







目录
1. 数据库简介
1.1 简介
- 数据库是长期保存在计算机存储设备上,按照一定规则组织起来,可以被各种用户和应用共享的数据集合。
- 数据库:存储、维护和管理数据的集合。
1.2 常见的数据库
目前互联网上常见的数据库管理软件有Oracle、MySQL、MS SQL Server、DB2、PostgreSQL、Access、Sybase、Informix。
1.3 关系型数据库
一个数据库可以有多个表,每个表都有一个名字,用来表示自己,表具有唯一性,表具有一些特性,这些特性定义了数据在表中如何存储,类似java中‘类’的设计。
1.4 表记录字段
- E-R(实体-联系)模型中有三个概念:实体、属性、联系集。
- 实体集(class)对应于表(table),实体(instance)则对应记录(record)。属性(attribute)对应字段(field)
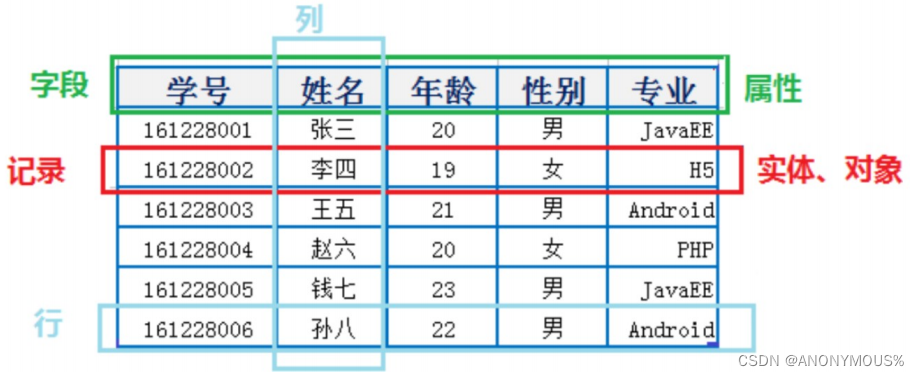
1.5 表的关联关系
- 表与表之间的数据记录有关系,均可用关系模型来表示
- 三种:一对一,一对多,多对多
2. MySql8配置
2.1 下载安装
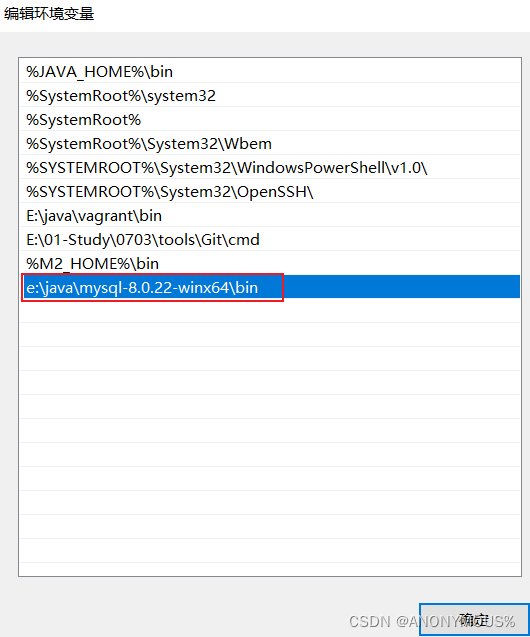
环境变量
配置文件
在mysql文件夹下新建my.ini。新增内容为如下,注意basedir和datadir是MySQL安装路径。最后新增加一个Data文件夹。
[mysqld]
# 设置3306端口
port=3306
# 设置mysql的安装目录
basedir=e:\java\mysql-8.0.22-winx64\
# 设置mysql数据库的数据的存放目录
datadir=e:\java\mysql-8.0.22-winx64\data
# 允许最大连接数
max_connections=200
# 允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统
max_connect_errors=10
# 服务端使用的字符集默认为UTF8
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 默认使用“mysql_native_password”插件认证
default_authentication_plugin=mysql_native_password
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[client]
# 设置mysql客户端连接服务端时默认使用的端口
port=3306
default-character-set=utf8

初始化
-
在
MySQL的bin目录下与运行cmd并进行初始化,mysqld --initialize --console -
在此界面的最后一行的冒号后为初始密码
-
mysqld --install mysql8 -
net start mysql8开启服务net stop mysql8关闭服务,不需要 -
mysql -u root -p数据库连接,并输入密码 -
修改账号密码
alter user 'root'@'localhost' identified with mysql_native_password BY '123456';
exit数据库退出mysql -V查看数据库版本
2.2 卸载
- 使用管理员关闭 MySQL服务
net stop mysql8 - 删除服务
mysqld remove mysql8 - 删除MySQLDB目录文件(安装MySQL时my.ini指定的目录)
2.3 图形化界面
3. SQL语句
3.1 SQL语言分类
-
DDL:数据定义语言,用来定义数据库对象:库、表、列等。主要的语句关键字包括 CREATE 、 DROP 、 ALTER 等。
-
DML:数据操作语言,用来定义数据库记录(数据)增删改。主要的语句关键字包括 INSERT 、 DELETE 、 UPDATE 、 SELECT 等 SELECT是SQL语言的基础,最为重要
-
DCL:数据控制语言,用来定义访问权限和安全级别。主要的语句关键字包括 GRANT 、 REVOKE 、 COMMIT 、 ROLLBACK 、 SAVEPOINT 等
-
DQL:数据查询语言,用来查询记录(数据)查询。因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类:DQL(数据查询语言)。
-
TCL 单独将 COMMIT 、 ROLLBACK 取出来称为TCL
3.2 SQL规约
-
每条命令以 ; 或 \g 或 \G 结束
-
关于标点符号
-
必须使用英文状态下的半角输入方式
-
字符串型和日期时间类型的数据可以使用单引号(’ ')表示
-
列的别名,尽量使用双引号(" "),而且不建议省略as
-
-
MySQL 在 Windows 环境下是大小写不敏感
-
MySQL 在 Linux 环境下是大小写敏感
-
数据库名、表名、表的别名、变量名是严格区分大小写的
-
关键字、函数名、字段名、字段的别名是忽略大小写的。
-
-
推荐采用统一的书写规范:
- 数据库名、表名、表别名、字段名、字段别名等都小写
- SQL 关键字、函数名、绑定变量等都大写
-
命名规约
- 数据库、表名不得超过30个字符,变量名限制为29个
- 必须只能包含 A–Z, a–z, 0–9, _共63个字符
- 数据库名、表名、字段名等对象名中间不要包含空格
- 同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;同一个表中,字段不能重名。
- 数据类型在一个表里是整数,那在另一个表里可不能为其他类型
4. select语句
4.1 导入SQL文件
mysql> source d:\mysqldb.sql
4.2 常用的语法
语法
- 判断是否为空使用
is null select * from departments;一般不建议使用 *
别名
SELECT last_name AS name, commission_pct comm FROM employees;
SELECT last_name "name", salary*12 "annual_salary" FROM employees;
去除重复行
- 去除department_id 中重复的数据
SELECT DISTINCT department_id FROM employees;
- 多列去除,只对department_id生效,对salary无效
SELECT DISTINCT department_id,salary FROM employees;
着重号
-
当表中的字段、表名与保留字、数据库系统或常用方法冲突时使用。
-
SQL语句中使用``将名字包住。
null值
所有运算符或列值遇到null结果均为null
查询常数
- 对于常数的查询就是在查询结果中添加一列固定的常数列,这一列取值是我们执行的,而不是从数据表中动态去除的
- 例如:我们对employees数据表中的员工姓名进行查询,同时增加一列字段corporation,这个字段固定值为"MySQL"可以这样写
SELECT 'MySQL' as corporation, last_name FROM employees;
显示表的结构
DESC employees;或 DESCRIBE employees
- 各个字段的含义
- Field:字段名称。
- Type:字段类型
- Null:是否可以为null。
- Key:该列是否已编制索引。PRI表示该列是表主键的一部分;UNI表示该列是UNIQUE索引的一部分;MUL表示在列中某个给定值允许出现多次。
- Default:该列是否有默认值,如果有,那么值是多少。
- Extra:表示可以获取的与给定列有关的附加信息,例如AUTO_INCREMENT等。
4.3 数据类型
| 数据类型 | 描述 |
|---|---|
| INT | 从-231到231-1的整型数据。存储大小为 4个字节 |
| CHAR(size) | 定长字符数据。若未指定,默认为1个字符,最大长度255 |
| VARCHAR(size) | 可变长字符数据,根据字符串实际长度保存,必须指定长度 |
| FLOAT(M,D) | 单精度,占用4个字节,M=整数位+小数位,D=小数位。D<=M<=255,0<=D<=30, 默认M+D<=6 |
| DOUBLE(M,D) | 双精度,占用8个字节,D<=M<=255,0<=D<=30,默认M+D<=15 |
| DECIMAL(M,D) | 高精度小数,占用M+2个字节,D<=M<=65,0<=D<=30,最大取值范围与 |
| DATE | 日期型数据,格式’YYYY-MM-DD’ |
| BLOB | 二进制形式的长文本数据,最大可达4G |
| TEXT | 长文本数据,最大可达4G |
5. 运算符
5.1 算数运算符
- 加运算符
Select A + B - 减运算符
Select A - B - 乘运算符
Select A * B - 除运算符
Select A / B - 模运算符
Select A mod B
5.2 比较运算符
- 比较运算符用来对表达式左边的操作数和右边的操作数进行比较,为真返回1,为假返回0,其他情况返回null
- 常用作select查询语句的条件来使用,返回符合条件的结果记录
| 运算符 | 名称 | 作用 | 示例 |
|---|---|---|---|
| = | 等于 | 值,字符串或表达式是否相等 | select C from table where A = B |
| <=> | 安全等于 | 安全地判断值,字符串或表达式是否相等 | select C from table where A <=> B |
| != | 不等于 | 值、字符串、表达式是否不相等 | select C from table where A != B |
| < | 小于 | 前面的值、字符串、表达式是否小于后面 | |
| <= | 小于等于 | 前面的值、字符串、表达式是否小于等于后面 | |
| > | 大于 | 前面的值、字符串、表达式是否大于后面 | |
| >= | 大于等于 | 前面的值、字符串、表达式是否大于等于后面 | |
| ISNULL | 为空运算符 | 值、字符串、表达式是否为空 | select b from table where a is null |
| ISNOTNULL | 不为空运算符 | 值、字符串、表达式是否不为空 | |
| BETWEEN AND | 两值之间的运算符 | 判断一个值是否在两个值之间 | where c between 12 and 18 |
| IN | 属于运算符 | 判断一个值是否为列表中的任意一个值 | where c in(a,b) |
| NOTE IN | 不属于运算符 | 判断一个值是否不是列表中的任意一个值 | |
| LIKE | 模糊匹配运算符 | 判断一个值是否符合模糊匹配规则 | where name LIKE ‘%li%’ |
| REGEXP | 正则表达式运算符 | 判断一个值是否符合正则表达式规则 | |
| RLIKKE | 正则表达式运算符 | 判断一个值是否符合正则表达式规则 |
//模糊查询
SELECT * FROM employees WHERE first_name LIKE '%ex%' //不区分大小写
SELECT * FROM employees WHERE first_name like binary '%ex%' //区分大小写
5.3 逻辑运算符
| 运算符 | 作用 | 示例 |
|---|---|---|
| NOT或! | 逻辑非 | select NOT A |
| AND | 逻辑与 | select A AND B |
| OR | 逻辑或 | SELECT A OR B |
| XOR | 逻辑异或 | SELECT A XOR B |
案例
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >=10000 AND job_id LIKE %MAN%';
//查询基本薪资不在9000-12000之间的员工编号和基本薪资
//方式一
SELECT employee_id,salary FROM employees WHERE NOT (salary >= 9000 AND salary <= 12000);
//方式二
SELECT employee_id,salary FROM employees WHERE salary <9000 OR salary > 12000;
//方式三
SELECT employee_id,salary FROM employees WHERE salary NOT BETWEEN 9000 AND 12000;
//正则运算符
SELECT * FROM employees WHERE first_name REGEXP '^A';//以字母A看开头
5.4 位运算符
| 运算符 | 作用 |
|---|---|
| & | 按位与 |
| | | 按位或 |
| ^ | 按位异或 |
| ~ | 按位取反 |
| >> | 按位右移 |
| << | 按位左移 |
案例
mysql> SELECT 1 & 10, 20 & 30;
+--------+---------+
| 1 & 10 | 20 & 30 |
+--------+---------+
| 0 | 20 |
+--------+---------+
1 row in set (0.00 sec)
6. 排序与分页
6.1 排序数据
- 使用ORDER BY进行排序
- ASC升序
- DESC降序
案例
//单例排序
SELECT employee_id, last_name, salary*12 annsal
FROM employees
ORDER BY annsal; //根据annsal排序,默认为升序
//多列排序
SELECT last_name, department_id, salary
FROM employees
ORDER BY department_id, salary DESC;
//根据department_id升序,salary降序方式排序
6.2 分页
- 对数据进行分页查看
- MySQL中使用
LIMIT实现分页,LIMIT [位置偏移量],一页行数
//--前10条记录:
SELECT * FROM 表名 LIMIT 0,10;
//--第11至20条记录:
SELECT * FROM 表名 LIMIT 10,10;
//--第21至30条记录:
SELECT * FROM 表名 LIMIT 20,10;
7. 关联查询
- 也称为多表查询,指两个或多个表一起完成查询操作
- 前提:两表之间有关联字段
7.1 笛卡尔积
-
笛卡尔乘积是一个数学运算。假设我有两个集合 X 和 Y,那么 X 和 Y 的笛卡尔积就是 X 和 Y 的所有可能组合,也就是说组合的个数为两个集合中元素个数的乘积。
-
使用 WHERE 放入连接条件可以有效避免笛卡尔积
//案例:查询员工的姓名及其部门名称
SELECT last_name, department_name
FROM employees, departments
WHERE employees.department_id = departments.department_id; //两表之间 WHERE条件返回true的记录相连接。
注意:多表关联应强制使用别名
//案例一
SELECT e.employee_id, e.last_name, e.department_id,d.department_id, d.location_id
FROM employees e , departments d
WHERE e.department_id = d.department_id
//案例二
SELECT e.last_name, e.salary, j.grade_level
FROM employees e, job_grades j
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal;//满足条件即可连接
7.2 自连接
顾名思义,自己和自己相连接
SELECT CONCAT(worker.last_name ,' works for ', manager.last_name)//此处为字符串拼接
FROM employees worker, employees manager//两个相同的表,一个为worker,一个为manager
WHERE worker.manager_id = manager.employee_id ;
7.3 内连接外连接
- 内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行,即:只显示公共部分
//内连接关键字为:JOIN B表表名 ON 关联条件
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e
JOIN departments d ON (e.department_id = d.department_id);//不建议使用三表关联
-
外连接: 除了返回满足条件的行外还返回左(右)表不满足条件的行,这种连接称为左(右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
-
如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
-
如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表
-
//左外连接关键字 LEFT JOIN 查询左边表所有数据(包括满足条件和不满足条件的数据)
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT JOIN departments d ON(e.department_id = d.department_id);
//右外连接关键字 RIGHT JOIN 查询右边表所有数据(包括满足条件和不满足条件的数据)
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT JOIN departments d ON (e.department_id = d.department_id) ;
- 满外连接 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据,
- 关键字
LEFT JOIN UNION RIGHT JOIN
- 关键字
7.4 UNION合并
- 可以给出多条SELECT语句,并将它们的结果组合成单个结果集。
- 注意:合并时两个表对应的列数和数据类型必须相同,并且相互对应。
- 各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
SELECT column,... FROM table1
UNION [ALL]// UNION是去重复,UNIONALL不去重复但资源消耗少,如果合并集合后的数据不存在重复数据,尽量使用UNIONALL
SELECT column,... FROM table2
案例:查询部门编号>90或邮箱包含a的员工信息
//方式1
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;
//方式2
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
7.5 七种JOINS
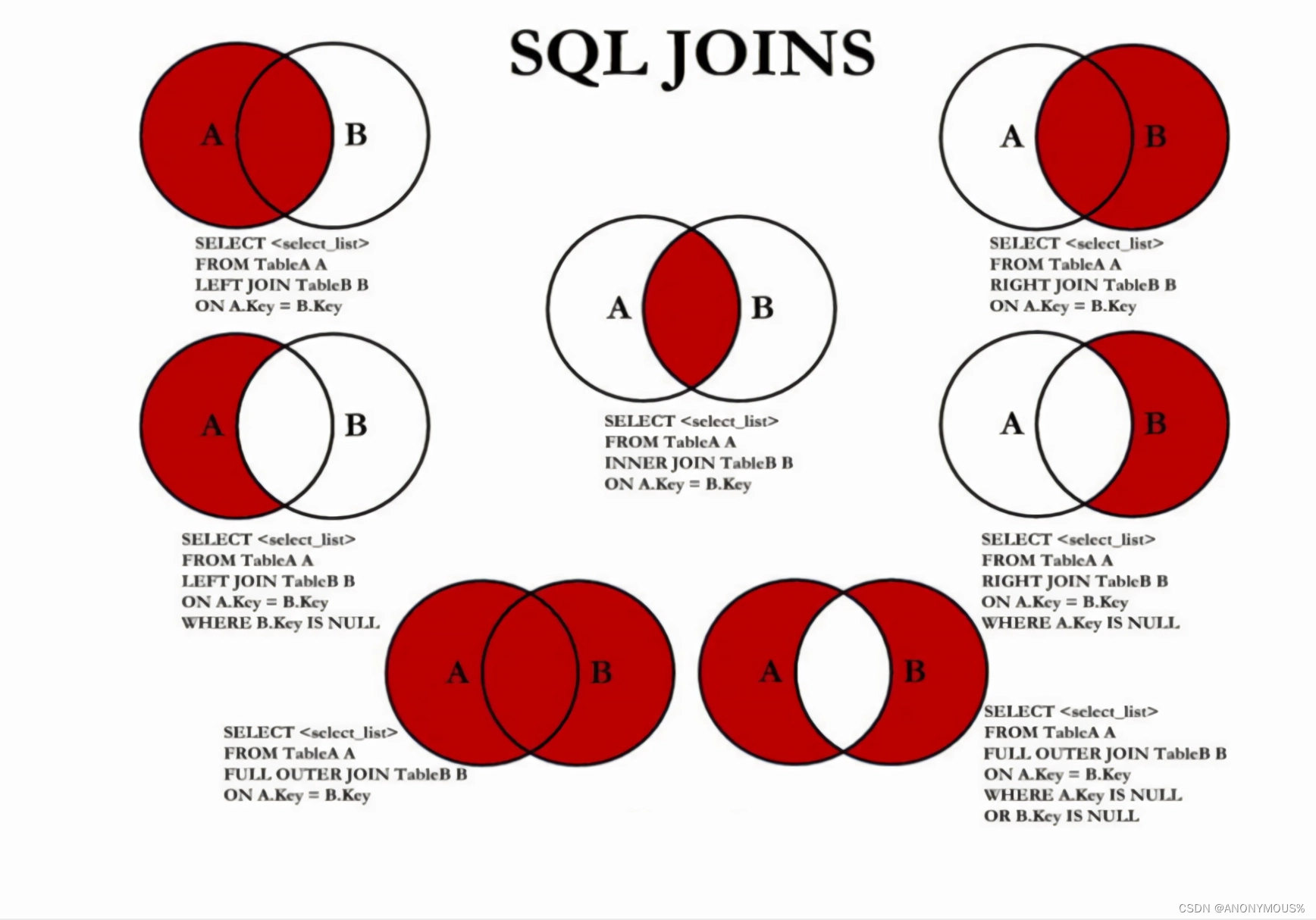
#中图:内连接 A∩B
SELECT employee_id,last_name,department_name
FROM employees e
JOIN departments d ON e.`department_id` = d.`department_id`;
#左上图:左外连接
SELECT employee_id,last_name,department_name
FROM employees e
LEFT JOIN departments d ON e.`department_id` = d.`department_id`;
#右上图:右外连接
SELECT employee_id,last_name,department_name
FROM employees e
RIGHT JOIN departments d ON e.`department_id` = d.`department_id`;
#左中图:A - A∩B
SELECT employee_id,last_name,department_name
FROM employees e
LEFT JOIN departments d ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL #对上面的结果进行留空操作,null数据均为左表的
#右中图:B-A∩B
SELECT employee_id,last_name,department_name
FROM employees e
RIGHT JOIN departments d ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL #对上面的结果进行留空操作,null数据均为右表的
#左下图 满外连接:左中图 + 右上图 A∪B
SELECT employee_id,last_name,department_name
FROM employees e
LEFT JOIN departments d ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL #没有去重操作,效率高
SELECT employee_id,last_name,department_name
FROM employees e
RIGHT JOIN departments d ON e.`department_id` = d.`department_id`;
#右下图 左中图 + 右中图
SELECT employee_id,last_name,department_name
FROM employees e
LEFT JOIN departments d ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e
RIGHT JOIN departments d ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
8. 函数
8.1 函数简介
- 总结使用频率较低,了解即可
- 在
SQL中我们可以使用函数对检索出来的数据进行函数操作 - 函数可分成 内置函数 和 自定义函数;内置函数可分为 单行函数 、 聚合函数(或分组函数)
- 单行函数可分为 字符串函数、日期和时间函数、数值函数、流程控制函数、加密与解密函数、MySQL信息函数
- 聚合函数:聚合函数作用于一组数据,并对一组数据返回一个值。
8.2 聚合函数
- 聚合函数类型
- AVG() 平均值
- SUM() 算数和
- MAX() 最大值
- MIN() 最小值
- COUNT() 统计数
//可以对数值类型的数据 使用AVG 和 SUM 函数。
SELECT AVG(salary), MAX(salary),MIN(salary), SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%'; //只生成一行数据,
//可以对任意数据类型的数据 使用MIN 和 MAX 函数
SELECT MIN(hire_date), MAX(hire_date)
FROM employees;
//COUNT() 适用于任意数据类型
SELECT COUNT(*) //返回表中记录总数
FROM employees
WHERE department_id = 50;
//COUNT(expr) 返回expr不为空的记录总数
SELECT COUNT(commission_pct)
FROM employees
WHERE department_id = 50;
-
问题:用count(*),count(1),count(列名) 三种方式那种更好。
- 结论:count(*),count(1)好。
-
问题:能不能使用count(列名) 替换 count(*)
- 结论:不能,count(*)会统计值为 NULL 的行,而 count(列名)不会统计。
8.3 GROUP BY
- 可以使用GROUP BY子句将表中的数据分成若干组
- 在SELECT列表中所有不是聚合函数的列都应在 GROUP BY中出现
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id;
- 使用多个列分组
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id ;//department_id相同,job_id不同的多列记录
8.4 HAVING
- having是用来过滤分组的,用法和where相同
- 使用了聚合函数
- having不能单独使用,必须要跟GROUP BY一起使用
- 注意:不能再where中使用聚合函数,否则会报错。
ELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000;
- HAVING和WHERE的区别
- WHERE 不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。
- 当与其它表关联获取数据时,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。 WHERE 比 HAVING 更高效。
8.5 执行过程
- 查询的结构
SELECT ...,...
FROM ... JOIN ...
ON 关联条件
WHERE ... AND/OR ...
GROUP BY 分组
HAVING 过滤条件
ORDER BY ... ASC/DESC 排序
LIMIT ...分页
- SELECT执行顺序
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT 去重复 -> ORDER BY -> LIMIT
案例
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7
9. 子查询(不推荐)
9.1 单行子查询
- 案例导入:谁的工资比Able的高
#方式一 自连接 一般情况下建议使用自连接
SELECT e2.last_name,e2.salary
FROM employees e1,employees e2
WHERE e1.last_name = 'Abel'
AND e1.salary < e2.salary
#方式二
SELECT last_name,salary
FROM employees
WHERE salary > (
SELECT salary
FROM employees
WHERE last_name = 'Abel'
);
- 使用HAVING查询最低工资大于50号部门最低工资的部门id和其最低工资
Select department_id, MIN(salary)
from employees
group by department_id
Having MIN(salary) >(
select MIN(salary)
from employees
GROUP BY department_id
Having department_id = 50;
);
9.2 多行子查询
| 操作符 | 含义 |
|---|---|
| IN | 等于列表中的任意一个 |
| ANY | 需要和单行比较操作符一起使用,和子查询返回的某一个值比较 |
| ALL | 需要和单行比较操作符一起使用,和子查询返回的所有值比较 |
| SOME | 实际上是ANY的别名,作用相同,一般常使用ANY |
查询平均工资最低的部门
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL (#返回最小的
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
);
10. 创建和管理
10.1 数据库
-
创建数据库
CREATE DATABASE IF NOT EXISTS 数据库名;创建数据库 -
使用数据库
-
SHOW DATABASES;查看所有的数据库 -
SELECT DATABASE();查看正在使用的数据库 -
SHOW TABLES FROM 数据库名;查看指定库下的所有表 -
USE 数据库名;切换/使用数据库
-
-
修改数据库
ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
-
删除数据库
drop database if exists 数据库名;
10.2 表
-
创建表
# 方式一 create table [IF NOT EXISTS] 表名( 字段1, 数据类型 [约束条件] [默认值], 字段2, 数据类型 [约束条件] [默认值], ); # 方式二 CREATE TABLE 表名 AS SELECT * FROM 已有表名; CREATE TABLE 表名 AS SELECT * FROM 已有表名 WHERE false; -- 创建与已有表相同字段的空表 -
修改表
# 向已有的表中添加列
alter table 表名 ADD 字段 数据类型;
#删除现有表中的列
ALTER TABLE 表名 drop 字段;
#修改现有表中的列
ALTER TABLE 表名 modify 字段 数据类型;
ALTER TABLE 表名 modify 字段 数据类型 default 默认值;
#重命名现有表中的列
ALTER TABLE 表名 change 旧字段 新字段 字段类型;
- 重命名表
RENAME TABLE 旧表名 TO 新表名; - 删除表
DROP TABLE 表名 - 清空表
DELETE FROM 表名;
11. 增删改
11.1 插入数据
- 所有字段添加数据
INSERT INTO 表名 VALUES (......); - 指定字段添加数据
INSERT INTO 表名(字段1,字段2...) VALUES (......); - 同时插入多条语句
INSERT INTO 表名 (字段1,字段2,字段3)
VALUES
(......),
(......),
...
(......);
- 将查询结果插入到表中
INSERT INTO 要插入的表名
SELECT *
FROM 要查询的表明
WHERE 条件;
11.2 更新数据
UPDATE 表名
SET 新数据
WHERE 更新满足的条件; #省略 WHERE,则表中的所有数据都将被更新
#例如
UPDATE employees
SET department_id = 70
WHERE employee_id = 113;
11.3 删除数据
DELETE FROM 表名
WHERE 删除满足的条件;
#例如
DELETE FROM departments
WHERE department_id = 60;
12. 约束
12.1 约束分类
-
根据约束的作用范围,约束可分为:
- 列级约束:只能作用在一个列上,跟在列的定义后面
- 表级约束:可以作用在多个列上,不与列一起,而是单独定义
-
根据约束起的作用,约束可分为:
-
NOT NULL 非空约束,规定某个字段不能为空
-
UNIQUE 唯一约束,规定某个字段在整个表中是唯一的
-
PRIMARY KEY 主键(非空且唯一)约束
-
FOREIGN KEY 外键约束
-
DEFAULT 默认值约束
-
12.2 非空约束
# 建表时
CREATE TABLE 表名称(
字段名 数据类型 NOT NULL,
字段名 数据类型 NOT NULL
);
#建表后
alter table 表名 modify 字段名 数据类型 NOT NULL;
# 删除非空约束
alter table 表名 modify 字段名 数据类型 NULL;
12.3 唯一性约束
# 建表时 表示该列记录不能重复
create table 表名称(
字段名 数据类型 unique key,
字段名 数据类型 unique key,
字段名 数据类型
UNIQUE KEY(字段1,字段2) #表级约束,表示:两者组合起来的记录不能重复
);
# 建表后
alter table 表名 modify 字段名,数据类型 unique KEY;
# 删除唯一性约束
SELECT * FROM information_schema.table_constraints WHERE table_name = '表名'; # 查看表的约束
ALTER TABLE 表名 DROP index 索引名; #再对该表的索引名进行操作
12.4 主键约束
#主键约束 = 唯一约束+非空约束;主键约束列不允许重复,也不允许出现空值
#建表时
create table 表名称(
字段名 数据类型 primary key, #列级模式
字段名 数据类型
);
# 建表后
ALTER TABLE 表名称 ADD PRIMARY KEY(字段列表); #字段列表可以是一个字段,也可以是多个字#段。
#删除主键约束
alter table 表名称 drop primary key; # 因为主键约束只能有一个,所以直接删除表的主键约束即可
12.5 自增列
# 建表时
create table 表名称(
字段名 数据类型 primary key auto_increment, #关键字 auto_increment
字段名 数据类型 unique key,
字段名 数据类型 not null default 默认值,
);
# 建表后
alter table 表名称 modify 字段名 数据类型 auto_increment;
# 删除主键约束
alter table 表名称 modify 字段名 数据类型; # 去掉关键字auto_increment即可
# 重置auto_increment
alter table 表名 auto_increment = 值;
12.6 外键约束
-
先说总结:不得使用外键与级联,一切外键概念必须在应用层解决,但在测试时可以使用
-
作用:限定表的某个字段的引用只能是另一个表的已有记录
# 比如 员工 和部门; 要求员工表的部门编号列 必须是 部门表编号列已有的记录。
从表(子表): 员工表 #引用别人的表
主表(父表): 部门表 #被引用的表
- 特点
- 从表的外键列,必须引用/参考主表的主键或唯一约束的列
- 先创建主表,再创建从表
- 删表时先删从表或先删外键约束
- 当从表参考主表时,主表的记录不允许删除,如果要删除数据,先删除从表中依赖该记录的数据,然后才可以删除主表的数据
- 一个表可以建立多个外键约束
- 从表的外键列与主表被参照的列名字可以不同但数据类型必须一样,不一样则会报错。
- 当创建外键约束时,系统默认会在所在的列上建立对应的普通索引。但是索引名是外键的约束名。(根据外键查询效率很高)
- 删除外键约束后,必须 手动 删除对应的索引
#建表时
create table 主表名称( #主表
字段1 数据类型 primary key,
字段2 数据类型
);
create table 从表名称( #从表
字段1 数据类型 primary key,
字段2 数据类型,
FOREIGN KEY(从表字段) references 主表名(主表字段)
);
#建表后
ALTER TABLE 从表名 ADD FOREIGN KEY (从表字段) REFERENCES 主表名(主表字段);
- 约束等级
- Cascade :在父表上更新记录时,同步更新子表的记录
- Set null :在父表上更新记录时,将子表上匹配记录的列设为null,前提是子表的外键列不能设为not null
- No action :不允许对父表进行更改操作
- Restrict :同no action, 不允许更改(默认使用)
- Set default :设置为默认值
- 如果没有指定等级,就相当于Restrict方式
12.7 默认值约束
#建表时
create table 表名称(
字段名 数据类型 primary key,
字段名 数据类型 not null default 默认值,
);
#建表后
alter table 表名称 modify 字段名 数据类型 default 默认值 NOT NULL;
#如果该字段原来有非空约束,你还保留非空约束,那么在加默认值约束时,还得保留非空约束,否则非空约束就被删除了
#加非空约束同理
- 从表的外键列与主表被参照的列名字可以不同但数据类型必须一样,不一样则会报错。
- 当创建外键约束时,系统默认会在所在的列上建立对应的普通索引。但是索引名是外键的约束名。(根据外键查询效率很高)
- 删除外键约束后,必须 手动 删除对应的索引
#建表时
create table 主表名称( #主表
字段1 数据类型 primary key,
字段2 数据类型
);
create table 从表名称( #从表
字段1 数据类型 primary key,
字段2 数据类型,
FOREIGN KEY(从表字段) references 主表名(主表字段)
);
#建表后
ALTER TABLE 从表名 ADD FOREIGN KEY (从表字段) REFERENCES 主表名(主表字段);
- 约束等级
- Cascade :在父表上更新记录时,同步更新子表的记录
- Set null :在父表上更新记录时,将子表上匹配记录的列设为null,前提是子表的外键列不能设为not null
- No action :不允许对父表进行更改操作
- Restrict :同no action, 不允许更改(默认使用)
- Set default :设置为默认值
- 如果没有指定等级,就相当于Restrict方式
12.7 默认值约束
#建表时
create table 表名称(
字段名 数据类型 primary key,
字段名 数据类型 not null default 默认值,
);
#建表后
alter table 表名称 modify 字段名 数据类型 default 默认值 NOT NULL;
#如果该字段原来有非空约束,你还保留非空约束,那么在加默认值约束时,还得保留非空约束,否则非空约束就被删除了
#加非空约束同理














 24万+
24万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









