







查看原文:【数据seminar】数据治理 | 数据分析与清洗工具:Pandas 基础
我们将在数据治理板块中推出一系列原创推文,帮助读者搭建一个完整的社科研究数据治理软硬件体系。该板块将涉及以下几个模块:
1. 计算机基础知识
2. 编程基础
(1) 数据治理 | 带你学Python之 环境搭建与基础数据类型介绍篇
(4) 数据治理 | 还在用Excel做数据分析呢?SQL它不香吗
(5) 数据治理 | 普通社科人如何学习SQL?一篇文章给您说明白
3. 数据采集
4. 数据存储
(1) 安装篇:数据治理 | 遇到海量数据stata卡死怎么办?这一数据处理利器要掌握
(2) 管理篇: 数据治理 | 多人协同处理数据担心不安全?学会这一招,轻松管理你的数据团队
(3) 数据导入:数据治理 | “把大象装进冰箱的第二步”:海量微观数据如何“塞进”数据库?
5. 数据清洗
(2) 本期内容:数据治理 | 数据分析与清洗工具:Pandas基础
6. 数据实验室搭建
目录
Part 1 前言
我们在【数据治理】板块中已经推出一些关于 Python 的技术文章,这一期将会向大家介绍 Python 编程,或者说 Python 数据清洗和数据分析中最重要(没有之一)的模块——Pandas。Pandas 中包含非常重要的数据结构和非常多实用的数据计算方法。为了更加清晰地了解 Pandas 模块,接下来我们将会用多篇文章,从不同深度介绍它的应用。希望学习 Pandas 能让你在数据处理和数据分析中如虎添翼!!!
Part 2 Pandas 和 Numpy
Pandas 提供了强大的 一维数据类型 Series 和 二维表格型数据结构 DataFrame(下文有相关解释),两者(尤其是后者)都提供了非常优秀实用的属性和方法。提起 Pandas ,熟悉它的人一般都会联想到 Python 的另一个模块——Numpy。这个反应是正常的,因为 Pandas 就是以 Numpy 为一大基础开发而来的。
Numpy 是Python 中科学计算的基础库。它是一个 Python 第三方库,提供了多维数组对象,以及用于数组快速操作的各种 API,有包括数学、逻辑、形状操作、排序、选择、输入输出、基本线性代数,基本统计运算和随机模拟等等。在 Python 中,已经有满足数组功能的列表,但是列表类型效率一般。Numpy 是一个 Python 库,部分用 Python 编写,但是大多数需要快速计算的部分都是用 C 或 C++ 编写的,旨在提供一个比传统 Python 列表处理速度快 50 倍的数组对象,Numpy 中的数组对象称为 ndarray,它封装了python原生的同数据类型的 n 维数组,使其计算效率非常之高。也就是说,Numpy 的精髓在于它性能强大的矩阵数据结构和高效的数学计算模型,而 Pandas 正是基于 Numpy 的数据结构所开发的,它继承了 Numpy 高效的计算框架,在处理较大数据集时也能游刃有余。
Part 3 DataFrame
在实际的工作生活中,大多数统计数据都是以二维表的形式存在,类似于 Excel 表格数据。Excel 中的工作簿(含有多个sheet 表)则可以被看作是三维数据。但其本质仍是二维数据的合集。二维数据在 Pandas 中的数据类型就是 DataFrame,也常被称为数据框。
1、什么是 DataFrame
DataFrame 其实就是一个 m行 x n列 的二维数据(一般m,n都不为零)。我们在 Python 交互式开发环境中生成并打印出一个简单的 DataFrame,并以这个数据来简单介绍一下 DataFrame 和 Series 的关系。生成数据的代码和打印结果如下:
import pandas as pd # 导入 pandas 模块,起别名为 pd
# 生成一个4行,8列;值全部为1的 DataFrame,赋值给变量 data (命名为data)
data_list = [[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15],
[16, 17, 18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29, 30, 31],
[32, 33, 34, 35, 36, 37, 38, 39],
[40, 41, 42, 43, 44, 45, 46, 47]] # 一个二维列表
data = pd.DataFrame(data_list, columns=list('ABCDEFGH'))
data # 打印生成的 DataFrame
输出如下:

图中最左侧一列中的 0,1,2,3表示 DataFrame 的行索引,DataFrame 行索引和列表等数据的索引一样,都是从 0 开始。最上面一行加粗的 A,B,C…… 则表示 DataFrame 的列索引,也称列名。
2、什么是 Series
DataFrame 的一行(row)或一列(column)数据,类似于一维数组,被称为 Series,不过 Series 并不只是单纯地一个序列,它是由索引和值构成的。我们将列名为 B 的一列数据输出,来查看 Series 数据类型是什么样子:
data['B']
输出如下:

这个 Series 所使用的索引其实就是 DataFrame 的索引。而许许多多个这样的一维数据 Series ,就构成了二维数据 DataFrame。
3、Series 与 DataFrame 的关系
如图:

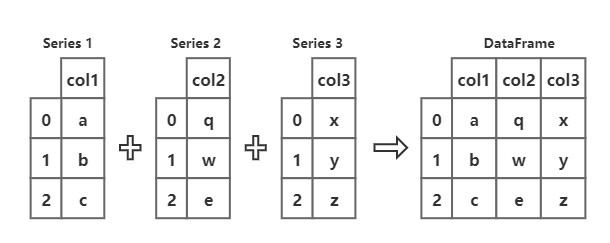
正如图中所示,DataFrame 的每一列都是一个 Series,多个(大于等于1)一维的 Series 就构成了 一个 二维的DataFrame 。
Part 4 DataFrame 的属性和方法
DataFrame 数据是具有很强大的兼容性的,我们既可以使用代码生成 DataFrame,也可以将我们本地存储的 Excel 表,csv 表以及数据库中的表读取为 DataFrame 类型并根据需要进行处理;处理完毕后也可以将 DataFrame 写入为 Excel 表,csv 表或者写入数据库。
为了方便理解,我们以一个实际的 Excel 表为例。Excel 表如下图所示:
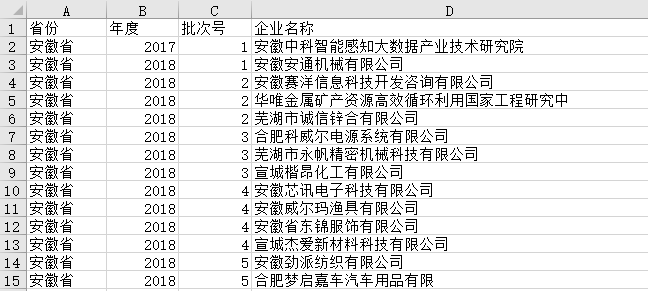
我们将会使用 Pandas 读取这张表为 DataFrame 类型,并用它介绍 DataFrame 类型的一些基本属性和方法,简单处理后再将其写入本地文件。
1、读取 Excel 表为 DataFrame
读取上面的 Excel 表的代码如下:
# 默认前面已经导入了 Pandas 模块
table = pd.read_excel('C:/Users/Ren/Desktop/中小科技企业.xlsx')
table
输出如下:

2、DataFrame 属性和方法
我们将使用上面读取到的 数据 table 来简单介绍一下一些 DataFrame 类型的简单属性和方法。
(1)筛选首尾数据
pandas.DataFrame.head(n) 表示一个 DataFrame 的前n行,默认参数值为 5。
table.head() # 输出 table 的前五行

不使用默认值,指定参数为 3,即 table 的前三行。
table.head(3) # 输出 table 的前三行

pandas.DataFrame.tail(n) :表示输出一个 DataFrame 的末尾n行,默认参数值为 。
table.tail(2) # 输出 table的末尾两行

(2) 输出列名称
pandas.DataFrame.columns :返回 DataFrame 的所有列索引(列名称)的信息。
table.columns # 输出结果为: # Index(['省份', '年度', '批次号', '企业名称'], dtype='object')
(3) 输出数据的行数与列数
pandas.DataFrame.shape:返回一个包含 DataFrame 行数和列数的元组。使用频率非常高。
table.shape # 输出为: # (14, 4),表示 table共有 14 行, 4 列
(4) 输出数据信息
pandas.DataFrame.info():返回 DataFrame 各列的基本信息以及所占内存的大小等。
table.info()

观察上图:
第一行表示数据的数据类型;
第二行中的 RangeIndex 表示行索引信息;
第三行往下是所有列的信息,我们生成的数据 data 共 6 行,图中的 "14 not-null" 表示该列共有 14 个非空值(又称缺失值);
最后一行中的 "momory usege" 则表示该数据在内存中所占用的空间大小。
(5) 数值数据统计
pandas.DataFrame.describe():返回各个数值列的基本数据分布和关键指数(最大值,最小值,平均数,中位数等)
table.describe()

观察上图:
第一行 count 中的值分别表示各列的数据量;
第二行 mean 中的值分别表示各列的数据的均值;
第三行 std 中的值分别表示各列的方差;
第四行 min 中的值分别表示各列的最小值;
第五行 25% 中的值分别表示各列的一分位数;
第六行 50% 中的值分别表示各列的二分位数(均值);
第七行 75% 中的值分别表示各列的的三分位数;
第八行 min 中的值分别表示各列的最大值。
这个方法只对值为数值型的数据生效,如果你的数据以数值型居多,这个方法将对你初步统计数据有很大帮助。
(6)添加&删除列
1. 在末尾追加一列
在 DataFrame 中添加一列最简单的方法就是直接赋值,给一列全部赋予同一个值。
table['新的一列'] = 'new' # 为 table 添加新的一列,列名称为'新的一列',值全部取'new'
table

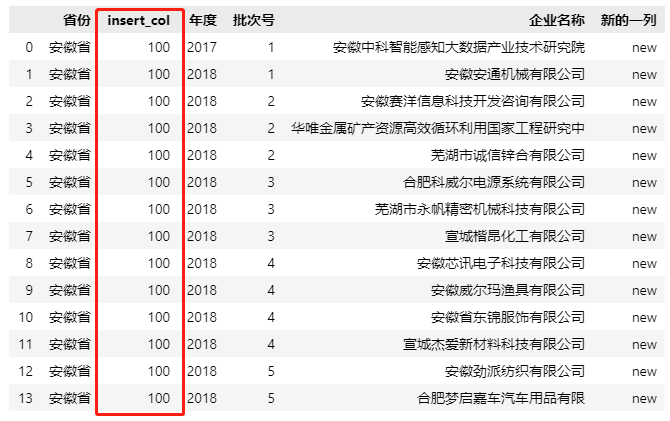
2. pandas.DataFrame.insert()
直接赋值的方法虽然方便,但是只能在 DataFrame 的末尾添加新列,如果想要在指定位置插入一列,我们可以使用 insert 方法在 DataFrame 的指定位置插入一列。insert方法主要有三个参数分别表示插入列的位置(所插入列的位置,从0开始计算),插入列的名称,插入列的取值。例如:
# 在 table 列位置为1的位置插入一列,
# 列名称为'新的一列',值全部取 100
table.insert(1,'insert_col',100)
table
3. pandas.DataFrame.drop()
可以增加新的列,当然也就会有删除现有的数据的操作,DataFrame 提供了一个 drop 方法,该方法既可以删除列,也可以删除行。删除列时,需要传入要删除的列名,并指定参数 axis=1,表示以横向为轴;删除行时,需要传入要删除行的行索引,并指定参数 axis=0,表示以纵向为轴。代码如下:
# 删除两列'insert_col','新的一列'
# 一次性删除多列时可以传入一个由待删除列名组成的列表
table = table.drop(['insert_col','新的一列'], axis=1)
table

删除行数据:
# 删除行索引为奇数(1,3,5,7,9,11,13)的所有行
# 删除行数据时,必须传入参数 axis=0,这也是默认值
table = table.drop([1,3,5,7,9,11,13], axis=0)
table

3、将 DataFrame 写入本地
Pandas 可以将 DataFrame 数据类型写入本地,可以保存为 Excel 表,csv 数据或者写入部署好的数据库中。这里将以写入为 Excel 表为例。
# 将处理后的数据保存为 Excel 表,存放在桌面
table.to_excel('C:/Users/Ren/Desktop/中小科技企业_处理后.xlsx')
我们可以在保存的路径中找到保存的数据:

Pandas 的应用千变万化,其中 DataFrame 类型的属性和方法远远不止以上所介绍的这些;同时,对于同一个操作,Pandas 往往会为使用者提供不止一个解决方案。想要了解更多 Pandas 的使用技巧的小伙伴,可以访问 Pandas 官方网站:https://pandas.pydata.org/pandas-docs/stable/reference/frame.html
Part 5 结束语
本篇文章介绍了 Pandas 中数据类型 DataFrame 的一些基本属性和方法。我们的目的在于,使想要学习 Pandas 的读者循序渐进地了解并使用它。所以本文最大的目的就是使读者了解 Pandas 中最重要数据类型 DataFrame。下期文章我们将继续介绍 Pandas,带领读者学习其中更加实用的数据处理方法。















 1274
1274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









