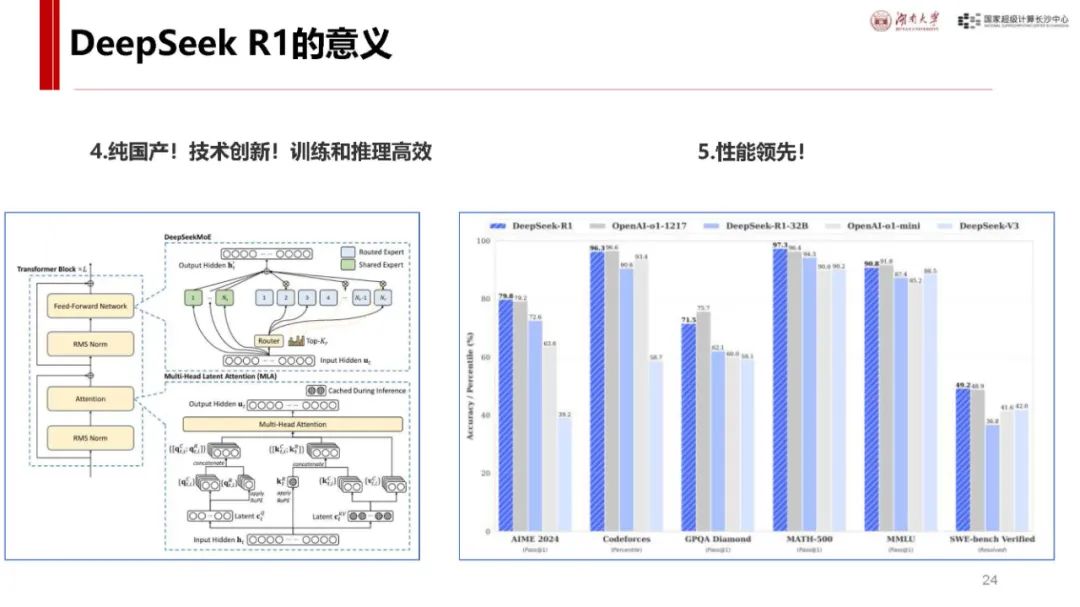
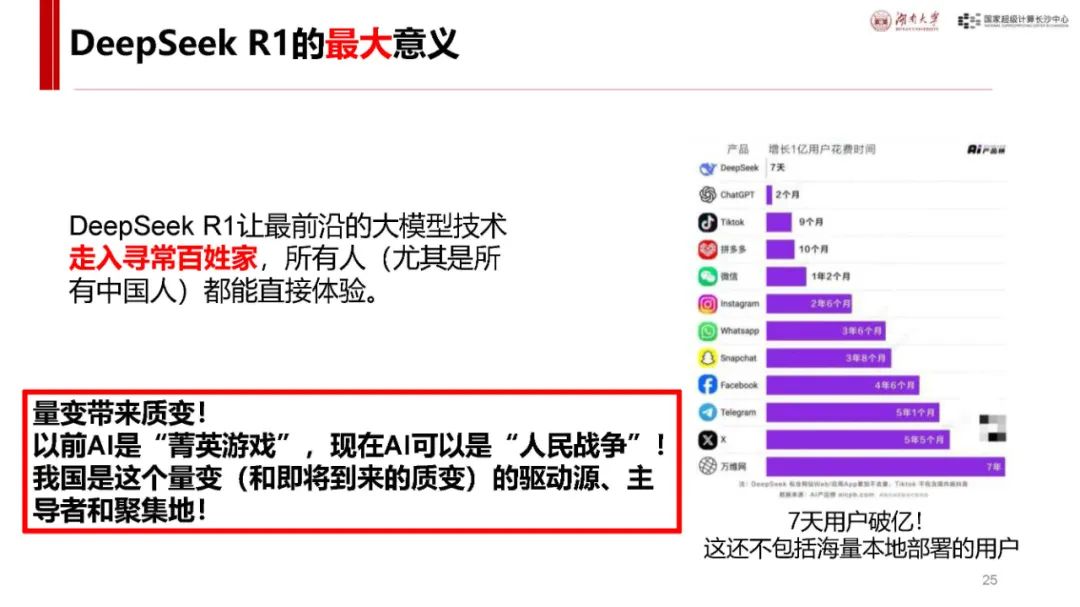
与 ChatGPT 对比及自身优势:ChatGPT 发布后用户增长迅速,而 DeepSeek - R1 具有独特优势。它是首个展示思维链过程的推理模型,在处理问题时能像人类一样逐步推导,如回答从长沙到武汉的驾车时间等问题时,会综合考虑距离、路线、车速、路况、天气、驾驶习惯等因素,相比非推理模型更具逻辑性。同时,其价格亲民,如 deepseek - chat 模型和 deepseek - reasoner 模型在输入输出价格上比 o1 模型低很多,且部分模型可本地安装使用,是首个开源的推理模型,为纯国产,技术创新且训练和推理高效,性能在多个领域领先,用户增长极快,7 天破亿。
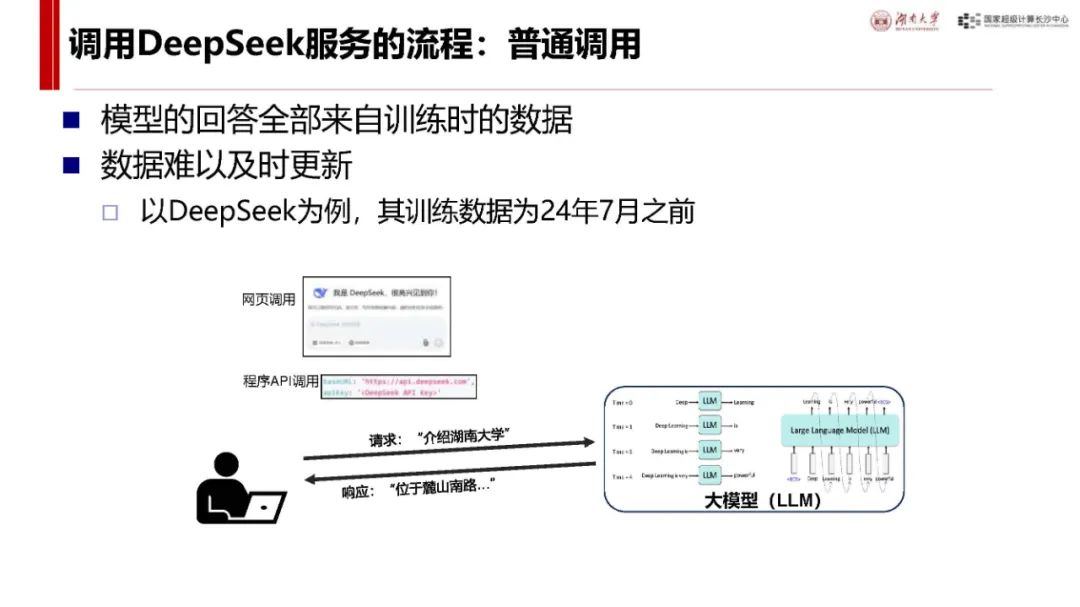
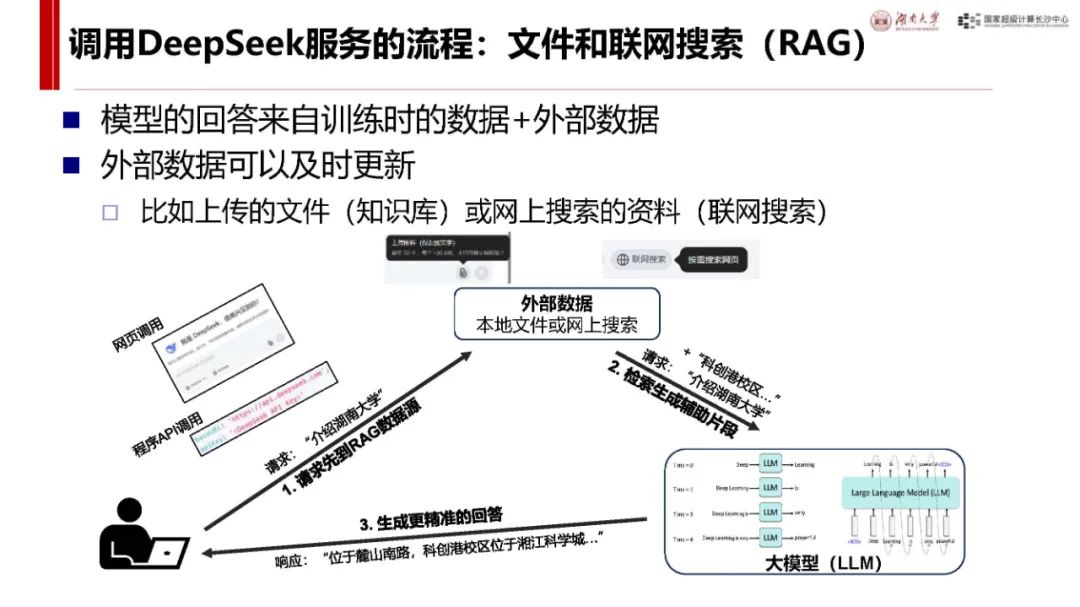
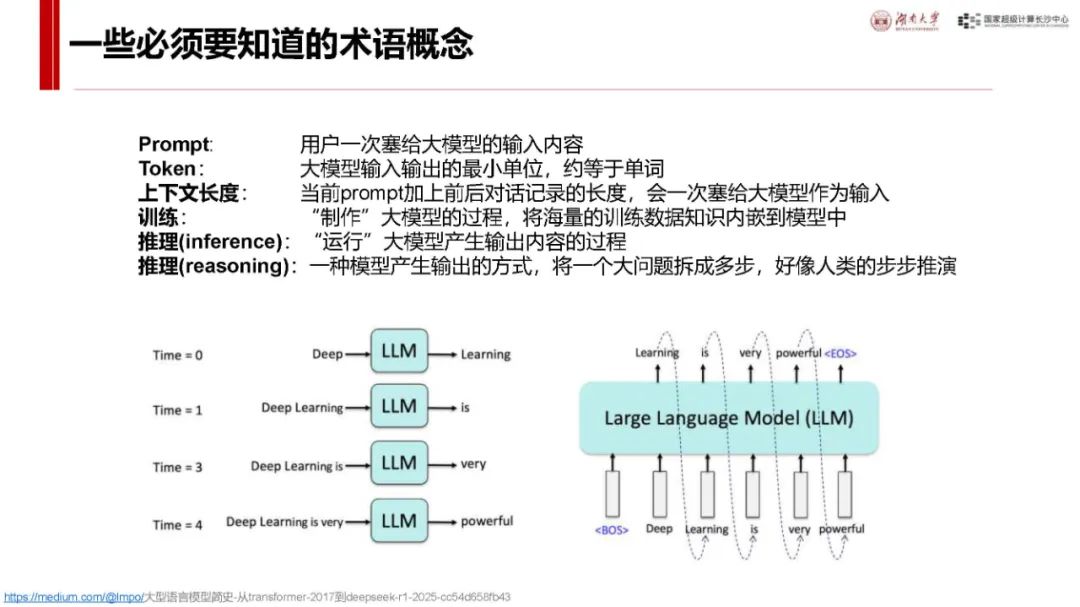
基本概念(用户角度):可通过 DeepSeek 官网、秘塔搜索、360 纳米 AI 搜索等多种渠道使用。其涉及的术语概念包括 Prompt(用户输入内容)、Token(输入输出最小单位)、上下文长度等,调用服务有普通调用和文件及联网搜索(RAG)两种方式,区别在于数据来源是否能及时更新。
DeepSeek 功能与应用
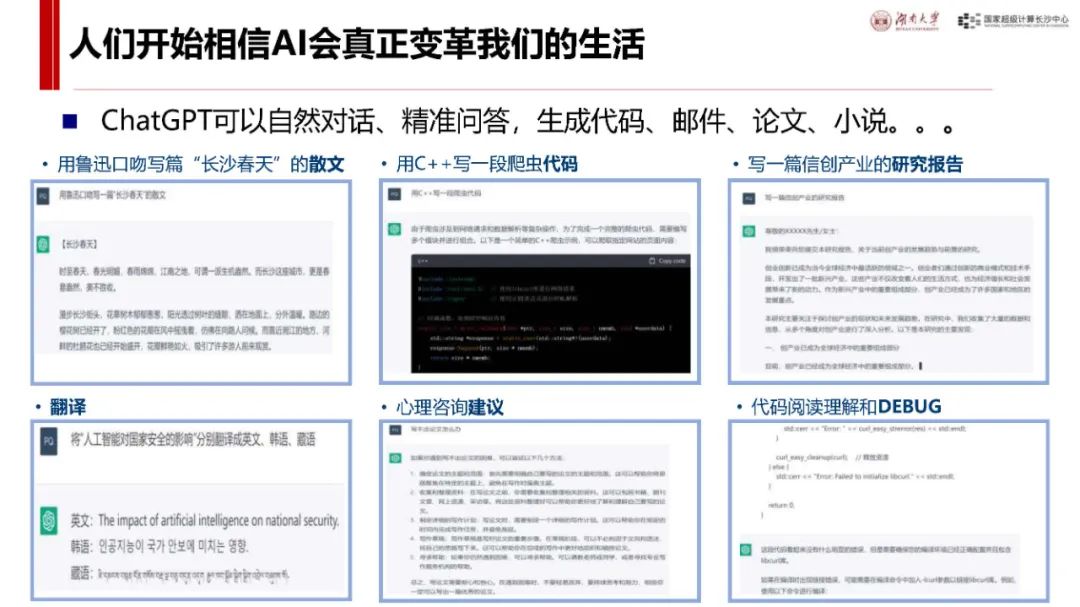
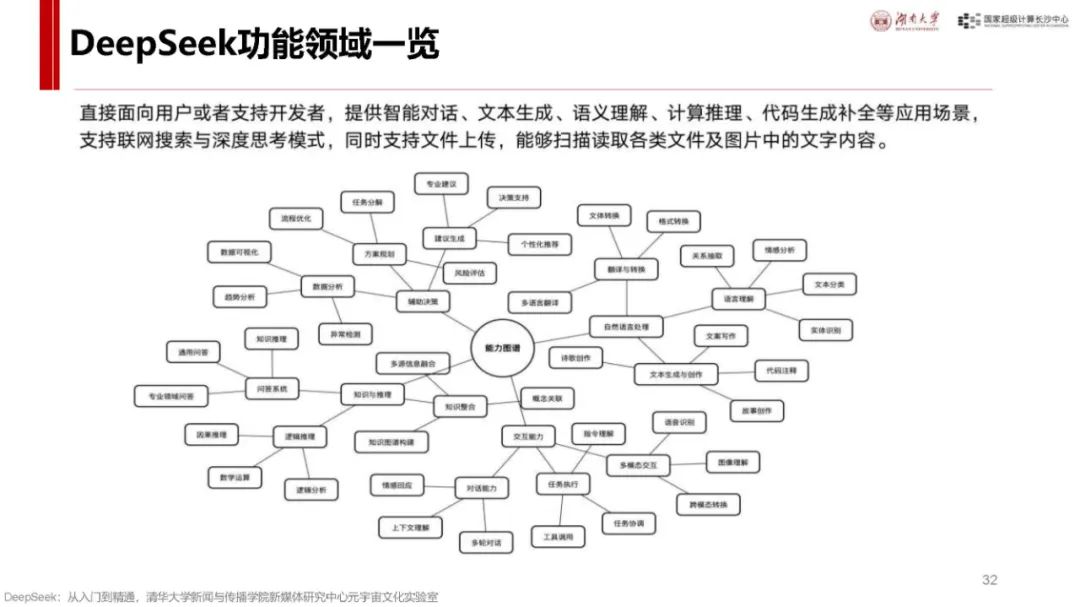
功能领域广泛:涵盖智能对话、文本生成、语义理解、计算推理、代码生成补全等,支持联网搜索与深度思考模式,能处理多种任务,如写诗、写代码、数据分析、文稿创作、教学辅助等。
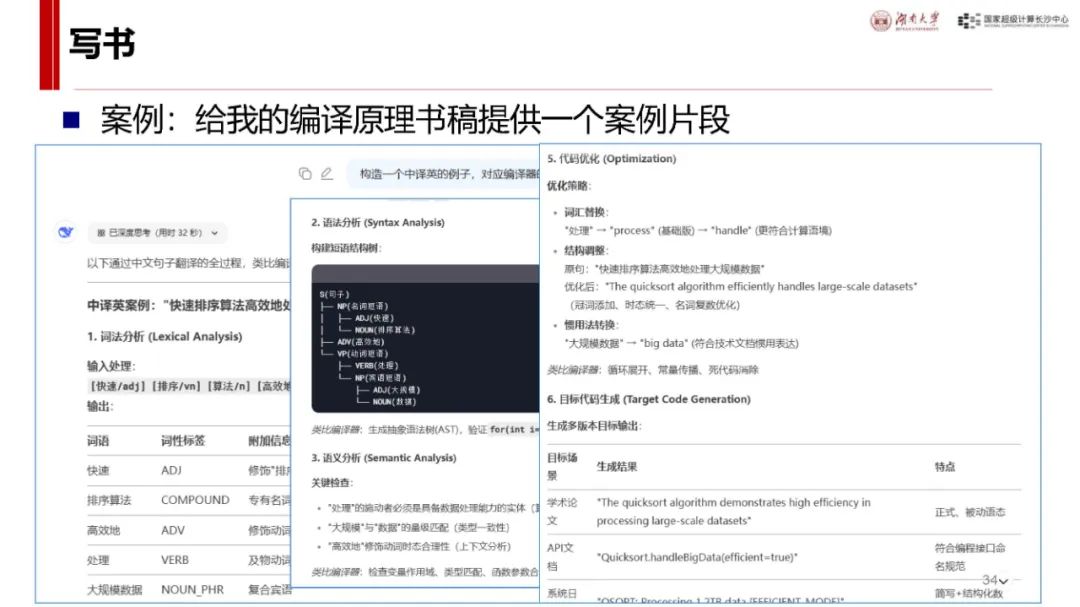
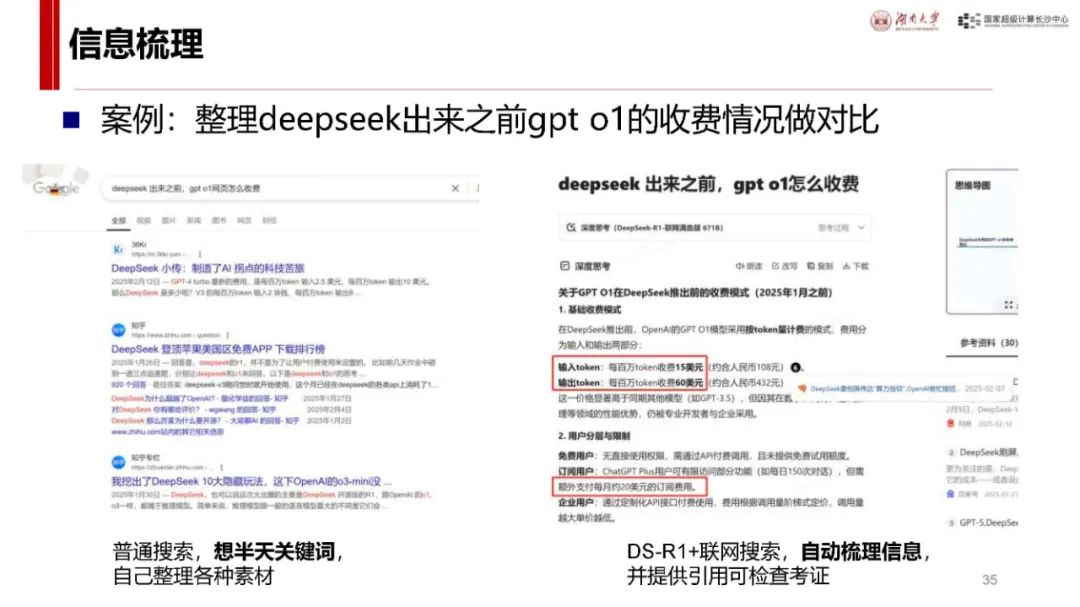
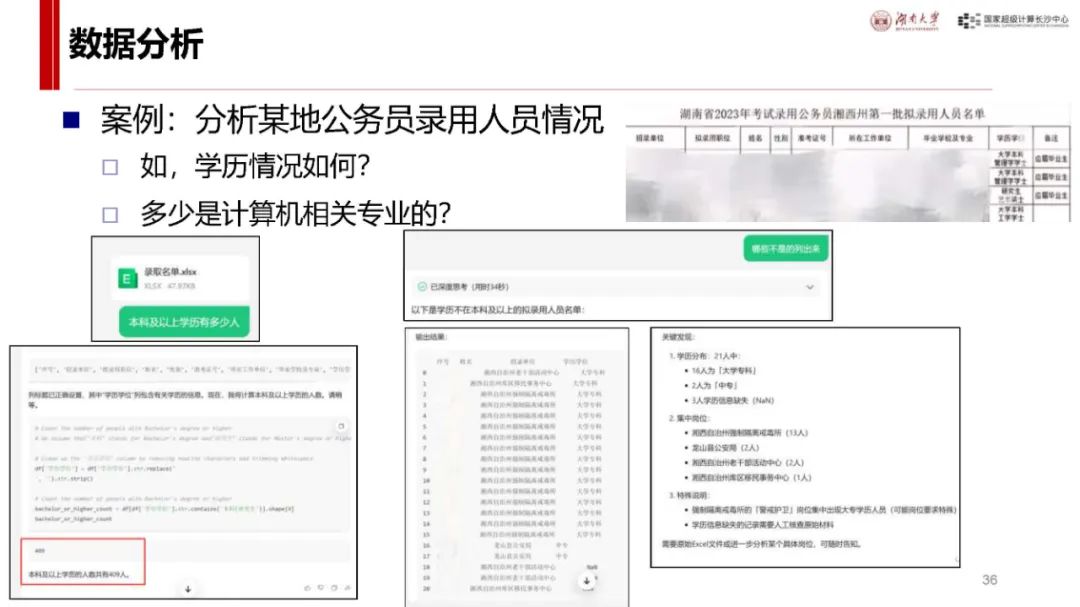
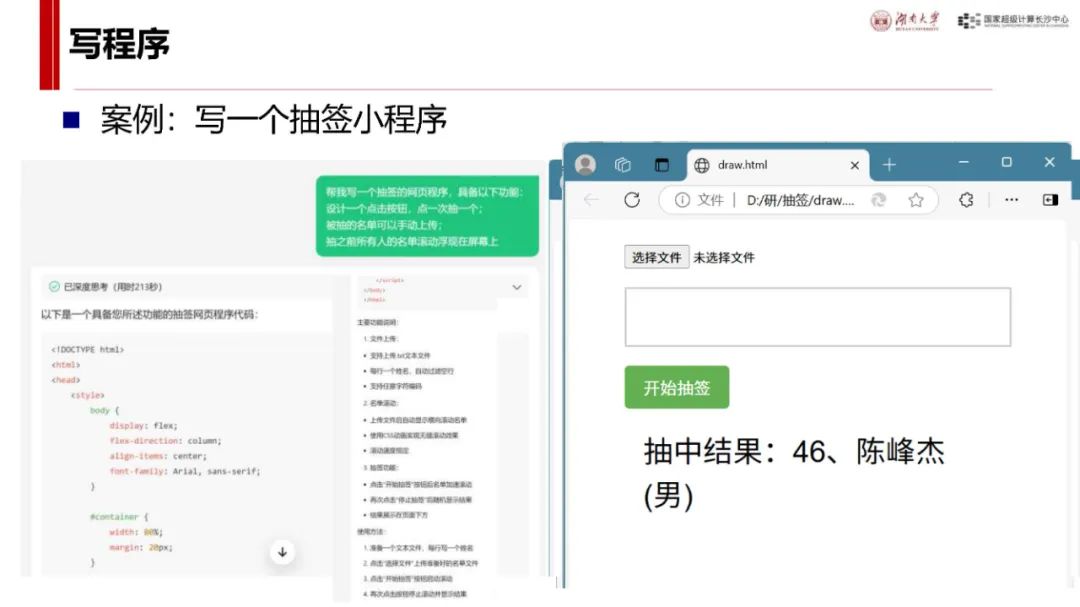
应用案例展示:在写书方面,可为编译原理书稿提供案例片段并进行多方面分析;在数据分析上,可分析公务员录用人员情况;咨询分析中,能评估专家研究特长并给出建议;还能编写抽签小程序、设计幼儿园科普讲稿等,展示了其在不同场景下的应用能力与方法。
DeepSeek 能力与局限
能力体现:具备逻辑推理、文字生成、搜索总结、代码生成等能力,能在多领域辅助用户完成任务,减轻工作量,为用户提供帮助和支持。
局限性:不是通用人工智能(AGI),用户需具备一定问题拆解等能力;可能出错,知识并非无所不包;不能直接处理多模态数据;受上下文长度限制;在模型效果上并非绝对领先且处于不断发展变化中。
DeepSeek 原理剖析
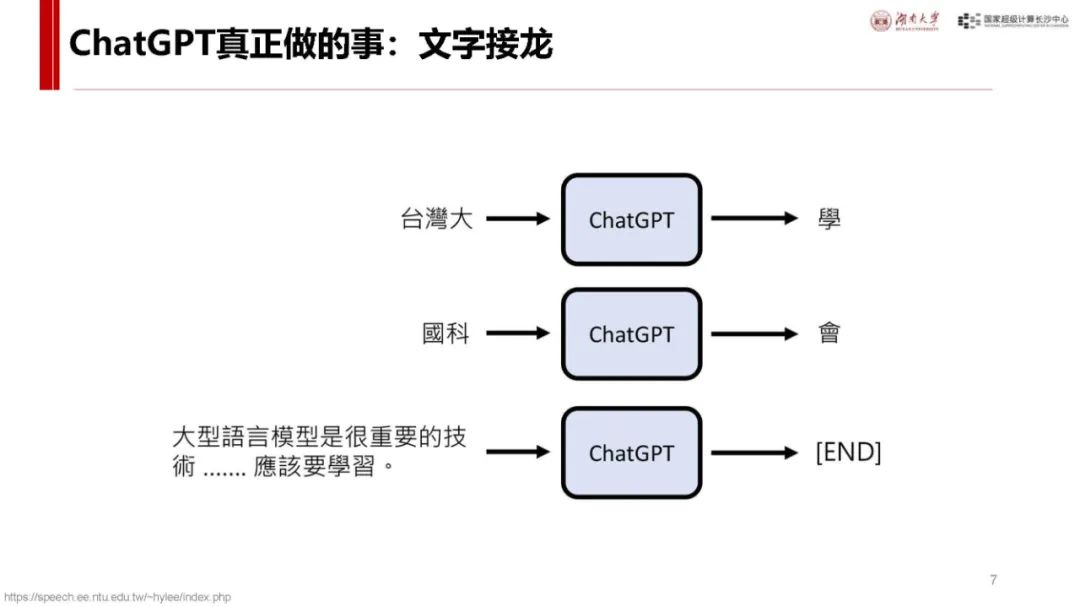
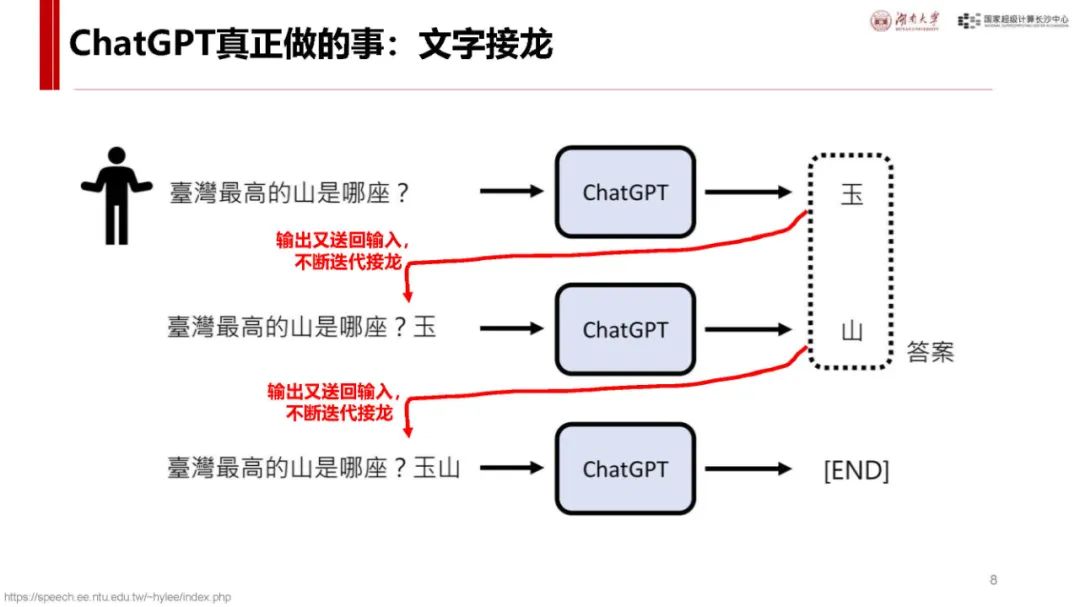
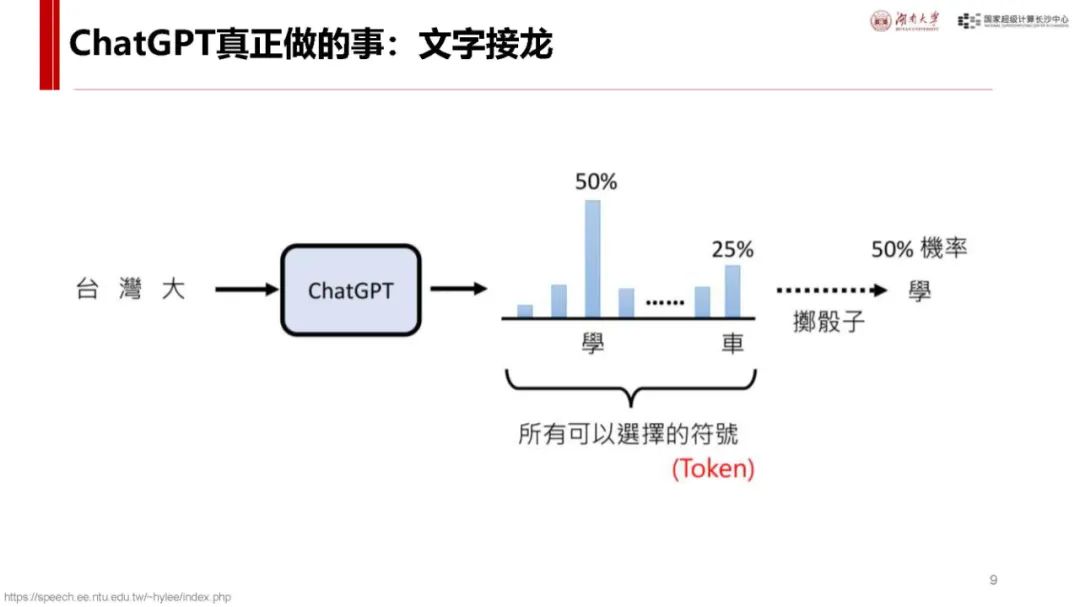
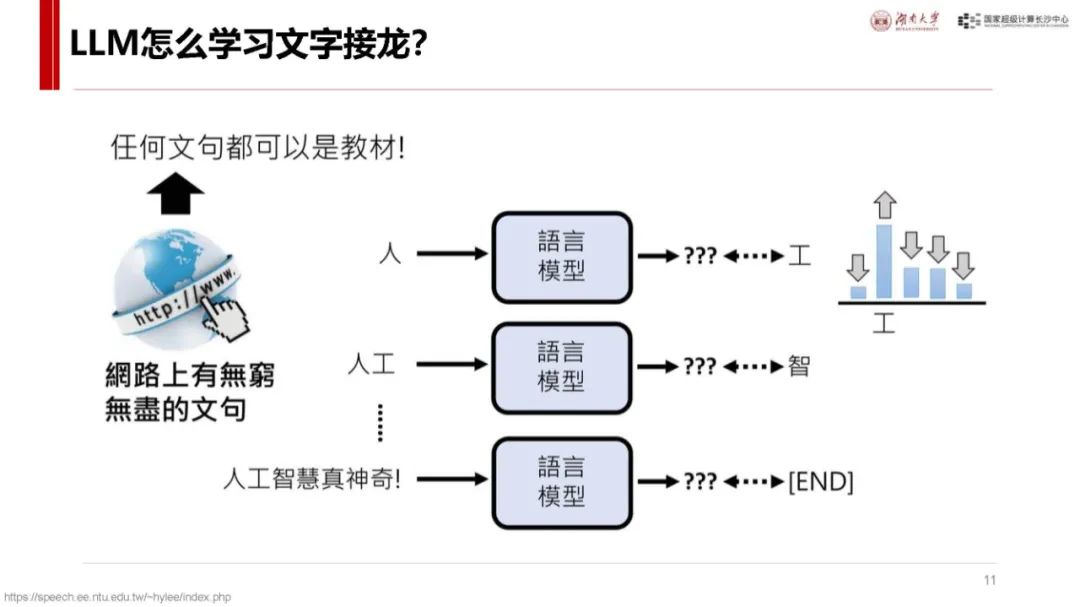
Transformer 基础:Transformer 是大模型常用神经网络,主流大模型多基于此。其流程包括输入 token 编码(Embedding)、计算 token 关系(Attention)、理解 token 含义(MLP)以及编码还原输出(Unembedding)等环节,各环节通过特定矩阵运算实现,数据和参数规模越大模型越聪明,达到一定规模会出现 “涌现” 现象,训练后还可通过后训练对齐提升性能。
模型发展历程:幻方公司早期投入 AI 研发,具备一定硬件基础。DeepSeek 公司 2023 年成立后不断创新,从开源 DeepSeek LLM 系列模型,到 2024 年对 Transformer 结构改造推出 DeepSeek - V2 等系列模型,再到 2024 年底的 DeepSeek - V3 基座模型达 SOTA,2025 年开源 DeepSeek - R1 推理模型,在模型结构和性能上持续进步。
未来关注重点
基于梅特卡夫定律,随着 DeepSeek 等使 AI 用户量增长,生态可能爆发。需关注行业应用(如 IT、教育等领域)、公共平台(模型云服务等)、模型算法(包括 DeepSeek 及其他模型)、系统软件(训练框架等)、算力底座(芯片、高性能网络等)等环节。国产 AI 芯片虽有机会但在大规模训练和推理效率上有短板;系统软件开源且更新快,但对本地部署玩家有要求;模型算法受硬件禁令影响有创新压力;行业应用需求大但需扎实落地;公共平台功能与用户体验等方面有待发展,知识库服务平台可能成为创业赛道。
后台回复“250225A”,可获得下载资料的方法。
















本公号使用腾讯元器(使用DeepSeek R1大模型)创建了智能交通技术AI服务,欢迎扫码进入体验(或在后台私信公号)。

点击文后阅读原文,可获得下载资料的方法。


















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









