






 电商商家面临数据统计难题,通过数据分析了解客户和竞品。爬虫技术,尤其是Python爬虫,因其高效抓取大量数据成为解决方案,但需注意反爬虫机制。利用API如淘宝商品详情获取功能,可以优化运营效率,应对促销季节挑战。
电商商家面临数据统计难题,通过数据分析了解客户和竞品。爬虫技术,尤其是Python爬虫,因其高效抓取大量数据成为解决方案,但需注意反爬虫机制。利用API如淘宝商品详情获取功能,可以优化运营效率,应对促销季节挑战。
电商商家最常唠叨的就是店铺运营难做。每日多平台店铺数据统计汇总繁琐耗时,人工效率偏低,且工作内容有限。
特别是眼下“618,双十一,双十二,年底大促”将至,如何提高运营的效率和质量、保证产品及服务的良性运作,是电商企业急需解决的难题。

01
数据,电商运营重中之重
数据(以及数据分析)对于电商而言至关重要。透过海量数据,商家可以了解客户行为和喜好,也可洞察同行对手的方向与动态,所谓知己知彼。
随着市场规模的普遍增大,业务规模的快速增长,电商业务流程开始变得纷繁复杂,其所涉及的交易数据量也将持续攀升。
为了能够在激烈的市场竞争中脱颖而出,很多电商公司会设立专门的岗位与人员,及时了解广告投放、产品价格和销量数据,根据竞品的产品和营销策略进行调整。
数据部门的运营人员访问电商平台页面,人工统计商品标题、商品价格、销量等信息、并复制粘贴到表格中,大量重复操作消耗了六七成的工作时间,且数据易遗漏、难监控。
数据整理效率会直接影响电商运营的报表分析速度,所以部分商家选择爬虫工具作为数据收集的主要工具,可以一次性抓取大量数据。
02
什么是爬虫?
爬虫,一般也称作“网络蜘蛛”(Spider),以编程的方式实现(使用Python开发脚本),通过发送http请求获取cookies或者直接注入网页等方式自动获取互联网上的数据。
由于使用Python语言写脚本直接操作HTML,爬虫非常灵活和精细,抓取网页数据的速度非常之快,抓取量巨大(甚至可达到几千万上亿的数据量)。
在应用时,爬虫采用接口或暴力破解的方式解析网页内容以获取资料,采集效率高,会对后台造成巨大负担,因此也会被反爬虫机制识别、禁止。爬虫API免费测试入口
item_get-获得淘宝商品详情
公共参数
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(注册调用key请求接入api) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
请求参数
请求参数:num_iid=652874751412&is_promotion=1
参数说明:num_iid:淘宝商品ID
is_promotion:是否获取取促销价
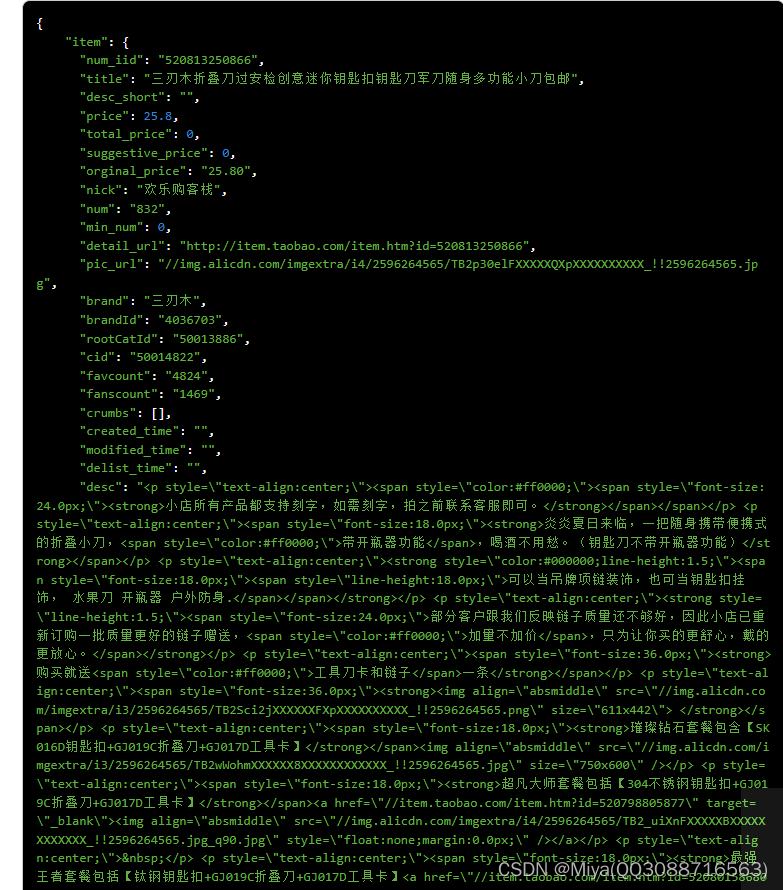
响应示例


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









