







考试时间及策略
8:00 - 8:20 开题,浏览题目,都没啥思路
8:20 - 8:40 开始磕 A 题, 感觉是一道非常恶心的二分,但是看数据规模
n
≤
2000
n \leq 2000
n≤2000,又不太像二分。
8:40 - 9:10 发现了关键性质:就是优先安排能最早开始准备的分身是最优的。考虑用
s
e
t
set
set 维护三个集合并模拟这个过程,复杂度
O
(
n
2
l
o
g
2
n
)
O(n^2log_2n)
O(n2log2n),感觉复杂度是正确的,开始写。
9:10 - 9:40 码完了A题, 测了一下,过了小样例,但是没有过大样例。
9:40 - 10:00 调 A 题,但是怎么都过不了大样例,改了一下代码的逻辑,惊奇的发现过大样例了。但还是感觉是错的。感觉时间快不够了,交了一发,扔了。
10:00 - 10:10 把 C 题暴力分写了写,过样例之后扔了,等会儿再想。
10:10 - 10:53 一眼看出来背包能拿
60
p
t
s
60pts
60pts, 写了写,冲过了样例,交了没管。
10:53 - 11:20 想 D 题,但是感觉好像暴力也不会写,先弃掉了。
11:20 - 11:40 回来看 C, 但是感觉思路都是错的,无奈放弃了。
11:40 - 12:00 感觉好像想到了 D 题的神奇部分分做法,赶紧码了一下,过样例了,没测大样例,感觉要假。
考试结果
30 + 60 + 30 + 10 = 130 rk3
考试反思
A. A题写的是正解,考场上往加一句话,痛失
50
p
t
s
50pts
50pts, 还要判重,这个小细节着实没注意到。
B. B题正解是二进制优化多重背包,感觉通过 分析数据规模来反推算法 很妙。
C. 性质题,考场上没推出来,现在也不会。
D. 假了
题解
A.分身乏术

分析:挺复杂的一道题。我们看到 a i a_i ai 的值域很大,考虑二分答案。关键在于 c h e c k check check 函数。
可以把分身分成三类: 1.正在休息的 2.休息完了,但是立刻准备也不能够使新来的奶牛吃到立刻要消失的草 3.可以使新来的奶牛吃到立刻要消失的草。
很显然,我们优先让第三类分身提供草,并把它们放到第一类中,如果第三类不够再考虑使用第二类。可以用 s e t set set 维护这三个集合。细节代码中有体现
CODE:
#include<bits/stdc++.h>//乱做
using namespace std;
const int N = 2100;
typedef long long LL;
typedef pair< LL, LL > PII;
int n, tot;
LL A, B, C;//牛的波数, 提供时间, 存在时间, 休息时间
struct cow{
LL t, a;
}c[N];
bool cmp(cow a, cow b){return a.t < b.t;}
multiset< PII > rest;//存正在休息的休息结束时间
multiset< PII > offer;//存休息完了但是不能最后供草的分身的最早供草时间
multiset< PII >:: iterator itor[N];
bool check(LL x){//x只分身
rest.clear(); offer.clear();
LL num = x;//表示可以最后提供草的分身数量
for(int i = 1; i <= n; i++){//一波一波处理
PII tmp;
if(!rest.empty()) tmp = *rest.begin();
while(!rest.empty() && (tmp.first <= c[i].t)){
offer.insert(make_pair((tmp.first) + A + B, tmp.second));//插入时间和数量
rest.erase(rest.begin());
if(!rest.empty()) tmp = *rest.begin();
}
if(!offer.empty()) tmp = *offer.begin();
while(!offer.empty() && ((tmp.first) <= c[i].t)){
num += (tmp.second);
offer.erase(offer.begin());
if(!offer.empty()) tmp = *offer.begin();
}
LL cnt = c[i].a;
if(num >= cnt){//先拿能最后用的
rest.insert(make_pair(c[i].t + C - B, cnt));
num -= cnt;
}
else{//不够 考虑在offer里面补 尽量拿时间小的,也就是快消失的
cnt -= num;
rest.insert(make_pair(c[i].t + C - B, num));
num = 0; tot = 0;
for(multiset< PII >:: iterator It = offer.begin(); It != offer.end(); It++){
PII it = *It;
if(it.first - B <= c[i].t){//可以提供
if(cnt >= it.second){//比它的数量多
cnt -= it.second;
rest.insert(make_pair(it.first - B + C, it.second));
itor[++tot] = It;
}
else{
if(cnt) rest.insert(make_pair(it.first - B + C, cnt));
itor[++tot] = It;
if(it.second > cnt) offer.insert(make_pair(it.first, it.second - cnt));
cnt = 0;
break;
}
}
}
for(int j = 1; j <= tot; j++) offer.erase(itor[j]);
if(cnt) return 0;
}
}
return 1;
}
int main(){
freopen("time.in", "r", stdin);
freopen("time.out", "w", stdout);
scanf("%d%lld%lld%lld", &n, &A, &B, &C);
for(int i = 1; i <= n; i++)
scanf("%lld%lld", &c[i].t, &c[i].a);
sort(c + 1, c + n + 1, cmp);
LL l = 0, r = 2e12 + 10, mid, res = -1;
while(l <= r){
mid = (l + r >> 1);
if(check(mid)) res = mid, r = mid - 1;
else l = mid + 1;
}
cout << res << endl;
return 0;
}
B.魔法是变化之神

分析:
很巧妙的一道题。 首先对于前
50
p
t
s
50pts
50pts,我们可以把每一条边看做一个物品,物品的体积是子树大小,物品的价值是 边权 乘 子树大小 乘 (n-子树大小)。做一遍
0
/
1
0/1
0/1 背包即可,复杂度
O
(
n
m
)
O(nm)
O(nm)。
对于
n
≤
5000
,
m
=
1
0
5
n\leq5000, m = 10^5
n≤5000,m=105 而言,我们注意到了树的形态随机,树的期望高度为
l
o
g
n
log_n
logn,这也就意味着所有物品的体积和为
O
(
n
l
o
g
2
n
)
O(nlog_2n)
O(nlog2n) 级别的,所以背包的体积是一定够的。全选输出
0
0
0 即可。
正解:我们发现边权的取值只有
[
1
,
5
]
[1,5]
[1,5],如果有两个物品体积相同,价值相同,那么它们可以看做是一样的。我们想到所有物品的体积和仍然是
O
(
n
l
o
g
2
n
)
O(nlog_2n)
O(nlog2n) 级别的。那么物品体积的取值有多少种呢?答案是
O
(
n
l
o
g
2
n
)
)
O(\sqrt{nlog_2n}))
O(nlog2n))。因为显然是每种体积不重复,从
1
1
1 一直加到种类数 所得到的答案最大。因为物品的价值只与物品的体积和边权有关,所以最多有
O
(
5
∗
n
l
o
g
2
n
)
O(5* \sqrt{nlog_2n})
O(5∗nlog2n) 中不同的物品。大概是
6500
6500
6500 种,我们统计一下每一种的数量,跑一遍二进制优化多重背包即可,时间复杂度为
O
(
6500
∗
m
∗
l
o
g
2
n
)
O(6500*m*log_2n)
O(6500∗m∗log2n),但是肯定跑不满而且会少跑很多,所以可以过。
CODE:
#include<bits/stdc++.h>//考虑多重背包
using namespace std;//物品的体积和价值相等就算一种物品
const int N = 1e5 + 10;
typedef long long LL;
int n, m, u, v, head[N], tot, id[N][6], rk;//存储每种体积及边权的编号
LL siz[N], weight[N], cost[N], c[N], w, f[N], all;//物品的体积, 价值, 数量
struct edge{
int v, last;
LL w;
}E[N * 2];
void add(int u, int v, LL w){
E[++tot].v = v;
E[tot].w = w;
E[tot].last = head[u];
head[u] = tot;
}
void dfs(int x, int fa){
siz[x] = 1;
for(int i = head[x]; i; i = E[i].last){
int v = E[i].v; LL w = E[i].w;
if(v == fa) continue;
dfs(v, x);
siz[x] += siz[v];
all += (1LL * n - siz[v]) * siz[v] * w;
if(id[siz[v]][w] == 0) id[siz[v]][w] = ++rk;
weight[id[siz[v]][w]] = siz[v];//体积
cost[id[siz[v]][w]] = siz[v] * (1LL * n - siz[v]) * w;//价值
c[id[siz[v]][w]]++;//数量加1
}
}
void Get_Bag(){//二进制优化
for(int i = 1; i <= rk; i++){//物品种类
LL p = 1, r = c[i];// 2^0
while(r >= p){
r -= p;
for(int j = m; j >= p * weight[i]; j--)
f[j] = max(f[j], f[j - p * weight[i]] + p * cost[i]);
p = p * 2;
}
for(int j = m; j >= r * weight[i]; j--)
f[j] = max(f[j], f[j - r * weight[i]] + r * cost[i]);
}
LL res = 0;
for(int i = 0; i <= m; i++) res = max(res, f[i]);
cout << all - res << endl;
}
int main(){
freopen("tree.in", "r", stdin);
freopen("tree.out", "w", stdout);
scanf("%d%d", &n, &m);
for(int i = 1; i < n; i++){
scanf("%d%d%lld", &u, &v, &w);
add(u, v, w); add(v, u, w);
}
dfs(1, 0);
Get_Bag();
return 0;
}
C.合并奶牛
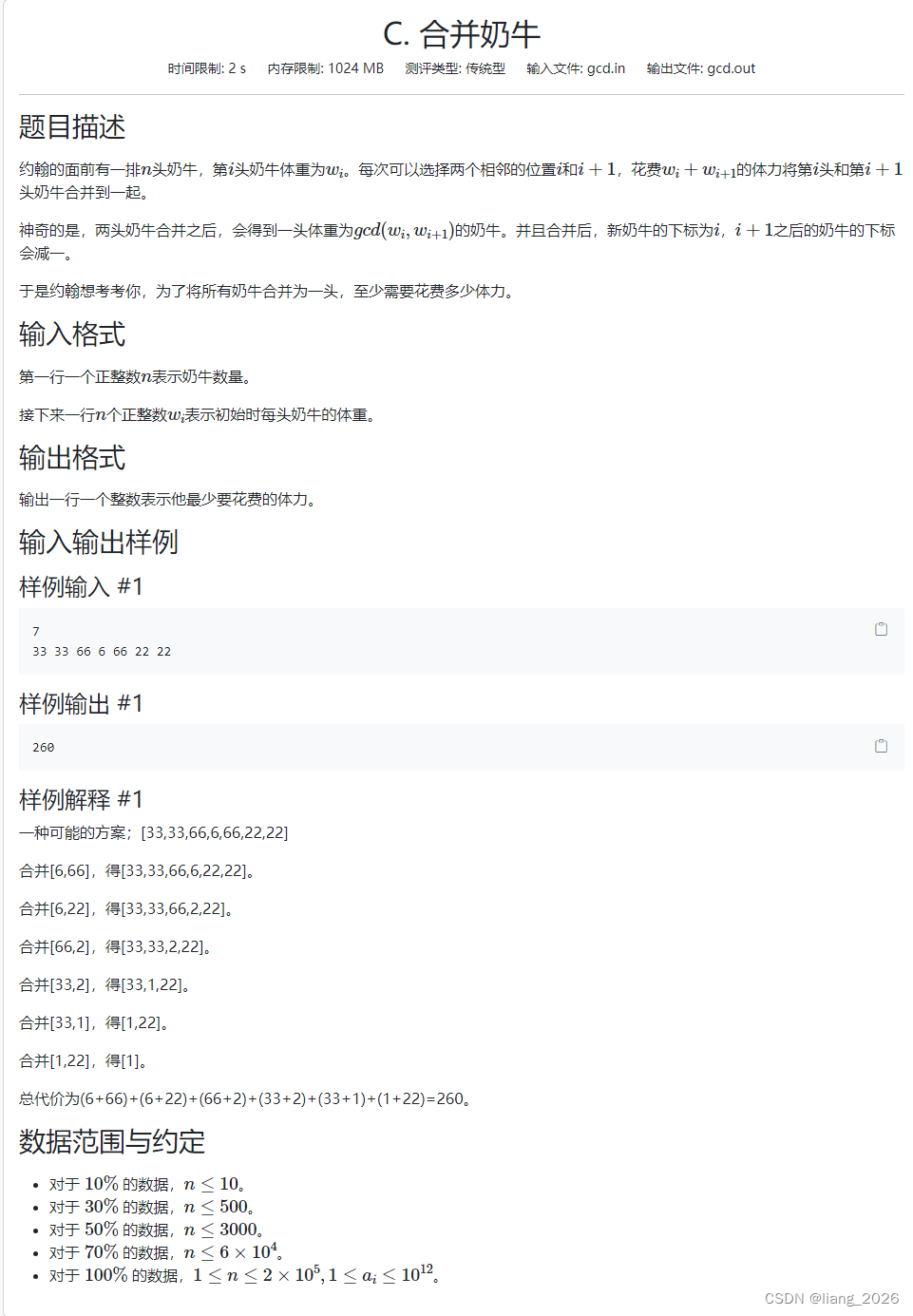
太菜了,这题正解还不太会。
D.奶牛旅行

好像是线段树分治的题,还不太会。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









