










项目体系架构设计
文章篇幅太长、超出字数限制、所以只发出三分之一!需要阅读完整版的文章请私信我、发送给你哦!
文章转载自乐字节
项目系统架构
项目以某电商网站真实的业务数据架构为基础,将数据从收集到使用通过前端应用程序,后端程序,数据分析,平台部署等多方位的闭环的业务实现。形成了一套符合教学体系的电商日志分析项目,主要通过离线技术来实现项目。
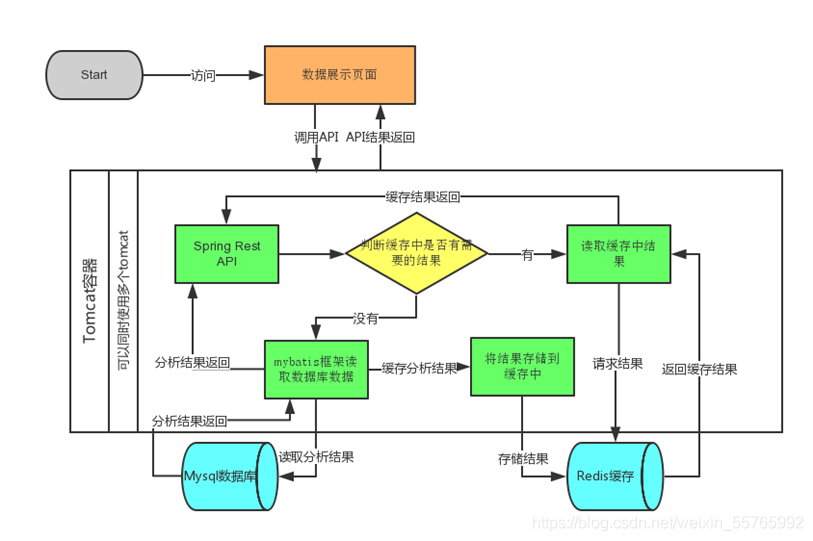
- 用户可视化:主要负责实现和用户的交互以及业务数据的展示,主体采用JS实现,不是在tomcat服务器上。
- 业务逻辑程序:主要实现整体的业务逻辑,通过spring进行构建,对接业务需求。部署在tomcat上。
- 数据存储
- 业务数据库:项目采用的是广泛应用的关系型数据库mysql,主要负责平台业务逻辑数据的存储
- HDFS分布式文件存储服务:项目采用HBase+Hive,主要用来存储历史全量的业务数据和支撑高速获取需求,以及海量数据的存储,为以后 的决策分析做支持。
- 离线分析部分
- 日志采集服务:通过利用Flume-ng对业务平台中用户对于页面的访问行为进行采集,定时发送到HDFS集群中
- 离线分析和ETL:批处理统计性业务采用MapReduce+Hivesql进行实现,实现对指标类数据的统计任务
- 数据转送服务:通过利用sqoop对业务数据批处理,主要负责将数据转送到Hive中
项目数据流程
-
分析系统(bf_transformer)
- 日志收集部分
- Flume从业务服务的运行日志中读取日志更新,并将更新的日志定时推送到HDFS中;HDFS在收到这些日志之后,通过MR程序对获取的日志信息进行过滤处理,获取用户访问数据流
UID|MID|PLATFORM|BROWER|TIMESTAMP;计算完成之后,将数据和HBase中的进行合并。
- Flume从业务服务的运行日志中读取日志更新,并将更新的日志定时推送到HDFS中;HDFS在收到这些日志之后,通过MR程序对获取的日志信息进行过滤处理,获取用户访问数据流
- ETL部分
- 通过MapReduce将系统初始化的数据,加载到HBase中。
- 离线分析部分
- 可以通过Oozie实现对离线统计服务以及离线分析服务的调度,通过设定的运行时间完成对任务的触发运行
- 离线分析服务从HBase中加载数据,将
浏览器维度信息、时间维度信息、kpi维度相关信息、操作系统信息维度、统计浏览器相关分析数据的统计、统计用户基本信息的统计、统计用户浏览深度相关分析数据的统计,多个统计算法进行实现,并将计算结果写到Mysql中;
- 日志收集部分
-
数仓分析服务
-
sql脚本的调度与执行
-
可以通过Oozie实现对数仓分析服务的调度,通过设定的运行时间完成对任务的触发运行
-
数据分析服务从各个系统的数据库中加载数据到HDFS中,HDFS在收到这些日志之后,通过MR程序对获取的数据进行过滤处理(进行数据格式的统一),计算完成之后,将数据和Hive中的进行合并;Hive获取到这些数据后,通过HQL脚本对获取的数据进行逻辑加工,将
交易信息、访问信息,多个指标进行实现;计算完成之后,将数据和Hive中的进行合并。
-
-
程序后台执行工作流
注意:不采用ip来标示用户的唯一性,我们通过在cookie中填充一个uuid来标示用户的唯一性。
在我们的js sdk中按照收集数据的不同分为不同的事件。
- 比如pageview事件等,Js sdk的执行流程如下:
-
分析
- PC端事件分析
针对我们最终的不同分析模块,我们需要不同的数据,接下来分别从各个模块分析,每个模块需要的数据。用户基本信息就是用户的浏览行为信息分析,也就是我们只需要pageview事件就可以了;
浏览器信息分析以及地域信息分析其实就是在用户基本信息分析的基础上添加浏览器和地域这个维度信息,,地域信息可以通过nginx服务器来收集用户的ip地址来进行分析,也就是说pageview事件也可以满足这两个模块的分析。
外链数据分析以及用户浏览深度分析我们可以在pageview事件中添加访问页面的当前url和前一个页面的url来进行处理分析,也就是说pageview事件也可以满足这两个模块的分析。
订单信息分析要求pc端发送一个订单产生的事件,那么对应这个模块的分析,我们需要一个新的事件chargeRequest。对于事件分析我们也需要一个pc端发送一个新的事件数据,我们可以定义为event。除此之外,我们还需要设置一个launch事件来记录新用户的访问。
Pc端的各种不同事件发送的数据url格式如下,其中url中后面的参数就是我们收集到的数据:http://shsxt.com/shsxt.gif?requestdata
最终分析模块 PC端js sdk事件 用户基本信息分析 pageview事件 浏览器信息分析 pageview事件 地域信息分析 pageview事件 外链数据分析 pageview事件 用户浏览深度分析 pageview事件 订单信息分析 chargeRequest事件 事件分析 event事件 用户基本信息修改 launch事件
PC端JS和SDK事件
- 通用参数
所有埋点中都会返回的相同信息。以下是通用参数具体内容
| 名称 | 内容 |
|---|---|
| 发送的数据 | u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time= 1449137597974&ver=1&pl=website&sdk=js& b_rst=1920*1080&u_ud=12BF4079-223E-4A57-AC60-C1A0 4D8F7A2F&b_iev=Mozilla%2F5.0%20(Windows%20NT%206. 1%3B%20WOW64)%20AppleWebKit%2F537.1%20(KHTML%2C%2 0like%20Gecko)%20Chrome%2F21.0.1180.77%20Safari% 2F537.1&l=zh-CN&en=e_l |
| 参数名称 | 类型 | 描述 |
|---|---|---|
| u_sd | string | 会话id |
| c_time | string | 客户端创建时间 |
| ver | string | 版本号, eg: 0.0.1 |
| pl | string | 平台, eg: website |
| sdk | string | Sdk类型, eg: js |
| b_rst | string | 浏览器分辨率,eg: 1800*678 |
| u_ud | string | 用户/访客唯一标识符 |
| b_iev | string | 浏览器信息useragent |
| l | string | 客户端语言 |
- Launch事件
当用户第一次访问网站的时候触发该事件,不提供对外调用的接口,只实现该事件的数据收集。
| 名称 | 内容 |
|---|---|
| 发送的数据 | en=e_l&通用参数 |
| 参数名称 | 类型 | 描述 |
|---|---|---|
| en | string | 事件名称, eg: e_l |
- 会员登陆时间
当用户登陆网站的时候触发该事件,不提供对外调用的接口,只实现该事件的数据收集。
| 名称 | 内容 |
|---|---|
| 发送的数据 | u_mid=phone&通用参数 |
| 参数名称 | 类型 | 描述 |
|---|---|---|
| u_mid | string | 会员id,和业务系统一致 |
- Pageview事件,依赖于onPageView类
当用户访问页面/刷新页面的时候触发该事件。该事件会自动调用,也可以让程序员手动调用。
| 方法名称 | 内容 |
|---|---|
| 发送的数据 | en=e_pv&p_ref=www.shsxt.com%3A8080&p_url =http%3A%2F%2Fwww.shsxt.com%3A8080%2Fvst_track%2Findex.html&通用参数 |
| 参数名称 | 类型 | 描述 |
|---|---|---|
| en | string | 事件名称, eg: e_pv |
| p_url | string | 当前页面的url |
| p_ref | string | 上一个页面的url |
-
ChargeSuccess事件
当用户下订单成功的时候触发该事件,该事件需要程序主动调用。
| 方法名称 | onChargeRequest |
|---|---|
| 发送的数据 | oid=orderid123&on=%E4%BA%A7%E5%93% 81%E5%90%8D%E7%A7%B0&cua=1000&cut=%E4%BA%BA%E6%B0 %91%E5%B8%81&pt=%E6%B7%98%E5%AE%9&en=e_cs &通用参数 |
| 参数 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
| orderId | string | 是 | 订单id |
| on | String | 是 | 产品购买描述名称 |
| cua | double | 是 | 订单价格 |
| cut | String | 是 | 货币类型 |
| pt | String | 是 | 支付方式 |
| en | String | 是 | 事件名称, eg: e_cs |
-
ChargeRefund事件
当用户下订单失败的时候触发该事件,该事件需要程序主动调用。
| 方法名称 | onChargeRequest |
|---|---|
| 发送的数据 | oid=orderid123&on=%E4%BA%A7%E5%93% 81%E5%90%8D%E7%A7%B0&cua=1000&cut=%E4%BA%BA%E6%B0 %91%E5%B8%81&pt=%E6%B7%98%E5%AE%9&en=e_cr &通用参数 |
| 参数 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
| orderId | string | 是 | 订单id |
| on | String | 是 | 产品购买描述名称 |
| cua | double | 是 | 订单价格 |
| cut | String | 是 | 货币类型 |
| pt | String | 是 | 支付方式 |
| en | String | 是 | 事件名称, eg: e_cr |
- Event事件
当访客/用户触发业务定义的事件后,前端程序调用该方法。
| 方法名称 | onEventDuration |
|---|---|
| 发送的数据 | ca=%E7%B1%BB%E5%9E%8B&ac=%E5%8A%A8%E4%BD%9C kv_p_url=http%3A%2F%2Fwwwshsxt…com %3A8080%2Fvst_track%2Findex.html&kv_%E5%B1%9E%E6 %80%A7key=%E5%B1%9E%E6%80%A7value&du=1000& en=e_e&通用参数 |
| 参数 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
| ca | string | 是 | Event事件的Category名称 |
| ac | String | 是 | Event事件的action名称 |
| kv_p_url | map | 否 | Event事件的自定义属性 |
| du | long | 否 | Event事件的持续时间 |
| en | String | 是 | 事件名称, eg: e_e |
-
数据参数说明
在各个不同事件中收集不同的数据发送到nginx服务器,但是实际上这些收集到的数据还是有一些共性的。下面将所用可能用到的参数描述如下:
参数名称 类型 描述 en string 事件名称, eg: e_pv ver string 版本号, eg: 0.0.1 pl string 平台, eg: website sdk string Sdk类型, eg: js b_rst string 浏览器分辨率,eg: 1800*678 b_iev string 浏览器信息useragent u_ud string 用户/访客唯一标识符 l string 客户端语言 u_mid string 会员id,和业务系统一致 u_sd string 会话id c_time string 客户端时间 p_url string 当前页面的url p_ref string 上一个页面的url tt string 当前页面的标题 ca string Event事件的Category名称 ac string Event事件的action名称 kv_* string Event事件的自定义属性 du string Event事件的持续时间 oid string 订单id on string 订单名称 cua string 支付金额 cut string 支付货币类型 pt string 支付方式 -
订单工作流如下所示:(退款类似)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-soXH2ZKG-1627010402703)(电商日志项目.assets/clip_image002.gif)]
-
分析
- 程序后台事件分析
本项目中在程序后台只会出发chargeSuccess事件,本事件的主要作用是发送订单成功的信息给nginx服务器。发送格式同pc端发送方式, 也是访问同一个url来进行数据的传输。格式为:
http://shsxt.com/shsxt.gif?requestdata
最终分析模块 PC端js sdk事件 订单信息分析 chargeSuccess事件 chargeRefund事件 -
chargeSuccess事件
当会员最终支付成功的时候触发该事件,该事件需要程序主动调用。
方法名称 onChargeSuccess 发送的数据 u_mid=shsxt&c_time=1449142044528&oid=orderid123&ver=1&en=e_cs&pl= javaserver&sdk=jdk 参数 类型 是否必填 描述 orderId string 是 订单id memberId string 是 会员id -
chargeRefund事件
当会员进行退款操作的时候触发该事件,该事件需要程序主动调用。
方法名称 onChargeRefund 发送的数据 u_mid=shsxt&c_time=1449142044528&oid=orderid123 &ver=1&en=e_cr&pl=javaserver&sdk=jdk 参数 类型 是否必填 描述 orderId string 是 订单id memberId string 是 会员id
-
集成方式
直接将java的sdk引入到项目中即可,或者添加到classpath中。
- 数据参数说明
参数描述如下:
| 参数名称 | 类型 | 描述 |
|---|---|---|
| en | string | 事件名称, eg: e_cs |
| ver | string | 版本号, eg: 0.0.1 |
| pl | string | 平台, eg: website,javaweb,php |
| sdk | string | Sdk类型, eg: java |
| u_mid | string | 会员id,和业务系统一致 |
| c_time | string | 客户端时间 |
| oid | string | 订单id |
项目数据模型
-
HBase存储结构
这里我们采用在rowkey中包含时间戳的方式来进行;hbase列簇采用log来标示列簇。所以最终我们创建一个单列簇的rowkey包含时间戳的eventlog表。
- create ‘eventlog’, ‘log’。rowkey设计规则为:timestamp+(uid+mid+en)crc编码项目中实际工作内容
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WrT28hDZ-1627010402705)(.\电商日志项目.assets\1594347991505.png)]
环境搭建
NginxLog文件服务(单节点)
1.上传,解压
//到根目录
cd /root
//上传文件
rz
//解压
tar -zxvf ./nginx-1.8.1.tar.gz
//删除压缩包
rm -rf ./nginx-1.8.1.tar.gz
2.编译安装
//编译安装
//提前安装nginx需要的依赖程序
yum install gcc pcre-devel zlib-devel openssl-devel -y
//找到configure文件
cd nginx-1.8.1/
//执行编译
./configure --prefix=/opt/sxt/nginx
//安装
make && make install
3.启动验证
//找到nginx启动文件
cd /opt/sxt/nginx/sbin
//启动
./nginx
//web端验证
shsxt-hadoop101:80
//常用命令
nginx -s reload
nginx -s quit
Flume-ng(单节点)
- 上传解压
//上传数据文件
mkdir -p /opt/sxt/flume
cd /opt/sxt/flume
rz
//解压
tar -zxvf apache-flume-1.6.0-bin.tar.gz
//删除
rm -rf apache-flume-1.6.0-bin.tar.gz
- 修改配置文件
cd /opt/sxt/flume/apache-flume-1.6.0-bin/conf
cp flume-env.sh.template flume-env.sh
vim flume-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
# 设置使用内存大小,只有当chnnel设置为内存存储的时候才会用到这个
# export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
- 修改环境变量
vim /etc/profile
export FLUME_HOME=/opt/sxt/flume/apache-flume-1.6.0-bin
export PATH=$FLUME_HOME/bin:
source /etc/profile
- 验证
flume-ng version
Sqoop (单节点)
- 安装
上传解压,配置文件修改,验证
//创建文件夹
mkdir -p /opt/sxt/sqoop
//上传
rz
//解压
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
//删除
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
//配置环境变量
export SQOOP_HOME=/opt/sxt/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
export PATH=$SQOOP_HOME/bin:
source /etc/profile
//添加mysql连接包
cd ./sqoop-1.4.6.bin__hadoop-2.0.4-alpha/lib/
//重命名配置文件
cd /opt/sxt/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/conf
mv sqoop-env-template.sh sqoop-env.sh
//修改配置文件(注释掉,不用的组件信息)
cd /opt/sxt/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/bin/configure-sqoop
vim configure-sqoop
//将以下内容注释
##if [ -z "${HCAT_HOME}" ]; then
## if [ -d "/usr/lib/hive-hcatalog" ]; then
## HCAT_HOME=/usr/lib/hive-hcatalog
## elif [ -d "/usr/lib/hcatalog" ]; then
## HCAT_HOME=/usr/lib/hcatalog
## else
## HCAT_HOME=${SQOOP_HOME}/../hive-hcatalog
## if [ ! -d ${HCAT_HOME} ]; then
## HCAT_HOME=${SQOOP_HOME}/../hcatalog
## fi
## fi
##fi
##if [ -z "${ACCUMULO_HOME}" ]; then
## if [ -d "/usr/lib/accumulo" ]; then
## ACCUMULO_HOME=/usr/lib/accumulo
## else
## ACCUMULO_HOME=${SQOOP_HOME}/../accumulo
## fi
##fi
## Moved to be a runtime check in sqoop.
##if [ ! -d "${HCAT_HOME}" ]; then
## echo "Warning: $HCAT_HOME does not exist! HCatalog jobs will fail."
## echo 'Please set $HCAT_HOME to the root of your HCatalog installation.'
##fi
##if [ ! -d "${ACCUMULO_HOME}" ]; then
## echo "Warning: $ACCUMULO_HOME does not exist! Accumulo imports will fail."
## echo 'Please set $ACCUMULO_HOME to the root of your Accumulo installation.'
##fi
##export HCAT_HOME
##export ACCUMULO_HOME
//验证
sqoop version
//验证sqoop和数据库连接
sqoop list-databases -connect jdbc:mysql://shsxt-hadoop101:3306/ -username root -password 123456
Hive和HBase的整合
hive和hbase同步https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration
- 将HBase中的数据映射到Hive中
- 因为都是存储在HDFS上
- 所以Hive建表的时候可以指定HBase的数据存储路径
- 但是如果删除Hive表,并不会删除Hbase
- 反过来说,删除HBase,那么Hive的数据就会被删除
//丢jar包,和配置集群信息,建表的时候指定是HBase映射的数据
cp /opt/sxt/apache-hive-1.2.1-bin/lib/hive-hbase-handler-1.2.1.jar /opt/sxt/hbase-1.4.13/lib/
//检查jar是否已经上传成功(三台节点)
ls /opt/sxt/hbase-1.4.13/lib/hive-hbase-handler-*
//在hive的配置文件增加属性:
vim /opt/sxt/apache-hive-1.2.1-bin/conf/hive-site.xml
//新增:(三台节点都新增)
<property>
<name>hbase.zookeeper.quorum</name>
<value>shsxt-hadoop101:2181,shsxt-hadoop102:2181,shsxt-hadoop103:2181</value>
</property>
//验证
//先在hive中创建临时表,再查询这张表
CREATE EXTERNAL TABLE brower1 (
`id` string,
`name` string,
`version` string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = "info:browser,info:browser_v")
TBLPROPERTIES ("hbase.table.name" = "event");
CREATE EXTERNAL TABLE tmp_order (
`key` string,
`name` string,
`age` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties('hbase.columns.mapping'=':key,info:u_ud,info:u_sd')
tblproperties('hbase.table.name'='event');
Hive on Tez (单节点)
1.将apache-tez-0.8.5-bin/share目录下的压缩包部署至HDFS上
cd /opt/bdp/
rz
tar -zxvf apache-tez-0.8.5-bin.tar.gz
rm -rf apache-tez-0.8.5-bin.tar.gz
cd apache-tez-0.8.5-bin/share/
hadoop fs -mkdir -p /bdp/tez/
hadoop fs -put tez.tar.gz /bdp/tez/
hadoop fs -chmod -R 777 /bdp
hadoop fs -ls /bdp/tez/
2.在{HIVE_HOME}/conf目录下创建tez-site.xml文件,内容如下:
cd /opt/bdp/apache-hive-1.2.1-bin/conf/
vim tez-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>/bdp/tez/tez.tar.gz</value>
</property>
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.2</value>
</property>
</configuration>
注意:tez.lib.uris配置的路径为上一步tez.tar.gz压缩包部署的HDFS路径。同样tez-site.xml文件需要拷贝至HiveServer2和HiveMetastore服务所在节点的相应目录下。
3.将apache-tez-0.8.5-bin/share目录下的tez.tar.gz压缩包解压当前lib目录下
cd /opt/bdp/apache-tez-0.8.5-bin/share/
ll
mkdir lib
tar -zxvf tez.tar.gz -C lib/
4.将lib和lib/lib目录下的所有jar包拷贝至{HIVE_HOME}/lib目录下
cd lib
pwd
scp -r *.jar /opt/bdp/apache-hive-1.2.1-bin/lib/
scp -r lib/*.jar /opt/bdp/apache-hive-1.2.1-bin/lib/
ll /opt/bdp/apache-hive-1.2.1-bin/lib/tez-*
注意:Tez的依赖包需要拷贝至HiveServer2和HiveMetastore服务所在节点的相应目录下。
5.完成如上操作后,重启HiveServer和HiveMetastore服务
nohup hive --service metastore > /dev/null 2>&1 &
nohup hiveserver2 > /dev/null 2>&1 &
netstat -apn |grep 10000
netstat -apn |grep 9083
Hive2 On Tez测试:使用hive命令测试
hive
set hive.tez.container.size=3020;
set hive.execution.engine=tez;
use bdp;
select count(*) from test;
Oozie搭建
部署Hadoop(CDH版本的)
-
修改Hadoop配置
core-site.xml
<!-- Oozie Server的Hostname --> <property> <name>hadoop.proxyuser.atguigu.hosts</name> <value>*</value> </property> <!-- 允许被Oozie代理的用户组 --> <property> <name>hadoop.proxyuser.atguigu.groups</name> <value>*</value> </property>mapred-site.xml
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 --> <property> <name>mapreduce.jobhistory.address</name> <value>shsxt_hadoop102:10020</value> </property> <!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>shsxt_hadoop102:19888</value> </property>yarn-site.xml
<!-- 任务历史服务 --> <property> <name>yarn.log.server.url</name> <value>http://shsxt_hadoop102:19888/jobhistory/logs/</value> </property>
完成后记得scp同步到其他机器节点
- 重启Hadoop集群
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
注意:需要开启JobHistoryServer, 最好执行一个MR任务进行测试。
部署Oozie
- 解压Oozie
tar -zxvf /opt/sxt/cdh/oozie-4.0.0-cdh5.3.6.tar.gz -C ./
- 在oozie根目录下解压oozie-hadooplibs-4.0.0-cdh5.3.6.tar.gz
tar -zxvf oozie-hadooplibs-4.0.0-cdh5.3.6.tar.gz -C ../
完成后Oozie目录下会出现hadooplibs目录。
- 在Oozie目录下创建libext目录
mkdir libext/
-
拷贝依赖的Jar包
- 将hadooplibs里面的jar包,拷贝到libext目录下:
cp -ra hadooplibs/hadooplib-2.5.0-cdh5.3.6.oozie-4.0.0-cdh5.3.6/* libext/- 拷贝Mysql驱动包到libext目录下:
cp -a /root/mysql-connector-java-5.1.27-bin.jar ./libext/ -
将ext-2.2.zip拷贝到libext/目录下
ext是一个js框架,用于展示oozie前端页面:
cp -a /root/ext-2.2.zip libext/ -
修改Oozie配置文件
oozie-site.xml
属性:oozie.service.JPAService.jdbc.driver
属性值:com.mysql.jdbc.Driver
解释:JDBC的驱动
属性:oozie.service.JPAService.jdbc.url
属性值:jdbc:mysql://shsxt_hadoop101:3306/oozie
解释:oozie所需的数据库地址
属性:oozie.service.JPAService.jdbc.username
属性值:root
解释:数据库用户名
属性:oozie.service.JPAService.jdbc.password
属性值:123456
解释:数据库密码
属性:oozie.service.HadoopAccessorService.hadoop.configurations
属性值:*=/opt/sxt/cdh/hadoop-2.5.0-cdh5.3.6/etc/hadoop
解释:让Oozie引用Hadoop的配置文件
-
在Mysql中创建Oozie的数据库
进入Mysql并创建oozie数据库:
mysql -uroot -p000000 create database oozie; grant all on *.* to root@'%' identified by '123456'; flush privileges; exit; -
初始化Oozie
1) 上传Oozie目录下的yarn.tar.gz文件到HDFS:
提示:yarn.tar.gz文件会自行解压
bin/oozie-setup.sh sharelib create -fs hdfs://shsxt_hadoop102:8020 -locallib oozie-sharelib-4.0.0-cdh5.3.6-yarn.tar.gz执行成功之后,去50070检查对应目录有没有文件生成。
2) 创建oozie.sql文件
bin/ooziedb.sh create -sqlfile oozie.sql -run3) 打包项目,生成war包
bin/oozie-setup.sh prepare-war -
Oozie的启动与关闭
启动命令如下:
bin/oozied.sh start关闭命令如下:
bin/oozied.sh stop -
访问Oozie的Web页面
http://shsxt_hadoop102:11000/oozie
项目实现
系统环境:
| 系统 | 版本 |
|---|---|
| windows | 10 专业版 |
| linux | CentOS 7 |
开发工具:
| 工具 | 版本 |
|---|---|
| idea | 2019.2.4 |
| maven | 3.6.2 |
| JDK | 1.8+ |
集群环境:
| 框架 | 版本 |
|---|---|
| hadoop | 2.6.5 |
| zookeeper | 3.4.10 |
| hbase | 1.3.1 |
| flume | 1.6.0 |
| sqoop | 1.4.6 |
硬件环境:
| 硬件 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 内存 | 1G | 1G | 1G |
| CPU | 2核 | 1核 | 1核 |
| 硬盘 | 50G | 50G | 50G |
数据生产
数据结构
我们将在HBase中采用在rowkey中包含时间戳的方式来进行;hbase列簇采用log来标示列簇。所以最终我们创建一个单列簇的rowkey包含时间戳的eventlog表。create ‘eventlog’, ‘log’
rowkey设计规则为:timestamp+(uid+mid+en)crc编码
| 列名 | 解释 | 距离 |
|---|---|---|
| browser | 浏览器名称 | 360 |
| browser_v | 浏览器版本 | 3 |
| city | 城市 | 贵阳市 |
| country | 国家 | 中国 |
| en | 事件名称 | e_l |
| os | 操作系统 | linux |
| os_v | 操作系统版本 | 1 |
| p_url | 当前页面的url | http://www.tmall.com |
| pl | 平台 | website |
| province | 省市 | 贵州省 |
| s_time | 系统时间 | 1595605873000 |
| u_sd | 会话id | 12344F83-6357-4A64-8527-F09216974234 |
| u_ud | 用户id | 26866661 |
编写代码
创建新的maven项目:shsxt_ecshop
- pom文件配置(需要自定义打包的名称和使用的技术版本,下边的是必填的):
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.2.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.xxxx</groupId>
<artifactId>bigdatalog</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>bigdatalog</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
文章篇幅太长、超出字数限制、所以只发出三分之一!需要阅读完整版的文章请私信我、发送给你哦!
文章转载自乐字节















 1534
1534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









