







SpringBoot文件切片
1. 计算文件的md5值
创建一个maven项目,导入commons-codec依赖
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.11</version>
</dependency>
代码如下:
public class EncryptDemo {
public static void main(String[] args) throws Exception {
// String str="abcd";
// String md5Str= DigestUtils.md5Hex(str);
// System.out.println("MD5-->"+md5Str);
// String sha1Str=DigestUtils.sha1Hex(str);
// System.out.println("SHA1-->"+sha1Str);
// String base64Str= Base64.encodeBase64String(str.getBytes());
// System.out.println("Base64-->"+base64Str);
// String base64DecodeStr=new String(Base64.decodeBase64(base64Str));
// System.out.println("base64解密:"+base64DecodeStr);
FileInputStream fileInputStream=new FileInputStream("D:\\root\\dhi\\dhi.pdf");
String md5Hex = DigestUtils.md5Hex(fileInputStream);
System.out.println("md5Hex:"+md5Hex);
}
}
结果如下:
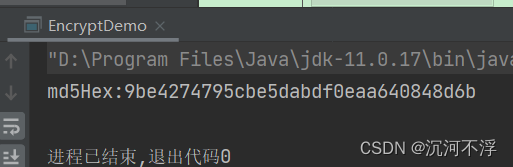
2. 创建SpringBoot项目
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.young</groupId>
<artifactId>hdfs01</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<artifactId>spring-boot-starter-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>2.7.0</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.3</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
</properties>
</project>
Hdfs01Application.java
@SpringBootApplication
public class HDFS01Application {
public static void main(String[] args) {
SpringApplication.run(HDFS01Application.class,args);
}
}
ChunkFile.java
@Data
@TableName(value = "chunk_file")
public class ChunkFile {
@TableId(type = IdType.AUTO)
private Integer id;
private String path;
private String fileName;
private String suffix;
private Integer totalSize;
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
private Integer chunkIndex;
private Integer chunkSize;
private Integer totalChunks;
private Integer identifier;
}
ChunkFileMapper.java
@Mapper
public interface ChunkFileMapper extends BaseMapper<ChunkFile> {
}
DirConfiguration.java
@Configuration
@Data
public class DirConfiguration {
@Value("${dir.source}")
private String source;
@Value("${dir.temp}")
private String temp;
@Value("${dir.target}")
private String target;
}
application.yml
spring:
datasource:
username: root
password: 3fa4d180
url: jdbc:mysql://localhost:3306/test?useSSL=false&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
dir:
source: D:\root\dhi\client\
temp: D:\root\dhi\tmp\
target: D:\root\dhi\data\
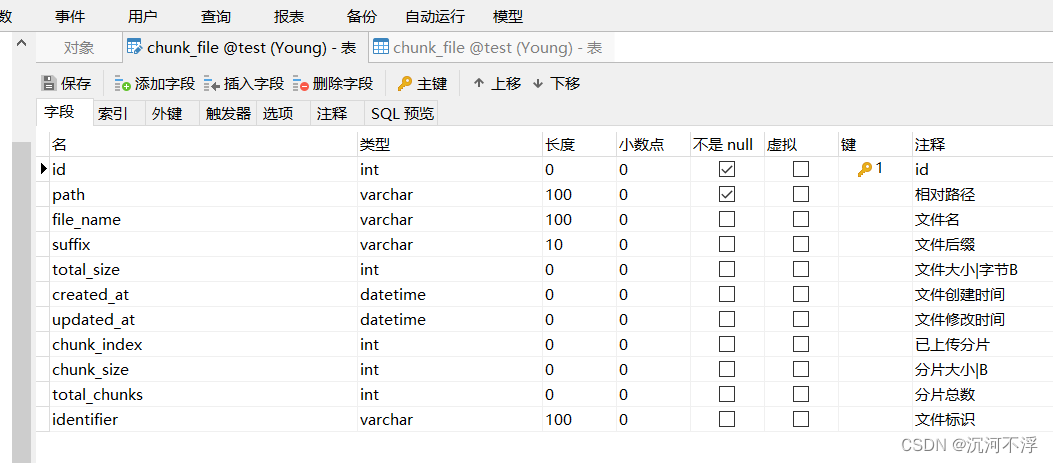
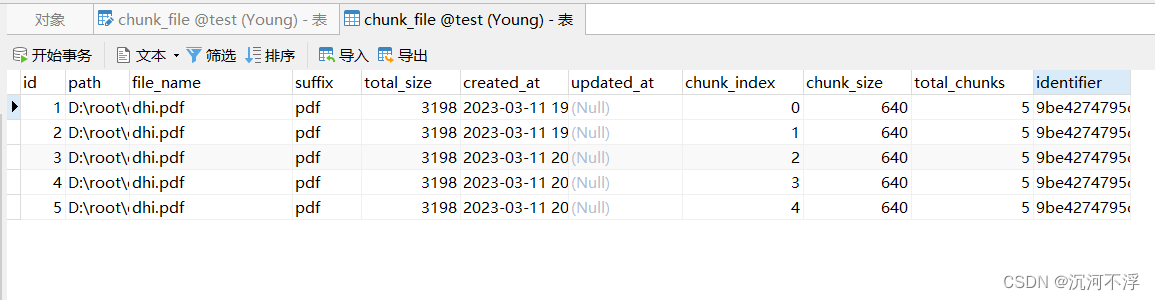
数据库表结构如下:
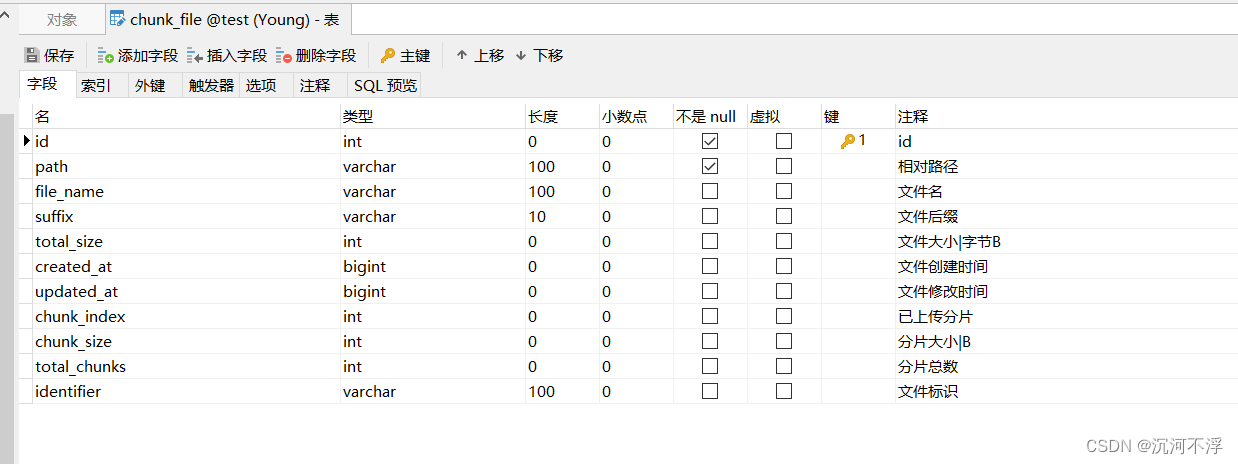
项目目录结构如下:
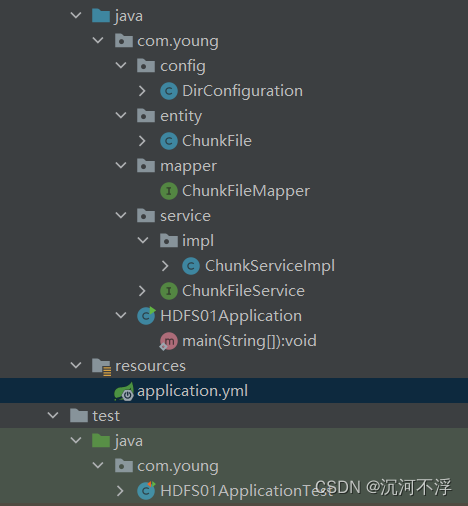
3. 对文件进行切片
在com.young.service包下,创建ChunkFileService.java
public interface ChunkFileService {
//文件分片
String splitFile(String sourceFile,String dir,String identifier,int count);
//文件合并
String getIdentifier(String filename);
}
ChunkFileServiceImpl.java
@Service
@Slf4j
public class ChunkServiceImpl implements ChunkFileService {
@Resource
private ChunkFileMapper chunkFileMapper;
@Resource
private DirConfiguration dirConfiguration;
@Override
public String splitFile(String sourceFile, String dir, String identifier,int count) {
// log.info("source:"+dirConfiguration.getSource());
// log.info("temp:"+dirConfiguration.getTemp());
// log.info("target:"+dirConfiguration.getTarget());
// return 0l;
try{
RandomAccessFile raf=new RandomAccessFile(new File(sourceFile),"r");
//计算文件大小
long length=raf.length();
//计算切片后的文件大小
long maxSize=length/count;
//偏移量
long offset=0L;
//开始切割文件
for (int i=0;i<count-1;i++){
long fbegin=offset;
long fend=(i+1)*maxSize;
//写入文件
offset=getWrite(sourceFile,dir,identifier,i,fbegin,fend);
}
//剩余部分文件写入到最后一份
if (length-offset>0){
getWrite(sourceFile,dir,identifier,count-1,offset,length);
}
}catch (Exception e){
e.printStackTrace();
return "fail";
}
return "success";
}
//获取文件md5后的值
@Override
public String getIdentifier(String filename) {
try ( FileInputStream fileInputStream=new FileInputStream(filename);
){
return DigestUtils.md5Hex(fileInputStream);
} catch (FileNotFoundException e) {
e.printStackTrace();
}catch (Exception e){
e.printStackTrace();
}
return "";
}
//写入文件,从左到右分别是文件名,目录,文件标识,索引,开始位置,结束位置
private long getWrite(String file,String dir,String identifier,int index,long begin,long end){
long endPointer=0L;
try( RandomAccessFile in=new RandomAccessFile(new File(file),"r");
RandomAccessFile out=new RandomAccessFile(new File(dir+identifier+"_"+index+".tmp"),"rw");){
byte[]b=new byte[1024];
int n=0;
in.seek(begin);
while (in.getFilePointer()<=end&&(n=in.read(b))!=-1){
out.write(b,0,n);
}
endPointer=in.getFilePointer();
}catch (Exception e){
e.printStackTrace();
}
return endPointer;
}
}
测试类
@SpringBootTest
public class HDFS01ApplicationTest {
@Resource
private ChunkFileService chunkFileService;
@Resource
private DirConfiguration dirConfiguration;
//测试分片
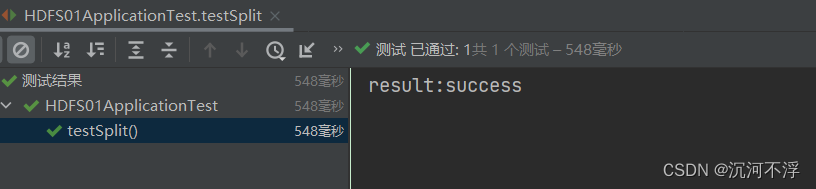
@Test
public void testSplit(){
String identifier = chunkFileService.getIdentifier("D:\\root\\dhi\\client\\dhi.pdf");
String result = chunkFileService.splitFile("D:\\root\\dhi\\client\\dhi.pdf", dirConfiguration.getSource(), identifier, 5);
System.out.println("result:"+result);
}
}
参考文章:https://blog.csdn.net/qq_45406120/article/details/121117817
4. 切片文件上传与合并
创建一个结果类接收
Result.java
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Result <T>{
private Integer code;
private String msg;
private T data;
public Result(Integer code,String msg){
this.code=code;
this.msg=msg;
}
}
ResultUtil.java
public class ResultUtil {
public static Result success(){
return new Result<>(200,"操作成功");
}
public static Result success(Object data){
return new Result<>(200,"操作成功",data);
}
public static Result fail(){
return new Result<>(400,"操作失败");
}
public static Result fail(Integer code,String msg){
return new Result<>(code,msg);
}
public static Result fail(Integer code,String msg,Object data){
return new Result<>(code,msg,data);
}
}
完整的ChunkFileService.java
public interface ChunkFileService {
//文件分片
String splitFile(String sourceFile,String dir,String identifier,int count);
//文件合并
String getIdentifier(String filename);
Result merge(String identifier);
Result verify(String identifier);
Result uploadChunk(MultipartFile file, String identifier,String fileName, String suffix, Integer chunkIndex, Integer chunkTotal, Integer chunkSize,Integer totalSize);
}
ChunkFileServiceImpl.java
@Service
@Slf4j
public class ChunkServiceImpl implements ChunkFileService {
@Resource
private ChunkFileMapper chunkFileMapper;
@Resource
private DirConfiguration dirConfiguration;
@Override
public String splitFile(String sourceFile, String dir, String identifier,int count) {
// log.info("source:"+dirConfiguration.getSource());
// log.info("temp:"+dirConfiguration.getTemp());
// log.info("target:"+dirConfiguration.getTarget());
// return 0l;
try{
RandomAccessFile raf=new RandomAccessFile(new File(sourceFile),"r");
//计算文件大小
long length=raf.length();
//计算切片后的文件大小
long maxSize=length/count;
//偏移量
long offset=0L;
//开始切割文件
for (int i=0;i<count-1;i++){
long fbegin=offset;
long fend=(i+1)*maxSize;
//写入文件
offset=getWrite(sourceFile,dir,identifier,i,fbegin,fend);
}
//剩余部分文件写入到最后一份
if (length-offset>0){
getWrite(sourceFile,dir,identifier,count-1,offset,length);
}
}catch (Exception e){
e.printStackTrace();
return "fail";
}
return "success";
}
@Override
public String getIdentifier(String filename) {
try ( FileInputStream fileInputStream=new FileInputStream(filename);
){
return DigestUtils.md5Hex(fileInputStream);
} catch (FileNotFoundException e) {
e.printStackTrace();
}catch (Exception e){
e.printStackTrace();
}
return "";
}
@Override
public Result merge(String identifier) {
LambdaQueryWrapper<ChunkFile>queryWrapper=new LambdaQueryWrapper<>();
queryWrapper.eq(ChunkFile::getIdentifier,identifier);
List<ChunkFile> chunkFiles = chunkFileMapper.selectList(queryWrapper);
if (chunkFiles==null||chunkFiles.size()==0){
return ResultUtil.fail(400,"文件不存在");
}
ChunkFile chunkFile=chunkFiles.get(0);
if (chunkFiles.size()<chunkFile.getTotalChunks()){
return ResultUtil.fail(400,"文件未上传完毕");
}
//获取临时文件的前缀,比如临时文件为123522_1.tmp,那么preTempPath就是123522
String tempPath=chunkFile.getPath();
String preTempPath = tempPath.substring(0, tempPath.lastIndexOf("_"));
String dir=dirConfiguration.getTarget()+identifier;
File targetFile=new File(dir,identifier+"."+chunkFile.getSuffix());
if (!targetFile.exists()){
targetFile.getParentFile().mkdirs();
try{
targetFile.createNewFile();
}catch (Exception e){
e.printStackTrace();
return ResultUtil.fail();
}
}
try( FileOutputStream outputStream=new FileOutputStream(targetFile);
){
FileInputStream inputStream=null;
byte[]buf=new byte[4*1024];
int len;
for (int i=0;i<chunkFiles.size();i++){
String sourceFilePath=preTempPath+"_"+i+".tmp";
inputStream=new FileInputStream(new File(sourceFilePath));
while ((len=inputStream.read(buf))!=-1){
outputStream.write(buf,0,len);
}
}
}catch (Exception e){
e.printStackTrace();
return ResultUtil.fail();
}
//删除临时文件
deleteTemp(preTempPath,chunkFiles.size());
return ResultUtil.success();
}
private void deleteTemp(String preTempPath, int size) {
ExecutorService executorService= Executors.newFixedThreadPool(4);
for (int i=0;i<size;i++){
int index=i;
executorService.execute(new Runnable() {
@Override
public void run() {
String path=preTempPath+"_"+index+".tmp";
File file=new File(path);
file.delete();
}
});
}
}
@Override
public Result verify(String identifier) {
//根据identifier获取数据库内容
LambdaQueryWrapper<ChunkFile>queryWrapper=new LambdaQueryWrapper<>();
queryWrapper.eq(ChunkFile::getIdentifier,identifier);
List<ChunkFile> chunkFiles = chunkFileMapper.selectList(queryWrapper);
Map<String,Object>res=new HashMap<>();
if (chunkFiles==null||chunkFiles.size()==0){
res.put("complete",false);
return new Result<>(101,"文件还未上传",res);
}
//获取第一个文件
ChunkFile chunkFileOne = chunkFiles.get(0);
//获取总数
Integer totalChunks = chunkFileOne.getTotalChunks();
if (chunkFiles.size()<totalChunks){
res.put("complete",false);
List<Integer> successList = chunkFiles.stream().map(chunkFile -> chunkFile.getChunkIndex())
.collect(Collectors.toList());
res.put("successList",successList);
return ResultUtil.fail(101,"文件未全部上传",res);
}
res.put("complete",true);
return ResultUtil.success(res);
}
@Override
public Result uploadChunk(MultipartFile file, String identifier,String fileName, String suffix, Integer chunkIndex, Integer chunkTotal, Integer chunkSize,Integer totalSize) {
//判断文件是否已上传过
LambdaQueryWrapper<ChunkFile>queryWrapper=new LambdaQueryWrapper<>();
queryWrapper.eq(ChunkFile::getIdentifier,identifier)
.eq(ChunkFile::getChunkIndex,chunkIndex);
ChunkFile chunkFile = chunkFileMapper.selectOne(queryWrapper);
if (chunkFile!=null){
return ResultUtil.fail(400,"文件已经上传过");
}
chunkFile=new ChunkFile();
//上传文件
//文件的目录
String dir=dirConfiguration.getTarget()+identifier+File.separator;
String path=dir+identifier+"_"+chunkIndex+".tmp";
try {
upload(file,path);
//存储文件信息到数据库
chunkFile.setPath(path);
chunkFile.setFileName(fileName);
chunkFile.setSuffix(suffix);
chunkFile.setTotalSize(totalSize);
chunkFile.setTotalChunks(chunkTotal);
chunkFile.setCreatedAt(LocalDateTime.now());
chunkFile.setChunkIndex(chunkIndex);
chunkFile.setChunkSize(chunkSize);
chunkFile.setIdentifier(identifier);
chunkFileMapper.insert(chunkFile);
} catch (IOException e) {
e.printStackTrace();
return ResultUtil.fail();
}
return ResultUtil.success();
}
private void upload(MultipartFile file, String path) throws IOException {
File targetFile=new File(path);
if (!targetFile.exists()){
targetFile.getParentFile().mkdirs();
targetFile.createNewFile();
}
FileOutputStream outputStream=new FileOutputStream(targetFile);
InputStream inputStream = file.getInputStream();
byte[]buf=new byte[1024*4];
int len;
while ((len=inputStream.read(buf))!=-1){
outputStream.write(buf,0,len);
}
if (outputStream!=null){
outputStream.close();
}
if (inputStream!=null){
inputStream.close();
}
}
private long getWrite(String file,String dir,String identifier,int index,long begin,long end){
long endPointer=0L;
try( RandomAccessFile in=new RandomAccessFile(new File(file),"r");
RandomAccessFile out=new RandomAccessFile(new File(dir+identifier+"_"+index+".tmp"),"rw");){
byte[]b=new byte[1024];
int n=0;
in.seek(begin);
while (in.getFilePointer()<=end&&(n=in.read(b))!=-1){
out.write(b,0,n);
}
endPointer=in.getFilePointer();
}catch (Exception e){
e.printStackTrace();
}
return endPointer;
}
}
ChunkFileController.java
@RestController
@Slf4j
public class ChunkFileController {
@Resource
private ChunkFileService chunkFileService;
//上传分片文件
@PostMapping(value = "/uploadChunk")
public Result uploadChunk(@RequestPart MultipartFile file,
@RequestParam(name = "identifier")String identifier,
@RequestParam(name = "fileName")String fileName,
@RequestParam(name = "suffix")String suffix,
@RequestParam(name = "index")Integer chunkIndex,
@RequestParam(name = "total")Integer chunkTotal,
@RequestParam(name = "size")Integer chunkSize,
@RequestParam(name = "totalSize")Integer totalSize){
log.info("上传分片文件==================");
return chunkFileService.uploadChunk(file,identifier,fileName,suffix,chunkIndex,chunkTotal,chunkSize,totalSize);
}
@GetMapping(value = "/verify")
public Result verify(@RequestParam(name = "identifier")String identifier){
return chunkFileService.verify(identifier);
}
@GetMapping(value = "/merge")
public Result merge(@RequestParam(name = "identifier")String identifier){
return chunkFileService.merge(identifier);
}
}
上传分片文件

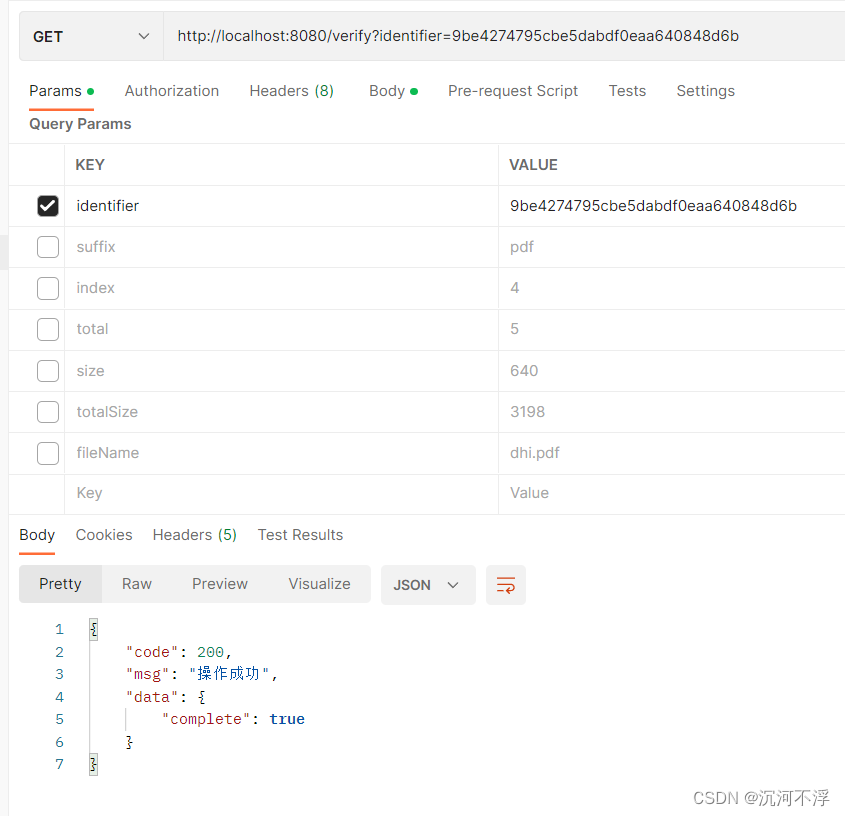
验证是否上传完成
合并文件
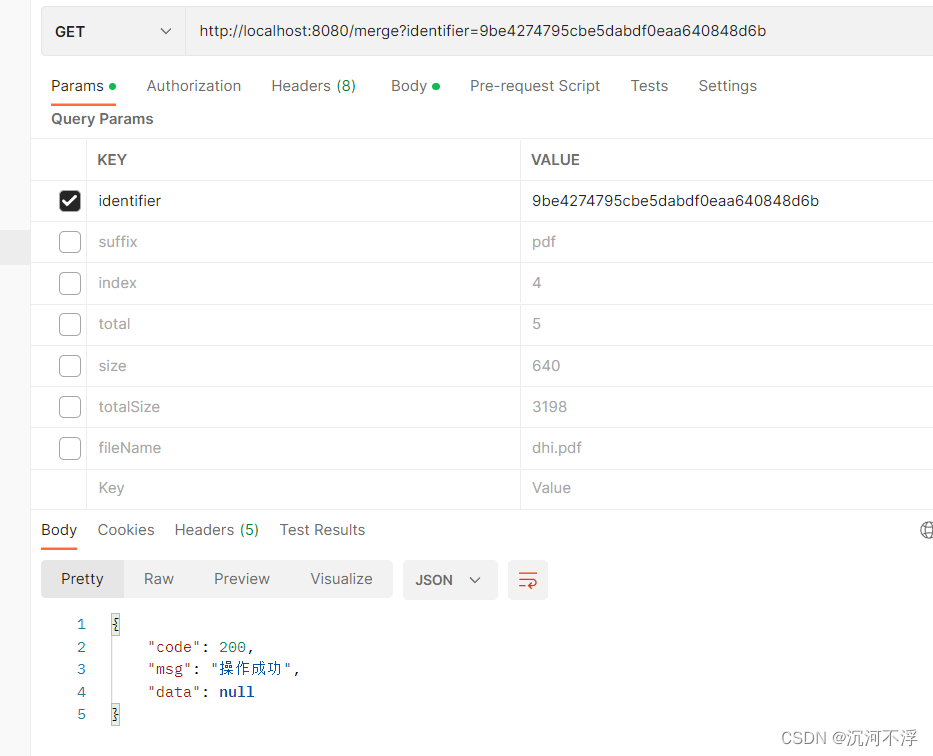
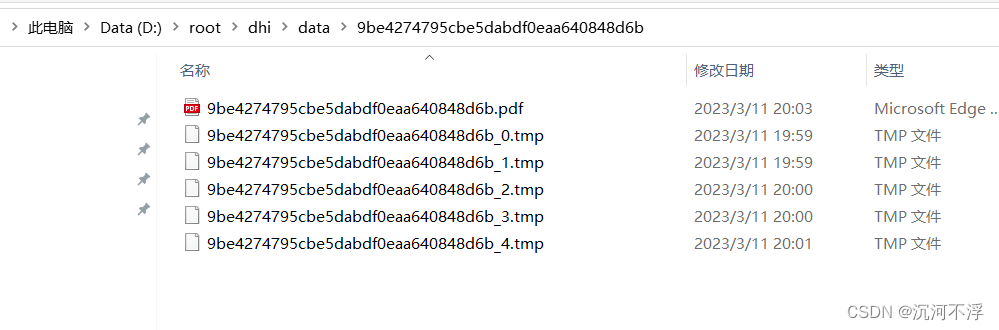
这里有点小瑕疵,临时文件没有删除
5. 小结
最近做项目时,遇到一个文件断点续传的问题,于是在本地试着做一个文件断点续传的功能,首先是将文件分片,因为我不会用微信小程序的切片组件,所以就直接在Test类中进行切片,在使用chunkService的getIdentifier()获取文件的摘要值,然后调用uploadChunk依次将分片后的文件上传,然后上传完成后,调用verify检查是否上传完成,最后调用merge进行文件合并。因为只是一个demo,所以没有讲究什么代码规范,也还没和小程序进行联调,后续联调成功后,再补充和修改demo
项目gitee: https://gitee.com/dhi-chen-xiaoyang/chunk-file-demo
参考文档:
https://developers.weixin.qq.com/miniprogram/dev/platform-capabilities/extended/component-plus/uploader.html















 1085
1085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









