







4. 第四章 串
4.1 字符串
串:又称字符串,是由零个或多个字符组成的有限序列。
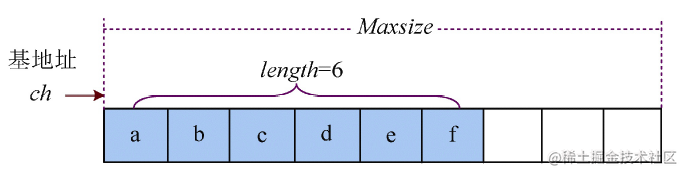
字符串通常用双引号括起来,例如S=“abcdef”,S为字符串的名字,双引号里面的内容为字符串的值。
串长:串中字符的个数,例如S的串长为6。
空串:零个字符的串,串长为0。
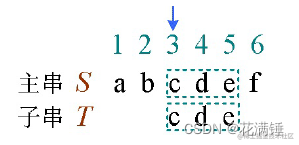
子串:串中任意个连续的字符组成的子序列,称为该串的子串,原串称为子串的主串。例如T=“cde”,T是S的子串。子串在主串中的位置,用子串的第一个字符在主串中出
现的位置表示。T在S中的位置为3,如图所示。
注意:空格也算一个字符,例如X=“abc fg”,X的串长为6。
空格串:全部由空格组成的串为空格串。
注意:空格串不是空串。
1)字符串的顺序存储
顺序存储是用一段连续的空间存储字符串。可以预先分配一个固定长度Maxsize的空间,在这个空间中存储字符串。
顺序存储又有3种方式。
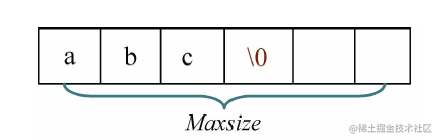
- (1)以’\0’表示字符串结束:在C、C++、Java语言中,通常用’\0’表示字符串结束,'\0’不算在字符串长度内,如图所示。
- 这样做有一个问题:如果想知道串的长度,需要从头到尾遍历一遍,如果经常需要用到串的长度,每次遍历一遍复杂性较高,因此可以考虑将字符串的长度存储起来以使用。
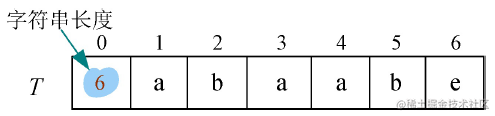
- (2)在0空间存储字符串的长度:下标为0的空间不使用,因此可以预先分配Maxsize+1的空间,在下标为0的空间中存储字符串长度,如图所示。
- (3)结构体变量存储字符串的长度
- 静态分配空间的方法
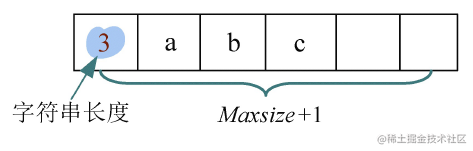
typedef struct {
char ch[Maxsize]; //字符型数组
int length; //字符串的长度
}SString;
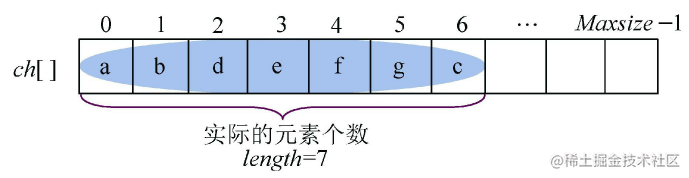
例如,字符串S=“abdefgc”,其存储结构如图所示。
这样做也有一个问题,串的运算如合并、插入、替换等操作,容易超过最大长度,出现溢出。为了解决这个问题,可以采用_动态分配空间的方法_,其结构体定义如下。
typedef struct {
char *ch; //指向字符串指针
int length; //字符串的长度
}SString;
例如,字符串S=“abcdef”,其存储结构如图4-5所示。
2)字符串的链式存储
顺序存储的串在插入和删除操作时,需要移动大量元素,因此也可以采用链表的形式存储

单链表存储字符串时,虽然插入和删除非常容易,但是这样做也有一个问题:一个节点只存储一个字符,如果需要存储的字符特别多,会浪费很多空间。因此也可以考虑一个节点存储多个字符的形式,例如一个节点存储3个字符,最后一个节点不够3个时用#代替,如图所示。

4.2 模式匹配BF算法
模式匹配:子串的定位运算称为串的模式匹配或串匹配。
假设有两个串S、T,设S为主串,也称正文串;T为子串,也称模式。在主串S中查找与模式T相匹配的子串,如果查找成功,返回匹配的子串第一个字符在主串中的位置。最笨的办法就是穷举所有S的所有子串,判断是否与T匹配,该算法称为BF(BruteForce[1])算法。
算法步骤 1)从S第1个字符开始,与T第1个字符比较,如果相等,继续比较下一个字符,否则转向下一步; 2)从S第2个字符开始,与T第1个字符比较,如果相等,继续比较下一个字符,否则转向下一步; 3)从S第3个字符开始,与T第1个字符比较,如果相等,继续比较下一个字符,否则转向下一步; …… 4)如果T比较完毕,则返回T在S中第一个字符出现的位置; 5)如果S比较完毕,则返回0,说明T在S中未出现。
完美图解
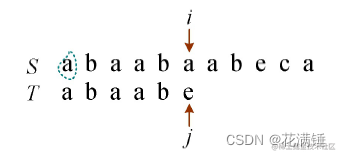
例如:S=“abaabaabeca”,T=“abaabe”,求子串T在主串S中的位置。
1)从S第1个字符开始:i=1,j=1,如图1所示。比较两个字符是否相等,如果相等,则i++,j++;如果不等,则转向下一步,如图2所示。

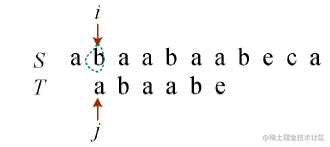
2)i回退到i−j+2的位置,j回退到1的位置,即i−j+2=6−6+2=2,即i从S第2个字符开始,j从T第1个字符开始。比较两个字符是否相等,如果相等,则i++,j++;如果不等则转向下一步,如图所示。
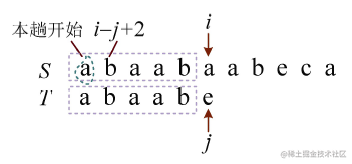
解释:为什么i要回退到i−j+2的位置呢?如果本趟开始位置是a,那么下一趟开始的位置就是a的下一个字符b的位置,这个位置正好是i−j+2,如图所示。
3)i回退到i−j+2的位置,i=2−1+2=3,即从S第3个字符开始,j=1,如图1所示。比较两个字符是否相等,如果相等,则i++,j++;如果不等,则转向下一步,如图2所示。
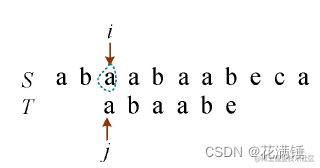
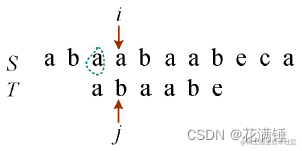
4)i回退到i−j+2的位置,i=4−2+2=4,即从S第4个字符开始,j=1,如图1所示。比较两个字符是否相等,如果相等,则i++,j++;此时T比较完了,执行下一步,如图2所示。
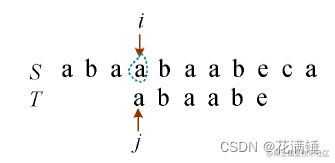
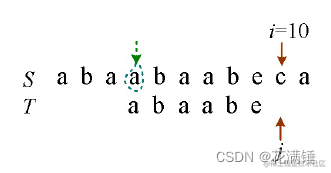
5)T比较完毕,返回子串T在主串S中第1个字符出现的位置,即i−m=10−6=4,m为T的长度。
因为串的模式匹配没有插入、合并等操作,不会发生溢出,因此可以采用第2种字符串顺序存储方法,用0空间存储字符串长度。例如,T的顺序存储方式如图所示。
算法复杂度分析 设S、T串的长度分别为n、m,则BF算法的时间复杂度分为以下两种情况。 (1)最好情况 在最好情况下,每一次匹配都在第一次比较时发现不等,如图4-17~图4-20所示。
假设第i次匹配成功,则前i−1次匹配都进行了1次比较,一共i−1次,第i次匹配成功时进行了m次比较,则总的比较次数为i−1+m。在匹配成功的情况下,最多需要n−m+1次匹配,即模式串正好在主串的最后端。假设每一次匹配成功的概率均等,概率pi =1/(n−m+1),则在最好情况下,匹配成功的平均比较次数为:
最好情况下的平均时间复杂度为O(n+m)。
(2)最坏情况 在最坏情况下,每一次匹配都比较到T的最后一个字符发现不等,回退重新开始,这样每次匹配都需要比较m次,如图4-21~图4-23所示。
假设第i次匹配成功,则前i−1次匹配都进行了m次比较,第i次匹配成功时也进行m次比较,则总的比较次数为i×m。在匹配成功的情况下,最多需要n−m+1次匹配,即模式串正好在主串的最后端。假设每一次匹配成功的概率均等,概率pi=1/(n−m+1),则在最坏情况下,匹配成功的平均比较次数为:
最坏情况下的平均时间复杂度为O(n×m)。
4.3 模式匹配KMP算法
例如:S=“abaabaabeca”,T=“abaabe”,求子串T在主串S中的位置。
完全没必要从S的每一个字符开始穷举每一种情况
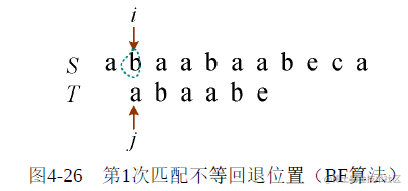
从S第1个字符开始:i=1,j=1,如图4-24所示。比较两个字符是否相等,如果相等,则i++,j++;第一次匹配不相等,如图4-25所示。

按照BF算法,如果不等,则i回退到i−j+2,j回退到1,即i=2,j=1,如图4-26所示。
其实i不用回退,让j回退到第3个位置,接着比较即可,如图4-27所示。
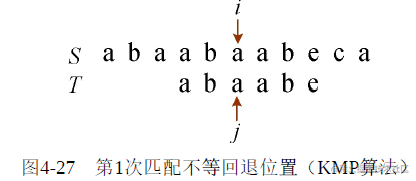
是不是像T向右滑动了一段距离? 为什么可以这样?为什么让j回退到第3个位置?而不是第2个?或第4个?
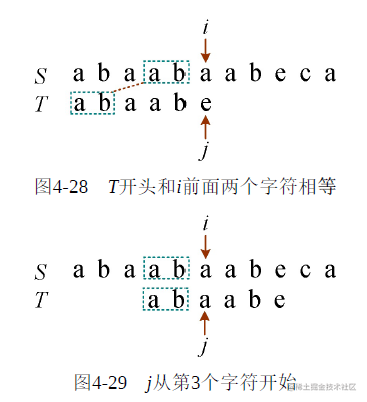
因为T串中开头的两个字符和i指向的字符前面的两个字符一模一样,如图4-28所示。这样j就可以回退到第3个位置继续比较了,因为前面两个字符已经相等了,如图4-29所
示。
那怎么知道T中开头的两个字符和i指向的字符前面的两个字符一模一样?难道还要比较?我们发现i指向的字符前面的两个字符和T中j指向的字符前面两个字符一模一样,因为它们一直相等, i++、j++才会走到当前的位置,如图4-30所示。
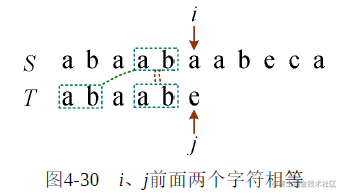
也就是说,我们不必判断开头的两个字母和i指向的字符前面的两个字符是否一样,只需要在T本身比较就可以了。假设T中当前j指向的字符前面的所有字符为T′,只需要比较T′的前缀和T′的后缀即可,如图4-31所示。
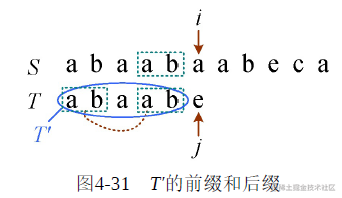
前缀后缀next[ ]
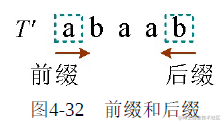
前缀是从前向后取若干个字符,后缀是从后向前取若干个字符。注意:前缀和后缀不可以取字符串本身。如果串的长度为n,前缀和后缀长度最多达到n−1,如图4-32所示。
判断T′=“abaab”的前缀和后缀是否相等,并找相等前缀后缀的最大长度。 1)长度为1:前缀“a”,后缀“b”,不等 × 2)长度为2:前缀“ab”,后缀“ab”,相等 √ 3)长度为3:前缀“aba”,后缀“aab”,不等 × 4)长度为4:前缀“abaa”,后缀“baab”,不等 ×
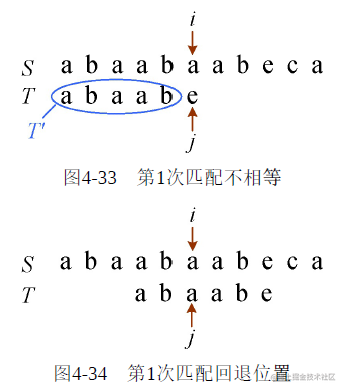
相等前缀后缀的最大长度为l=2,则j就可以回退到第l+1=3个位置继续比较了。因此,当i、j指向的字符不等时,只需要求出T′的相等前缀后缀的最大长度l,i不变,j回退到l+1的位置继续比较即可,如图4-33和图4-34所示。
现在可以写出通用公式,next[j]表示j需要回退的位置,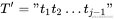 ,则:
,则:
根据公式很容易求出T=“abaabe”的next[]数组,如图4-35所示。
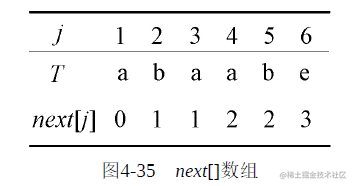
解释如下。
1)j=1:根据公式next[1]=0。
2)j=2:T′=“a”,没有前缀和后缀,next[2]=1。
3)j=3:T′=“ab”,前缀为“a”,后缀为“b”,不等,next[3]=1。
4)j=4:T′=“abc”,前缀为“a”,后缀为“a”,相等且l=1;前缀为“ab”,后缀为“ba”,
不等;因此next[4]=l+1=2。
5)j=5:T′=“abaa”,前缀为“a”,后缀为“a”,相等且l=1;前缀为“ab”,后缀为“aa”,不等;前缀为“aba”,后缀为“baa”,不等;因此next[5]=l+1=2。j=6:T′=“abaab”,前缀为“a”,后缀为“a”,相等且l=1;前缀为“ab”,后缀为“ab”,相等且l=2;前缀为“aba”,后缀为“aab”,不等;前缀为“abaa”,后缀为“baab”,不等;取最大长度2,因此next[6]=l+1=3。
可以用动态规划递推
首先大胆假设,我们已经知道了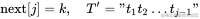 那么T′的相等前缀、后缀最大长度为k−1,如图4-36所示。
那么T′的相等前缀、后缀最大长度为k−1,如图4-36所示。
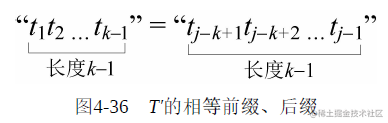
那么next[j+1]=?
考查以下两种情况。
1) :那么
:那么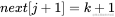 ,即相等前缀和后缀的长度比
,即相等前缀和后缀的长度比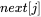 多1,如图4-37所示。
多1,如图4-37所示。

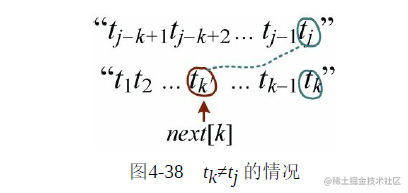
2)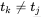 :当两者不相等时,我们又开始了这两个串的模式匹配,回退找
:当两者不相等时,我们又开始了这两个串的模式匹配,回退找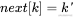 的位置,比较
的位置,比较 与
与 是否相等,如图4-38所示。
是否相等,如图4-38所示。
如果 与
与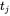 相等,则
相等,则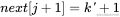 。
。
如果 与
与 不相等,则继续回退找
不相等,则继续回退找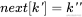 ,比较
,比较 与
与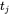 是否相等,如图4-39所示。
是否相等,如图4-39所示。
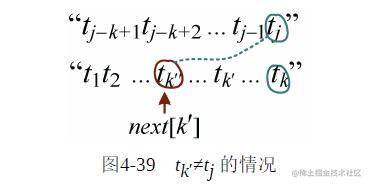
如果 与
与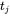 相等,则
相等,则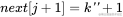 。
。
如果 与
与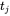 不相等,继续向前找,直到找到next[1]=0停止。
不相等,继续向前找,直到找到next[1]=0停止。
求解求出T=“abaabe”的next[ ]数组
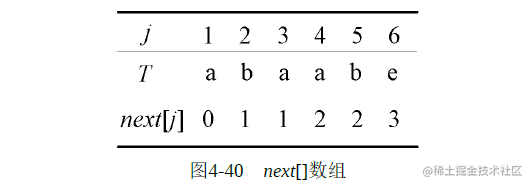
解释如下。
1)初始化时next[1]=0,j=1,k=0,进入循环,判断满足k==0,则执行代码next[++j]=++k,即next[2]=1,此时j=2、k=1。
2)进入循环,判断满足T[j]T[k],T[2]≠T[1],则执行代码k=next[k],即k=next[1]=0,此时j=2、k=0。
3)进入循环,判断满足k0,则执行代码next[++j]=++k,即next[3]=1,此时j=3、k=1。
4)进入循环,判断满足T[j]==T[k],T[3]=T[1],则执行代码next[++j]=++k,即next[4]=2,此时j=4、k=2。
5)进入循环,判断满足T[j]==T[k],T[4]≠T[2],则执行代码k=next[k],即k=next[2]=1,此时j=4、k=1。
6)进入循环,判断满足T[j]==T[k],T[4]=T[1],则执行代码next[++j]=++k,即next[5]=2,此时j=5、k=2。
7)进入循环,判断满足T[j]==T[k],T[5]=T[2],则执行代码next[++j]=++k,即next[6]=3,此时j=6、k=3。
8)j=T[0],循环结束。
有了next[ ]数组,就很容易进行模式匹配了,当S[i]≠T[j]时,i不动,j回退到next[ j ]的位置继续比较即可。
算法复杂度分析
设S、T串的长度分别为n、m。KMP算法的特点是:i不回退,当S[i]≠T[j]时,j回退到next[j],重新开始比较。最坏情况下扫描整个S串,其时间复杂度为O(n)。计算next[]数
组需要扫描整个T串,其时间复杂度为O(m),因此总的时间复杂度为O(n+m)。
需要注意的是,尽管BF算法最坏情况下时间复杂度为O(n×m),KMP算法的时间复杂度为O(n+m)。但是在实际运用中,BF算法的时间复杂度一般为O(n+m),因此仍然有很多
地方用BF算法进行模式匹配。只有在主串和子串有很多部分匹配的情况下,KMP才显得更优越。
4.4 改进的KMP算法
在KMP算法中,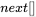 求解非常方便、迅速,但是也有一个问题:当
求解非常方便、迅速,但是也有一个问题:当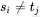 时,j回退到
时,j回退到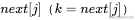 ,然后
,然后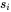 与
与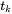 比较。这样的确没错,但是如果
比较。这样的确没错,但是如果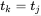 ,这次比较就没必要了,因为刚才就是因为
,这次比较就没必要了,因为刚才就是因为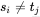 才回退的,那么肯定
才回退的,那么肯定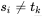 ,完全没必要再比了,如图4-41所示。
,完全没必要再比了,如图4-41所示。
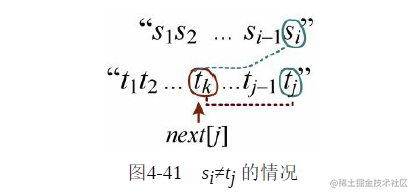
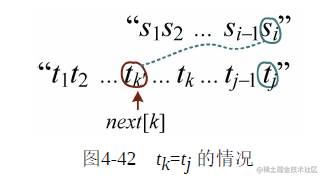
再向前回退,找下一个位置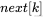 ,继续比较就可以了。当
,继续比较就可以了。当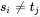 时,本来应该j回退到
时,本来应该j回退到 ,
,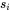 与
与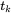 比较。但是如果
比较。但是如果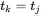 ,则不需要比较,继续回退到下一个位置
,则不需要比较,继续回退到下一个位置 ,减少了一次无效比较,如图4-42所示。
,减少了一次无效比较,如图4-42所示。
算法复杂度分析
设S、T的长度分别为n、m。改进的KMP算法只是在求解next[]从常数上的改进,并没
有降阶,因此其时间复杂度仍为O(n+m)。
3种算法的运行结果比较如下。
S: a a b a a a b a a a a b e a
T: a a a a b
BF算法运行结果:
一共比较了21次。主串和子串在第8个字符处首次匹配。
KMP算法运行结果:
-----next[]-------
0 1 2 3 4
一共比较了19次。主串和子串在第8个字符处首次匹配。
改进的KMP算法运行结果:
-----next[]-------
0 0 0 0 4
一共比较了14次。主串和子串在第8个字符处首次匹配。
4.5 字符串小结

串解题时需要注意几个问题。
1)空格也算一个字符。空串是指没有任何字符,空格串不是空串。
2)串中位序和下标之间的关系。如果下标从0开始,则第i个字符的下标为i−1。
3)充分理解KMP算法中的next[]求解方法。
4)熟练利用字符串模式匹配解决实际问题。















 4611
4611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









