






该文档围绕 DeepSeek 模型及昇腾 AI 基础软硬件展开,涵盖技术创新、性能优势、应用落地和生态建设等方面内容。
DeepSeek 模型技术创新与优势
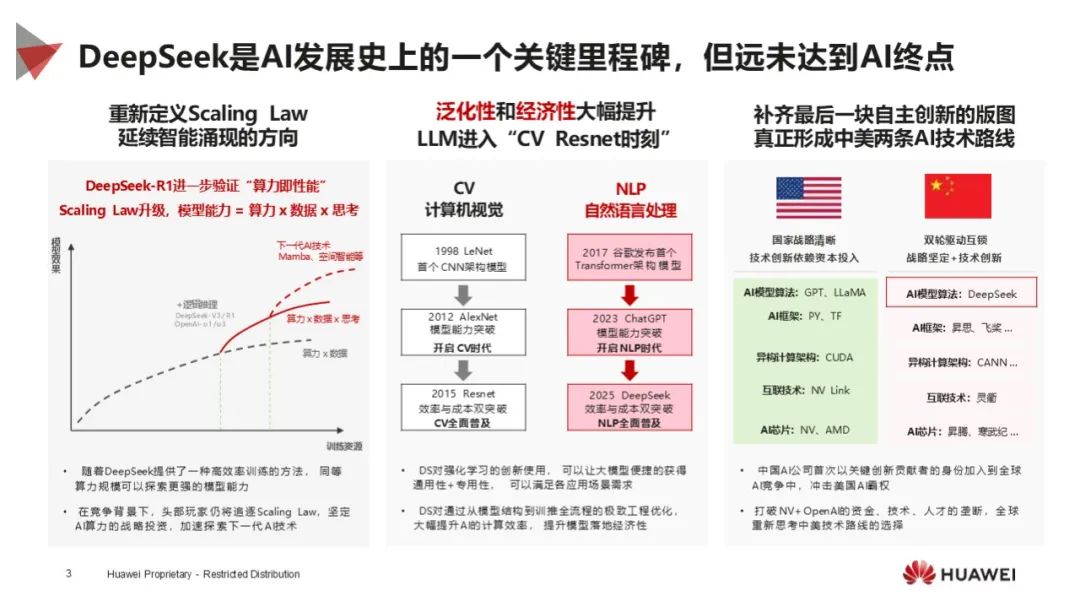
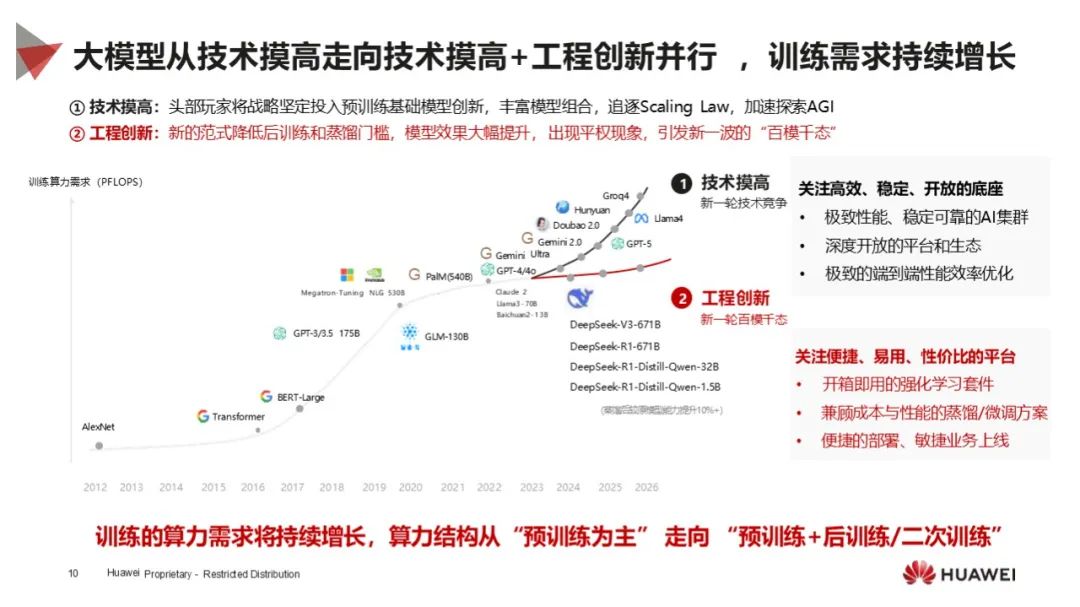
重新定义 Scaling Law:DeepSeek 是 AI 发展重要里程碑,重新定义 Scaling Law,验证 “算力即性能”,提出模型能力公式,推动 AI 技术发展,改变全球 AI 竞争格局,使中国在 AI 领域获得更多话语权。
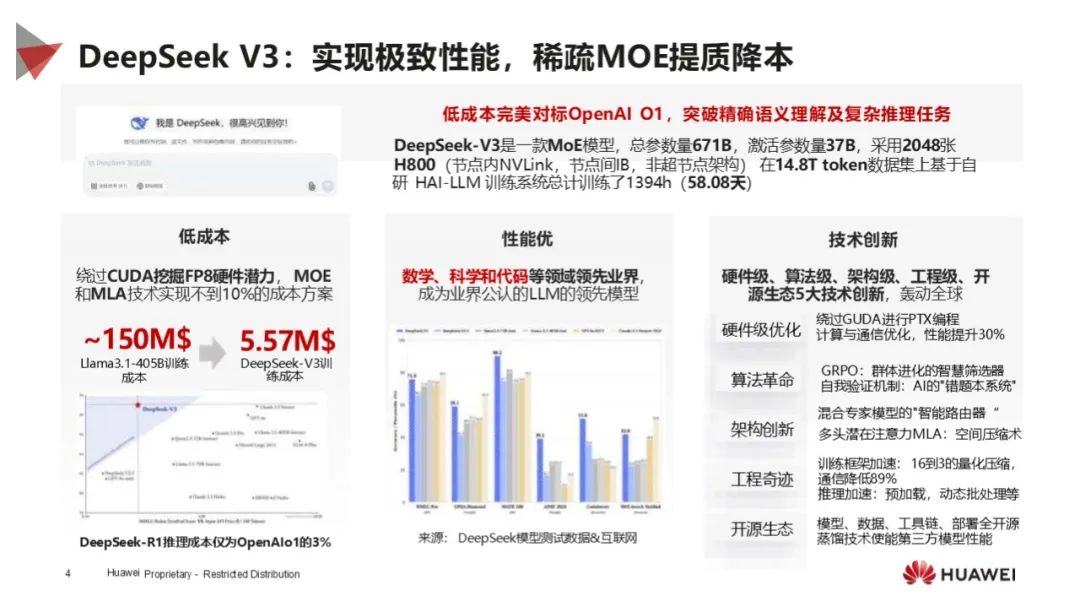
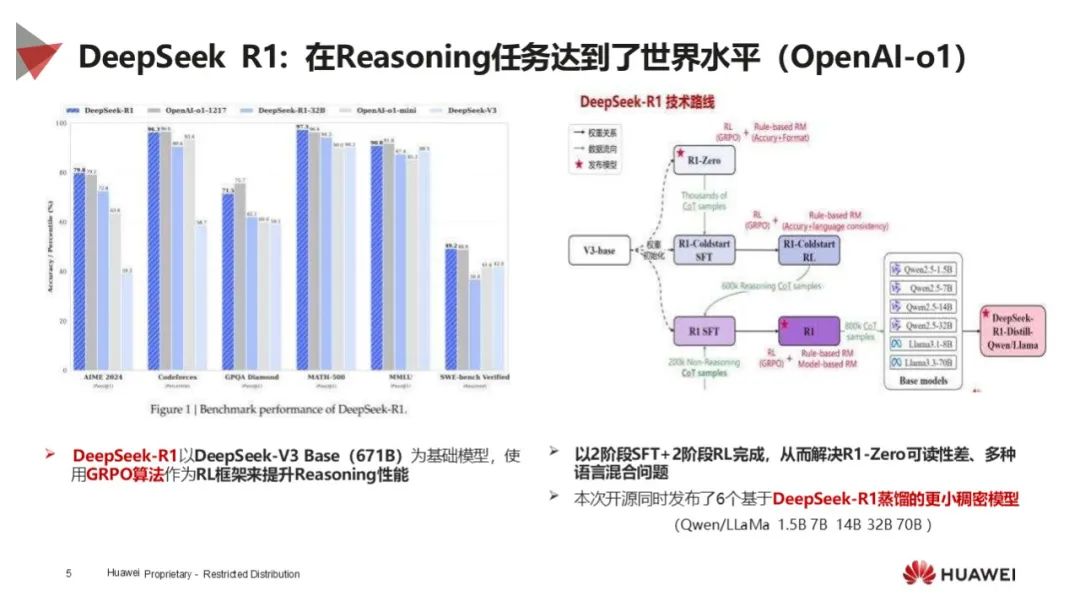
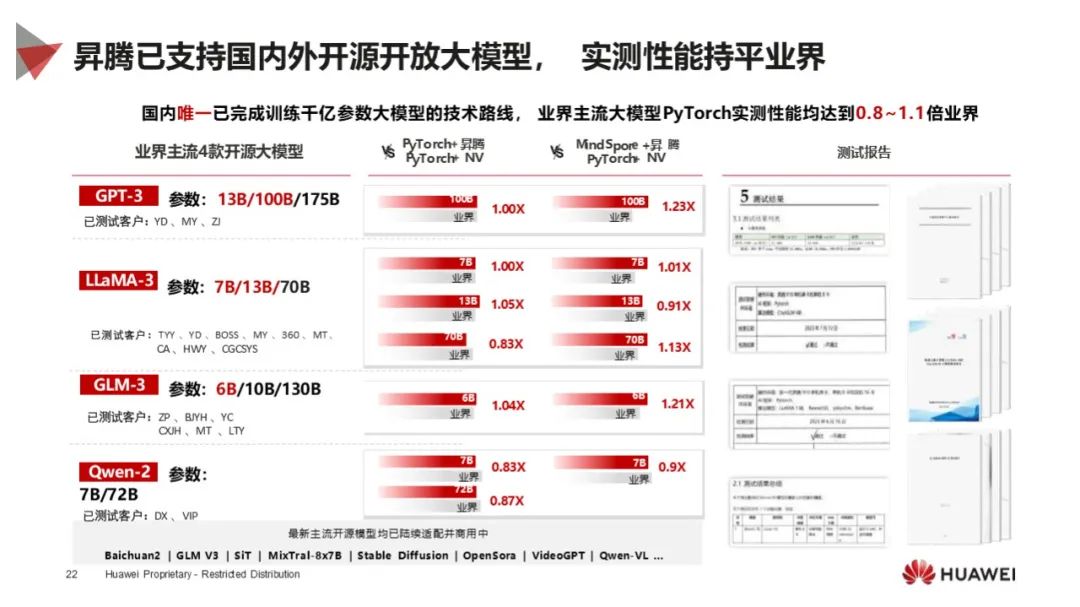
模型性能卓越:DeepSeek - V3 为 MoE 模型,参数量大,在数学、科学和代码领域领先,低成本对标 OpenAI O1,突破语义理解和推理任务;DeepSeek - R1 在推理任务达世界水平,开源多个蒸馏模型。
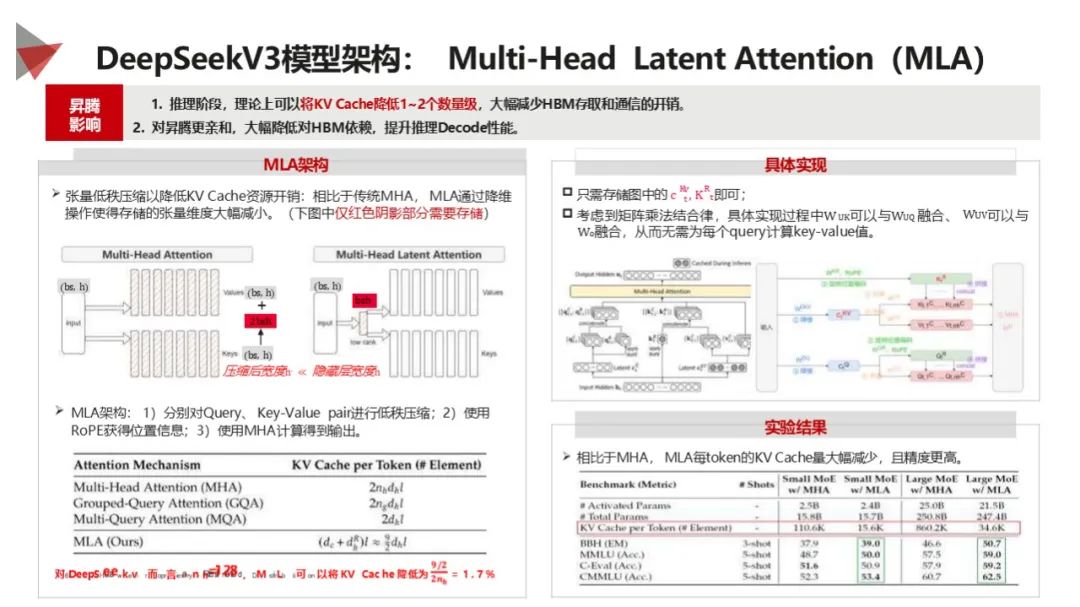
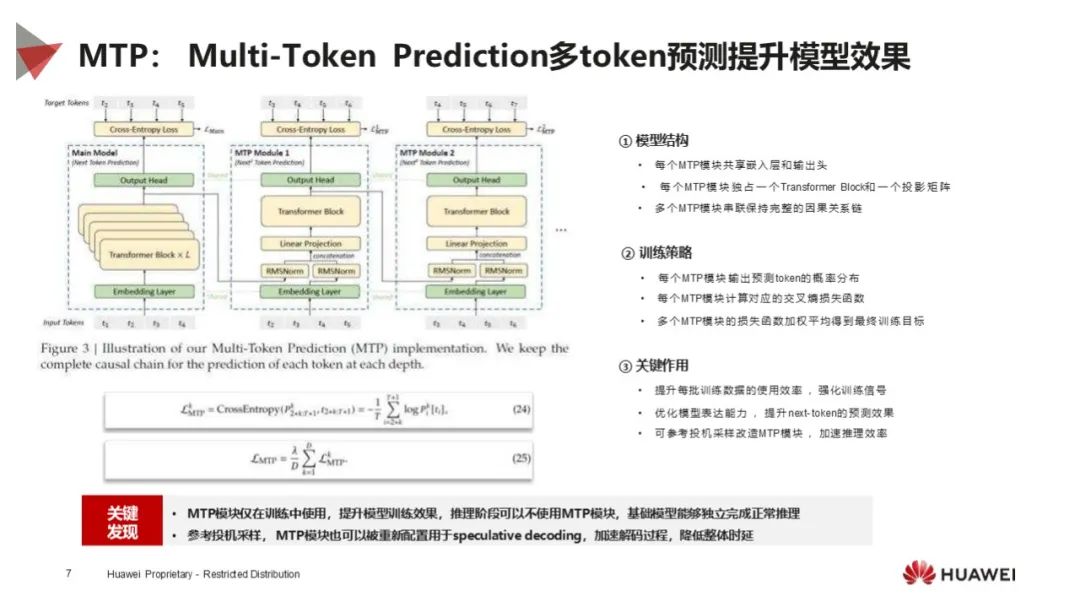
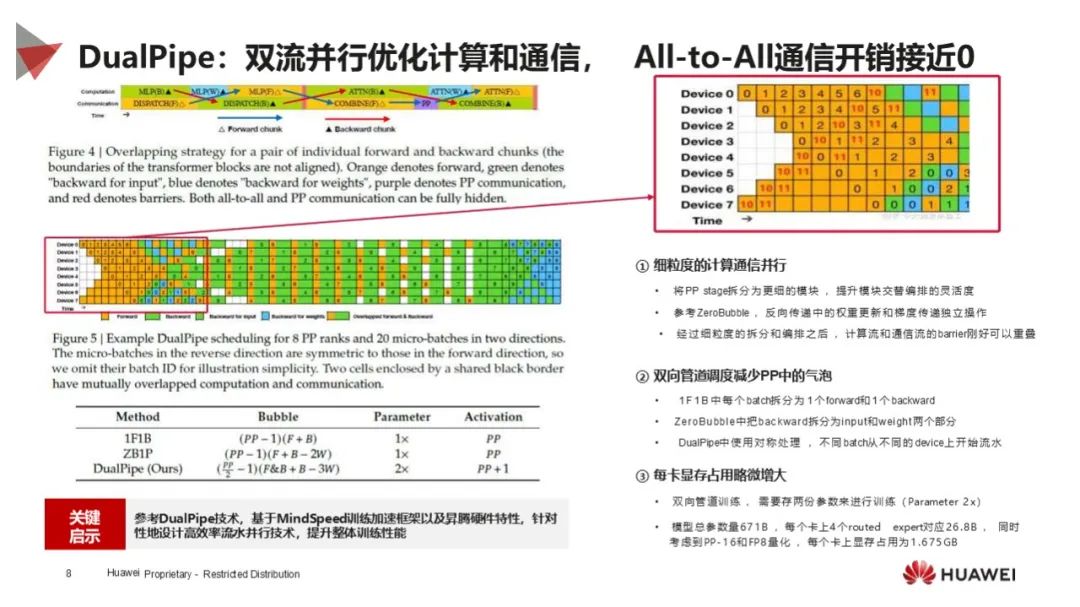
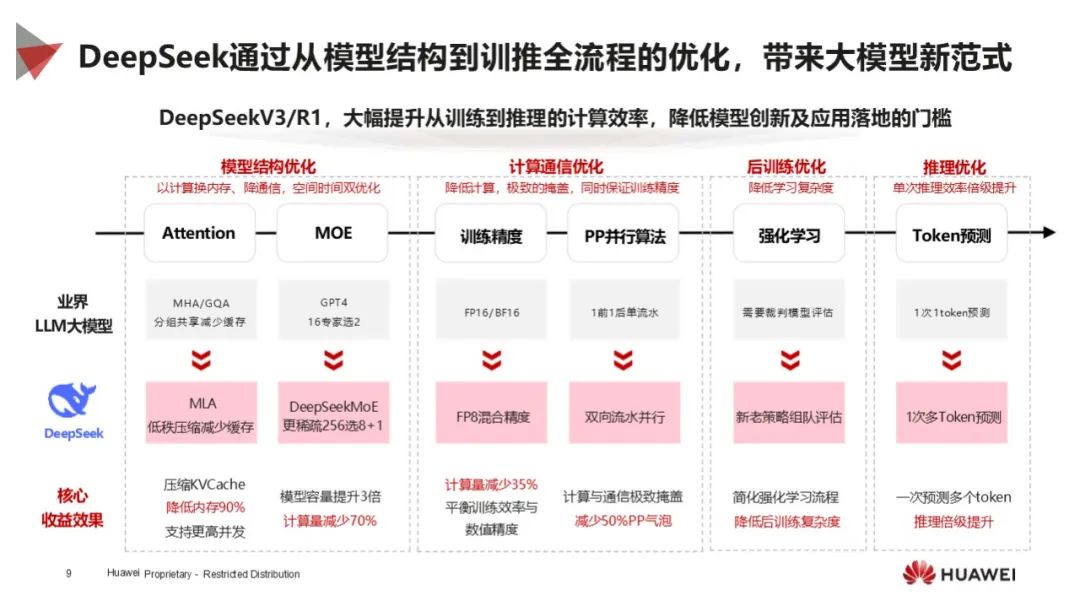
技术创新多样:涉及硬件级到开源生态 5 大技术创新,如绕过 GUDA 编程、计算通信优化、创新算法和机制、模型架构优化(MLA 架构)、全流程开源等,提升性能和降低成本。
昇腾 AI 基础软硬件架构与能力
架构全面创新:昇腾 AI 基础软硬件架构包括应用使能、计算框架、异构计算架构和硬件等,深度开放,对标英伟达架构,满足不同场景需求。
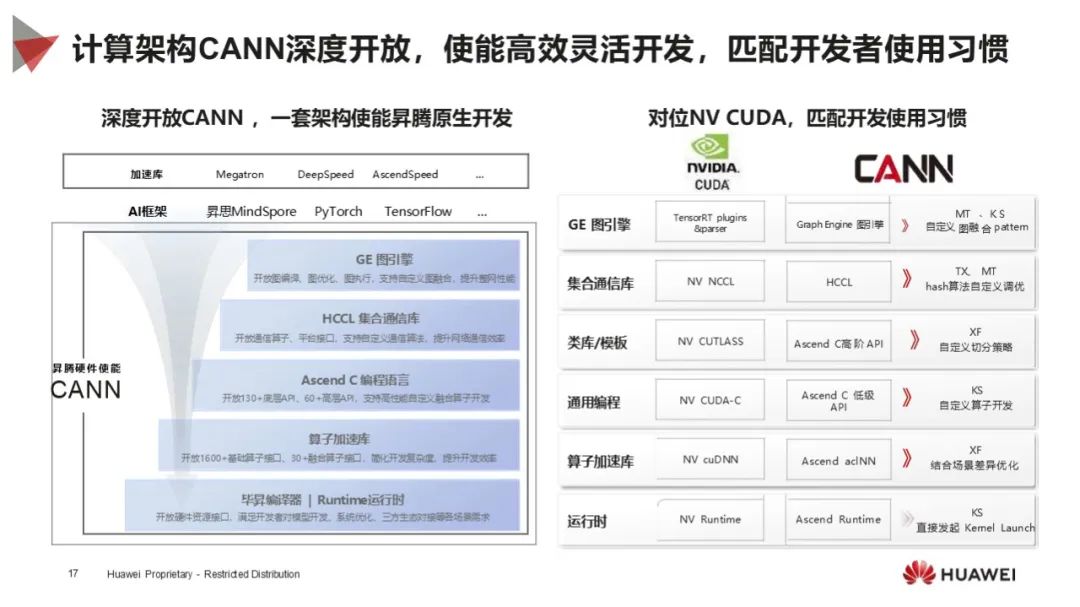
CANN 深度开放:计算架构 CANN 深度开放,匹配开发者习惯,提供多种加速库和接口,支持高效灵活开发,涵盖模型训练和推理的各个环节。
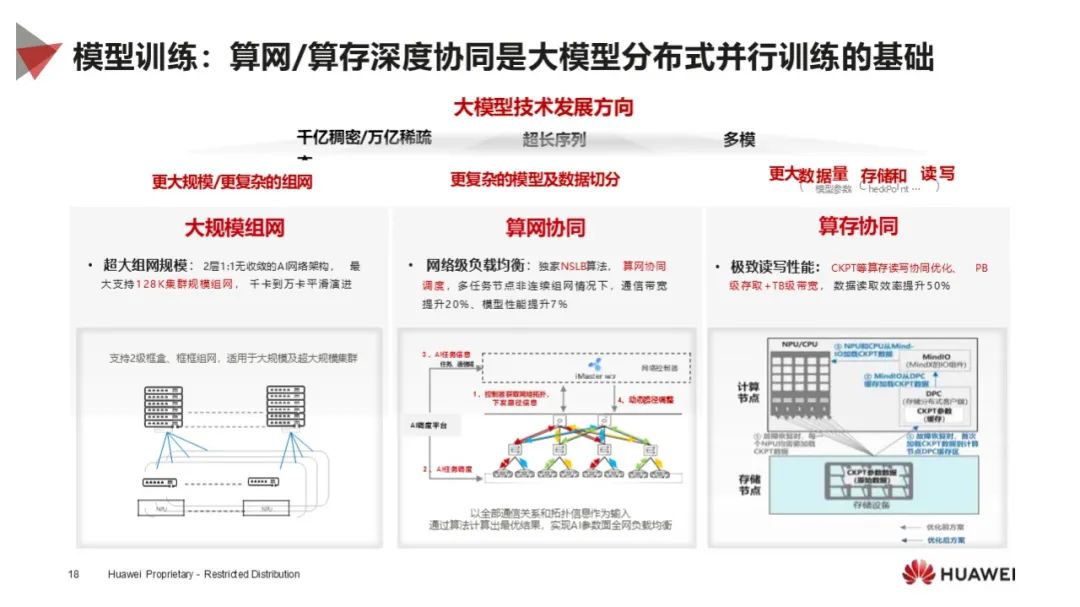
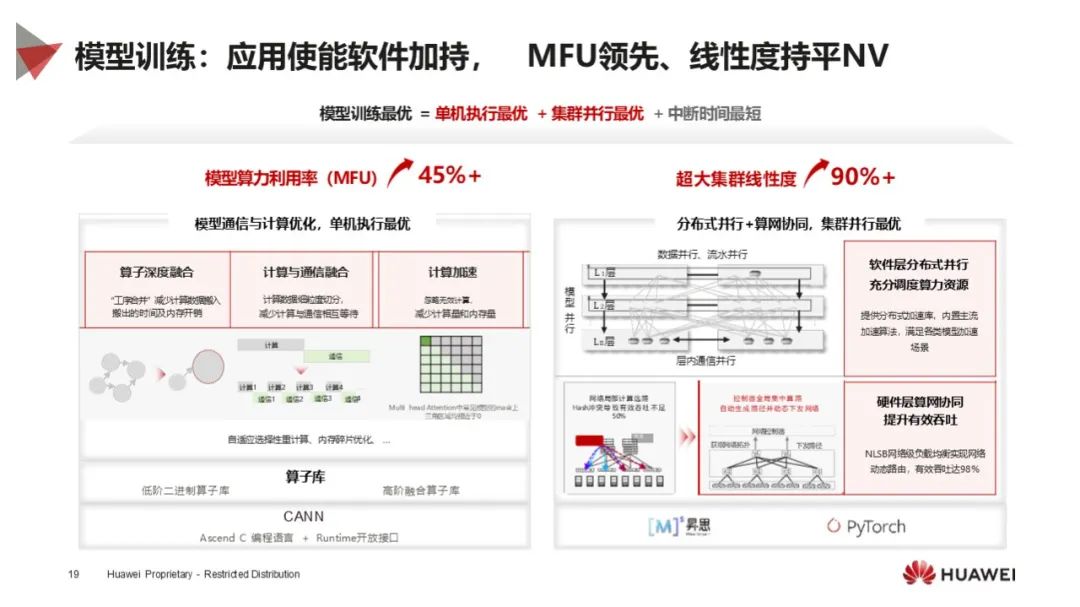
模型训练优势:昇腾在模型训练方面实现算网 / 算存协同,支持大规模组网,通过应用使能软件加持,提升模型训练效率,MFU 领先,线性度与英伟达持平。
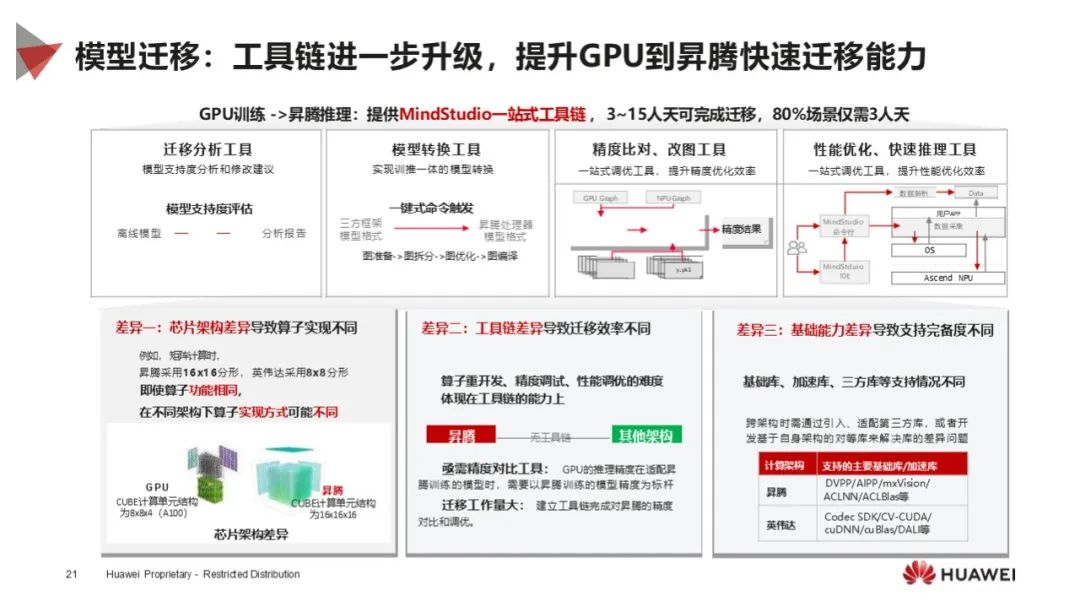
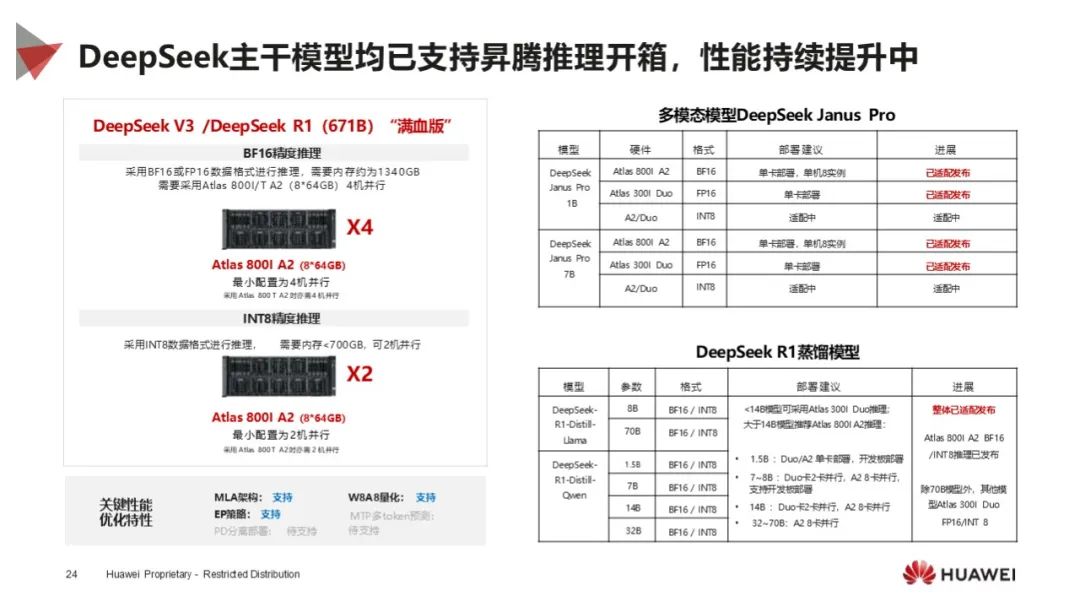
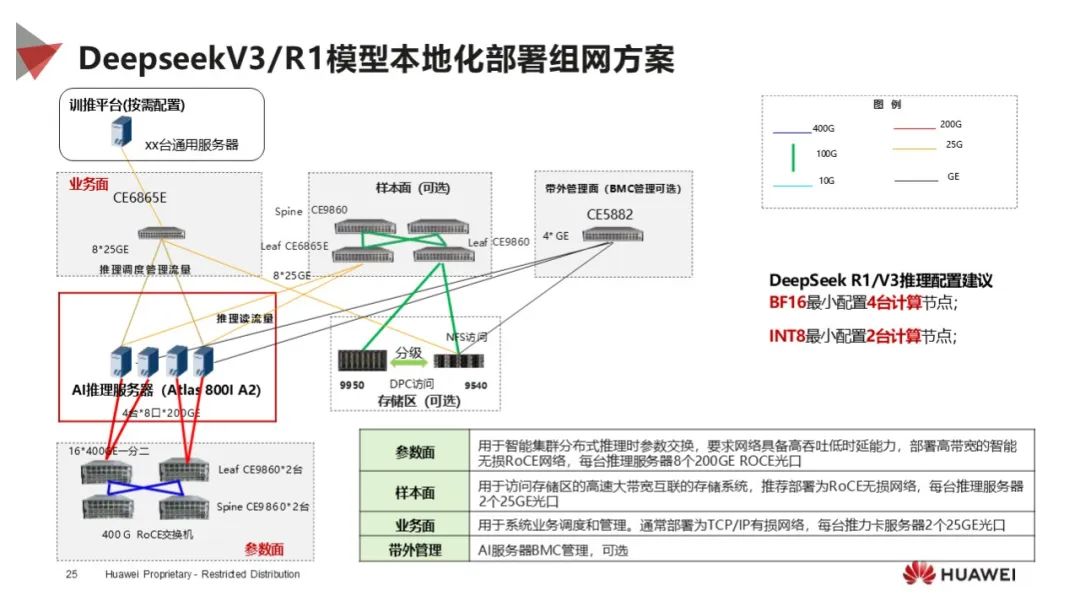
模型推理能力:提供分层开放的推理引擎 MindIE,对标主流推理引擎,支持多种框架,实现高效推理,提供丰富开发工具和接口,方便模型迁移和优化。
DeepSeek 与昇腾适配进展及应用
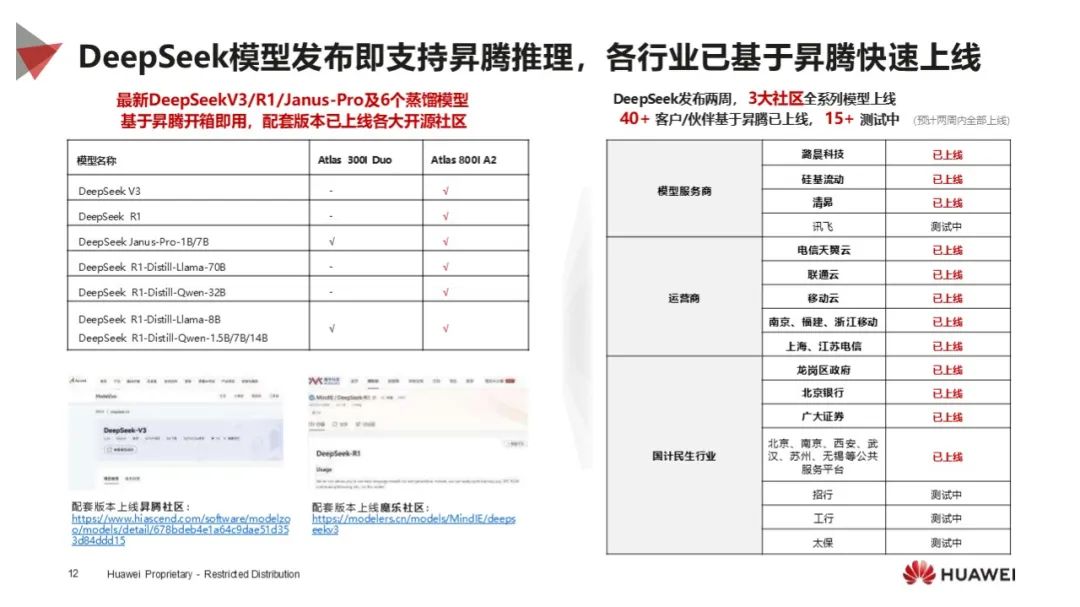
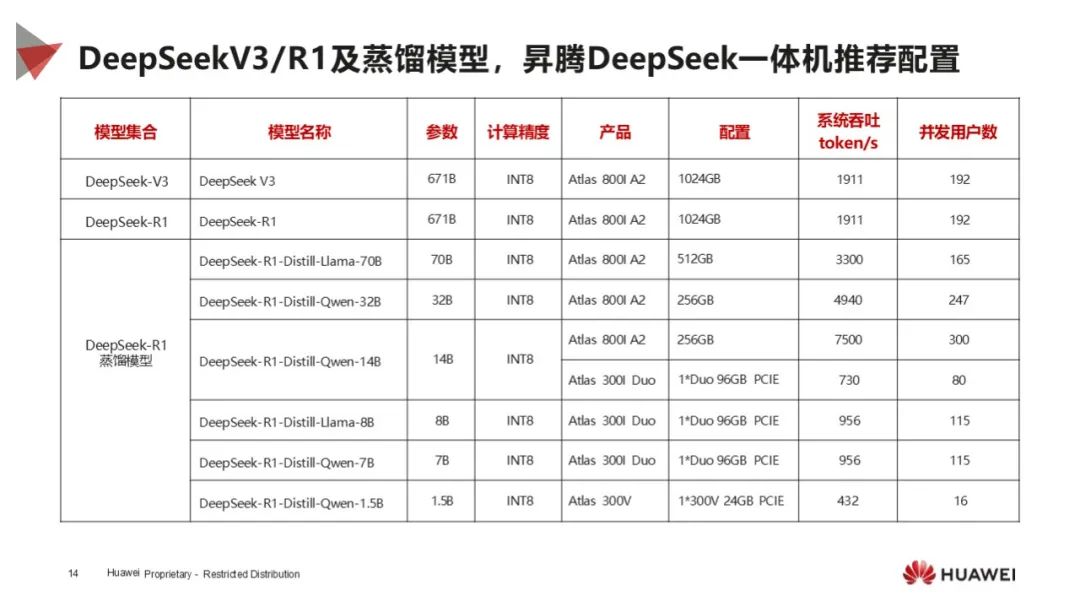
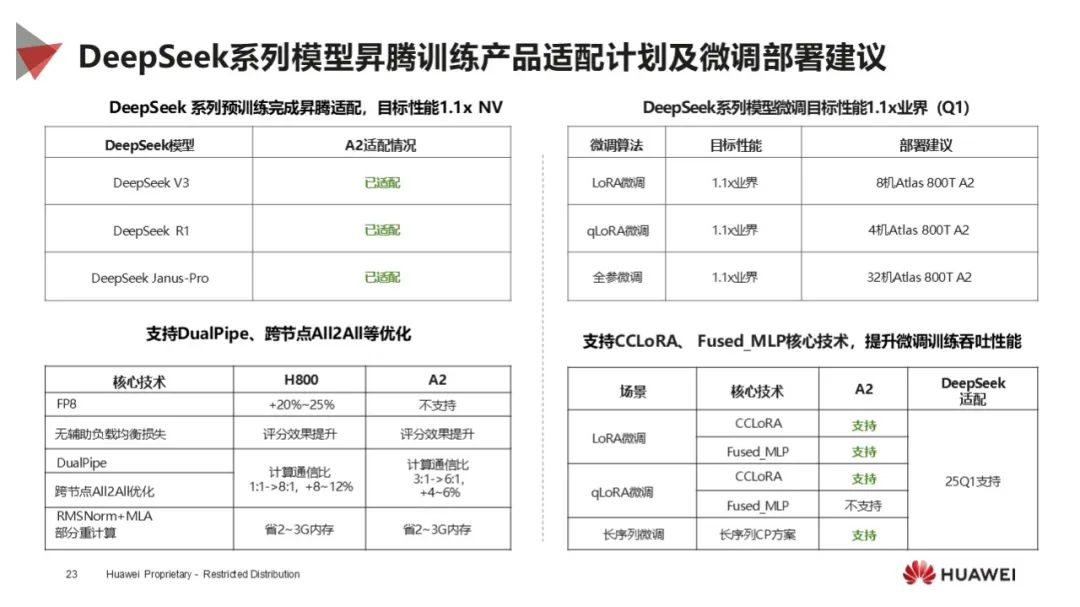
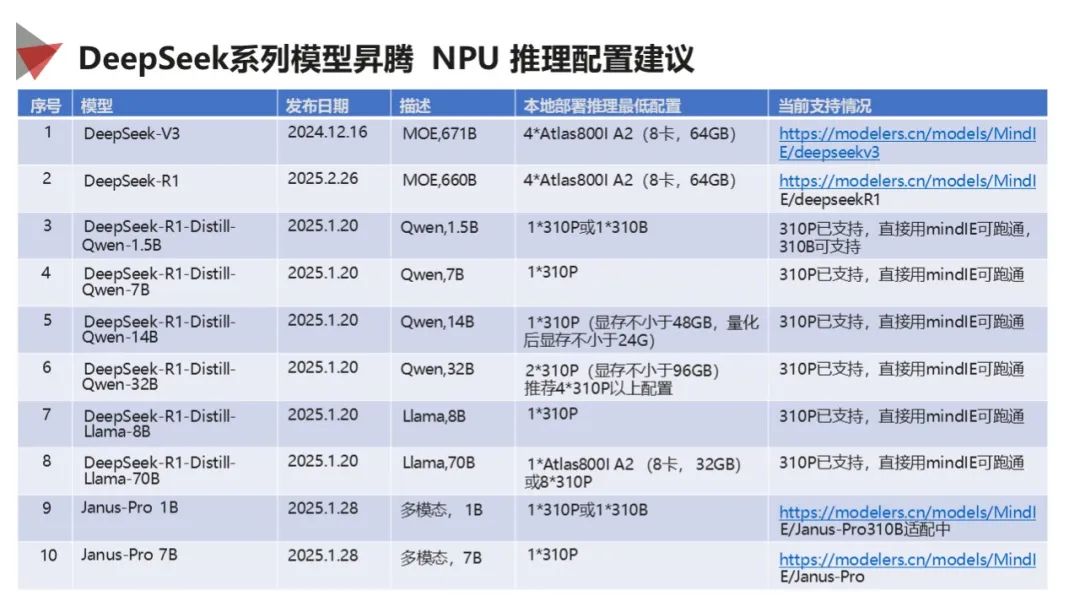
适配成果显著:DeepSeek 系列模型已完成昇腾适配,支持多种核心技术,微调目标性能达 1.1 倍业界水平,不同模型有相应部署建议。
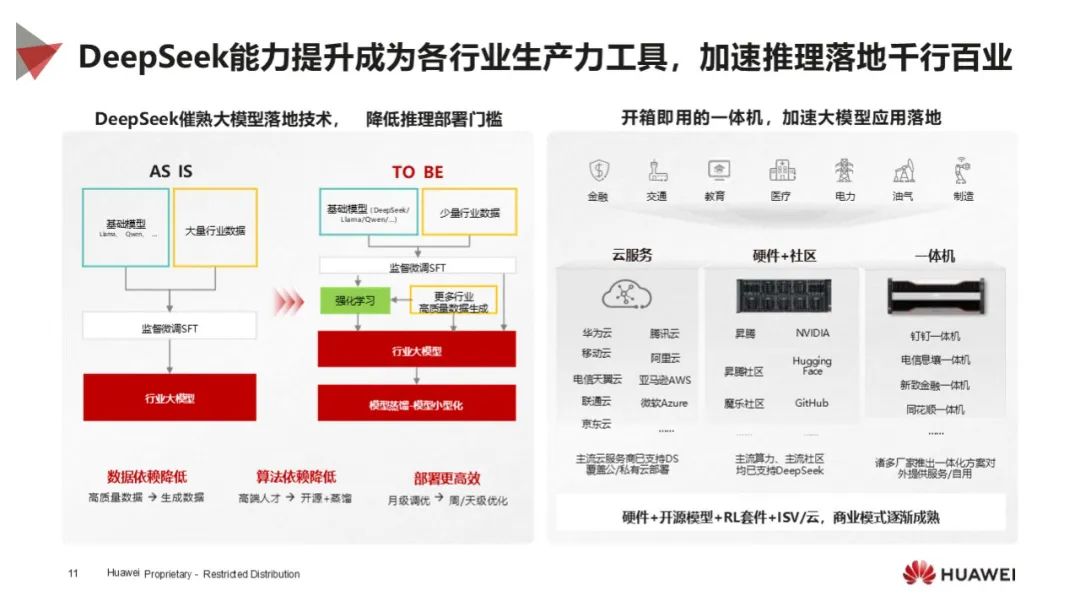
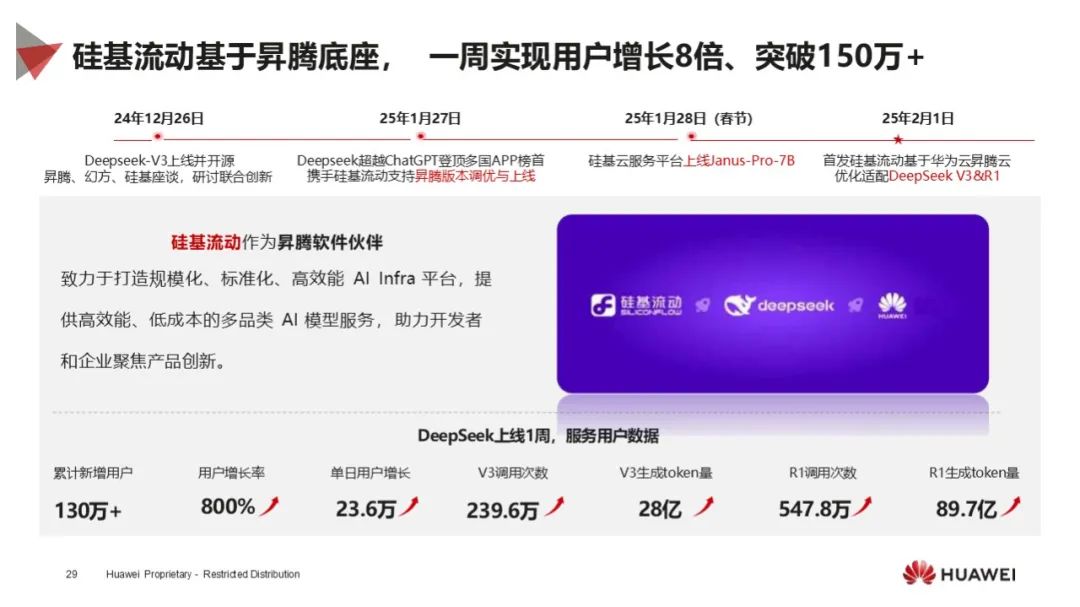
应用广泛落地:DeepSeek 模型借助昇腾在多行业上线,昇腾 DeepSeek 一体机实现大吞吐和高并发,加速行业模型落地,众多生态伙伴基于昇腾推出一体机方案。
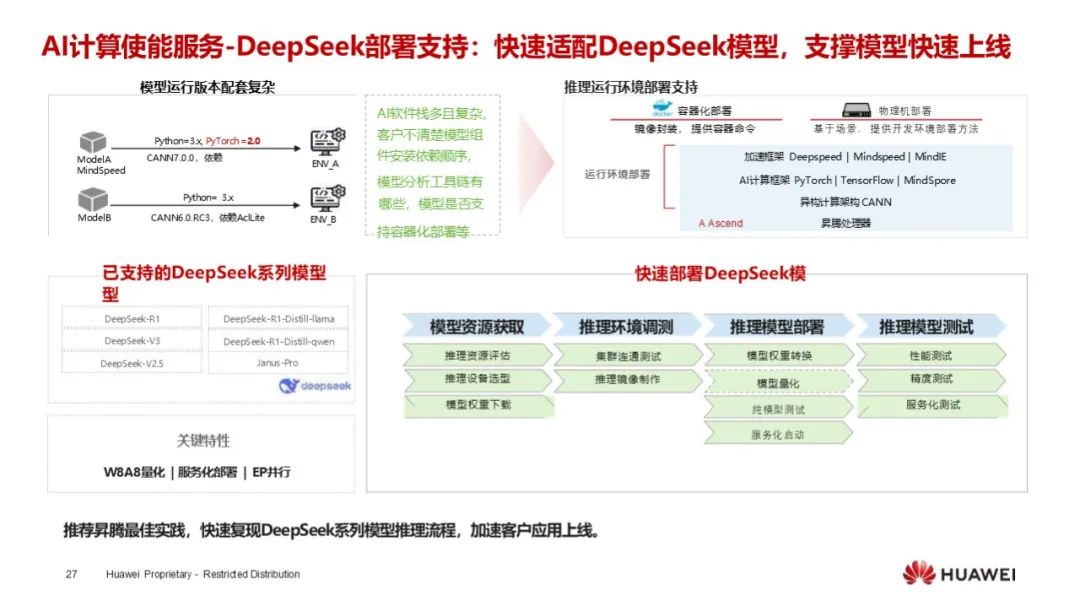
开发支持完善:AI 计算使能服务为 DeepSeek 模型提供全方位支持,包括环境部署、模型测试等,通过样例演示和知识赋能,帮助开发者掌握昇腾技术栈。
昇腾 AI 生态建设与发展
生态伙伴合作紧密:昇腾与众多生态伙伴合作,推出多种一体机方案,满足不同行业需求,促进 AI 技术在各领域应用。
开源社区协同创新:昇腾与 PyTorch 开源社区紧密合作,同步发布版本,提供原生开发体验,推动 AI 生态创新发展 。
后台回复“250321B”,可获得下载资料的方法。








点击文后阅读原文,可获得下载资料的方法。


















 2189
2189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









