







文章目录
一、CSS Selector 语法选择元素原理
HTML中经常要为某些元素指定显示效果,比如前景文字颜色是红色, 背景颜色是黑色, 字体是微软雅黑等。
那么CSS必须告诉浏览器:要选择哪些元素 , 来使用这样的显示风格。
比如 ,下图中,为什么狮子老虎山羊会显示为红色呢?

因为红色框里面用css 样式,指定了class 值为animal的元素,要显示为红色。
其中红色框里面的 .animal 就是 CSS Selector ,或者说 CSS 选择器。
CSS Selector 语法就是用来选择元素的。
既然 CSS Selector 语法就是浏览器用来选择元素的,selenium自然就可以使用它用在自动化中,去选择要操作的元素了。
只要 CSS Selector 的语法是正确的, Selenium 就可以选择到该元素。
通过 CSS Selector 选择单个元素的方法是
find_element_by_css_selector(CSS Selector参数)
选择所有元素的方法是
find_elements_by_css_selector(CSS Selector参数)
二、根据 tag名、id、class 选择元素
CSS Selector 同样可以根据tag名、id 属性和 class属性 来 选择元素,
2.1 根据 tag名 选择元素
根据 tag名选择元素的 CSS Selector 语法非常简单,直接写上tag名即可,
比如 要选择所有的tag名为div的元素,就可以是这样
elements = wd.find_elements_by_css_selector('div')
等价于
elements = wd.find_elements_by_tag_name('div')
2.2 根据id属性选择元素
根据id属性 选择元素的语法是在id号前面加上一个井号:#id值
有下面这样的元素:
<input type="text" id='searchtext' />
就可以使用#searchtext 这样的 CSS Selector 来选择它。
比如,我们想在 id 为 searchtext 的输入框中输入文本 “你好” ,完整的Python代码如下
from selenium import webdriver
wd = webdriver.Chrome()
wd.get('http://cdn1.python3.vip/files/selenium/sample1.html')
element = wd.find_element_by_css_selector('#searchtext')
element.send_keys('你好')
2.3 根据class属性选择元素
根据class属性选择元素的语法是在 class 值 前面加上一个点:.class值
可点击该网址测试
要选择所有 class 属性值为 animal的元素 动物 除了这样写
elements = wd.find_elements_by_class_name('animal')
还可以这样写
elements = wd.find_elements_by_css_selector('.animal')
因为是选择 所有符合条件的 ,所以用 find_elements 而不是 find_element
三、选择子元素和后代元素
HTML中, 元素 部可以 包含其他元素, 比如 下面的 HTML片段
<div id='layer1'>
<div id='inner11'>
<span>内层11</span>
</div>
<div id='inner12'>
<span>内层12</span>
</div>
</div>
<div id='layer2'>
<div id='inner21'>
<span>内层21</span>
</div>
</div>
id 为 container 的div元素 包含了 id 为 layer1 和 layer2 的两个div元素。
这种包含是直接包含, 中间没有其他的层次的元素了。 所以 id 为 layer1 和 layer2 的两个div元素 是 id 为 container 的div元素 的 直接子元素
而 id 为 layer1 的div元素 又包含了 id 为 inner11 和 inner12 的两个div元素。 中间没有其他层次的元素,所以这种包含关系也是 直接子元素关系
id 为 layer2 的div元素 又包含了 id 为 inner21 这个div元素。 这种包含关系也是 直接子元素关系
而对于 id 为 container 的div元素来说, id 为 inner11 、inner12 、inner22 的元素 和 两个 span类型的元素都不是它的直接子元素, 因为中间隔了几层。
虽然不是直接子元素, 但是 它们还是在 container 的内部, 可以称之为它 的后代元素
后代元素也包括了直接子元素, 比如 id 为 layer1 和 layer2 的两个div元素 也可以说 是 id 为 container 的div元素 的直接子元素,同时也是后代子元素
如果 元素2 是 元素1 的 直接子元素, CSS Selector 选择子元素的语法是这样的
元素1 > 元素2
中间用一个大于号 (我们可以理解为箭头号)
注意,最终选择的元素是 元素2, 并且要求这个 元素2 是元素1 的直接子元素
也支持更多层级的选择, 比如
元素1 > 元素2 > 元素3 > 元素4
就是选择 元素1 里面的子元素 元素2 里面的子元素 元素3 里面的子元素 元素4 , 最终选择的元素是 元素4
测试一下#container>#layer1:
from selenium import webdriver
driver=webdriver.Chrome()
driver.implicitly_wait(5)
driver.get("http://cdn1.python3.vip/files/selenium/sample1.html")
elements=driver.find_elements_by_css_selector('#container>#layer1')
for element in elements:
print("--------------");
print(element.get_attribute("outerHTML"))
最终选择的是layer1部分的内容
--------------
<div id="layer1">
<div id="inner11">
<span>内层11</span>
</div>
<div id="inner12">
<span>内层12</span>
</div>
</div>
Process finished with exit code 0
如果 元素2 是 元素1 的 后代元素, CSS Selector 选择后代元素的语法是这样的
元素1 元素2
中间是一个或者多个空格隔开
最终选择的元素是 元素2 ,并且要求这个 元素2 是 元素1 的后代元素。
也支持更多层级的选择, 比如
元素1 元素2 元素3 元素4
最终选择的元素是 元素4
测试一下#container #inner11:
from selenium import webdriver
driver=webdriver.Chrome()
driver.implicitly_wait(5)
driver.get("http://cdn1.python3.vip/files/selenium/sample1.html")
elements=driver.find_elements_by_css_selector('#container #inner11')
for element in elements:
print("--------------");
print(element.get_attribute("outerHTML"))
最终选择inner11的内容
--------------
<div id="inner11">
<span>内层11</span>
</div>
Process finished with exit code 0
四、根据属性选择
id、class 都是web元素的 属性,因为它们是很常用的属性,所以css选择器专门提供了根据 id、class 选择的语法。
那么其他的属性呢?
比如
<a href="http://www.miitbeian.gov.cn">苏ICP备88885574号</a>
里面根据 href选择,用css 选择器应该怎么选呢?
css 选择器支持通过任何属性来选择元素,语法是用一个方括号[]。
比如要选择上面的a元素,就可以使用 [href="http://www.miitbeian.gov.cn"]。
这个表达式的意思是,选择属性href值为 http://www.miitbeian.gov.cn 的元素。
完整代码如下
from selenium import webdriver
wd = webdriver.Chrome()
wd.get('http://cdn1.python3.vip/files/selenium/sample1.html')
# 根据属性选择元素
element = wd.find_element_by_css_selector('[href="http://www.miitbeian.gov.cn"]')
# 打印出元素对应的html
print(element.get_attribute('outerHTML'))
当然,前面可以加上标签名的限制,比如 div[class=‘SKnet’] 表示 选择所有标签名为div,且class属性值为SKnet的元素。
属性值用单引号,双引号都可以。
根据属性选择,还可以不指定属性值,比如 [href] , 表示选择所有具有属性名 为href 的元素,不管它们的值是什么。
CSS 还可以选择 属性值 包含 某个字符串 的元素
比如, 要选择a节点,里面的href属性包含了 miitbeian 字符串,就可以这样写
a[href*="miitbeian"]
还可以 选择 属性值 以某个字符串 开头 的元素
比如, 要选择a节点,里面的href属性以 http 开头 ,就可以这样写a[href^="http"]
还可以 选择属性值以某个字符串结尾 的元素
比如, 要选择a节点,里面的href属性以 gov.cn 结尾 ,就可以这样写a[href$="gov.cn"]
如果一个元素具有多个属性
<div class="misc" ctype="gun">沙漠之鹰</div>
CSS 选择器可以指定 择的元素要同时具有多个属性的限制,像这样 div[class=misc][ctype=gun]
五、验证 CSS Selector
那么我们怎么验证 CSS Selector 的语法是否正确选择了我们要选择的元素呢?
可以像下面这样,写出Python代码,运行看看,能否操作成功
element = wd.find_element_by_css_selector('#searchtext')
element.input('输入的文本')
如果成功,说明选择元素的语法是正确的。
但是这样做的问题就是:太麻烦了。
当我们进行自动化开发的时候,有大量选择元素的语句,都要这样一个个的验证,就非常耗时间。
由于 CSS Selector 是浏览器直接支持的,可以在浏览器 开发者工具栏中验证。
比如我们使用Chrome浏览器打开 http://cdn1.python3.vip/files/selenium/sample1.html
打开 开发者工具栏
如果我们要验证 下面的表达式.footer1 span
能否选中 这个元素
<span class="copyright">版权</span>
<span class="date">发布日期:2018-03-03</span>
可以这样做:
点击 Elements 标签后, 同时按 Ctrl 键 和 F 键, 就会出现下图箭头处的搜索框
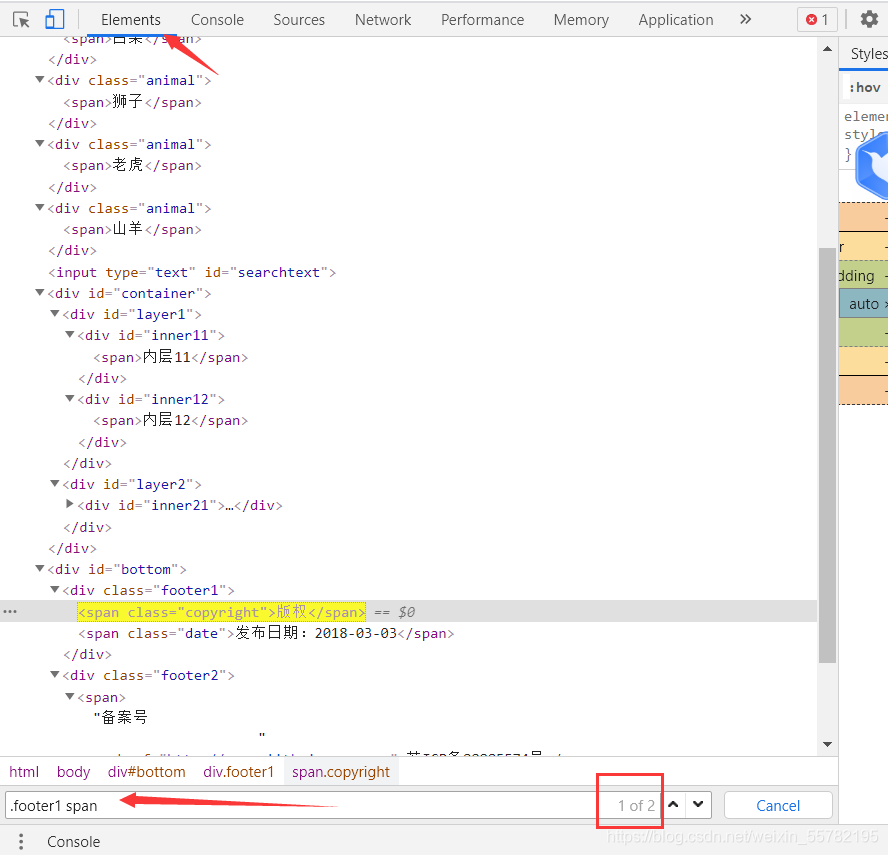
我们可以在里面输入任何 CSS Selector 表达式 ,如果能选择到元素, 右边的的红色方框里面就会显示出类似1 of 2 这样的内容。
of 后面的数字表示这样的表达式总共选择到几个元素
of 前面的数字表示当前黄色高亮显示的是其中第几个元素
上图中的 1of2就是指 : CSS 选择语法 .footer1 span
在当前网页上共选择到 2个元素, 目前高亮显示的是第1个。
六、选择语法联合使用
CSS selector的另一个强大之处在于: 选择语法可以联合使用
请点击打开该网址
比如, 我们要选择 网页 html 中的元素<span class='copyright'>版权</span>
<div id='bottom'>
<div class='footer1'>
<span class='copyright'>版权</span>
<span class='date'>发布日期:2018-03-03</span>
</div>
<div class='footer2'>
<span>备案号
<a href="http://www.miitbeian.gov.cn">苏ICP备88885574号</a>
</span>
</div>
</div>
CSS selector 表达式 可以这样写:
div.footer1 > span.copyright
就是 选择 一个class 属性值为 copyright 的 span 节点, 并且要求其 必须是 class 属性值为 footer1 的 div节点 的子节点
也可以更简单:
.footer1 > .copyright
就是 选择 一个class 属性值为copyright 的节点(不限类型), 并且要求其 必须是 class 属性值为 footer1 的节点的 子节点
当然 这样也是可以的:
.footer1 .copyright
因为子元素同时也是后代元素
七、组选择
如果我们要 同时选择所有class 为 plant 和 class 为 animal 的元素。怎么办?
这种情况,css选择器可以 使用逗号 ,称之为组选择 ,像这样
.plant , .animal
再比如,我们要同时选择所有tag名为div的元素 和 id为BYHY的元素,就可以像这样写
div,#BYHY
对应的selenium代码如下
elements = wd.find_elements_by_css_selector('div,#BYHY')
for element in elements:
print(element.text)
我们再看一个例子

我们要选择所有 唐诗里面的作者和诗名, 也就是选择所有 id 为 t1 里面的 span 和 p 元素
我们不应该这样写#t1 > span,p
这样写的意思是 选择所有 id 为 t1 里面的 span 和 所有的 p 元素
只能这样写在#t1 > span , #t1 > p














 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









