







JAVA爬虫入门篇——jsoup
前言:在一个偶然的机会下,我接到了一个网页爬虫的需求。但是之前对爬虫也只是偶尔听说,那么这次就借这次机会来进行一次爬虫相关入门。然而由于本人技术栈限制,这次仅是通过Java进行爬虫进行入门学习。
一、什么是爬虫,其技术原理是什么?
爬虫,也称为网络爬虫或网络机器人,是一种自动化的网络程序,用于从互联网上的网页中提取信息。爬虫的技术本质实现原理主要包括以下几个步骤:
1、请求网页:爬虫首先发送HTTP请求到目标网站的服务器,请求获取网页内容
2、解析内容:获取到网页后,爬虫会解析网页的HTML代码,提取出有用的信息,如文本、图片链接等
3、数据存储:提取出的信息通常会被存储到数据库或文件中,以供后续处理或分析
4、遵守规则:合理的爬虫要遵守网站所允许的爬虫规则
技术上,爬虫可能使用多种编程语言实现,如Python、Java等。爬虫的设计还需要考虑效率、并发处理、错误处理和网络安全等多方面的问题。
那么Python爬虫和Java爬虫有什么区别以及我们该如何选择呢?
总的来说,选择Python还是Java进行爬虫开发,很大程度上取决于项目需求、团队的技术栈偏好以及开发时间等限制。Python因其快速开发的优势和强大的数据处理能力,通常是爬虫初学者和数据科学相关项目首选。而Java则更适合需要高性能和大规模数据处理的企业级应用。
二、Java爬虫测试
1、依赖jsoup库
新建一个Maven项目,在pom中加入jsoup解析库的依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
2、需求分析
这里我们以中关村网站上的手机信息及价格为我们需要爬取的目标,进行代码开发
需求:获取目标网页中前四页手机信息及对应价格
需求解析:
第一步:首先打开目标网站,找到我们想要爬取的信息。这里我们可以看到一页中有多个手机信息及价格,那么理论上我们可以通过找到信息、及价格的列表进行遍历就可以了。
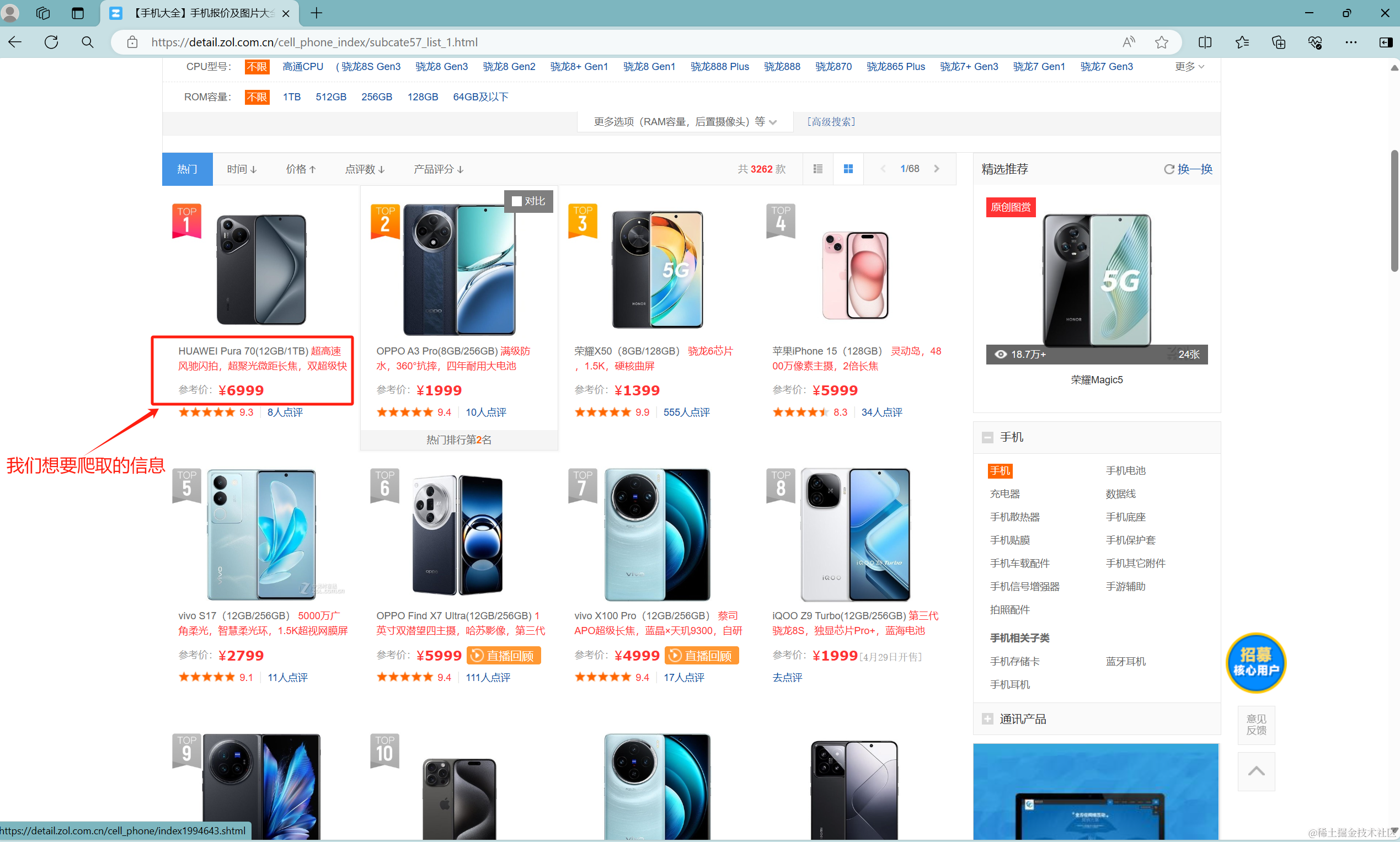
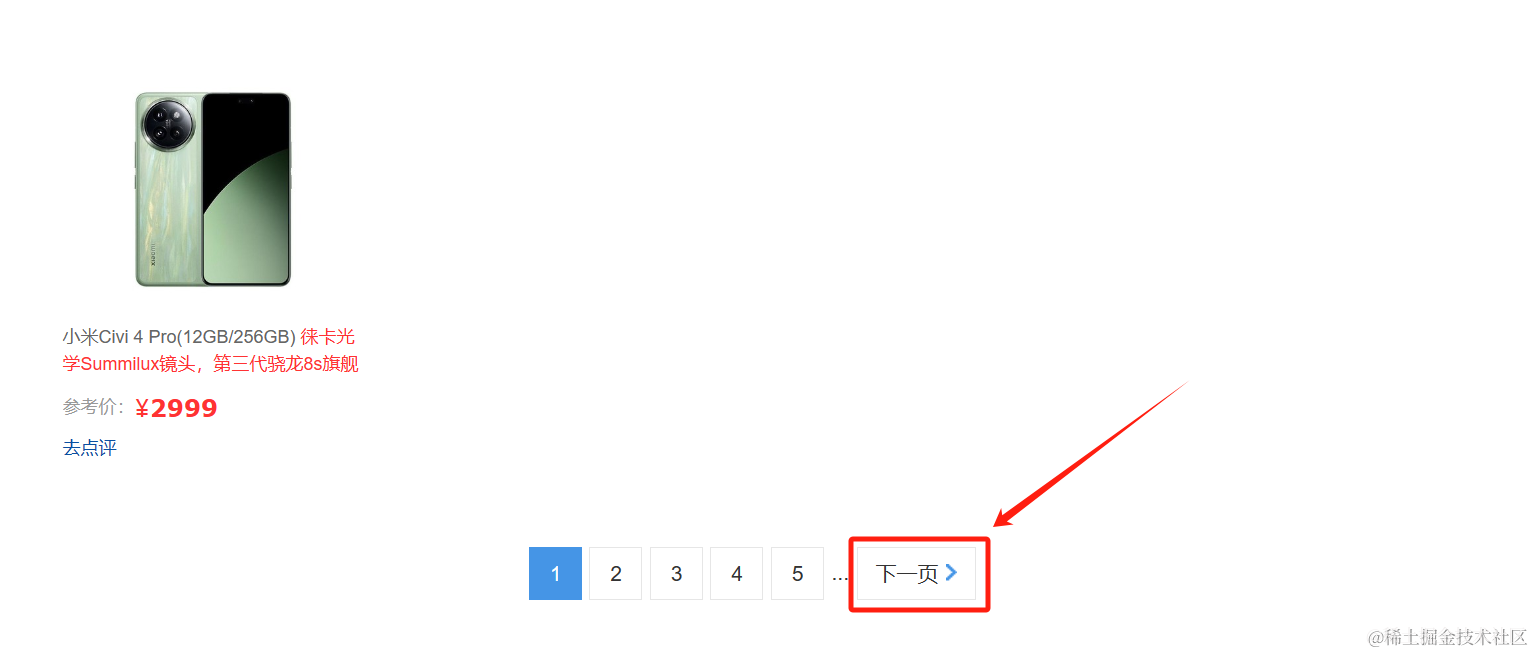
第二步:如何获取第二页的手机信息及价格——通过下一页按钮获取到下一页链接
3、获取到相关dom元素
这里需要一定的前端知识,通过浏览器开发者工具找到对应的dom元素。(我的前端知识太垃了,这里就不在关公面前耍大刀了)
前置知识获取:CSS选择器
4、代码实现
package org.living.getdataqichachademo.service.impl;
import lombok.extern.slf4j.Slf4j;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.living.getdataqichachademo.service.GetQichachaDataService;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.io.BufferedWriter;
import java.io.FileWriter;
@Service
@Slf4j
public class DemoServiceImpl implements DemoService {
private final Map<String, String> phoneMap = new HashMap<>();
private final List<String> nameList = new ArrayList<>();
private final List<String> priceList = new ArrayList<>();
private final String baseUrl = "https://detail.zol.com.cn";
private int pageNum = 1;
@Override
public void run(){
System.out.println("程序执行!");
String firstUrl = "/cell_phone_index/subcate57_list_1.html";
// 拼接成第一页的url
String url = baseUrl + firstUrl;
try {
// 获取第一页的手机名称及价格
this.getPhoneNameAndPrice(url);
log.info("获取完成第 {} 页手机及价格", pageNum);
pageNum++;
/**
* 开始获取第二页及以后页的手机名称及价格
*/
Document document = Jsoup.connect(url).get();
Elements elements = document.select(".next");
String nextPageUrl = baseUrl + elements.attr("href");
while(pageNume <= 4){
this.getPhoneNameAndPrice(nextPageUrl);
log.info("获取完成第 {} 页手机及价格", pageNum);
pageNum++;
// 获取下一页的url
document = Jsoup.connect(nextPageUrl).get();
elements = document.select(".next");
if (elements.isEmpty()) {
break;
} else {
nextPageUrl = baseUrl + elements.attr("href");
}
Thread.sleep(2000);
}
} catch (Exception e){
log.warn("爬取下一页错误!", e);
}
log.info("程序执行结束!!!");
}
/**
* @Description: 获取每一页的手机名称及价格
* @param url
*/
public void getPhoneNameAndPrice(String url){
try {
// 获取到目标网页的dom元素
Document document = Jsoup.connect(url).get();
Elements elements = document.select(".pic-mode-box");
for (Element element : elements) {
Elements elements1 = element.select(".pic");
/**
* 获取手机名称
*/
for (Element element1 : elements1){
Element imgElement = element1.select("img").first();
String phoneName = imgElement.attr("alt");
nameList.add(phoneName);
}
/**
* 获取手机价格
*/
Elements elements2 = element.select(".price-row");
for (Element element2 : elements2) {
String phonePrice = element2.text();
priceList.add(phonePrice);
}
}
/**
* 将手机名称信息及价格对应起来
*/
for (int i = 0; i < nameList.size(); i++) {
String name = nameList.get(i);
String price = priceList.get(i);
phoneMap.put(name, price);
}
/**
* 将map中的数据写入到文本文件中
*/
String filePath = "D:/phonePrice.txt";
try (BufferedWriter writer = new BufferedWriter(new FileWriter(filePath, true))) {
for (Map.Entry<String, String> entry : phoneMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
writer.write(entry.getKey() + ": " + entry.getValue());
writer.newLine(); // 添加换行符
}
}
phoneMap.clear();
nameList.clear();
priceList.clear();
} catch (Exception e){
log.warn("获取手机名称及价格错误!", e);
}
}
}















 3566
3566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









