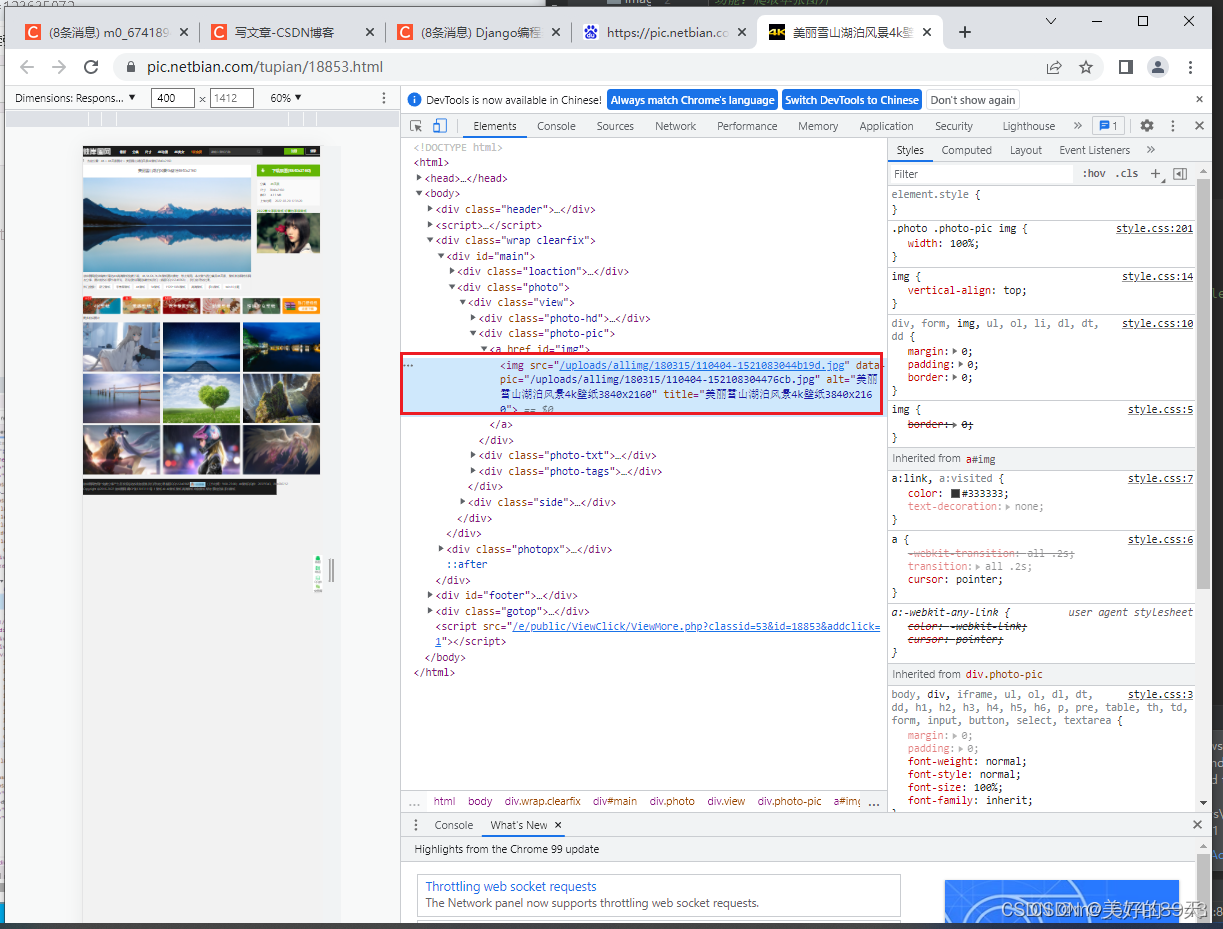
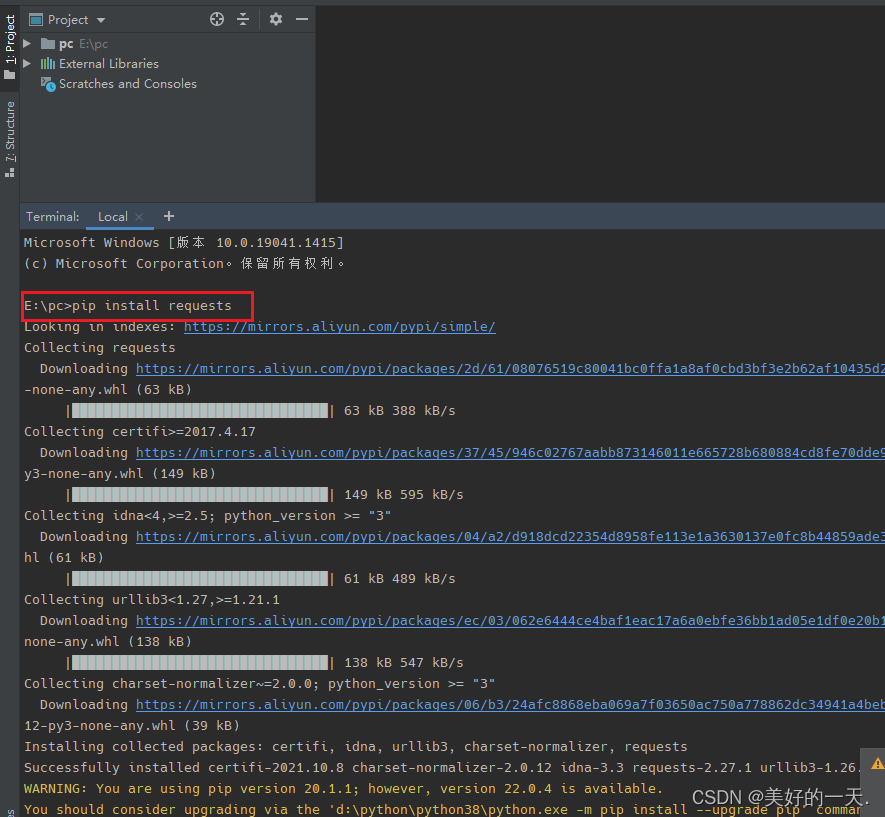
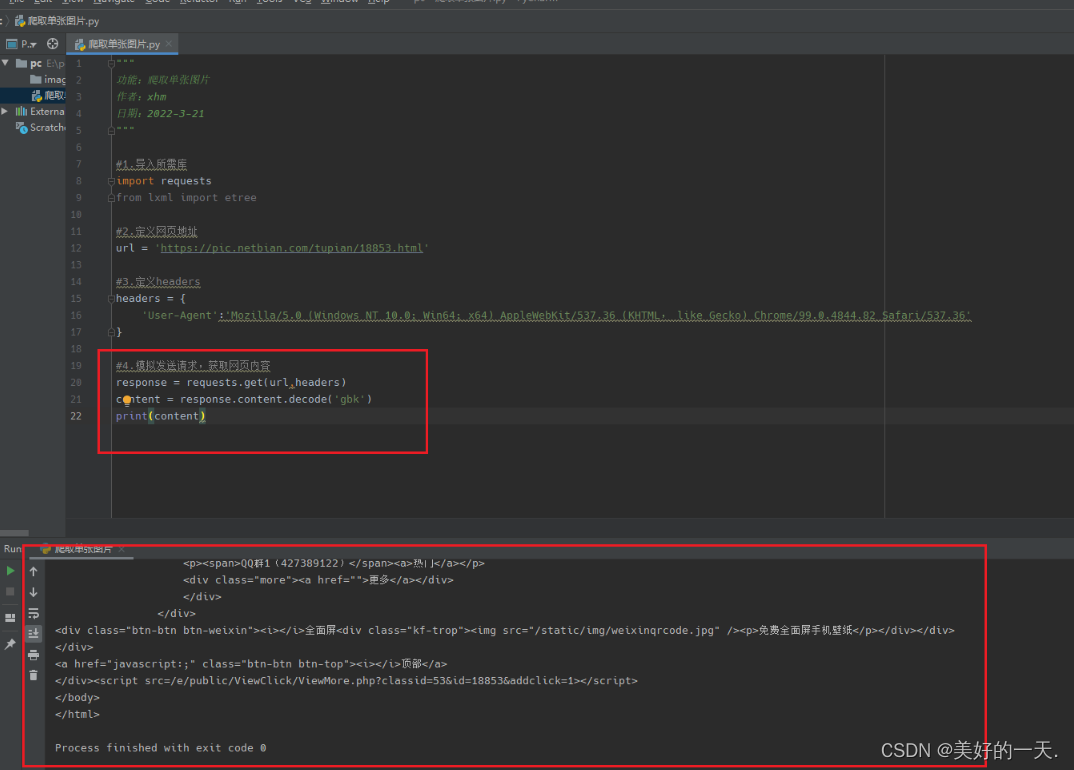
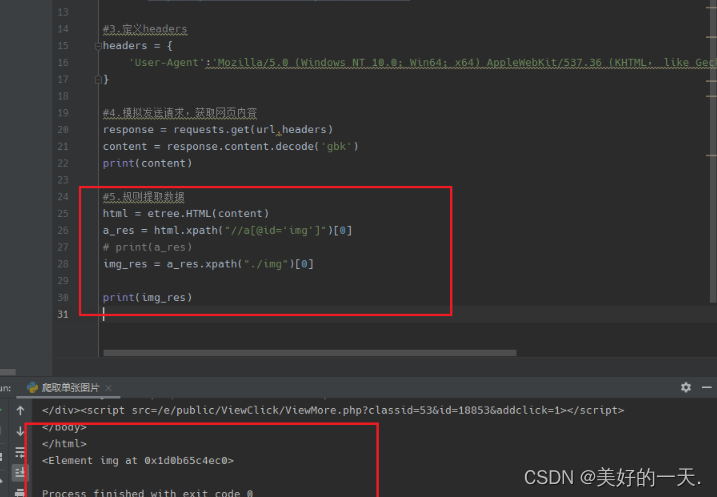
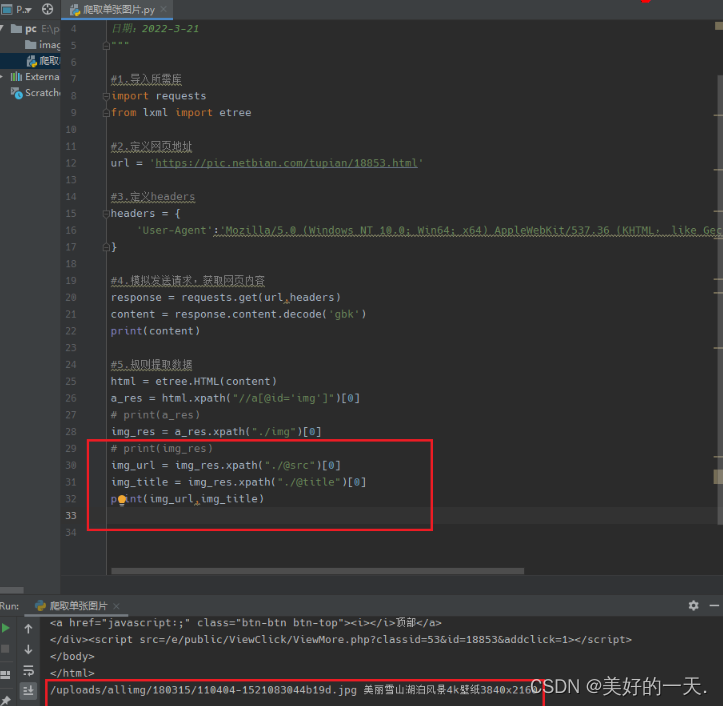
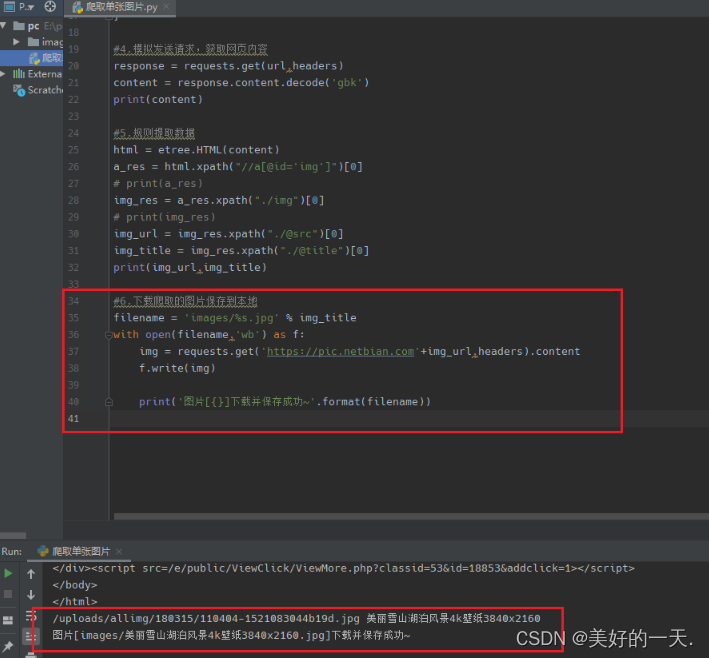
1.查看网页Network,了解情况 2.分析所要爬取网页的源代码,找到爬取图片的位置 3.新建一个python项目 4.在终端中输入pip install requests/lxml, 5.创建名为images的文件夹,方便存放爬取的图片 6.新建python文件,开始爬取单张图片 7.导入所需要的库并定义要爬取的网页 8.定义headers 9.模拟发送请求,从而获取网页的内容 10.搜索该属性值以及图像标签 11.搜索该网址和标题 12.最后下载所爬取图片并保存到本地























 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
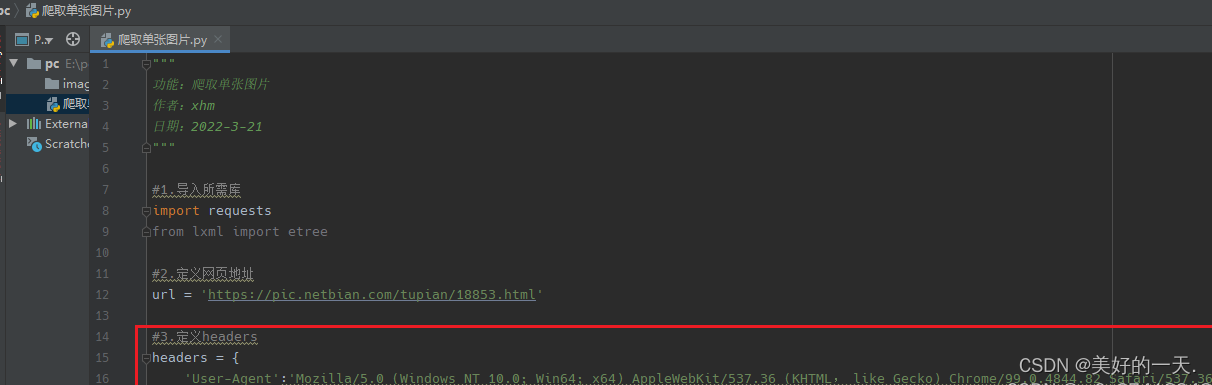
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






