







第三章 - 基础数据类型(下)
3.4 列表(List)
3.4.1 列表(list)
列表(list)也是最常用的 Python 数据类型之一,它以一个方括号[] 内包含多个其他数据项(字符串,数字等甚至是另一个列表),数据项间以逗号作为分隔的数据类型。
*列表为可变数据类型,列表中可以有重复值。
3.4.2 列表的创建
在Python中,使用中括号 [] 来创建列表,用 , 分割列表中每一元素。空列表可以使用 [] 或者 list() 来创建空列表。
list1 = [] # 创建一个空列表
print(list1) # []
print(type(list1)) # 查看列表的类型
list2 = list("zhangsan123")
print(list2) # ['z', 'h', 'a', 'n', 'g', 's', 'a', 'n', '1', '2', '3']
# 配合range函数来使用
print(list(range(4))) # [0, 1, 2, 3]
嵌套列表
使用嵌套列表即在列表里创建其它列表,例如:
a = ['a', 'b', 'c']
n = [1, 2, 3]
x = [a, n]
print(x)
# [['a', 'b', 'c'], [1, 2, 3]]
print(x[0])
# ['a', 'b', 'c']
print(x[0][1])
# 'b'
3.4.3 列表查询
当我们想要访问列表的时候我们可以使用索引与切片来查看列表中的元素。
list1 = ['Z','H','a',12,4,'san',567,1]
# 正序取单值
print(list1[0]) # 'Z'
print(list1[2]) # 'a'
# 反序取值
print(list1[-1]) # 1
# 切片取值,取出来的是一个新的列表
print(list1[3:-2]) # [12, 4, 'san']
当我们想要逐个取出列表中所有的值我们可以使用循环来做
list1 = ['Z','H','a',12,4,'san',567,1]
for i in list1:
print(i)
# 或者使用索引
for i in range(0,len(list1)):
print(list1[i])
我们可以使用 index() 查找某个元素在列表中的具体索引位置。
| 方法 | 含义 |
|---|---|
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
list1 = ['Z','H','a',12,4,'san',567,1]
# index 会有一个返回值我们可以使用变量来接收或者直接打印出来
result = list1.index(12)
print(result) # 3
print(list1.index("san")) # 5
3.4.4 列表增加
列表是一个可变的数据类型,我们就可以在列表中追加新的内容在列表中。
在循环一个列表时的过程中,如果你要改变列表的大小(增加值,或者删除值),那么结果很可能会出错或者报错。
| 方法 | 含义 |
|---|---|
| list.append(obj) | 在列表末尾添加新的对象 |
list1 = ["张三","李四"]
print(id(list1)) # 140439551629320
list1.append("王五")
print(id(list1)) # 140439551629320
print(list1)
# ['张三', '李四', '王五']
# 我们在追加前后加了查看地址,得到的结果我们可以看见是同一个地址。
| 方法 | 含义 |
|---|---|
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
list1 = ["张三","李四"]
list2 = [1,2,3]
list1.extend(list2)
print(list1) # ['张三', '李四', 1, 2, 3]
# 当添加一个列表时,将列表中的逐个元素追加在原列表中
list2.extend(["张三","李四"])
print(list2) # [1, 2, 3, '张三', '李四']
# 当添加的是一个字符串,会将字符串中的每个元素追加到列表中
list2.extend('lisi')
print(list2) # [1, 2, 3, '张三', '李四', 'l', 'i', 's', 'i']
# 这里list2 经历了两次追加
| 方法 | 含义 |
|---|---|
| list.insert(index, obj) | 将对象按索引插入列表中 |
list1 = ["张三","李四"]
# 插入单个元素
list1.insert(1,'王二麻')
print(list1) # ['张三', '王二麻', '李四']
# 插入一个列表
list1.insert(1,[1,2,3])
print(list1) # ['张三', [1, 2, 3], '王二麻', '李四']
在列表中我们还可以使用 + 将两个列表连接成一个新的列表。
list1 = ['张三']
list2 = [1,2,3]
list3 =list1+list2
print(list3)
# ['张三', 1, 2, 3]
同样可以使用 * 来得到对应重复的列表
list1 = ['张三']
print(list1*3) # ['张三', '张三', '张三']
3.4.5 列表删除
当我们想要对列表多余元素进行删除可以有以下操作
| 方法 | 含义 |
|---|---|
| list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
list1 = ['张三', [1, 2, 3], '王二麻', '李四']
# 使用pop不给索引,会删除列表中最后一个
result1 = list1.pop()
print(result1) # 李四
print(list1) # ['张三', [1, 2, 3], '王二麻']
# pop删除会有一个返回值,会返回删除的值
result2 = list1.pop(1)
print(result2) # [1, 2, 3]
print(list1) # ['张三', '王二麻']
| 方法 | 含义 |
|---|---|
| list.remove(obj) | 移除列表中某个值的第一个匹配项 |
注意:remove是没有返回值的
list1 = ['张三',1,1,23,'李四','张三',1]
list1.remove('张三')
print(list1) # [1, 1, 23, '李四', '张三', 1]
list1.remove(1)
print(list1) # [1, 23, '李四', '张三', 1]
| 方法 | 含义 |
|---|---|
| list.clear() | 清空列表 |
list1 = ['张三',1,1,23,'李四','张三',1]
list1.clear()
print(list1) # []
在Python列表中还可以使用del配上切片来删除列表中的元素
# del
lst = ['张三', '李四', '王二麻', 10]
#按照索引删除该元素
del lst[2]
print(lst) # ['张三', '李四', 10]
lst = ['张三', '李四', '王二麻', 10]
# 切片删除该元素
del lst[1:]
print(lst) # ['张三']
lst = ['张三', '李四', '王二麻', 10]
# 切片(步长)删除该元素
del lst[::2]
print(lst) # ['李四', 10]
3.4.6 列表修改
在Python列表中我们使用索引来修改列表中的某个元素。
list1 = ['张三',1,1,23,'李四','张三',1]
list1[2] = '王二麻'
print(list1) # ['张三', 1, '王二麻', 23, '李四', '张三', 1]
list1[2:3] = ['王二麻','san']
list1[2:3] = '王二麻','san' # 不适用列表也可以
print(list1) # ['张三', 1, '王二麻', 'san', 23, '李四', '张三', 1]
# 采用间隔切片,长度与值要保证足够匹配
list1[2:5:2] = ['王二麻','san']
print(list1) # ['张三', 1, '王二麻', 23, 'san', '张三', 1]
3.4.7 列表的其他用法
列表中可以使用以下函数:
| 序号 | 函数 | 含义 |
|---|---|---|
| 1 | len(list) | 列表元素个数 |
| 2 | max(list) | 返回列表元素最大值 |
| 3 | min(list) | 返回列表元素最小值 |
| 4 | list(seq) | 将元组转换为列表 |
# len()
list1 = ['张三', 1, '王二麻', 23, 'san', '张三', 1]
print(len(list1)) # 7
# max与min列表中必须是同一种类型
# 当列表内容为字符串,则比对是其ASCII码的值
list2 = ['张三','李四','zhangsan']
print(max(list2)) # zhangsan
print(min(list2)) # 李四
# 当列表中内容为数字,则直接比对数字大小
list3 = [1,20,4,33,6,5,7]
print(max(list3)) # 33
print(min(list3)) # 1
# list()
list4 = list('张三')
print(list4) # ['张', '三']
列表的其他方法包括:
| 序号 | 方法 | 含义 |
|---|---|---|
| 1 | list.count(obj) | 统计某个元素在列表中出现的次数 |
| 2 | list.reverse() | 反向列表中元素 |
| 3 | list.sort( key=None, reverse=False) | 对原列表进行排序 |
| 4 | list.copy() | 复制列表 |
list1 = ['张三', 1, '王二麻', 23, 'san', '张三', 1]
# count()
result = list1.count('张三')
print(result) # 2
# reverse()
list1.reverse()
print(list1)
# [1, '张三', 'san', 23, '王二麻', 1, '张三']
# 序列化列表中必须为同类型的int或者str类型,这里与max,min要求以及排序方法类似
# sort(key = None,reverse =False)
'''
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)。
'''
list2 = [2,3,34,5,1,34]
list2.sort()
print(list2) # [1, 2, 3, 5, 34, 34]
list2.sort(reverse =True)
print(list2) # [34, 34, 5, 3, 2, 1]
# copy()
lst = list1.copy()
print(lst)
# [1, '张三', 'san', 23, '王二麻', 1, '张三']
3.5 元组(Tuple)
Python 的元组与列表类似,不同之处在于元组的元素不能修改。元组是不可变数据类型。 所以对于元组的操作就不能增加、修改、删除。
元组使用小括号( ),列表使用方括号 [ ]。
3.5.1 元组的创建
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。元组和列表内容可以出现相同的值。
# 创建空元组
tup1 = ()
# 创建有数据元组
tup1 = ('张三', '李四', 1997, 2000)
tup2 = (1, 2, 3, 4, 5 )
tup3 = "a", "b", "c", "d" # 不需要括号也可以
type(tup3)
# <class 'tuple'>
元组中只包含一个元素时,需要在元素后面添加逗号 , ,否则括号会被当作运算符使用:
tup1 = (10)
print(type(tup1))
# <class 'int'>
tup2 = (10,)
print(type(tup2))
# <class 'tuple'>
3.5.2 元组查询
元组的查询与列表一样使用索引与切片来查询值。
| 正序索引 | 0 | 1 | 2 | 3 | 4 |
| 值 | “张三” | “李四” | “王二麻” | 12 | 34 |
| 负序索引 | -5 | -4 | -3 | -2 | -1 |
tup1 = ("张三","李四","王二麻",12,34)
# 使用索引查询
print(tup1[0]) # 张三
# 使用切片查询
print(tup1[1:4]) # ('李四', '王二麻', 12)
print(tup1[0:4:2]) # ('张三', '王二麻')
因为元组与列表都是可迭代对象,可以使用for循环查询提取每个元素。
# 直接迭代
for i in tup1:
print(i)
# 使用索引迭代
for i in range(0,len(tup1)):
print(tup1[i])
同样元组可以反向查询一个元素的索引,以及某个元素出现的次数
tup1 = ("张三",12,"李四",12,"王二麻",12,34)
# tuple.index(obj)
print(tup1.index('张三')) # 0
# tuple.count(obj)
print(tup1.count(12)) # 3
3.5.3 元组的基础操作
1、元组嵌套
在一个元组中可以嵌套元组的。
tup1 = (1,2,3,(2,3,4,(6,7)),(8,9))
print(tup1[3]) # (2, 3, 4, (6, 7))
print(tup1[3][3]) # (6, 7)
print(tup1[4]) # (8, 9)
2、元组的运算
与字符串一样,元组之间可以使用 +、+=和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
tup1 = (1,2,3,)
tup2 = (4,5,6)
tup3 = tup1 + tup2
print(tup3) # (1, 2, 3, 4, 5, 6)
tup1 += tup2
print(tup1) # (1, 2, 3, 4, 5, 6)
print(tup2 * 3) # (4, 5, 6, 4, 5, 6, 4, 5, 6)
print(3 in tup1) # True
3、删除元组
因为元组为不可变数据类型,我们不能使用元组的内建函数来删除元组中的元素,但是可以使用del来删除整个元组。
tup1 = ("张三","李四","王二麻",12,34)
print(tup1) # ('张三', '李四', '王二麻', 12, 34)
del tup1
print(tup1) # 报错 NameError: name 'tup1' is not defined
3.5.4 元组可使用函数
| 函数名 | 描述 |
|---|---|
| len(tuple) | 计算元组元素个数。 |
tuple1 = ('张三', '李四', '王五')
print(len(tuple1))
# 3
| 函数名 | 描述 |
|---|---|
| max(tuple) | 返回元组中元素最大值。 |
tuple2 = ('5', '4', '8')
print(max(tuple2))
# '8'
| 函数名 | 描述 |
|---|---|
| min(tuple) | 返回元组中元素最小值。 |
tuple2 = ('5', '4', '8')
print(min(tuple2))
# '4'
| 函数名 | 描述 |
|---|---|
| tuple(iterable) | 将可迭代系列转换为元组。 |
list1= ['张三', '李四', '王二麻', 456]
tuple1=tuple(list1)
print(tuple1)
# ('张三', '李四', '王二麻', 456)
元组为不可变数据类型,通常我们会把重要的数据,不能让别人改变的放入元组中。
3.6 字典(Dict)
在Python3中字典(dictionary ,简写为dict)是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 (key=>value) 对用冒号 (😃 分割,每对之间用逗号 (,) 分割,整个字典包括在花括号 ({}) 中 ,格式如下所示:
dict = {key1 : value1, key2 : value2 }
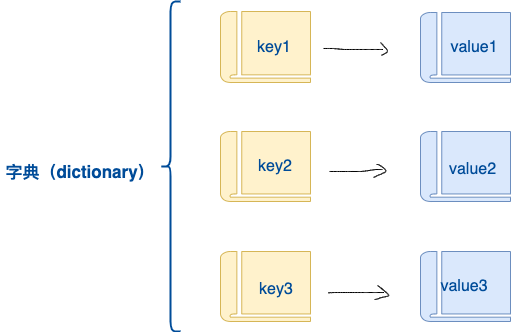
字典的特性
键必须是唯一的,但值则不必。
1、不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住。
2、键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行,值可以取任何数据类型。
3.6.1 创建字典
使用大括号 {} 来创建空字典
dict1 = {}
dict2 = dict()
# 打印字典
print(dict1)
print(dict2)
# 查看类型
print(type(dict1))
print(type(dict2))
dict1 = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
print(dict1)
3.6.2 字典的查询
字典的查询使用key来查询。
dict1 = {'name':'张三','age':18,'sex':'男'}
print(dict1['name']) # 张三
print(dict1['age']) # 18
print(dict1['sex']) # 男
# 如果查询的键不在字典中会报错
print(dict1['height']) # KeyError: 'height'
| 方法 | 描述 |
|---|---|
| dict.keys() | 以列表返回所有键 |
| dict.values() | 以列表形式返回所有值 |
dict1 = {'name':'张三','age':18,'sex':'男'}
# keys()
key_list = dict1.keys()
print(key_list)
# dict_keys(['name', 'age', 'sex'])
# values()
value_list = dict1.values()
print(value_list)
# dict_values(['张三', 18, '男'])
| 方法 | 描述 |
|---|---|
| dict.get(key,default=None) | 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| dict.items() | 以列表返回一个视图对象,键值对以元组形式保存在列表中 |
dict1 = {'name':'张三','age':18,'sex':'男'}
# get()
result = dict1.get('name')
print(result) # 张三
print(dict1.items())
# dict_items([('name', '张三'), ('age', 18), ('sex', '男')])
使用for循环得到查询
dict1 = {'name':'张三','age':18,'sex':'男'}
# 遍历列表得到列表的键
for i in dict1:
print(i) # 得到键
print(dict1[i]) # 利用索引得到值
'''
# 结果
name
张三
age
18
sex
男
'''
dict1 = {'name':'张三','age':18,'sex':'男'}
# 遍历keys()得到的列表获取到键,值
for key in dict1.keys():
print(key)
print(dict1[key])
'''
# 结果:
name
张三
age
18
sex
男
'''
dict1 = {'name':'张三','age':18,'sex':'男'}
# 逐个获取值
for value in dict1.values():
print(value)
'''
# 结果:
张三
18
男
'''
dict1 = {'name':'张三','age':18,'sex':'男'}
# 获取items()得到的列表,以元组形式返回
for i in dict1.items():
print(i)
'''
# 结果:
('name', '张三')
('age', 18)
('sex', '男')
'''
# 使用两个变量,分别来接收items返回元组中的值
for key,value in dict1.items():
print(key,value)
'''
# 结果:
name 张三
age 18
sex 男
'''
3.6.3 字典的增加
在Python中可以使用索引键赋值的形式来添加新的键值对。
在循环一个字典的过程中,不要改变字典的大小(增,删字典的元素),这样会直接报错。
dict1 = {}
# 如果dict中没有出现这个key,就会将key-value组合添加到这个字典中
dict1['name'] = '张三'
dict1['age'] = 18
print(dict1)
# {'name': '张三', 'age': 18}
| 方法 | 描述 |
|---|---|
| dict.setdefault(key, default=None) | 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
dict1 ={} # 创建一个空字典
# 如果字典中没有,则添加这个键,值(如果不给值,则默认为None),并返回添加则值
s1 = dict1.setdefault('name','张三')
print(s1) # 张三
print(dict1)
# {'name': '张三'}
# 如果字典中存在则不会更改,并将值返回
s2 = dict1.setdefault('name','zhnagsan')
print(s2) # 张三
print(dict1)
# {'name': '张三'}
3.6.4 字典的删除
| 方法 | 描述 |
|---|---|
| dict.pop(key[,default]) | 删除字典 key(键)所对应的值,返回被删除的值。 |
| dict.popitem() | 返回并删除字典中的最后一对键和值。 |
| dict.clear() | 删除字典内所有元素 |
dict1 = {'name':'张三','age':18,'sex':'男'}
# pop() 通过键删除字典中键值对,如果没有则返回默认值
result1 = dict1.pop('sex')
print(result) # 男
print(dict1) # {'name': '张三', 'age': 18}
# popitem() 3.5版本之前,popitem为随机删除,3.6之后为删除最后一个,有返回值
result2 = dict1.popitem()
print(result) # ('age', 18)
print(dict1) # {'name': '张三'}
# clear() 清空字典
dict1.clear()
print(dict1) # {}
另外我们还可以使用 del 来进行删除操作
dict1 = {'name':'张三','age':18,'sex':'男'}
# 通过键删除键值对
del dict1['name']
print(dict1) # {'age': 18, 'sex': '男'}
# 删除整个字典
del dict1
3.6.5 字典的修改
使用键索引修改
dict1 = {'name':'张三','age':18,'sex':'男'}
dict1['name'] = 'zhangsan'
print(dict1)
# {'name': 'zhangsan', 'age': 18, 'sex': '男'}
使用函数修改
| 方法 | 描述 |
|---|---|
| dict.update(dict2) | 把字典dict2的键/值对更新到dict里 |
# update
dic = {'name': '张三', 'age': 18}
dic.update(name = 'zhangsan')
print(dic)
# {'name': 'zhangsan', 'age': 18}
dic = {'name': '张三', 'age': 18}
dic.update(sex='男', height=175)
print(dic)
# {'name': '张三', 'age': 18, 'sex': '男', 'height': 175}
dic = {'name': '张三', 'age': 18}
dic.update([(1, 'a'),(2, 'b'),(3, 'c'),(4, 'd')])
print(dic)
# {'name': '张三', 'age': 18, 1: 'a', 2: 'b', 3: 'c', 4: 'd'}
dic1 = {"name":"jin","age":18,"sex":"male"}
dic2 = {"name":"zhangsan","weight":75}
dic1.update(dic2)
print(dic1)
# {'name': 'zhangsan', 'age': 18, 'sex': 'male', 'weight': 75}
print(dic2)
# {'name': 'zhangsan', 'weight': 75}
3.6.6 字典的其他用法
1、字典的嵌套
dict1 = {
'name' : '张三',
'age' : '18',
'informations' : [{'height':'175cm','weight':'75kg'}],
'interests' : {
'one':'打篮球',
'two':'游泳',
'three':'打游戏',}
}
# 获取姓名
print(dict1['name'])
# 张三
# 获取informations字典
print(dict1['informations'][0])
# {'height': '175cm', 'weight': '75kg'}
# 获取weight信息
print(dict1['informations'][0]['weight'])
# 75kg
# 获取interests的所有信息
for i in dict1['interests']:
print(dict1['interests'][i])
# for key in dict1['interests'].keys():
# print(dict1['interests'][key])
# for value in dict1['interests'].values():
# print(value)
# for key,value in dict1['interests'].items():
# print(key,value)
'''
打篮球
游泳
打游戏
'''
# 获取interests的第二个信息
print(dict1['interests']['two'])
# 游泳
2、其他函数
| 方法 | 描述 |
|---|---|
| dict.copy(seq[, value])) | 返回一个字典的浅复制 |
| dict.fromkeys() | 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| key in dict | 如果键在字典dict里返回true,否则返回false |
dict1 = {'name':'张三'}
dict2 = dict1.copy() # 浅copy,深浅copy见第二章
print(dict2) # {'name': '张三'}
dic = dict.fromkeys('abcd','张三')
print(dic) # {'a': '张三', 'b': '张三', 'c': '张三', 'd': '张三'}
dic = dict.fromkeys([1, 2, 3],'张三')
print(dic) # {1: '张三', 2: '张三', 3: '张三'}
# 这里有一个坑,就是如果通过fromkeys得到的字典的值为可变的数据类型,那么你的小心了。
result = 'name' in dict1
print(result) # True
3.7 集合(set)
集合(set)是一个无序的不重复元素序列。可变的数据类型,
集合里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。以下是集合最重要的两点:
1、去重,把一个列表变成集合,就自动去重了。
2、关系测试,测试两组数据之前的交集、差集、并集等关系。
lst = [1,3,4,112,23,1,3,1,41,12,3,1]
print(set(lst)) # 这样就没有重复的元素出现了,我们在将集合抓换成列表
list(set(lst)) # 这样就把没有重复的集合转成列表了
print(list(set(lst)))
3.7.1 集合的创建
可以使用大括号 { } 或者 set() 函数创建集合,
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
# 创建空集合
set1 = set()
print(type(set1)) # <class 'set'>
set1 = set('san') # 这里必须放一个可迭代的数据类型,数字不行
print(set1) # {'s', 'a', 'n'}
set2 = {1,2,'san'}
print(set2) # {'san', 1, 2}
set3 = set({1,2,'san'})
print(set3) # {'san', 1, 2}
3.7.2 集合查询
set 是不支持索引的,所以在这里我们不能使用索引查看查看
set1 = {1,2,3,4,56,7}
# 自动排序
for i in set1:
print(i)
3.7.3 集合增加
| 方法 | 描述 |
|---|---|
| set.add() | 为集合添加元素 |
| set.update() | 给集合添加元素 |
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.add("郑裕玲")
print(s)
# {'郑裕玲', '关之琳', '刘嘉玲', '王祖贤'}
s.add("郑裕玲") # 重复的内容不会被添加到set集合中
print(s)
# {'郑裕玲', '关之琳', '刘嘉玲', '王祖贤'}
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.update("麻花藤") # 迭代更新
print(s)
# {'王祖贤', '麻', '藤', '关之琳', '花', '刘嘉玲'}
s.update(["张曼⽟", "李若彤","李若彤"])
print(s)
# {'王祖贤', '麻', '藤', '李若彤', '关之琳', '花', '张曼⽟', '刘嘉玲'}
3.7.4 集合删除
| 方法 | 描述 |
|---|---|
| set.pop() | 随机移除元素 |
| set.remove() | 移除指定元素 |
| set.clear() | 移除集合中的所有元素 |
| set.discard() | 删除集合中指定的元素 |
set1 = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"}
set1.discard('关之琳') # 指定删除
print(set1) # {'李若彤', '刘嘉玲', '王祖贤', '张曼⽟'}
item = set1.pop() # 随机弹出⼀个.
print(item)
print(set1)
set1.remove("关之琳") # 直接删除元素
# set1.remove("⻢⻁疼") # 不存在这个元素. 删除会报错
print(set1)
set1.clear() # 清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和dict区分的.
print(set1) # set()
另外del可以删除集合
del set1 # 删除集合
print(set1)
3.7.5 集合修改
set集合中的数据没有索引,也没有办法去定位⼀个元素, 所以没有办法进⾏直接修改。
我们可以采⽤先删除后添加的⽅式来完成修改操作。
s = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"}
# 把刘嘉玲改成赵本⼭
s.remove("刘嘉玲")
s.add("赵本⼭")
print(s)
3.7.6 集合的运算
1、交集。(& 或者 set.intersection() )
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2) # {4, 5}
print(set1.intersection(set2)) # {4, 5}
2、并集。(| 或者 set.union() )
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7,8}
print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7,8}
3、差集。(- 或者 set.difference() )
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2) # {1, 2, 3}
print(set1.difference(set2)) # {1, 2, 3}
# difference_update() 移除集合中的元素,该元素在指定的集合也存在。
set1.difference_update(set2)
print(set1) # {1, 2, 3}
4、反交集。 (^ 或者 set.symmetric_difference() )
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8}
5、子集与超集
| 方法 | 描述 |
|---|---|
| set.issuperset(set) | 方法用于判断指定集合的所有元素是否都包含在原始的集合中,如果是则返回 True,否则返回 False。 |
| set.issubset(set) | 方法用于判断集合的所有元素是否都包含在指定集合中,如果是则返回 True,否则返回 False。 |
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
3.7.7 集合其他函数使用
| 方法 | 描述 |
|---|---|
| set.isdisjoint(set) | 方法用于判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
x = {"apple", "banana", "cherry"}
y = {"google", "runoob", "facebook"}
# 判断集合 y 中是否有包含 集合 x 的元素:
z = x.isdisjoint(y)
print(z) # True
x = {"apple", "banana", "cherry"}
y = {"google", "runoob", "apple"}
z = x.isdisjoint(y)
print(z) # False
frozenset不可变集合,让集合变成不可变类型。
s = frozenset('barry')
print(s,type(s))
# frozenset({'a', 'y', 'b', 'r'})
# <class 'frozenset'>
3.8 类型转换
3.8.1 int bool str 之间的转换
# int ---> bool
i = 100
print(bool(i)) # True # 非零即True
i1 = 0
print(bool(i1)) # False 零即False
# bool ---> int
t = True
print(int(t)) # 1 True --> 1
t = False
print(int(t)) # 0 False --> 0
# int ---> str
i1 = 100
print(str(i1)) # '100'
# str ---> int
# 全部由数字组成的字符串才可以转化成数字
s1 = '90'
print(int(s1)) # 90
# str ---> bool
s1 = '太白'
s2 = ''
print(bool(s1)) # True 非空即True
print(bool(s2)) # False
# bool ---> str
t1 = True
print(str(True)) # 'True'
3.8.2 str list 转换
# str ---> list
s1 = '张三 李四 王五'
print(s1.split()) # ['张三', '李四', '王五']
# list ---> str # 前提 list 里面所有的元素必须是字符串类型才可以
l1 = ['张三', '李四', '王五']
print(' '.join(l1)) # '张三 李四 王五
3.8.3 list 与 set 转换
# list ---> set
s1 = [1, 2, 3]
print(set(s1))
# set ---> list
set1 = {1, 2, 3, 3,}
print(list(set1)) # [1, 2, 3]
3.8.4 str 与 bytes 转化
# str ---> bytes
s1 = '太白'
print(s1.encode('utf-8')) # b'\xe5\xa4\xaa\xe7\x99\xbd'
# bytes ---> str
b = b'\xe5\xa4\xaa\xe7\x99\xbd'
print(b.decode('utf-8')) # '太白'
类型之间可以进行相互转化,bool类型,只要不是空都为真(True),空则为假(False)
| 函数 | 描述 |
|---|---|
| int(x [,base]) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
3.9 数据类型总结
3.9.1 数据类型的分类情况
按存储空间的占用分(从低到高)
| 数字 | |
| 字符串 | |
| 集合: | 无序,即无序存索引相关信息 |
| 元组: | 有序,需要存索引相关信息,不可变 |
| 列表: | 有序,需要存索引相关信息,可变,需要处理数据的增删改 |
| 字典: | 有序,需要存key与value映射的相关信息, 可变,需要处理数据的增删改(3.6之后有序) |
按存值个数区分
| 标量/原子类型 | 数字,字符串 |
| 容器类型 | 列表,元组,字典 |
按可变不可变区分
| 可变 | 列表,字典 |
| 不可变 | 数字,字符串,元组,布尔值 |
按访问顺序区分
| 直接访问 | 数字 |
| 顺序访问(序列类型) | 字符串,列表,元组 |
| key值访问(映射类型) | 字典 |
3.9.2 关于列表循环的一些问题
1、循环添加
lst = [1,2,3,4,5,6]
for i in lst:
lst.append(7) # 这样写法就会一直持续添加7,导致死循环产生
print(lst)
print(lst)
2、列表循环删除错误实例
列表: 循环删除列表中的每⼀个元素
li = [11, 22, 33, 44]
for e in li:
li.remove(e)
print(li)
# 结果:
# [22, 44]
分析原因: for的运⾏过程. 会有⼀个指针来记录当前循环的元素是哪⼀个, ⼀开始这个指针指向第0 个。
然后获取到第0个元素. 紧接着删除第0个. 这个时候. 原来是第⼀个的元素会⾃动的变成 第0个。
然后指针向后移动⼀次, 指向1元素. 这时原来的1已经变成了0, 也就不会被删除了。
li = [11, 22, 33, 44]
for i in range(0, len(li)):
del li[i]
print(li)
# 结果: 报错
# 删除的时候li[0] 被删除之后. 后⾯⼀个就变成了第0个.
# 以此类推. 当i = 2的时候. list中只有⼀个元素. 但是这个时候删除的是第2个 肯定报错啊
经过分析发现. 循环删除都不⾏. 不论是⽤del还是⽤remove. 都不能实现. 那么pop呢?
用pop删除试一试
li = [11, 22, 33, 44]
for el in li:
li.pop() # pop也不⾏
print(li)
# 结果:
# [11, 22]
3、列表循环删除成功
只有这样才是可以的:
li = [11, 22, 33, 44]
for i in range(0, len(li)): # 循环len(li)次, 然后从后往前删除
li.pop() # 删除最后一项
print(li)
或者. ⽤另⼀个列表来记录你要删除的内容. 然后循环删除
li = [11, 22, 33, 44]
del_li = []
for e in li:
del_li.append(e)
for e in del_li:
li.remove(e)
print(li)
li = [1,2,3,4]
lst = li[:]
for i in lst:
li.remove(i)
print(li)
注意: 由于删除元素会导致元素的索引改变, 所以容易出现问题. 尽量不要再循环中直接去删除元素. 可以把要删除的元素添加到另⼀个容器中然后再批量删除.
4、字典的坑
dict中的fromkey(),再次重提 可以帮我们通过list来创建⼀个dict
dic = dict.fromkeys(["jay", "JJ"], ["周杰伦", "麻花藤"])
print(dic)
# {'jay': ['周杰伦', '麻花藤'], 'JJ': ['周杰伦', '麻花藤']}
代码中只是更改了jay那个列表. 但是由于jay和JJ⽤的是同⼀个列表. 所以. 前⾯那个改了. 后面那个也会跟着改
5、字典在循环时不能修改数据的大小
dict中的元素在迭代过程中是不允许进⾏添加和删除的
dic = {'k1': 'alex', 'k2': 'wusir', 'k3': '大宝哥'}
# 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
del dic[k]
# dictionary changed size during iteration, 在循环迭代的时候不允许进⾏删除操作
print(dic)
那怎么办呢? 把要删除的元素暂时先保存在⼀个list中, 然后循环list, 再删除
dic = {'k1': 'alex', 'k2': 'wusir', 'k3': '大宝哥'}
dic_del_list = []
# 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
dic_del_list.append(k)
for el in dic_del_list:
del dic[el]
print(dic)
# 使用两个字典进行删除
dic = {'k1': 'alex', 'k2': 'wusir', 'k3': '大宝哥'}
dic1 = dic.copy()
for i in dic1:
dic.pop(i)
print(dic)
集合在循环时不能修改数据的大小
set1 = {1,2,3,4,5,6}
for i in set1:
set1.pop()
print(set1)
# Traceback (most recent call last):
# File "/python项目/m2.py", line 224, in <module>
# for i in set1:
# RuntimeError: Set changed size during iteration
成功进行删除
set1 = {1,2,3,4,5,6}
set2 = set1.copy()
for i in set2:
set1.remove(i)
print(set1)
3.10 推导式
Python 推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。
Python 支持各种数据结构的推导式:
- 列表(list)推导式
- 字典(dict)推导式
- 集合(set)推导式
- 元组(tuple)推导式
3.10.1 列表推导式
列表推导式格式为:
[表达式 for 变量 in 列表]
[out_exp_res for out_exp in input_list]
或者
[表达式 for 变量 in 列表 if 条件]
[out_exp_res for out_exp in input_list if condition]
- out_exp_res:列表生成元素表达式,可以是有返回值的函数。
- for out_exp in input_list:迭代 input_list 将 out_exp 传入到 out_exp_res 表达式中。
- if condition:条件语句,可以过滤列表中不符合条件的值。
过滤掉长度小于或等于3的字符串列表,并将剩下的转换成大写字母:
names = ['Bob','Tom','alice','Jerry','Wendy','Smith']
new_names = [name.upper() for name in names if len(name)>3]
print(new_names)
# ['ALICE', 'JERRY', 'WENDY', 'SMITH']
计算 30 以内可以被 3 整除的整数:
multiples = [i for i in range(30) if i % 3 == 0]
print(multiples)
# [0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
3.10.2 字典推导式
字典推导基本格式:
{ key_expr: value_expr for value in collection }
或
{ key_expr: value_expr for value in collection if condition }
使用字符串及其长度创建字典:
listdemo = ['Google','Runoob', 'Taobao']
# 将列表中各字符串值为键,各字符串的长度为值,组成键值对
newdict = {key:len(key) for key in listdemo}
print(newdict)
# {'Google': 6, 'Runoob': 6, 'Taobao': 6}
提供三个数字,以三个数字为键,三个数字的平方为值来创建字典:
dic = {x: x**2 for x in (2, 4, 6)}
print(dic)
# {2: 4, 4: 16, 6: 36}
print(type(dic))
# <class 'dict'>
3.10.3 集合推导式
集合推导式基本格式:
{ expression for item in Sequence }
或
{ expression for item in Sequence if conditional }
计算数字 1,2,3 的平方数:
setnew = {i**2 for i in (1,2,3)}
print(setnew)
# {1, 4, 9}
判断不是 abc 的字母并输出:
a = {x for x in 'abracadabra' if x not in 'abc'}
print(a)
# {'d', 'r'}
print(type(a))
# <class 'set'>
3.10.4 元组推导式(生成器表达式)
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
元组推导式基本格式:
(expression for item in Sequence )
或
(expression for item in Sequence if conditional )
元组推导式和列表推导式的用法也完全相同,只是元组推导式是用 () 圆括号将各部分括起来,而列表推导式用的是中括号 [],另外元组推导式返回的结果是一个生成器对象。
例如,我们可以使用下面的代码生成一个包含数字 1~9 的元组:
a = (x for x in range(1,10))
print(a)
# <generator object <genexpr> at 0x7faf6ee20a50> # 返回的是生成器对象
# 使用 tuple() 函数,可以直接将生成器对象转换成元组
tuple(a)
# (1, 2, 3, 4, 5, 6, 7, 8, 9)
30 以内可以被 3 整除的整数:
multiples = [i for i in range(30) if i % 3 == 0]
print(multiples)
# [0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
3.10.2 字典推导式
字典推导基本格式:
{ key_expr: value_expr for value in collection }
或
{ key_expr: value_expr for value in collection if condition }
使用字符串及其长度创建字典:
listdemo = ['Google','Runoob', 'Taobao']
# 将列表中各字符串值为键,各字符串的长度为值,组成键值对
newdict = {key:len(key) for key in listdemo}
print(newdict)
# {'Google': 6, 'Runoob': 6, 'Taobao': 6}
提供三个数字,以三个数字为键,三个数字的平方为值来创建字典:
dic = {x: x**2 for x in (2, 4, 6)}
print(dic)
# {2: 4, 4: 16, 6: 36}
print(type(dic))
# <class 'dict'>
3.10.3 集合推导式
集合推导式基本格式:
{ expression for item in Sequence }
或
{ expression for item in Sequence if conditional }
计算数字 1,2,3 的平方数:
setnew = {i**2 for i in (1,2,3)}
print(setnew)
# {1, 4, 9}
判断不是 abc 的字母并输出:
a = {x for x in 'abracadabra' if x not in 'abc'}
print(a)
# {'d', 'r'}
print(type(a))
# <class 'set'>
3.10.4 元组推导式(生成器表达式)
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
元组推导式基本格式:
(expression for item in Sequence )
或
(expression for item in Sequence if conditional )
元组推导式和列表推导式的用法也完全相同,只是元组推导式是用 () 圆括号将各部分括起来,而列表推导式用的是中括号 [],另外元组推导式返回的结果是一个生成器对象。
例如,我们可以使用下面的代码生成一个包含数字 1~9 的元组:
a = (x for x in range(1,10))
print(a)
# <generator object <genexpr> at 0x7faf6ee20a50> # 返回的是生成器对象
# 使用 tuple() 函数,可以直接将生成器对象转换成元组
tuple(a)
# (1, 2, 3, 4, 5, 6, 7, 8, 9)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











