






一、问题
使用tensorflow加载数据集时出现报错:Exception: URL fetch failure on https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz: None -- [WinError 10054] 远程主机强迫关闭了一个现有的连接。
二、解决办法
1、打开tensorflow的安装路径中的mnist.py
E:\ANACINDA\envs\Tensorflow\Lib\site-packages\tensorflow_core\python\keras\datasets
2、用编辑器打开mnist.py文件,更改以下部分
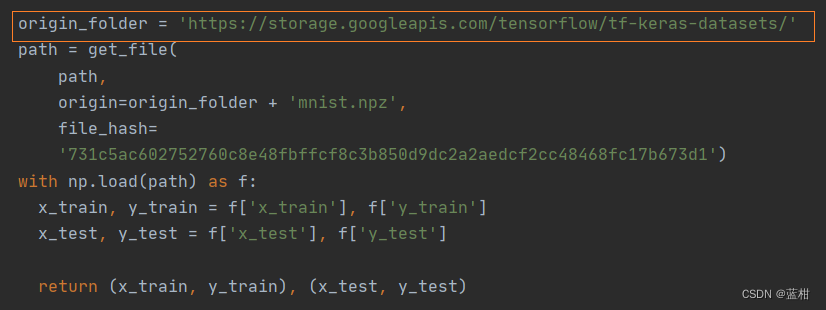
只需更改origin_folder那一行,路径在~/.keras/datasets下,其中mnist.npz文件需要自己下载(下载链接在文章结尾),将下载好的文件放到tensorflow的环境~/.keras/datasets下

修改origin_folder内容如下,注意斜杠/,更改时注意找到自己的路径
origin_folder = '/Users/某某某/.keras/datasets'
path = get_file(
path,
origin=origin_folder + 'mnist.npz',
file_hash=
'731c5ac602752760c8e48fbffcf8c3b850d9dc2a2aedcf2cc48468fc17b673d1')
with np.load(path) as f:
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
return (x_train, y_train), (x_test, y_test)3、minist.npz文件下载链接
链接: https://pan.baidu.com/s/1ZFN4Qqst14eG3KTpbUXcLg?pwd=hm62
提取码: hm62
三、通过简单代码进行测试
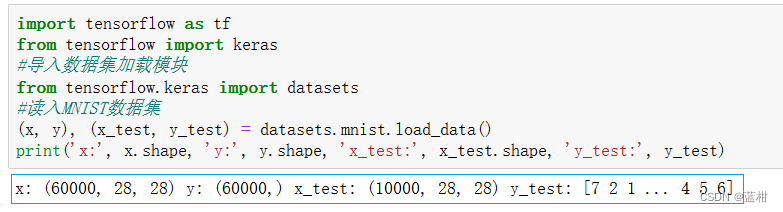
import tensorflow as tf
from tensorflow import keras
#导入数据集加载模块
from tensorflow.keras import datasets
#读入MNIST数据集
(x, y), (x_test, y_test) = datasets.mnist.load_data()
print('x:', x.shape, 'y:', y.shape, 'x_test:', x_test.shape, 'y_test:', y_test)输出结果
















 7496
7496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











