






基础知识
创建正则
- 字面量创建
使用
//包裹的字面量创建方式是推荐的作法,但它不能在其中使用变量
let hd = "houdunren.com";
console.log(/u/.test(hd));//true
- 使用
eval转换为js语法来实现将变量解析到正则中
let hd = "houdunren.com";
let a = "u";
console.log(eval(`/${a}/`).test(hd)); //true
- 对象创建
当正则需要动态创建时使用对象方式
let hd = "houdunren.com";
let web = "houdunren";
let reg = new RegExp(web);
console.log(reg.test(hd)); //true
replace 替换
let a = 'abc'
console.log(a.replace('a','g')); //gbc
//正则表达式替换
console.log(a.replace(/\w/g,'@')); //@@@
根据用户输入高亮显示内容,支持用户输入正则表达式
const content = prompt("请输入要搜索的内容,支持正则表达式"); //假如填u,也可以写正则\w
const reg = new RegExp(content, "g");
let body = document
.querySelector("#content")
.innerHTML.replace(reg, str => { //第二个参数可以变量每一个符合的
return `<span style="color:red">${str}</span>`;
});
document.body.innerHTML = body; //所有字母u变为红色,如果正则\w所有字母为红色
符号
- 选择符
|这个符号带表选择修释符,也就是|左右两侧有一个匹配到就可以。
let tel = "010-12345678";
console.log((/(010|020)\-\d{7,8}/).test(tel));
[]这个符号只匹配符号里面第一个,只匹配一次
let tel = "010-12345678";
let reg = /[12345]/
console.log(tel.match(reg).join()); //1
- 字符转义
假如有这样的场景,如果我们想通过正则查找
/符号,但是/在正则中有特殊的意义。如果写成///这会造成解析错误,所以要使用转义语法/\//来匹配。
const url = "https://www.houdunren.com";
console.log(/https:\/\//.test(url)); //true
使用
RegExp构建正则时在转义上会有些区别,下面是对象与字面量定义正则时区别
let price = 12.23;
//字符串中 \d 与 d 是一样的,所以在 new RegExp 时\d 即为 d
console.log("\d" == "d");
//使用对象定义正则时,可以先把字符串打印一样,结果是字面量一样的定义就对了
console.log("\\d+\\.\\d+"); // \d+\.\d+
let reg = new RegExp("\\d+\\.\\d+");
console.log(reg.test(price)); //true
console.log(/\d+\.\d+/.test(price)); //true
- 字符边界
| 边界符 | 说明 |
|---|---|
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束,忽略换行符 |
匹配内容必须以
www开始
const hd = "www.houdunren.com";
console.log(/^www/.test(hd)); //true
匹配内容必须以
.com结束
const hd = "www.houdunren.com";
console.log(/\.com$/.test(hd)); //true
检测用户名长度为3~6位,且只能为字母。如果不使用
^与$限制将得不到正确结果,无法限制位数
let res = this.value.match(/^[a-z]{3,6}$/i);
console.log(res ? "正确" : "失败");
元子字符
字符列表
| 元字符 | 说明 | 示例 |
|---|---|---|
| \d | 匹配任意一个数字 | [0-9] |
| \D | 与除了数字以外的任何一个字符匹配 | [^0-9] |
| \w | 与任意一个英文字母,数字或下划线匹配 | [a-zA-Z_] |
| \W | 除了字母,数字或下划线外与任何字符匹配 | [^a-zA-Z_] |
| \s | 任意一个空白字符匹配,如空格,制表符\t,换行符\n | [\n\f\r\t\v] |
| \S | 除了空白符外任意一个字符匹配 | [^\n\f\r\t\v] |
| . | 匹配除换行符外的任意字符 |
使用体验
匹配任意数字
let hd = "houdunren 2010";
console.log(hd.match(/\d/g)); //["2", "0", "1", "0"]
console.log(hd.match(/\d+/g)); //['2010'] 加号匹配多个可以把匹配的链接到一起
匹配所有电话号码
let hd = `
张三:010-99999999,李四:020-88888888
`;
let res = hd.match(/\d{3}-\d{7,8}/g);
console.log(res);
获取所有用户名
let hd = `
张三:010-99999999,李四:020-88888888`;
let res = hd.match(/[^:\d-,]+/g);
console.log(res);
匹配任意非数字
console.log(/\D/.test(2029)); //false
匹配字母数字下划线
let hd = "hdcms@";
console.log(hd.match(/\w/g)); //["h", "d", "c", "m", "s"]
匹配除了字母,数字或下划线外与任何字符匹配
console.log(/\W/.test("@")); //true
匹配与任意一个空白字符匹配
console.log(/\s/.test(" ")); //true
console.log(/\s/.test("\n")); //true
匹配除了空白符外任意一个字符匹配
let hd = "hdcms@";
console.log(hd.match(/\S/g)); //["2", "0", "1", "0","@"]
如果要匹配点则需要转义
let hd = `houdunren@com`;
console.log(/houdunren.com/i.test(hd)); //true
console.log(/houdunren\.com/i.test(hd)); //false
使用
.匹配除换行符外任意字符,下面匹配不到hdcms.com因为有换行符
const url = `
https://www.houdunren.com
hdcms.com
`;
console.log(url.match(/.+/)[0]);
使用
/s视为单行模式(忽略换行)时,.可以匹配所有
let hd = `
<span>
houdunren
hdcms
</span>
`;
let res = hd.match(/<span>.*<\/span>/s);
console.log(res[0]);
正则中空格会按普通字符对待
let tel = `010 - 999999`;
console.log(/\d+-\d+/.test(tel)); //false
console.log(/\d+ - \d+/.test(tel)); //true
所有字符
可以使用
[\s\S]或[\d\D]来匹配所有字符
let hd = `
<span>
houdunren
hdcms
</span>
`;
let res = hd.match(/<span>[\s\S]+<\/span>/);
console.log(res[0]);
模式修饰
正则表达式在执行时会按他们的默认执行方式进行,但有时候默认的处理方式总不能满足我们的需求,所以可以使用模式修正符更改默认方式。可以写多个,不区分顺序
| 修饰符 | 说明 |
|---|---|
| i | 不区分大小写字母的匹配 |
| g | 全局搜索所有匹配内容 |
| m | 视为多行,一行一行对待 |
| s | 视为单行忽略换行符,使用. 可以匹配所有字符 |
| y | 从 regexp.lastIndex 开始匹配 |
| u | 正确处理四个字符的 UTF-16 编码 |
i
将所有
houdunren.com统一为小写
let hd = "houdunren.com HOUDUNREN.COM";
hd = hd.replace(/houdunren\.com/gi, "houdunren.com");
console.log(hd); //houdunren.com houdunren.com
g
使用
g修饰符可以全局操作内容
let hd = "houdunren";
hd = hd.replace(/u/, "@");
console.log(hd); // ho@dunren没有使用 g 修饰符是,只替换了第一个
let hd = "houdunren";
hd = hd.replace(/u/g, "@");
console.log(hd); //使用全局修饰符后替换了全部的 u ho@d@nren
m
用于将内容视为多行匹配,主要是对 ^和 $ 的修饰
将下面是将以
#数字开始的课程解析为对象结构,学习过后面讲到的原子组可以让代码简单些
let hd = `
#1 js,200元 #
#2 php,300元 #
#9 houdunren.com # 后盾人
#3 node.js,180元 #
`;
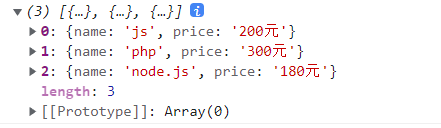
// [{name:'js',price:'200元'}]
let lessons = hd.match(/^\s*#\d+\s+.+\s+#$/gm).map(v => {
v = v.replace(/\s*#\d+\s*/, "").replace(/\s+#/, "");
[name, price] = v.split(",");
return { name, price };
});
console.log(lessons);
u
每个字符都有属性,如
L属性表示是字母,P表示标点符号,需要结合u模式才有效。其他属性简写可以访问 属性的别名 (opens new window)网站查看。
//使用\p{L}属性匹配字母
let hd = "houdunren2010.不断发布教程,加油!";
console.log(hd.match(/\p{L}+/u));
//使用\p{P}属性匹配标点
console.log(hd.match(/\p{P}+/gu));
字符也有unicode文字系统属性
Script=文字系统,下面是使用\p{sc=Han}获取中文字符han为中文系统,其他语言请查看 文字语言表(opens new window)
let hd = `
张三:010-99999999,李四:020-88888888`;
let res = hd.match(/\p{sc=Han}+/gu);
console.log(res);
使用
u模式可以正确处理四个字符的 UTF-16 字节编码
let str = "𝒳𝒴";
console.table(str.match(/[𝒳𝒴]/)); //结果为乱字符"�"
console.table(str.match(/[𝒳𝒴]/u)); //结果正确 "𝒳"
lastIndex
RegExp对象lastIndex 属性可以返回或者设置正则表达式开始匹配的位置
- 必须结合
g修饰符使用 - 对
exec方法有效 - 匹配完成时,
lastIndex会被重置为0
let hd = `后盾人不断分享视频教程,后盾人网址是 houdunren.com`;
let reg = /后盾人(.{2})/g;
reg.lastIndex = 10; //从索引10开始搜索
console.log(reg.exec(hd).join('')); //后盾人网址网址
console.log(reg.lastIndex); //17
y
我们来对比使用
y与g模式,使用g模式会一直匹配字符串
let hd = "udunren";
let reg = /u/g;
console.log(reg.exec(hd));
console.log(reg.lastIndex); //3
console.log(reg.exec(hd));
console.log(reg.lastIndex); //3
console.log(reg.exec(hd)); //null
console.log(reg.lastIndex); //0
但使用
y模式后如果从lastIndex开始匹配不成功就不继续匹配了
let hd = "udunren";
let reg = /u/y;
console.log(reg.exec(hd));
console.log(reg.lastIndex); //1
console.log(reg.exec(hd)); //null
console.log(reg.lastIndex); //0
因为使用
y模式可以在匹配不到时停止匹配,在匹配下面字符中的qq时可以提高匹配效率
let hd = `后盾人QQ群:11111111,999999999,88888888
后盾人不断分享视频教程,后盾人网址是 houdunren.com`;
let reg = /(\d+),?/y;
reg.lastIndex = 7;
let qq = []
while ((res = reg.exec(hd))) qq.push(res[1])
console.log(qq); //['11111111', '999999999', '88888888']
原子表
在一组字符中匹配某个元字符,在正则表达式中通过元字符表来完成,就是放到
[](方括号)中。
使用语法
| 原子表 | 说明 |
|---|---|
| [] | 只匹配其中的一个原子 |
| [^] | 只匹配"除了"其中字符的任意一个原子 |
| [0-9] | 匹配0-9任何一个数字 |
| [a-z] | 匹配小写a-z任何一个字母 |
| [A-Z] | 匹配大写A-Z任何一个字母 |
注意:元字符中括号里面有的字符,只有本意,没有其他正则中其他含义
实例操作
获取
0~3间的任意数字
const num = "2";
console.log(/[0-3]/.test(num)); //true
匹配
a~f间的任意字符
const hd = "e";
console.log(/[a-f]/.test(hd)); //true00
顺序为升序否则将报错
const num = "2";
console.log(/[3-0]/.test(num)); //SyntaxError
字母也要升序否则也报错
const hd = "houdunren.com";
console.log(/[f-a]/.test(hd)); //SyntaxError
获取所有用户名
let hd = `
张三:010-99999999,李四:020-88888888`;
let res = hd.match(/[^:\d-,]+/g);
console.log(res);
原子表中有些正则字符不需要转义,如果转义也是没问题的,可以理解为在原子表中
.就是小数点
let str = "(houdunren.com)+";
console.table(str.match(/[().+]/g));
//使用转义也没有问题
console.table(str.match(/[\(\)\.\+]/g));
可以使用
[\s\S]或[\d\D]匹配到所有字符包括换行符
...
const reg = /[\s\S]+/g;
...
下面是使用原子表知识删除所有标题
<body>
<p>后盾人</p>
<h1>houdunren.com</h1>
<h2>hdcms.com</h2>
</body>
<script>
const body = document.body;
const reg = /<(h[1-6])>[\s\S]*<\/\1>*/g; //*是0个或者多个,意思内容为空也删除
let content = body.innerHTML.replace(reg, "");
document.body.innerHTML = content;
</script>
原子组
- 元字符组用
()包裹
下面使用原子组匹配
h1标签,如果想匹配h2只需要把前面原子组改为h2即可。
const hd = `<h1>houdunren.com</h1>`;
console.log(/<(h1)>.+<\/\1>/.test(hd)); //true \1代表(h1)
基本使用
没有添加
g模式修正符时只匹配到第一个,匹配到的信息包含以下数据
| 变量 | 说明 |
|---|---|
| 0 | 匹配到的完整内容 |
| 1,2… | 匹配到的原子组 |
| index | 原字符串中的位置 |
| input | 原字符串 |
| groups | 命名分组 |
let hd = "houdunren.com";
console.log(hd.match(/houdun(ren)\.(com)/));
//["houdunren.com", "ren", "com", index: 0, input: "houdunren.com", groups: undefined]
下面使用原子组匹配标题元素
let hd = `
<h1>houdunren</h1>
<span>后盾人</span>
<h2>hdcms</h2>
`;
console.table(hd.match(/<(h[1-6])[\s\S]*<\/\1>/g)); // \1等于(h[1-6])
下面使用原子组匹配邮箱
let hd = "2300071698@qq.com";
let reg = /^[\w\-]+@[\w\-]+\.(com|org|cn|cc|net)$/i;
console.dir(hd.match(reg));
如果邮箱是以下格式
houdunren@hd.com.cn上面规则将无效,需要定义以下方式
let hd = `admin@houdunren.com.cn`;
let reg = /^[\w-]+@([\w-]+\.)+(org|com|cc|cn)$/; //([\w-]+\.)表示可以匹配多次hd.com.
console.log(hd.match(reg));
引用分组
\n在匹配时引用原子组,$n指在替换时使用匹配的组数据。下面将标签替换为p标签
let hd = `
<h1>houdunren</h1>
<span>后盾人</span>
<h2>hdcms</h2>
`;
let reg = /<(h[1-6])>([\s\S]*)<\/\1>/gi; // \1等于第一个括号(h[1-6])
console.log(hd.replace(reg, `<p>$2</p>`)); // $2表示第二个括号匹配的内容([\s\S]*)
如果只希望组参与匹配,便不希望返回到结果中使用
(?:处理。下面是获取所有域名的示例
let hd = `
https://www.houdunren.com
http://houdunwang.com
https://hdcms.com
`;
let arr = []
let reg = /https?:\/\/((?:\w+\.)?\w+\.(?:com|org|cn))/gi; //https? 外面没有括号表示s可有可不有
while ((v = reg.exec(hd))) {
arr.push(v[1])
}
console.log(arr); //['www.houdunren.com', 'houdunwang.com', 'hdcms.com']
重复匹配
基本使用
如果要重复匹配一些内容时我们要使用重复匹配修饰符,包括以下几种,只影响前面第一个字符。
| 符号 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
默认情况下重复选项对单个字符进行重复匹配,即不是贪婪匹配
let hd = "hdddd";
console.log(hd.match(/hd+/i)); //hddd
使用原子组后则对整个组重复匹配
let hd = "hdddd";
console.log(hd.match(/(hd)+/i)); //hd
下面是验证坐机号的正则
let hd = "010-12345678";
console.log(/0\d{2,3}-\d{7,8}/.exec(hd));
验证用户名只能为3~8位的字母或数字,并以字母开始
let state = /^[a-z][\w]{2,7}$/i.test(value);
console.log(
state ? "正确!" : "用户名只能为3~8位的字母或数字,并以字母开始"
);
验证密码必须包含大写字母并在5~10位之间,利用循环实现多个正则验证
let input = document.querySelector(`[name="password"]`);
input.addEventListener("keyup", e => {
const value = e.target.value.trim();
const regs = [/^[a-zA-Z0-9]{5,10}$/, /[A-Z]/];
let state = regs.every(v => v.test(value)); //利用循环实现多个正则验证
console.log(state ? "正确!" : "密码必须包含大写字母并在5~10位之间");
});
禁止贪婪
禁止贪婪就是取最小个数
下面是禁止贪婪的语法例子
let str = "aaa";
console.log(str.match(/a+/)); //aaa
console.log(str.match(/a+?/)); //a
console.log(str.match(/a{2,3}?/)); //aa
console.log(str.match(/a{2,}?/)); //aa
将所有span更换为
h4并描红,并在内容前加上后盾人-
<body>
<main>
<span>houdunwang</span>
<span>hdcms.com</span>
<span>houdunren.com</span>
</main>
</body>
<script>
const main = document.querySelector("main");
const reg = /<span>([\s\S]+?)<\/span>/gi;
main.innerHTML = main.innerHTML.replace(reg, (v, p1) => {
console.log(p1);
return `<h4 style="color:red">后盾人-${p1}</h4>`;
});
全局匹配
下面是使用
match全局获取页面中标签内容,但并不会返回匹配细节
<body>
<h1>houdunren.com</h1>
<h2>hdcms.com</h2>
<h1>后盾人</h1>
</body>
<script>
function elem(tag) {
const reg = new RegExp("<(" + tag + ")>.+?<\.\\1>", "g");
return document.body.innerHTML.match(reg);
}
console.table(elem("h1")); //['<h1>houdunwang</h1>', '<h1>houdunren.com</h1>']
</script>
matchAll
在新浏览器中支持使用 matchAll 操作,并返回迭代对象
需要添加
g修饰符
let str = "houdunren";
let reg = /[a-z]/ig;
for (const iterator of str.matchAll(reg)) {
console.log(iterator); //这种方法可以返回下标等待信息
}
获取标签内容
<h1>houdunwang</h1>
<span>hdcms.com</span>
<h1>houdunren.com</h1>
let reg = /<(h[1-6])>([\s\S]+?)<\/\1>/gi
const body = document.body
const hd = body.innerHTML.matchAll(reg)
let contents= []
for (const iterator of hd){
contents.push(iterator[2])
}
console.log(contents); // ['houdunwang', 'houdunren.com']
exec
使用
g模式修正符并结合exec循环操作可以获取结果和匹配细节
<body>
<h1>houdunren.com</h1>
<h2>hdcms.com</h2>
<h1>后盾人</h1>
</body>
<script>
function search(string, reg) {
const matchs = [];
while ((data = reg.exec( string))) {
matchs.push(data[2]);
}
return matchs;
}
console.log(search(document.body.innerHTML, /<(h[1-6])>([\s\S]+?)<\/\1>/gi)); // ['houdunwang', 'houdunren.com']
</script>
字符方法
search
search() 方法用于检索字符串中指定的子字符串,也可以使用正则表达式搜索,返回值为索引位置
let str = "houdunren.com";
console.log(str.search("com")); //10 找不到返回-1
使用正则表达式搜索
console.log(str.search(/\.com/i)); //9 找不到返回-1
match
直接使用字符串搜索
let str = "houdunren.com";
console.log(str.match("com"));
使用正则获取内容,下面是简单的搜索字符串
let hd = "houdunren";
let res = hd.match(/u/);
console.log(res);
console.log(res[0]); //匹配的结果 u
console.log(res['index']); //出现的位置 2
如果使用 g 修饰符时,就不会有结果的详细信息了(可以使用exec或者matchAll)
split
用于使用字符串或正则表达式分隔字符串,下面是使用字符串分隔日期
let str = "2023-02-12";
console.log(str.split("-")); //["2023", "02", "12"]
如果日期的连接符不确定,那就要使用正则操作了
let str = "2023/02-12";
console.log(str.split(/-|\//)); //["2023", "02", "12"]
replace
replace方法不仅可以执行基本字符替换,也可以进行正则替换,下面替换日期连接符
let str = "2023/02/12";
console.log(str.replace(/\//g, "-")); //2023-02-12
替换字符串可以插入下面的特殊变量名:
| 变量 | 说明 |
|---|---|
$$ | 插入一个 “$”。 |
$& | 插入匹配的子串。 |
| $` | 插入当前匹配的子串左边的内容。 |
$' | 插入当前匹配的子串右边的内容。 |
$n | 假如第一个参数是 RegExp 对象,并且 n 是个小于100的非负整数,那么插入第 n 个括号匹配的字符串。提示:索引是从1开始 |
在后盾人前后添加三个
=
let hd = "=后盾人=";
console.log(hd.replace(/后盾人/g, "$`$`$&$'$'")); //===后盾人===
把电话号用
-连接
let hd = "(010)99999999 (020)8888888";
console.log(hd.replace(/\((\d{3,4})\)(\d{7,8})/g, "$1-$2")); //010-99999999 020-8888888
把所有
教育汉字加上链接https://www.houdunren.com
<body>
在线教育是一种高效的学习方式,教育是一生的事业
</body>
<script>
const body = document.body;
body.innerHTML = body.innerHTML.replace(
/教育/g,
`<a href="https://www.houdunren.com">$&</a>`
);
</script>
为链接添加上
https,并补全www.
<body>
<main>
<a style="color:red" href="http://www.hdcms.com">
开源系统
</a>
<a id="l1" href="http://houdunren.com">后盾人</a>
<a href="http://yahoo.com">雅虎</a>
<h4>http://www.hdcms.com</h4>
</main>
</body>
<script>
const main = document.querySelector("body main");
const reg = /(<a.*href=['"])(http)(:\/\/)(www\.)?(hdcms|houdunren)/gi;
main.innerHTML = main.innerHTML.replace(reg, (v, ...args) => {
args[1] += "s";
args[3] = args[3] || "www.";
return args.splice(0, 5).join(""); //截取索引0到5的值拼接成地址
});
</script>
正则方法
test
检测输入的邮箱是否合法
<body>
<input type="text" name="email" />
</body>
<script>
let email = document.querySelector(`[name="email"]`);
email.addEventListener("keyup", e => {
console.log(/^\w+@\w+\.\w+$/.test(e.target.value));
});
</script>
exec
计算内容中后盾人出现的次数
<body>
<div class="content">
后盾人不断分享视频教程,后盾人网址是 houdunren.com
</div>
</body>
<script>
let content = document.querySelector(".content");
let reg = /(?<tag>后盾)人/g;
let num = 0;
while ((result = reg.exec(content.innerHTML))) {
num++;
}
console.log(`后盾人共出现${num}次`);
</script>
断言匹配
断言虽然写在扩号中但它不是组,所以不会在匹配结果中保存,可以将断言理解为正则中的条件。
(?<=exp)
零宽先行断言 ?=exp 匹配后面为 exp 的内容
把后面是
教程的后盾人汉字加上链接
<script>
let lessons = `
js,200元,300次
php,300.00元,100次
node.js,180元,260次
`;
let reg = /(\d+)(.00)?(?=元)/gi; //后面是元的
lessons = lessons.replace(reg, (v, ...args) => {
args[1] = args[1] || ".00";
return args.splice(0, 2).join("");
});
console.log(lessons);
</script>
(?<=exp)
零宽后行断言 ?<=exp 匹配前面为 exp 的内容
匹配前面是
houdunren的数字
let hd = "houdunren789hdcms666";
let reg = /(?<=houdunren)\d+/i;
console.log(hd.match(reg)); //789
所有超链接替换为
houdunren.com
<body>
<a href="https://baidu.com">百度</a>
<a href="https://yahoo.com">雅虎</a>
</body>
<script>
const body = document.body;
let reg = /(?<=<a.*href=(['"])).+?(?=\1)/gi;
// console.log(body.innerHTML.match(reg));
body.innerHTML = body.innerHTML.replace(reg, "https://houdunren.com");
</script>
将电话的后四位模糊处理
let users = `
向军电话: 12345678901
后盾人电话: 98745675603
`;
let reg = /(?<=\d{7})\d+\s*/g;
users = users.replace(reg, str => {
return "*".repeat(4); //repeat(4)重复4次意思
});
console.log(users); //向军电话: 1234567****后盾人电话: 9874567****
(?!exp)
零宽负向先行断言 后面不能出现 exp 指定的内容
下例为用户名中不能出现
向军
<body>
<main>
<input type="text" name="username" />
</main>
</body>
<script>
const input = document.querySelector(`[name="username"]`);
input.addEventListener("keyup", function() {
const reg = /^(?!.*向军.*)[a-z]{5,6}$/i; //?!表示不能出现
console.log(this.value.match(reg));
});
</script>
(?<!exp)
零宽负向后行断言 前面不能出现exp指定的内容
把所有不是以
https://oss.houdunren.com开始的静态资源替换为新网址
<body>
<main>
<a href="https://www.houdunren.com/1.jpg">1.jpg</a>
<a href="https://oss.houdunren.com/2.jpg">2.jpg</a>
<a href="https://cdn.houdunren.com/2.jpg">3.jpg</a>
<a href="https://houdunren.com/2.jpg">3.jpg</a>
</main>
</body>
<script>
const main = document.querySelector("main");
const reg = /https:\/\/(\w+)?(?<!oss)\..+?(?=\/)/gi;
main.innerHTML = main.innerHTML.replace(reg, v => {
console.log(v);
return "https://oss.houdunren.com";
});
</script>
宽负向先行断言** 后面不能出现 exp 指定的内容
下例为用户名中不能出现
向军
<body>
<main>
<input type="text" name="username" />
</main>
</body>
<script>
const input = document.querySelector(`[name="username"]`);
input.addEventListener("keyup", function() {
const reg = /^(?!.*向军.*)[a-z]{5,6}$/i; //?!表示不能出现
console.log(this.value.match(reg));
});
</script>
(?<!exp)
零宽负向后行断言 前面不能出现exp指定的内容
把所有不是以
https://oss.houdunren.com开始的静态资源替换为新网址
<body>
<main>
<a href="https://www.houdunren.com/1.jpg">1.jpg</a>
<a href="https://oss.houdunren.com/2.jpg">2.jpg</a>
<a href="https://cdn.houdunren.com/2.jpg">3.jpg</a>
<a href="https://houdunren.com/2.jpg">3.jpg</a>
</main>
</body>
<script>
const main = document.querySelector("main");
const reg = /https:\/\/(\w+)?(?<!oss)\..+?(?=\/)/gi;
main.innerHTML = main.innerHTML.replace(reg, v => {
console.log(v);
return "https://oss.houdunren.com";
});
</script>















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











