







 zookeeper集群 目录 前言一、Zookeeper 概述1.1 Zookeeper 工作机制1.2 Zookeeper 特点1.3 Zookeeper数据结构1.4 Zookeeper 应用场景1.5 Zookeeper 选举机制1.5.1 第一次启动选举机制1.5.2 非第一次启动选举机制 二、Zookeeper 集群部署2.1 环境准备2.2 安装 Zookeeper 软件,修改配置2.3 设置 myid2.4 添加系统启动服务2.5 查看集群状态 一、Zookeeper
zookeeper集群 目录 前言一、Zookeeper 概述1.1 Zookeeper 工作机制1.2 Zookeeper 特点1.3 Zookeeper数据结构1.4 Zookeeper 应用场景1.5 Zookeeper 选举机制1.5.1 第一次启动选举机制1.5.2 非第一次启动选举机制 二、Zookeeper 集群部署2.1 环境准备2.2 安装 Zookeeper 软件,修改配置2.3 设置 myid2.4 添加系统启动服务2.5 查看集群状态 一、Zookeeper
zookeeper集群
目录
一、Zookeeper 概述
- 定义:Zookeeper是一个开源的分布式的,为用户提供一个高性能、高可用,且具有严格顺序访问控制能力的分布式协调服务,是用Java编写创建的。
1.1 Zookeeper 工作机制
- Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在zookeeper上注册的那些观察者做出相应的反应。
- 也就是说 Zookeeper = 文件系统+通知机制。
1.2 Zookeeper 特点
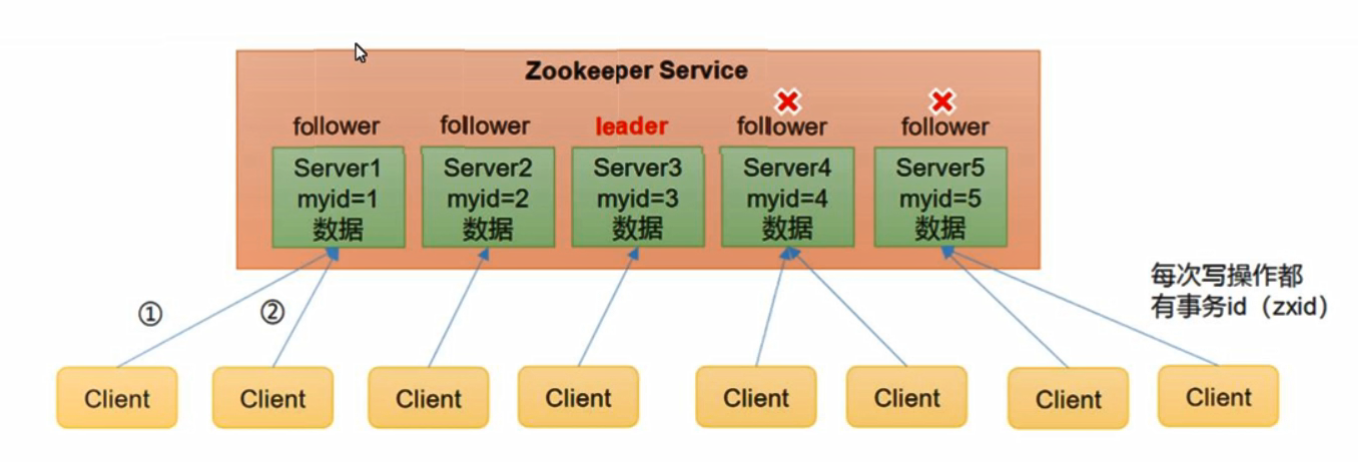
- Zookeeper 是由有 一个领导者(Leader),多个跟随者(Follower)组成的集群。
- Zookeepe 集群中只要有半数以上节点存活,Zookeeper 集群就能正常服务。所以 Zookeeper 适合安装奇数台服务器(最少三台)。
- 全局数据一致:每个 Server 保存一份相同的数据副本,Client 无论连接到哪个Server,数据都是一致的。
- 更新请求顺序执行,来自同一个 Client 的更新请求按其发送顺序依次执行,即先进先出。
- 数据更新原子性,一次数据更新要么成功,要么失败。
- 实时性,在一定时间范围内,Client 能读到最新数据。
1.3 Zookeeper数据结构
- ZooKeeper 数据模型的结构与 Linux 文件系统很类似,整体上可以看作是一颗多叉树,每个节点称做一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
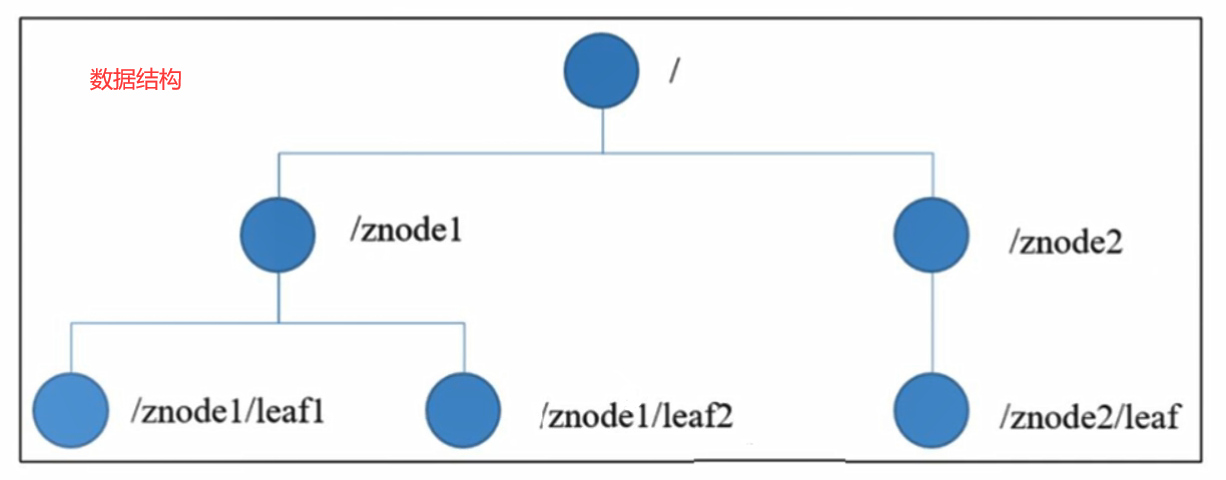
在每个结点上都存储了相应的数据,数据可以是字符串、二进制数。但是默认情况下每个结点的数据大小的上限是1M,这是因为Zookeeper主要是用来协调服务的,而不是存储数据,管理一些配置文件和应用列表之类的数据。虽然可以修改配置文件来改变数据大小的上限,但是为了服务的高效和稳定,建议结点数据不要超过默认值。
1.4 Zookeeper 应用场景
Zookeeper 提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
统一命名服务
- 在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如:IP不容易记住,而域名容易记住。
统一配置管理
- 分布式环境下,配置文件同步非常常见。一般要求一个集群中,所有节点的配置信息是一致的,比如Kafka集群。对配置文件修改后,希望能够快速同步到各个节点上。
- 配置管理可交由ZooKeeper实现。可将配置信息写入ZooKeeper上的一个Znode。各个客户端服务器监听这个Znode。一旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
统一集群管理
- 分布式环境中,实时掌握每个节点的状态是必要的。可根据节点实时状态做出一些调整。
- ZooKeeper可以实现实时监控节点状态变化。可将节点信息写入ZooKeeper上的一个ZNode。监听这个ZDMode可获取它的实时状态变化。
服务器动态上下线
- 客户端能实时洞察到服务器上下线的变化。
软负载均衡
- 在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求。
1.5 Zookeeper 选举机制
集群角色
- Leader (领导)
- Follower (追随者)
- Observer (观察员)
- 一个 ZooKeeper 集群同一时刻只会有一个 Leader,其他都是 Follower 或 Observer。ZooKeeper 配置很简单,每个节点的配置文件(zoo.cfg)都是一样的,只有 myid 文件不一样。myid 的值必须是 zoo.cfg中server.{数值} 的{数值}部分。
1.5.1 第一次启动选举机制
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息。此时服务器1发现服务器2的 myid 比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持 LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为 FOLLONING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOCKING 状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为 FOLLOWING;
(5)服务器5启动,同4一样当小弟。
1.5.2 非第一次启动选举机制
(1)当 ZooKeeper 集群中的一台服务器出现以下两种情况之一时,就会开始进入 Leader 选举:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4665
4665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









