







只贴代码思路,不讲代码。部分代码取自博客并加以修改,代码都不难,可以一行一行的读懂,实现自己的目的。
一:根据图片名称,在图片库中挑选图片
思路:
1:获取图片库中所有的jpg文件名(包含路径的)
2:【图片源列表】:步骤1(列表)各项的basename,并去掉后缀(可选)。
(增强代码的复用性,例如 你要获取文件夹中的XML文件对应的同名图片,可参考我代码中注释掉的那一段)如下图,上面是步骤一的列表,下面是basename,重点:两个列表元素是一一对应的,只是一个是全路径,一个是文件名

3:【图片目标列表】按行读取txt或csv生成一个列表就行(或者类似步骤1的方式,等等)。和图片源列表格式统一(有无后缀)。代码中给了读txt和csv的方式,我的txt和csv分别是这样的:
txt:end结尾

csv:空行结尾

4:骑驴找驴,双for遍历。dir = imageList1[imgname_source.index(item1)] 这个看似难,其实不难。dir=imageList1[i] ; i=imgname_source.index(item1) ,i是item1所在的位置,由于前面的一一对应关系。说好的不讲代码的QAQ
import os
import csv
import glob
from time import sleep
from PIL import Image
#指定找到文件后,另存为的文件夹路径
outDir = os.path.abspath('G:\BaiduNetdiskDownload\泰迪杯数据挖掘大赛数据\正式数据\训练集') #输出文件夹的绝对路径
#指定第一个文件夹的位置
imageDir1 = os.path.abspath('G:\BaiduNetdiskDownload\泰迪杯数据挖掘大赛数据\正式数据\附件1')#JPEG图片库
#定义要处理的第一个文件夹变量
image_source = [] #image1指文件夹里的文件,包括文件后缀格式;
imgname_source = [] #imgname1指里面的文件名称,不包括文件后缀格式
#通过glob.glob来获取第一个文件夹下,所有'.jpg'文件
imageList1 = glob.glob(os.path.join(imageDir1, '*.jpg'))
#遍历所有文件,获取文件名称(包括后缀)
for item in imageList1:
image_source .append(os.path.basename(item))
#遍历文件名称,去除后缀,只保留名称
for item in image_source :
(temp1, temp2) = os.path.splitext(item)
imgname_source.append(temp1)
print(imgname_source)
imgname_obj_txt_path="..\wql_presonal_file\label_voc.csv"
imgname_obj_CSV_path="..\wql_presonal_file\label_voc.csv"
file='csv'
imgname_obj = []
if(file=='csv'):
with open(imgname_obj_CSV_path, 'r',encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
imgname=row[0].split('.')
imgname_obj.append(imgname[0])
csvfile.close()
# 逐行读取csv文件
if(file=='txt'):
f = open(imgname_obj_txt_path, encoding="utf-8")
while(1):
try:
line = f.readline()
line=line[0].split('.')
imgname_obj.append(line[0])
except:
break
f.close()
print(imgname_obj)
'''
#对于第二个文件夹路径,做同样的操作
imageDir2 = os.path.abspath('G:\WQL\data_Rgb\www')#新建标签组
image_obj = []
imgname_obj = []
imageList2 = glob.glob(os.path.join(imageDir2, '*.xml'))
for item in imageList2:
image_obj.append(os.path.basename(item))
for item in image_obj:
(temp1, temp2) = os.path.splitext(item)
imgname_obj.append(temp1)
'''
#拿着标签组找到图片库里选图片
for item2 in imgname_obj:
for item1 in imgname_source:
if item1 == item2:
dir = imageList1[imgname_source.index(item1)]
try:
img = Image.open(dir)
name = os.path.basename(dir)
img.save(os.path.join(outDir, name))
# print('save:',name)
except:
print("error:",item2)
continue
二 :txt或csv标注格式的数据集转成VOC的xml格式
思路:
1.需要一个函数,可以按照我的指示,生成XML标签文件,我必需要给他的参数有:图片名,图片宽高信息,类别1,类别1的budbox(左上坐标,右下坐标);类别2,类别2的budbox(左上坐标,右下坐标)。。。
2.读取csv或txt文件,获取图片名对应的图片的宽高信息,类别和标注框信息,调用函数生成XML文件
因此:写XML的代码:
'''
imgname:图片名
w,h:图片宽高,像素
objbud:(列表)标注框(5的倍数,5*(class,xmin,ymin,xmax,ymax))
xmlpath:写入路径
'''
def writeXml(imgname, w, h, objbud, xmlpath):
doc = Document()
# owner
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
# owner
folder = doc.createElement('folder')
annotation.appendChild(folder)
folder_txt = doc.createTextNode("VOC2007")
folder.appendChild(folder_txt)
filename = doc.createElement('filename')
annotation.appendChild(filename)
filename_txt = doc.createTextNode(imgname)
filename.appendChild(filename_txt)
path = doc.createElement('path')
annotation.appendChild(path)
path_txt = doc.createTextNode('/home/Images/'+imgname)
path.appendChild(path_txt)
# ones#
source = doc.createElement('source')
annotation.appendChild(source)
database = doc.createElement('database')
source.appendChild(database)
database_txt = doc.createTextNode("Unknown")
database.appendChild(database_txt)
size = doc.createElement('size')
annotation.appendChild(size)
width = doc.createElement('width')
size.appendChild(width)
width_txt = doc.createTextNode(str(w))
width.appendChild(width_txt)
height = doc.createElement('height')
size.appendChild(height)
height_txt = doc.createTextNode(str(h))
height.appendChild(height_txt)
depth = doc.createElement('depth')
size.appendChild(depth)
depth_txt = doc.createTextNode("3")
depth.appendChild(depth_txt)
# twoe#
segmented = doc.createElement('segmented')
annotation.appendChild(segmented)
segmented_txt = doc.createTextNode("0")
segmented.appendChild(segmented_txt)
shape = np.shape(objbud)
for i in range(0,int(shape[0]/5) ):
object_new = doc.createElement("object")
annotation.appendChild(object_new)
name = doc.createElement('name')
object_new.appendChild(name)
name_txt = doc.createTextNode(str(objbud[0+5*i]))
name.appendChild(name_txt)
pose = doc.createElement('pose')
object_new.appendChild(pose)
pose_txt = doc.createTextNode("Unspecified")
pose.appendChild(pose_txt)
truncated = doc.createElement('truncated')
object_new.appendChild(truncated)
truncated_txt = doc.createTextNode("0")
truncated.appendChild(truncated_txt)
difficult = doc.createElement('difficult')
object_new.appendChild(difficult)
difficult_txt = doc.createTextNode("0")
difficult.appendChild(difficult_txt)
bndbox = doc.createElement('bndbox')
object_new.appendChild(bndbox)
xmin = doc.createElement('xmin')
bndbox.appendChild(xmin)
xmin_txt = doc.createTextNode(str(objbud[1+5*i]))
xmin.appendChild(xmin_txt)
ymin = doc.createElement('ymin')
bndbox.appendChild(ymin)
ymin_txt = doc.createTextNode(str(objbud[2+5*i]))
ymin.appendChild(ymin_txt)
xmax = doc.createElement('xmax')
bndbox.appendChild(xmax)
xmax_txt = doc.createTextNode(str(objbud[3+5*i]))
xmax.appendChild(xmax_txt)
ymax = doc.createElement('ymax')
bndbox.appendChild(ymax)
ymax_txt = doc.createTextNode(str(objbud[4+5*i]))
ymax.appendChild(ymax_txt)
tempfile = xmlpath + "test.xml"
with open(tempfile, "w") as f:
f.write(doc.toprettyxml(indent='\t'))
rewrite = open(tempfile, "r")
lines = rewrite.read().split('\n')
newlines = lines[1:len(lines) - 1]
xmlwritepath=xmlpath+imgname.split('.')[0]+'.xml'
fw = open(xmlwritepath, "w")
for i in range(0, len(newlines)):
fw.write(newlines[i] + '\n')
fw.close()
rewrite.close()
os.remove(tempfile)
return我的原始标注:

因此,我生成一张图片的标注信息的代码如下:
def get_txtlabel(output='yolo_txt'):
# output ="voc_xml"or"yolo_txt"
outlabelfilename='label_wql'
if(output=='voc_xml'):
labelpath=LABELOUTPUT+outlabelfilename+'.csv'
else:
labelpath = LABELOUTPUT + outlabelfilename + '.txt'
f = open(labelpath,'w',encoding='utf-8',newline='')
csv_writer = csv.writer(f)
with open(CSVLABEL, 'r',encoding="gbk") as csvfile:
reader = csv.reader(csvfile)
rows = [row for row in reader]
shape=np.shape(rows)
i=1
while(i<(shape[0])):
#计算图片的目标数 j
j=1
try:
while(rows[i][1]==rows[i+j][1]):
j+=1
except:
pass
im = Image.open(img_path + rows[i][1])
w = int(im.size[0])
h = int(im.size[1])
label=[rows[i][1]] #imgname
if (rows[i][3] != "无"):
for same in range(0,j):
if (output == "yolo_txt"):
xmin = format(int(rows[i + same][6]) / w, '.6f')
ymin = format(int(rows[i + same][7]) / h, '.6f')
xmax = format(int(rows[i + same][8]) / w, '.6f')
ymax = format(int(rows[i + same][9]) / h, '.6f')
if (output == "voc_xml"):
xmin = format(rows[i + same][6])
ymin = format(rows[i + same][7])
xmax = format(rows[i + same][8])
ymax = format(rows[i + same][9])
label.append(rows[i + same][2]) # class
label.append(xmin ) # xmin
label.append(ymin ) # ymin
label.append(xmax ) # xmax
label.append(ymax) # ymax
else:
label.append(0) # class
label.append(0) # xmin
label.append(0) # ymin
label.append(1) # xmax
label.append(1) # ymax
if (output == 'voc_xml'):
writeXml(label[0], w,h, label[1:], xmloutpath)
csv_writer.writerow(label)
i+=j
f.close()
return代码头:
import numpy as np
import csv
from xml.dom.minidom import Document
import os
import os.path
from PIL import Image
img_path = 'G:\BaiduNetdiskDownload\泰迪杯数据挖掘大赛数据\正式数据\附件1\\'
CSVLABEL="F:\yolo3-pytorch-master\wql_presonal_file\图片虫子位置详情表.csv"
LABELOUTPUT="F:\yolo3-pytorch-master\wql_presonal_file\\"
xmloutpath = 'F:\yolo3-pytorch-master\wql_presonal_file\\'
if not os.path.exists(xmloutpath):
os.mkdir(xmloutpath)
xml:
<annotation>
<folder>VOC2007</folder>
<filename>00378.jpg</filename>
<path>/home/Images/00378.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>5472</width>
<height>3648</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>480</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>3221</xmin>
<ymin>540</ymin>
<xmax>3521</xmax>
<ymax>780</ymax>
</bndbox>
</object>
</annotation>
yololabel:

三:下载合并网页的.ts视频
思路:
1.载入M3U8文件(在线下载或下载后导入)
2.解析M3U8
3.开启并行下载
4.合并
5.删除ts碎片
谷歌:F12 --Network--筛选“m3u8”--点击打开,复制Request URL,新建txt,放到txt文件中,格式标准: line1:电影名称, line2:URL, 以此类推,可以批量下载。
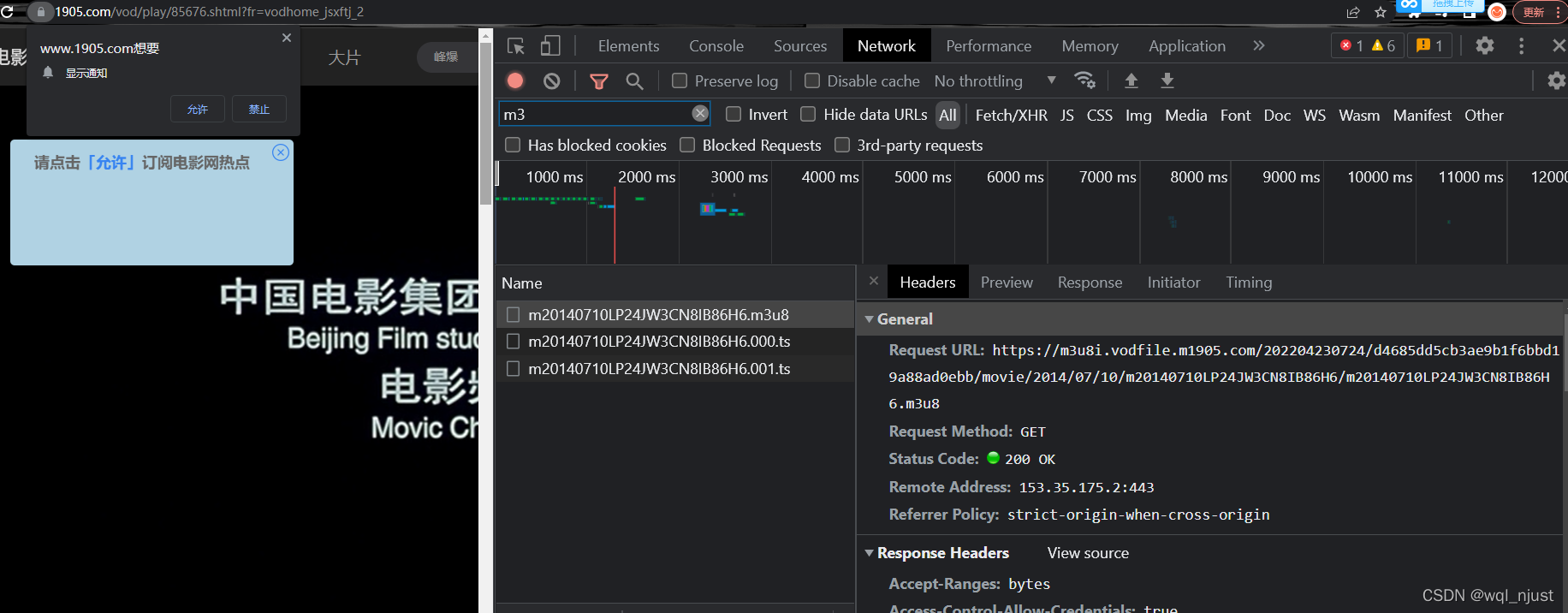
代码如下:
# -*- coding:utf-8 -*-
#!!!DONT USE VPN-SYSTEM PROXY
import logging
import os
from glob import iglob
import requests
import m3u8
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor
from natsort import natsorted
from time import sleep
class M3u8Download:
def __init__(self,m3u8_url,file_mame):
self.m3u8_url = m3u8_url
self.headers = {
'User-Agent': 'Mozilla/5.ThreadPoolExecutor0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
self.threadpool = ThreadPoolExecutor(max_workers=32)
self.file_name = file_mame
logging.basicConfig(format='[%(asctime)s][*%(levelname)s]:%(message)s',
level=logging.INFO)
def get_ts_url(self,m3u8_url):
"""
解析ts_url
:param m3u8_url:
:return:
"""
m3u8_obj = m3u8.load(m3u8_url)
# m3u8_obj = m3u8.load('') #如果m3u8自动下载不行,手动下载后在此处修改路径即可
base_uri = m3u8_obj.base_uri
logging.info('[*]get_base_uri'+base_uri)
for seg in m3u8_obj.segments:
yield urljoin(base_uri, seg.uri)
def download__ts(self, urlinfo):
"""
下载ts文件
:param urlinfo:
:return:
"""
url, ts_name = urlinfo
res = requests.get(url, headers=self.headers)
with open(ts_name, 'wb') as fp:
fp.write(res.content)
logging.info('[*download]'+ts_name)
def download_all_ts(self):
"""
下载所有函数
:return:
"""
ts_urls = self.get_ts_url(self.m3u8_url)
logging.info('[*download]download:'+self.m3u8_url)
for index, ts_url in enumerate(ts_urls):
print(ts_url)
self.threadpool.submit(self.download__ts, [ts_url, f'{index}.ts'])
self.threadpool.shutdown()
def remove_ts(self,ts_path):
"""
删除ts文件
:param ts_path:
:return:
"""
for ts in iglob(ts_path):
os.remove(ts)
logging.info('[*remove]remove all *.ts')
def run(self):
self.download_all_ts()
print("TS下载完成,准备合并")
sleep(0.5)
ts_path = '*.ts'
all_ts = iglob(ts_path)
with open(self.file_name, 'wb') as fn:
#根据ts排序
for ts in natsorted(all_ts):
#读ts写mp4
with open(ts, 'rb') as ft:
scline = ft.read()
fn.write(scline)
self.remove_ts(ts_path)
if __name__ == '__main__':
classes_path = os.path.expanduser('D:\机器学习代码\爬取视频\\121.txt')
with open(classes_path, 'r', encoding='UTF-8') as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
a = len(class_names) / 2
for i in range(int(a)):
loadpath = class_names[2 * i + 1]
filemame = class_names[2 * i] + '.mp4'
# print(loadpath)
print(filemame)
m3u8Download = M3u8Download(loadpath, filemame)
m3u8Download.run()
print("###视频总数:{}###".format(a))
print("第{}个视频下载完毕,准备下载下一个...".format(i + 1))















 3816
3816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











